The First Fully General Computer Action Model
si.incHey guys! I’m Neel, been holed up in our south park office for the past year working on model training. excited to share our research!
This is a preview of a very different type of computer use model—we train on the internet. Specifically we have 11 million hours of computer video stored on our storage cluster (previously shared https://news.ycombinator.com/item?id=45438496 !) and the model can work in 30 FPS. Since we match the fundamental form factor of computer-use, we can get our model to do CAD, browse websites, and even drive a car using arrow keys. I’m super excited to see what our model can do as we scale more, it's a fun frontier to work on (not language models :) ).
The team and I will be online responding to the comments, so drop any questions.
How do I access this? Any HF or API coming?
Any benchmark comparisons to Fara-7B or Sonnet 4.6, Qwen 3.5 etc.?
This looks like a really promising approach
In particular the Forward rollout module is very important. It aligns your (effectively) world model with what it expects from the world, and keeping those in sync I think gives this the power it needs to be able to generate the state action pairs to continuously train semi supervised
11 million hours of data is a lot, did you have to synthesize it at all, or was it purely collected?
collected! no synthetic
Cool! Isn’t this what cursor initially tried to do before they pivoted? Hence cursor?
Must have been really hard. What was the breakthrough?
Great work! Why no benchmarks though?
Get ready for the acquisition offers.
This seems like really great research, and the first time I’ve seen overwhelming praise on HN. Congrats!
I wanted to comment though that your title is not doing you any favors, and I suspect that is why this is not getting more traction (which it deserves). I fully expected some half baked GitHub repo, but instead found something truly awesome.
To use your own words, Neel, “ a very different type of computer use model” would have had me clicking faster. I’m not great at titles, however, and maybe there are better ideas out there.
Anyway, can’t wait to see how this develops! Especially looking forward to the CAD work.
cool thanks for the title idea!! hopefully when we scale up in the next month/two we can update the community
I rly liked the point about ctrl-c only being able to be labelled retrocausally. I do think that with enough past context you should be able to know what was copied - in some sense the past does encode the future - but also an agentic decision is precisely the kind where the future is more informative than the past for reconstructing that decision.
It does make me wonder if you should have the inverse dynamics model split into specifically retrocausal and causal. You kind of do this already with the inverse and forward dynamics model, but the idea of a model that knows only about the future training in a feedback loop with a model that knows only about the past is kind of interesting.
I think you could just do a clever masking regime in your diffusion model to achieve the same effect without a whole architecture change.
yeah we actually had some wacky ideas with ctc + a reverse-causal mask but diffusion does just make it all a bit more simple
At first glance, this looks incredible to me. The authors train one model on 40K hours of computer-use video, previously labeled by contractors with keyboard and mouse actions, then use that model, in effect, to label 11M hours of computer-use video, which they use to train the computer-action model. The key advance is in compression. Quoting from the OP:
> [previous models] burn a million tokens to understand just one minute of 30 FPS computer data. Our video encoder encodes nearly 2 hours of video in the same number of tokens—that’s 50x more token-efficient than the previous state-of-the-art and 100x more token-efficient than OpenAI’s encoder.
While I was already aware that there are people working on new, more efficient "world models," this is the first one I've seen in action. I'm a bit in shock at how good it is, quite frankly.
I've added the OP, as well as a related 2018 paper on Behavioral Cloning from Obervation (BCO) to my reading list.[a] So far, I've only skimmed the 2018 paper, but it's already evident that it's well-written. I'm no expert in deep RL, and I can understand it. BTW, "Behavioral Cloning from Obervation" is a really good name, with an easy-to-remember acronym.
Thank you for sharing this on HN.
yeah! i love the BCO paper, i think its extremely intuitive and these methods are really interesting in a time where data without labels is abundant. i especially like the idea of iteratively making the inverse dynamics better—might lean closer to that in the future
> i especially like the idea of iteratively making the inverse dynamics better
Same here.
The notion of inducing these models to "hypothesize" distributions over possible actions given subsequent observed transitions makes me think of "contrastive divergence," the method Hinton and others came up with for unsupervised training of Restricted Boltzmann Machines (RBMs), in the prehistoric era of deep learning.
Given each training sample, an RBM would 1) execute a forward pass, 2) sample its output units, 3) "hypothesize" its input units, 4) execute another forward pass on the "hypothesized" input units to sample new output units, and (5) compute a type of contrastive error for local backpropagation. RMBs could be stacked, with output units from one becoming input units for the next one. Hinton called the input units "visible," and the output ones "hidden."
It's not the same, obviously, but the idea of modeling machine-generated inputs (or actions) given outputs (or transitions) has always been appealing. It has a long history.
This looks extremely impressive, really deserves more attention here.
Are the inverse dynamics and forward dynamics models trained separately? It sounds like if the inverse dynamics model is meant to extrapolate more training data, then perhaps all that means is it takes very little data to generalize directly with the forward dynamics model assuming the right architecture.
thanks! the inverse dynamics model is trained first on 40k hours of data and then frozen to label all 11 million hours. yup! the idea is that it should take a small amount of data to generalize environment dynamics, then you can use a lot of data to understand actions.
Congratulations! I’ll be interested to see the next steps in alignment. Do you plan to start selling access, or collect more data to train bigger & better? What tasks or benchmarks are your biggest guide stars, or what was unexpectedly tricky—a few are hinted in the post.
It would be pretty interesting to see activation maps for the encoder on video, confidence building to see the compression derived from so much training.
we have an alignment blog post dropping soon! scaling up in the next couple of months, then hopefully opening up an API or licensing it.
Benchmarks are really fun—lots of secret ones. Our main thesis is that you should be using the same benchmarks to measure human ability to use a computer, as you would an AI model. Definitely a suite of continuous long term planning tasks (games) and things such as marking emails as spam etc.
definitely! we are looking into more interp + visualizations in general as we scale up.
The mouse cursor binning special case is starting to look like how animals perceive, where we detect patterns and develop predictive models over time in how they are going to act, and that confidence leads to more deeply encoding those patterns for lower energy usage. Obviously the mouse cursor is a hand-rolled example in a controlled 2d environment, but it makes me wonder what efficiencies lie in identifying patterns in 3d environments once you construct an accurate enough 3d scene out of the images you have.
Do you have other examples of special cases you're looking at? Any 3d ones?
This is one of those hacker news posts that you stumble upon and see 2 genius ideas within the span of as many paragraphs. Thanks again for sharing the diffusion based labeling algorithm. Truly demonstrates a mastery and understanding of what diffusion is capable of.
thanks! i definitely love diffusion + pushed for it, as a non-causal generative method i think its pretty unique
I thought it was a good write up but did anyone catch the ending comment?
> We believe artificial general intelligence will be created within our lifetimes, and likely within the next decade.
Maybe within our lifetimes (if you are young) but I find it highly unlikely within the next decade.
That's just like, your opinion man
Nice, I have always felt the computer was the ultimate environment and screen capture the ultimate training data. Nice to see it in practice, now we have to wait to see if folks are going to argue on if your model could really learn a world model. I'm surprised this post doesn't have more comments, their site is worth checking out. Rooting for them, they are gritty, checkout their storage buildout story.
dammmmmmnnnn - lots to like here. I'm impressed with the 80,000 parallel website fuzzing desktops. And the 30hz (everything). Amazing.
Neel, this is really cool. How long have you been working on this, and where did you guys get inspiration from? Did you work on vlms earlier or something like that? Just curious.
Also, thanks for choosing a technical blog post for presenting this information.
thanks! got a lot of inspiration from VPT https://arxiv.org/abs/2206.11795 is a great paper, would recommend a read
we all have various backgrounds, me particularly i did a lot of material science x ai research and just fundamental architecture research before
I think you guys are on the right track here. I’d love to learn more about the math behind the FDM. I don’t think folks realize how behind we are on vision, thank you for your work here.
thanks! the math and architecture of the FDM (no video encoder) is pretty simple, its a regular transformer with next-token predictions but with frames interleaved.
Just wanted to say: this is might impressive research.
Really interesting breakdown, proper nerdsniped into this, thanks for the refreshing AI news outside of language models :)
May I suggest a driving demo in a parking lot with a mannequin instead of a real world video where it drives way too close to a pedestrian?
Otherwise, very cool and exciting!
safety was important for the demo, the model didn't have access to the brake or accelerator.
Frankly, this comment does little to avail the parent's point - doing this on the open road was both illegal and reckless. It reflects extremely poorly on your character and the project as a whole.
This is fascinating! Having a really strong video encoder model and then a simpler decoder from that reminds me of the recent D4RT from DeepMind as well: https://d4rt-paper.github.io/
I think we'll see more of these video encoder models in the coming years, they truly seem like magic.
Curious about the masked diffusion IDM choice. They mention CTC loss and cross-entropy both underperformed — I'd love to see ablations on that. The claim that typos were "extremely common" with non-causal cross-entropy is interesting but hand-wavy without numbers.
the main chain of experiments was trying causal => non-causal => non-causal with ctc and CE. i think a good intuition here is that you need a generative approach fundamentally because there definitely are multiple correct IDM labels.
The car thing is very impressive By the way, do you have plans to handle the computer’s audio output?
yeah we've done audio work in the past so we'll def merge the recipes at some point, long term should have full io that a human has (except maybe not generating video for video calls that seems a bit much)
what tasks can the model do out of the box? was each of the examples a different fine tuned model?
it's a pretty general policy but this is all super early, it's great at exploring websites so fuzzing was easy, for CAD it has good enough base rates with the few-shot prompt when we do the repetitive stuff, and we gave it checkpoints on each step, the other stuff in the mosaic are just some of our favorite clips from internal evals
The lack of benchmarks and light demos have me skeptical... The methods seem interesting, and maybe does unlock something novel, but it's odd to go into so much depth on the methods and leave so much wanting in the results?
It's probably much worse than VLMs on the computer use benchmarks out there. A lot of those benchmarks would be very hard to complete without the intelligence that arises from text pretraining.
Do you have more info on video encoding process?
You write:
>We created a model without this tradeoff by training our video encoder on a masked compression objective
And I understand why this would give you more detail per token, but how are you reducing total number of tokens?
The video compression is very cool. And the small tricks like binning the mouse movements.
Wonder how much data is generalizable across different UIs? ie how good will the model be at using Figma if it’s never seen it before but has seen a lot of Photoshop
this is honestly an issue for the inverse dynamics (for app specific shortcuts etc.) but for general UI learning we still see promising eval trends
Amazing work! I look forward to an API if/when you release it!
I am amazed that the IDM is able to produce enough high quality annotations for the downstream FDM to work, even matching the ground truth contractor annotations!
Can it defeat captchas?
Where did they get 11 million hours of screen recordings?
Looks extremely impressive! Genuine question - why are you sharing your methods openly? I am grateful for it, but just curious your motivations.
giving back to the research community! releasing and talking about research helps everyone
Saw this a few days ago, looks really cool! How many params is the model? Did you fine tune or train from scratch? Are you hiring?
What sort of fine tuning data was needed to allow the model to self-drive? One hour of video of someone driving, or extra labeling?
i actually drove the car (with arrow keys) around south park for around ~45 minutes as finetuning data, no extra labelling other than that. think the car line graph is super cool because you actually see the videegame prior working
relevant note is that we finetuned by having the human also use arrow keys which keeps it in-distribution but also slower to collect
Curious - how much did this cost to train?
This is the coolest thing I’ve seen on HN in a while
How effective is the model on real world computer tasks
Looks like it's playing the special stages from Knuckles' Chaotix?
Very impressive stuff!
Can you prompt it or is it strictly Copilot-style prediction?
planning on instruct tuning soon!
Very exciting, great work to you and the team. Will there be any APIs available for commercial use or open source access?
What's the plan on that front?
Awesome! That will be very interesting
Nice that it can drive a car, but you could just use openpilot.
Beware of ending up on the top page of "things HN didn't like" with such a comment (see post a few days ago)
Really really cool. I appreciate the article style a lot too.
thanks! a lot of credit to the people who helped write/edit
How do you tokenize the mouse inputs?
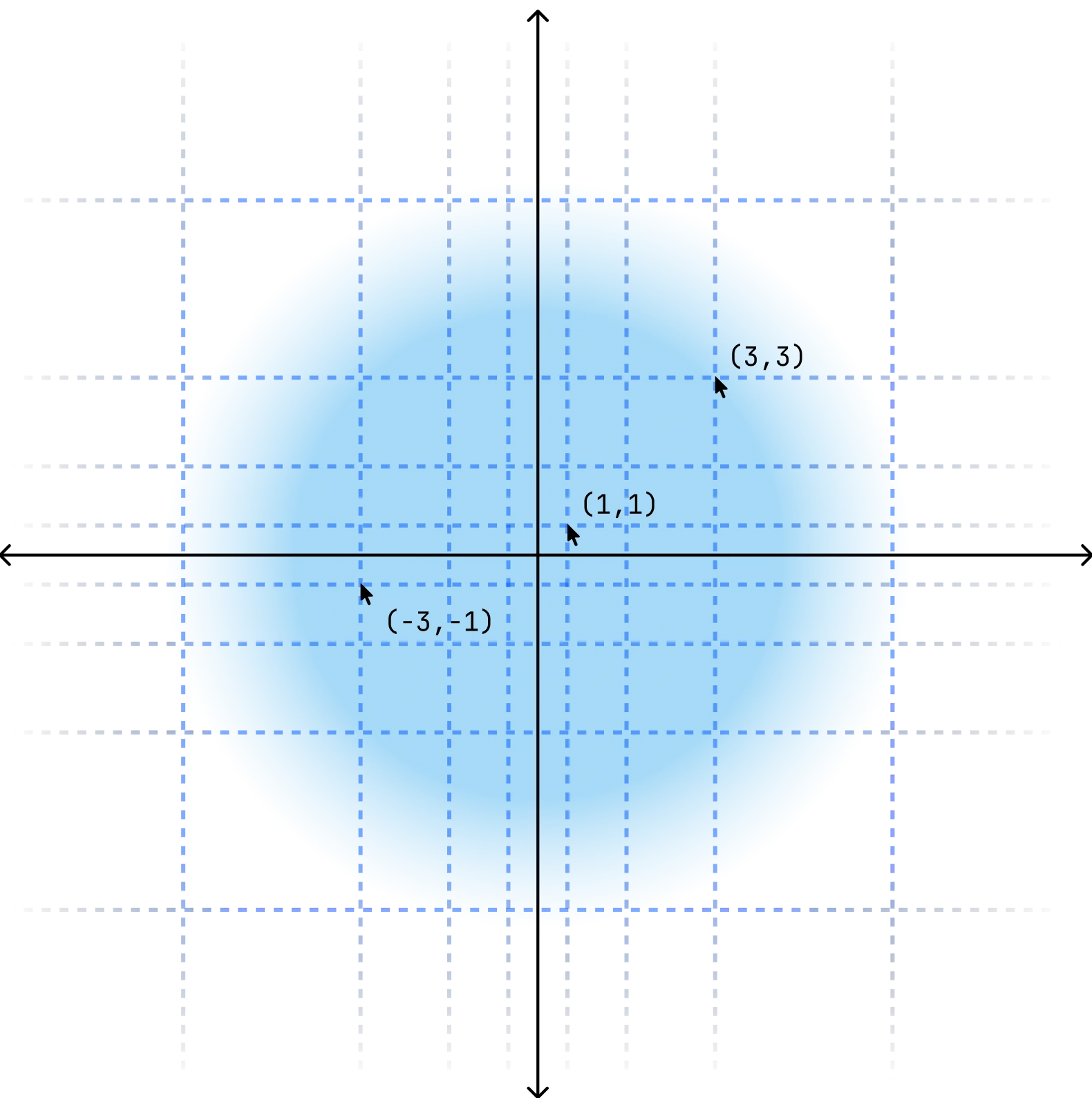
good question! we use exponential binning (map the mouse movements onto a plane with exponentially increasing tick marks https://si.inc/fdm1/exponential_binning.webp) but tried a bunch of other methods (linear creates too many tokens for the model to learn well). Polar coordinates seem like a better solution but empirically didn't work well because the tokens got too coarse too fast.
It’s interesting that you invest in mouse movements vs just targeting a click at X in Y milliseconds. CAD and video games are of course a great reason for this, but I wonder how much typical tool use can be modeled by just next click events.
I’d love to see this sort of thing paired with eye tracking and turned into a general purpose precog predictive tool for computer use … but you probably have many better use cases for your world model!
we do exponential binning but fwiw I think we can do way better just hasn't been the main research area initially
{kind=link}
holy crap, this is so good. How did it get buried?
Too technical for HN
real
Are you guys affiliated with Meta’s ex-CTO in any way? I remember he famously implied that LLMs hyped. The demos are very impressive. Does this use an attention based mechanism too? Just trying to understand (as a layman) how these models handle context and if long contexts lead to weaker results. Could be catastrophic in the real world!
I think in the long run, we may need something like a batch job that compresses context from the last N conversations (in LLMs) and applies that as an update to weights. A looser form of delayed automated reinforcement learning.
Or make something like LoRA mainstream for everyone (probably scales better for general use models shared by everyone).
Amazing!
My tech-informed but ML-ignorant take: This will soon be the biggest thing since ChatGPT.
Cannot scroll this page without my phone hanging.
Disgusting website.