Introducing
Xiaomi-Robotics-0
February 12, 2026
Xiaomi-Robotics-0 is an advanced Vision-Language-Action (VLA) model optimized for high performance and real-time execution.
We introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on a large amount of cross-embodiment robot trajectories and vision-language data, enabling it to acquire broad and generalizable action-generation knowledge while preserving strong VLM capabilities. During post-training and deployment, we employ asynchronous execution techniques to address inference latency, ensuring continuous and seamless real-time rollouts.
Results
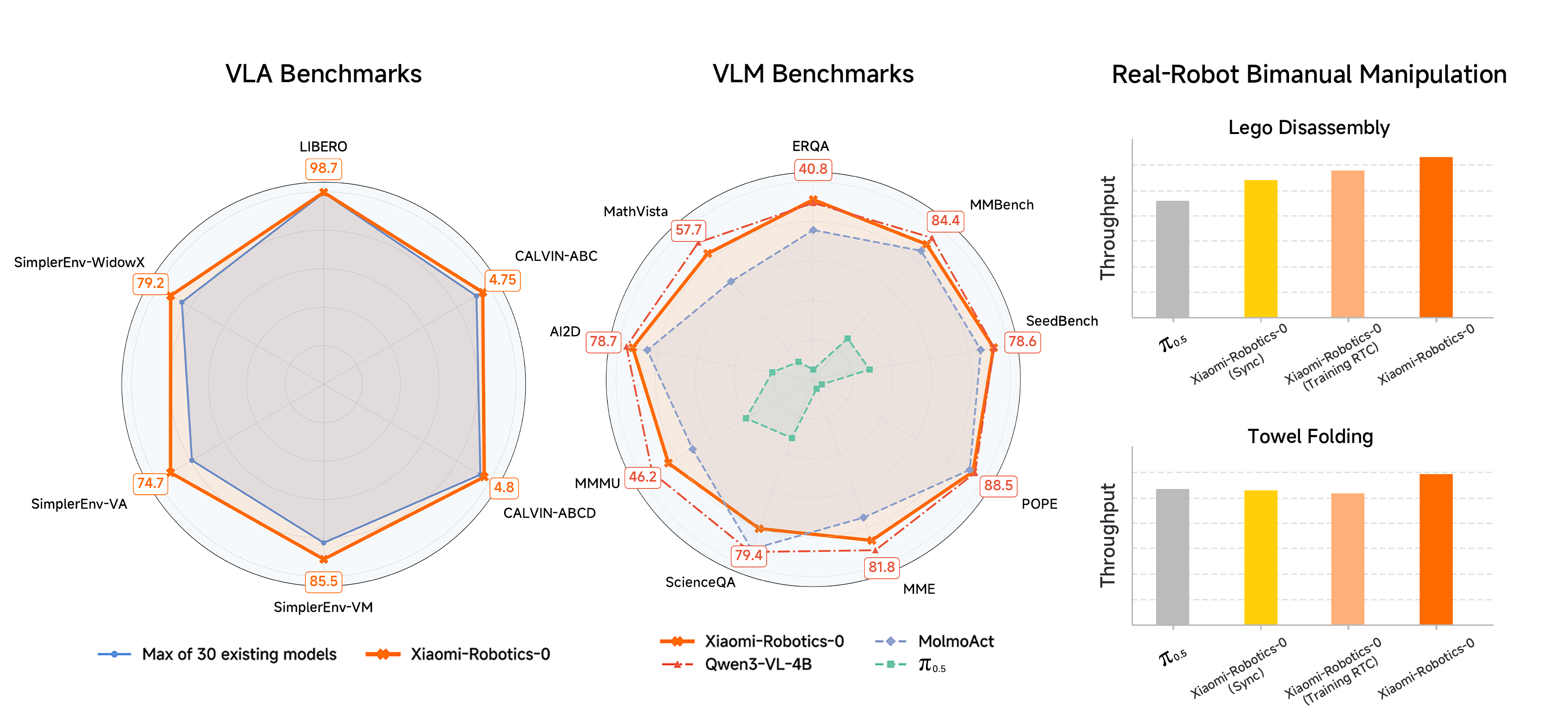
Xiaomi-Robotics-0 achieves state-of-the-art performance across three simulation benchmark. Specifically, it achieves an average success rate of 98.7% on LIBERO. On SimplerEnv, it delivers strong performance under Visual Matching (85.5%) , Visual Aggregation (74.7%), and WidowX (79.2%). On CALVIN, it attains an average length of 4.75 and 4.80 on the ABC-D and ABCD-D split, respectively. On VLM benchmarks, our pre-trained model matches the performance of the underlying pre-trained VLM. In real-robot evaluations, Xiaomi-Robotics-0 achieves high success rates and strong throughput on two challenging bimanual manipulation tasks, Lego Disassembly and Towel Folding.
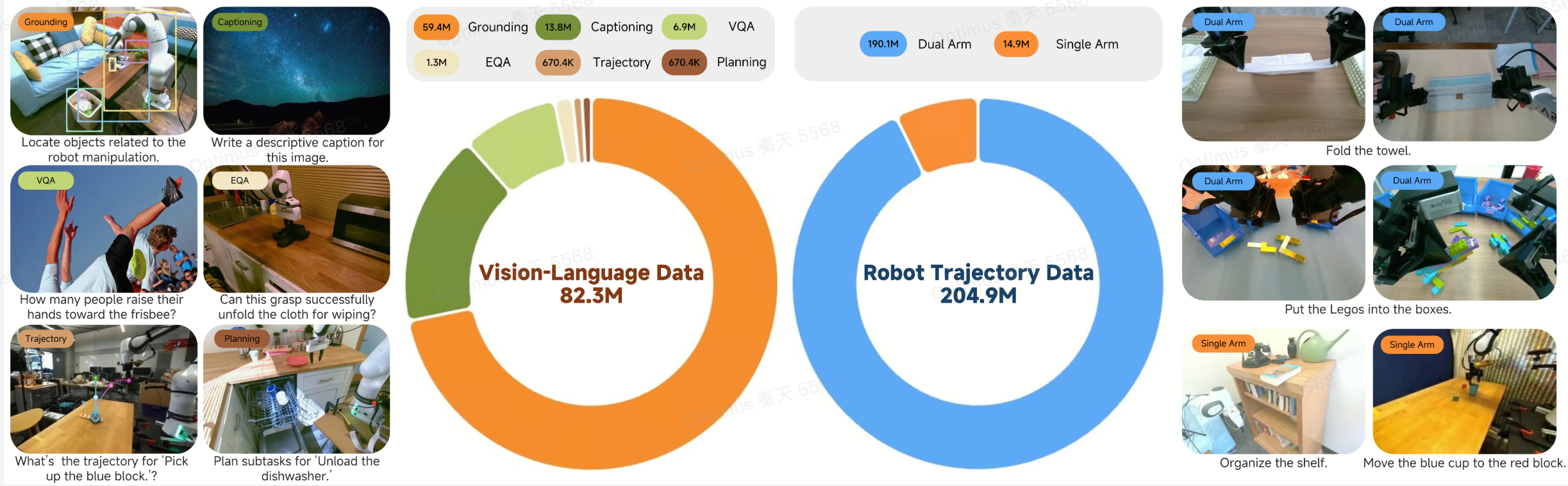
Data
Our training leverages a massive dataset consisting of approximately 200M timesteps of robot trajectories and over 80M samples of general vision-language data. The robot data is sourced from both open-sourced datasets and in-house data collected via teleoperation, including 338 hours for Lego Disassembly and 400 hours for Towel Folding. The VL data is integrated to prevent catastrophic forgetting and enhance visual understanding on robot-centric images.
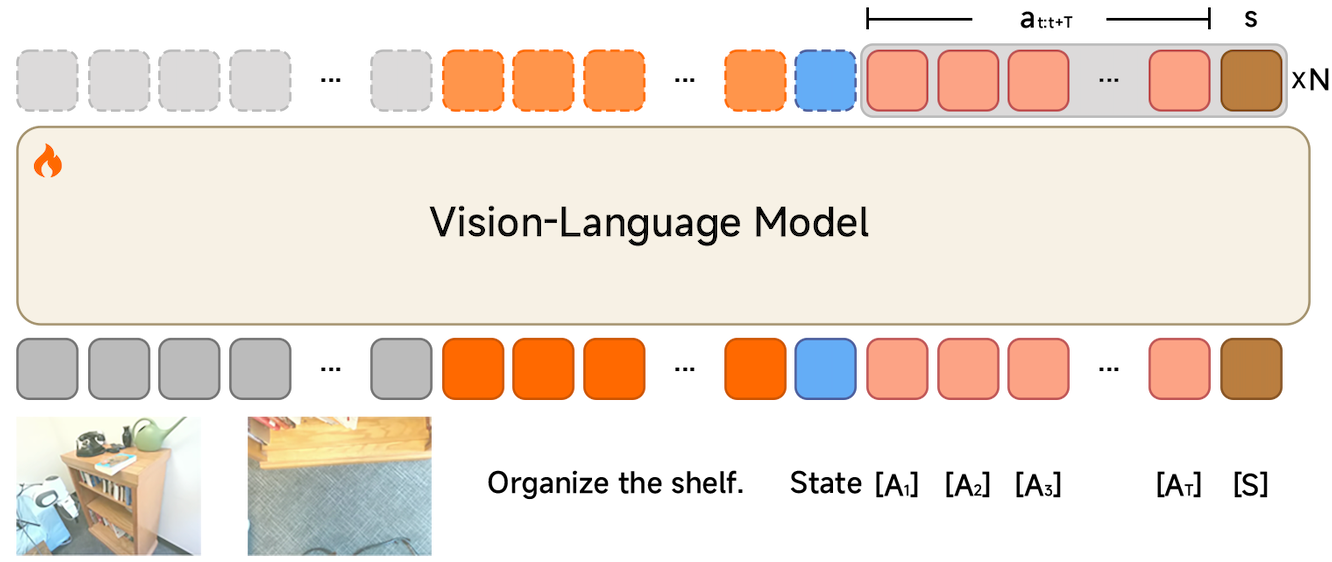
Pre-training
We adopt a architecture comprising a pre-trained VLM (Qwen3-VL-4B-Instruct) and a Diffusion Transformer (DiT). The VLM processes observation images and language instructions to produce a KV cache. The DiT then generates an action chunk via flow matching, conditioned on the KV cache and the robot proprioceptive state. In total, the model contains 4.7B parameters.
Stage 1
We first endow the VLM with action-generation capabilities using Choice Policies, accounting for the multimodality of action trajectories. To maintain vision-language capabilities, we mix vision-language data and robot trajectories at a ratio of 1:6.
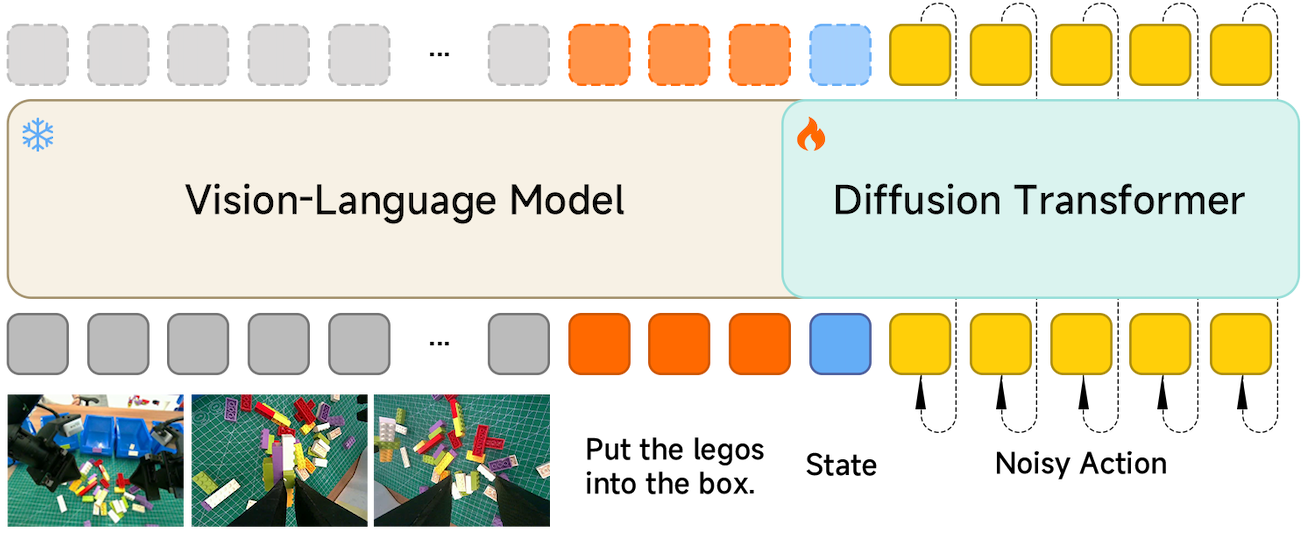
Stage 2
We then freeze the VLM and train the DiT from scratch using a flow-matching loss. The VLM acts as a frozen multimodal conditioner. The DiT learns to generate precise and continuous action chunks conditioned on the VLM's visual-language features and the robot state.
Post-training
Post-training adapts Xiaomi-Robotics-0 to a specific embodiment. We adopt action prefixing during training to ensure consistency between consecutively predicted action chunks. To ensure reactive and responsive actions, we introduce several techniques to prevent the model from leveraging the temporal correlations between successive actions.
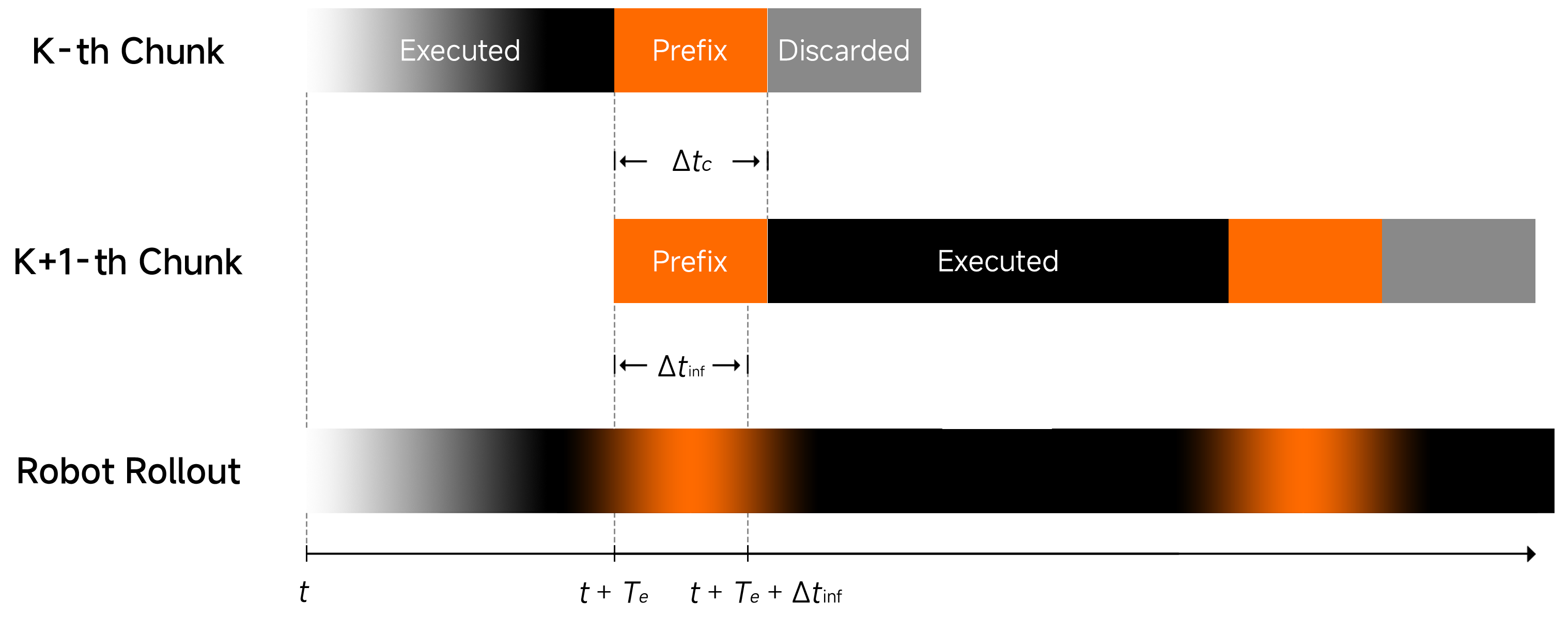
Asynchronous Execution
To enable seamless real-time rollouts, we perform asynchronous execution. The robot executes the remaining actions of the current chunk while simultaneously inferring the next chunk.
We condition the next inference by prefixing Δtc committed actions from the current chunk. By ensuring that Δtc is larger than the inference latency Δtinf, we guarantee that there are actions always available for execution.
We align the timesteps of consecutive predicted action chunks to ensure continuous rollouts.
The Temporal-Correlation Problem
Conditioning on previous actions allows the model to exploit the temporal correlation between successive actions. Since successive actions are often similar, policy learning can leverage a shortcut which simply copies the action prefix rather than attending to other signals, resulting in less reactive motion.
Features
1. Adaptive Loss Re-weighting
We re-weight the flow-matching loss based on the L1 error between online-predicted actions and the ground truth. By assigning higher weights to actions with larger deviations, we penalize the model heavily when it drifts from the ground-truth trajectories.
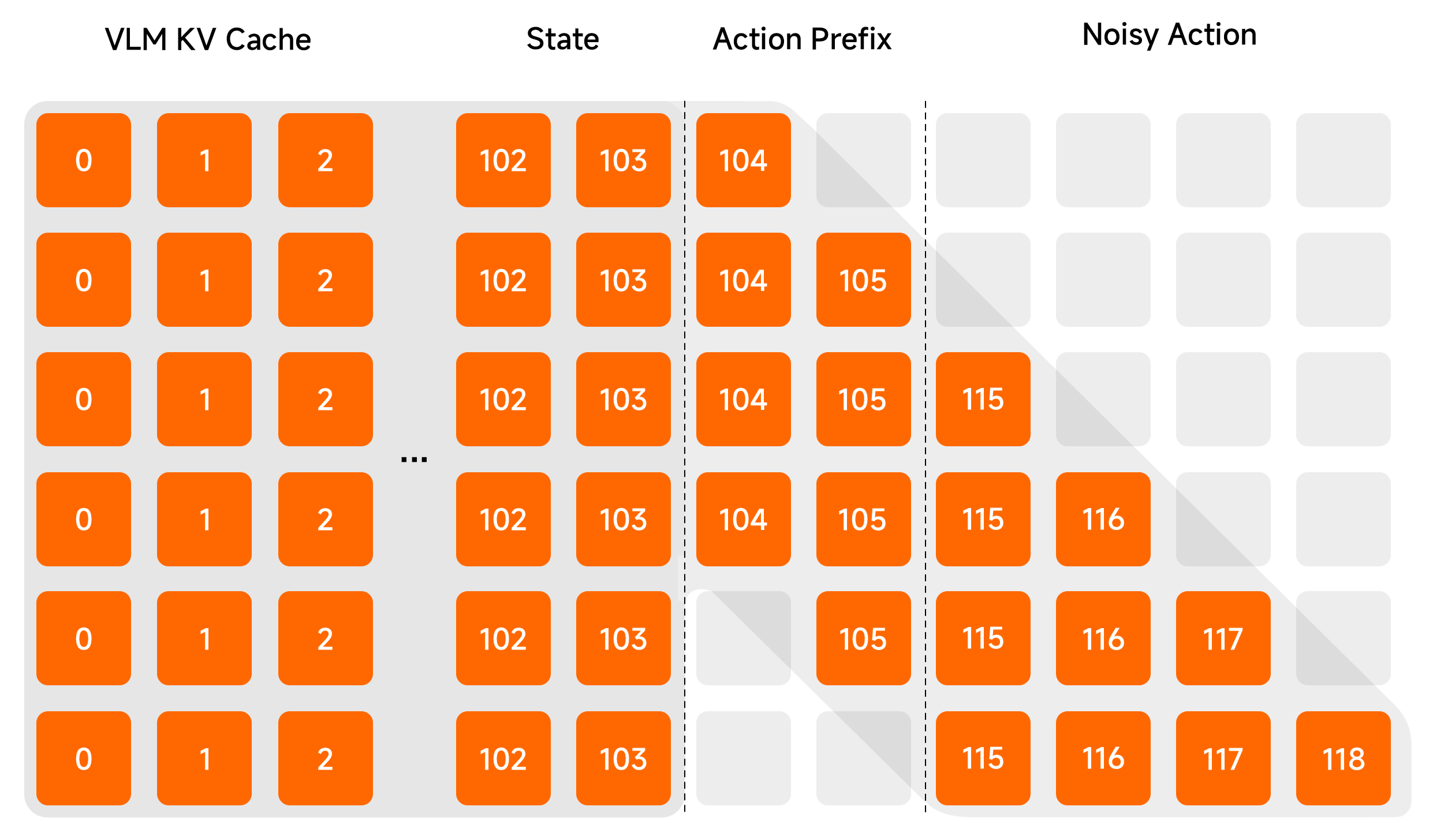
2. Λ-shape Attention Mask
We replace the causal attention mask in DiT with a Λ-shape mask. The noisy action tokens immediately following the prefixed actions can attend to them. Thus, the generated actions can smoothly transition from the action chunk produced by the previous inference. On the other hand, noisy action tokens of later timesteps cannot attend to the action prefix, forcing them to attend to visual and other signals, ensuring reactivity in the generated actions.
Highlights
Our method can disassemble complex Lego assemblies made of up to 20 bricks.
Our method adaptively switches grasping motions upon failure.
When a towel corner is occluded, our method learns to fling the towel with one hand to expose the hidden corner.
When two towels are picked out, our method puts the extra towel back before beginning the folding process.
Citation
@article{cai2026xiaomi,
title={Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution},
author={Cai, Rui and Guo, Jun and He, Xinze and Jin, Piaopiao and Li, Jie and Lin, Bingxuan and Liu, Futeng and Liu, Wei and Ma, Fei and Ma, Kun and Qiu, Feng and Qu, Heng and Su, Yifei and Sun, Qiao and Wang, Dong and Wang, Donghao and Wang, Yunhong and Wu, Rujie and Xiang, Diyun and Yang, Yu and Ye, Hangjun and Zhang, Yuan and Zhou, Quanyun},
journal={arXiv preprint arXiv:2602.12684},
year={2026}
}