In part one we went on a whistle-stop tour of the impactful papers in machine learning before deep learning took over the entire field.
Before the ascendance of LLMs, we had a revolution in computer vision that used similar tools (neural nets, backpropagation). To me they culminated in the NotHotDog App from the TV show Silicon Valley which does exactly what you think it does.
However both things taste like shoes
To go from reading numbers in a zip code to being able to identify (or not) a literal hot dog in an image required a few breakthroughs.
Welcome to part two of the two line paper summaries series!
I’m sure you know what a neural net is, but others might not, so here’s a quick summary for them.
A neural net is a function that takes numbers in and spits numbers out. The input numbers pass through layers of “neurons” that each do three things: multiply inputs by weights, add them up, and pass the result through an activation function.
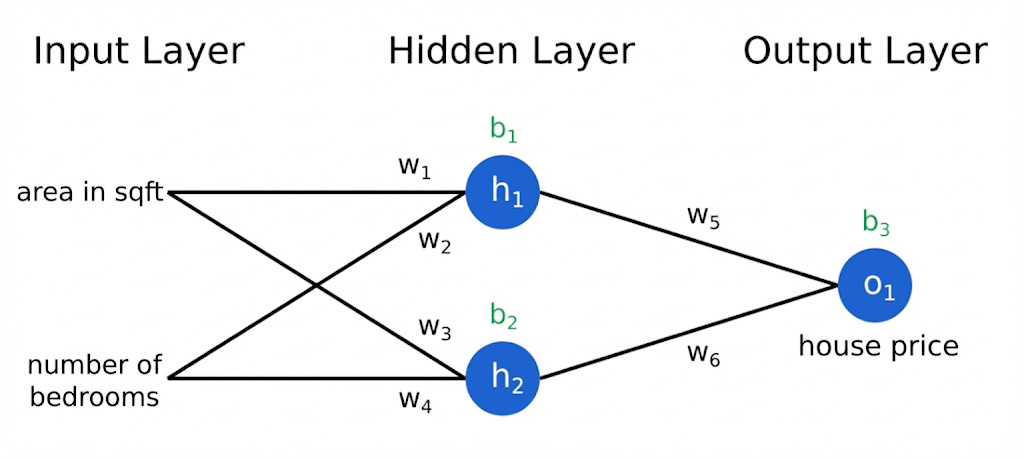
For a neural net that uses house area and number of bedrooms to predict house price, it might look like this:
To get the value of house price, o1, you need to compute w5 * h1 + w6 * h2 + b3 and then run that through a non linear function. Similarly for getting the value of h1 from w1, w2 and the area and bedrooms.
The flexibility here is in the weights (w1-6 and b1-3). They start random and get adjusted through training. You show the network my apartment size, and its one bedroom, and it guesses I need a job a house price.
You then tell it how wrong it was (called the loss), and then you nudge all the weights slightly in the direction that would have made it less wrong. That nudging process is called gradient descent, and figuring out which direction to nudge each weight is called backpropagation.
You can do the same with an image based neural net and build something that can distinguish hot-dogs from not-hot-dogs. This requires you to convert the image pixels into raw numbers from the red, green, and blue channels before passing it through a larger neural net that contains more hidden layers and more flexibility. And similarly you then nudge the weights after each example in the direction of the correct answer.
Do this millions of times with millions of images and those weights will hopefully arrange themselves into something that recognizes hot dogs.
The problem is that ‘nudge the weights’ gets tricky when you stack many layers. Without some careful thought the gradient tends to either shrink to nothing or blow up to infinity. Many of the papers in this post are trying to fix that.
As the models got bigger, we needed more data. Well curated datasets ended up being important parts of improving our models and the early important datasets were often built by people who are now well known in the field.
What if Alex Krizhevsky (while working for Geoff Hinton) simply right-clicked “Save-As” on 6000 images of cats, 6000 of airplanes, and 6000 of eight other nouns and turned that into a 60,000 image dataset?
Answer: We end up with one of the most popular datasets for image recognition prototyping of the 2010s.
What if Fei-Fei Li simply did CIFAR-10 but with 14 million images rather than 60 thousand?
Answer: 14 million images ends up being so big and difficult that this becomes the de facto standard dataset for benchmarking for years.
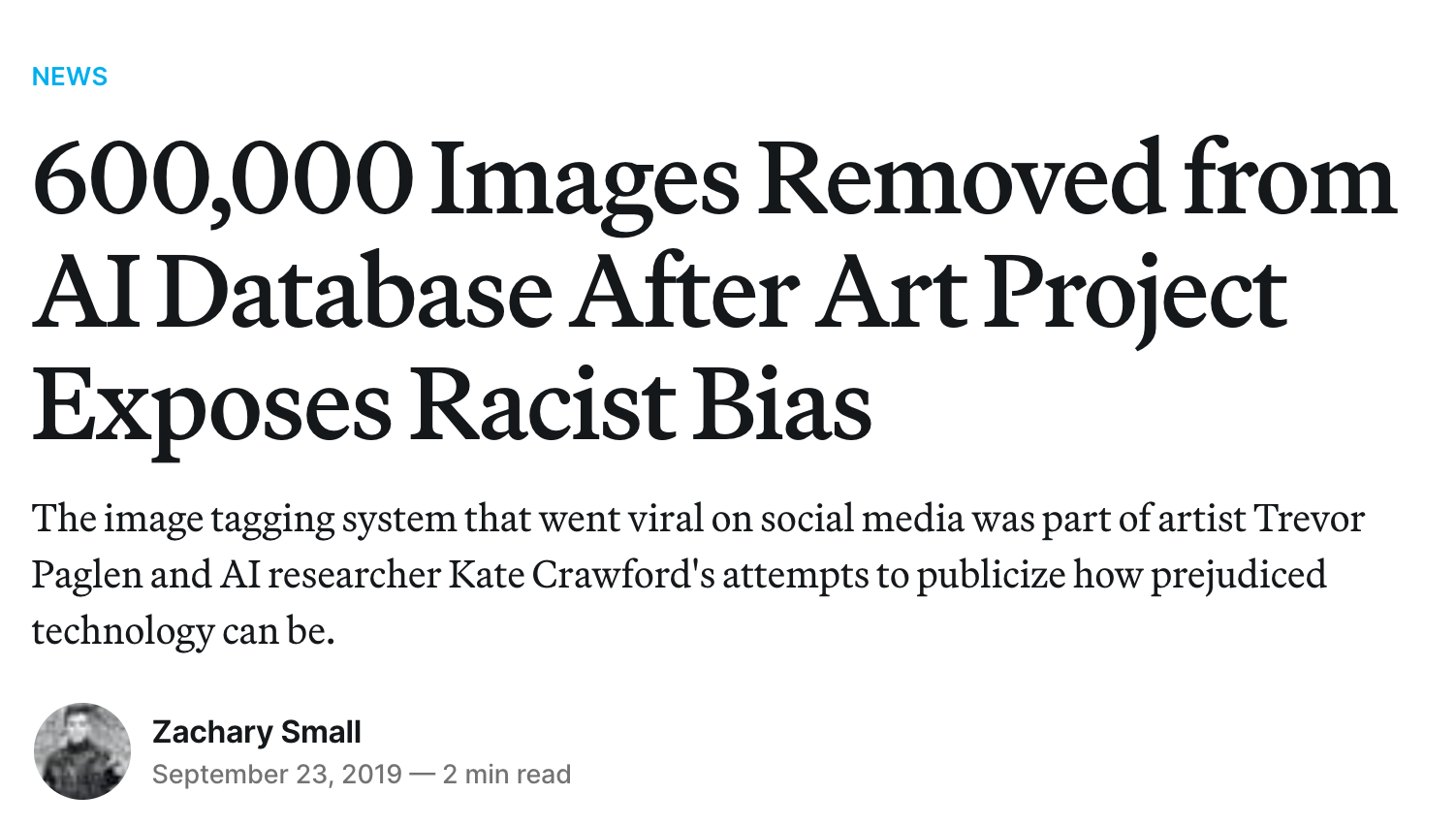
Somehow with 14 million images labeled by mechanical turks we had absolutely perfect labeling. Right?
Only took 10 years to realize our data was kinda racist
Once AlexNet made everyone realize that you could train neural nets on GPUs, there was a mad rush to try every small variant of neural network architecture. Most are forgotten to history, a few breakthroughs are listed here, but most progress came from the training tricks in the next section.
What if we simply wrote GPU code ourselves (ew gross) and trained a convolutional neural net on two GPUs for a week (also gross) and used the ReLU activation function (ok not that gross)?
Answer: It destroys the competition, upends the field, and makes everyone switch away from anything but “convolutional neural nets” on GPUs. The model itself wasn’t simple though. Here’s a picture of it:
What if we simply added the input of a layer to its output?
Answer: One of the biggest training problems (the vanishing gradient problem) itself vanishes. We can now train networks with 100+ layers without them breaking.
This becomes the most cited ML paper of all time and this technique continues to be used to this day. The ResNet improvement leads to the concept of the residual stream in mechanistic interpretability which we’ll touch on in the next post.
Training these models was really hard for a variety of reasons. The gradient, a crucial piece of the training process, was hard to keep from vanishing or exploding. Over-fitting was a constant struggle because we trained on the data multiple times. And finding optimal hyperparameters remained an art.
Answer: Good idea guys! AdamW remains the main optimizer in open source training runs.
Computer vision was the success story of the 2010s, but people weren’t sleeping on natural language processing. A few important papers in this decade laid the foundation for the next part of the series - LLMs
What if we simply gave the neurons a “memory cell” and “gates” to decide what to forget and what to keep?
Answer: Recurrent networks stop forgetting the beginning of the sentence by the time they reach the end. Unfortunately training these was finnicky and took ages.
What if we simply normalized across the features instead of across the batch?
Answer: BatchNorm doesn’t work well for RNNs but this does. The Transformer would eventually need this to exist.
The history of deep learning is really the history of making model training not break. Papers that could help people train models more reliably, consistently, and faster, got immediately adopted. Training tricks, new datasets, and occasional architectural improvements all contributed to image recognition being a solved problem by the end of the decade.
And at the same time NLP hadn’t had its ImageNet moment, but in 2017 a small paper called “Attention is all you need” came out and while only a few took notice originally, it ended up setting the groundwork for the era of the LLMs.

![Network architecture of AlexNet [1].](https://substackcdn.com/image/fetch/$s_!qihw!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcefa0367-71f4-45d1-bc0a-7432b2383112_1339x503.png "Network architecture of AlexNet [1].")