Introduction
Zyphra announces a preview of ZAYA1, the first AI model trained entirely end-to-end on AMD’s hardware, software, and networking stack. Details of our pretraining efforts, hardware specific optimizations, and ZAYA1-base model benchmarks are described in the accompanying technical report published to arXiv.
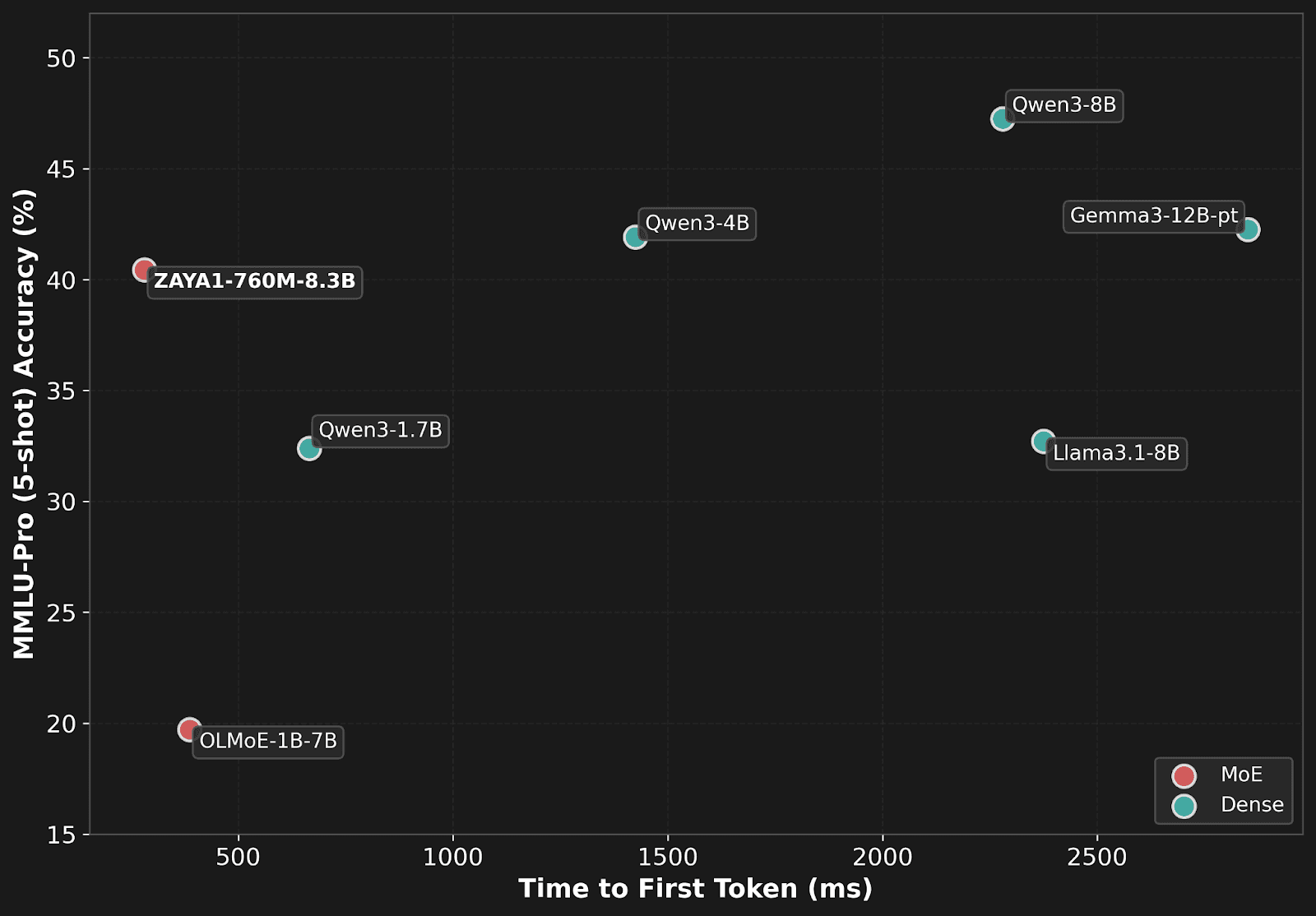
Our ZAYA1-base model’s benchmark performance is extremely competitive with the SoTA Qwen3 series of models of comparable scale, and outperforms comparable western open-source models such as SmolLM3, and Phi4.
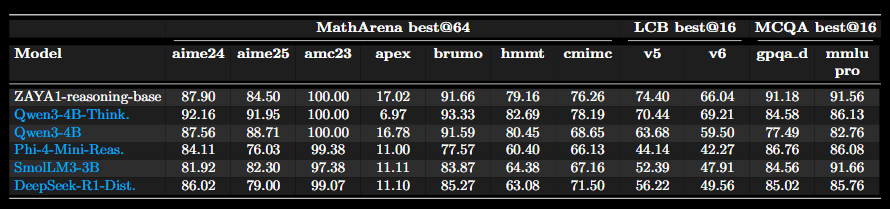
ZAYA1-reasoning-base excels especially at complex and challenging mathematical and STEM reasoning tasks, nearly matching the performance of SoTA Qwen3 thinking models under high pass@k settings even prior to explicit post-training for reasoning, and exceeds other strong reasoning models such as Phi4-reasoning, and Deepseek-R1-Distill.
Building on our previous work with AMD, we have been deeply committed to de-risking end-to-end large-scale pretraining on AMD. To create the infrastructure required to train ZAYA1-base, Zyphra, AMD, and IBM collaborated closely to build a large-scale, reliable, and highly performant training cluster using AMD MI300X GPUs with AMD Pensando Pollara networking. At the same time, we built a highly optimized, fault tolerant, and robust training stack specialized for AMD pretraining which we used to pretrain ZAYA1.
For Zyphra, ZAYA1 stands as a crucial demonstration that the AMD hardware and software stacks are both mature and performant enough to support large scale high performance pretraining workloads. With feasibility thus proven, and with the help of our close partners, we look forward to substantially scaling up our training efforts and training AI models that will deliver the next generation of breakthroughs in agentic capabilities, long term memory, and continual learning.
In our accompanying technical report, we provide a deep dive into our experience and insights from our efforts pretraining on AMD hardware as well as describe our training framework and the hardware specific optimizations we perform in detail. We aim to distill and describe a practical recipe that others can use when considering training on AMD..
Specifically, we provide a detailed characterization of our cluster hardware in terms of compute, memory bandwidth and networking components and relevant microbenchmarks for assessing their performance. We also provide detailed guidance on model sizing and other optimizations to ensure strong performance of training on this particular hardware, as well as details on fundamental kernels for the muon optimizer and other core training components that we implemented in order to optimize our training speed and efficiency.
The ZAYA1 Model
In addition, we provide a preview of the base model we produced by pretraining on the full AMD platform. In future works we will release and detail the final post-trained model checkpoints and its performance, as well as provide a more detailed description of the entire training process.
In short, the ZAYA1-base model was trained for 14T total tokens on Zyphra’s internal AMD-specialized training stack. Following recent works, ZAYA1 was optimized using the Muon optimizer. We trained in three core phases – pretraining phase1, pretraining phase 2 followed by a context length extension including mid-training. As the phases progress, we follow a curriculum training strategy where we shift from primarily unstructured web data to more highly structured and information dense mathematical, coding, and reasoning data.
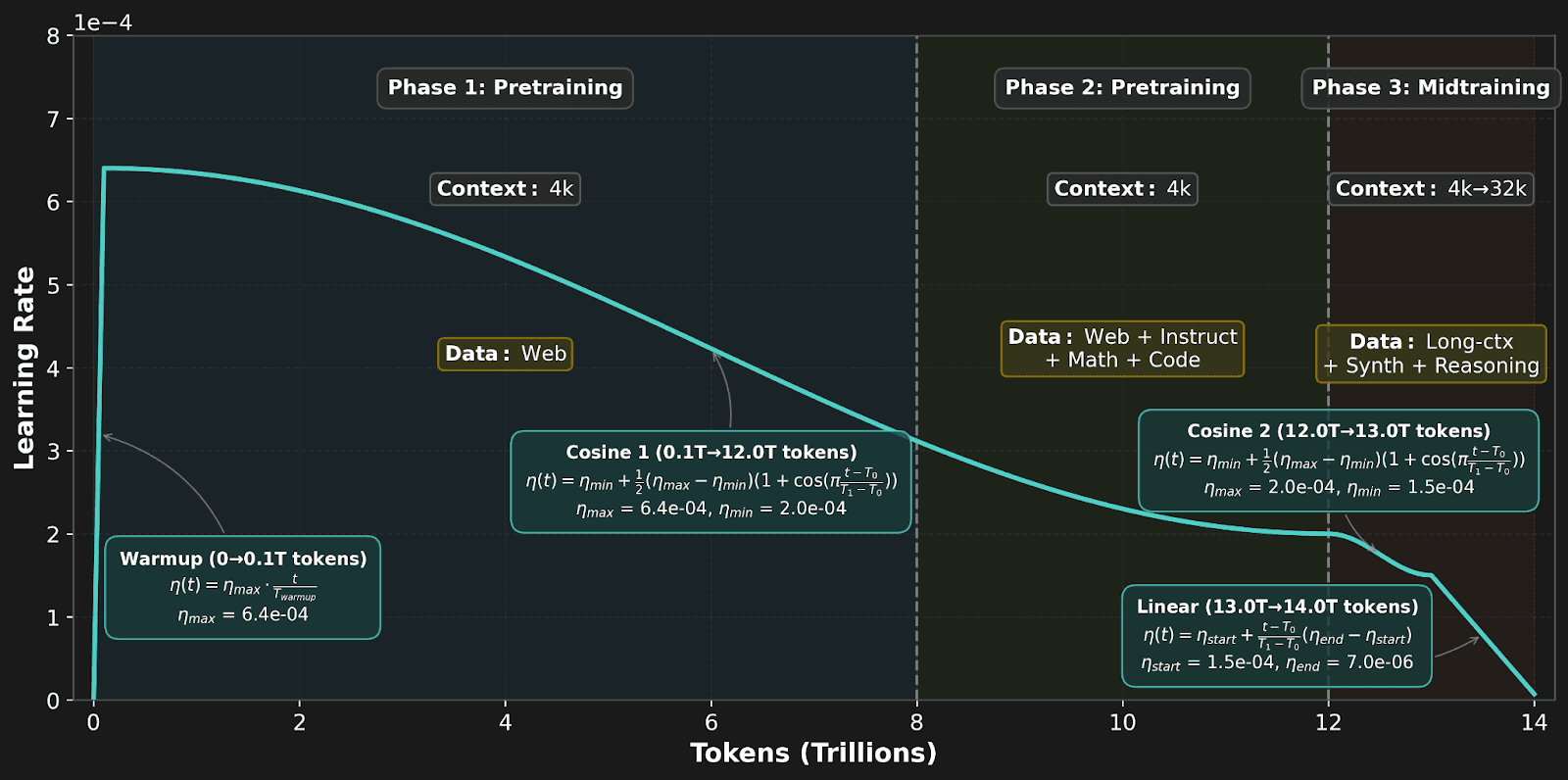
The ZAYA1-base model also showcases some of our architectural innovations that we have developed internally at Zyphra, aiming to improve the FLOP and parameter efficiency of training. These include substantial improvements to the fundamental components of a MoE transformer – attention and the expert router.
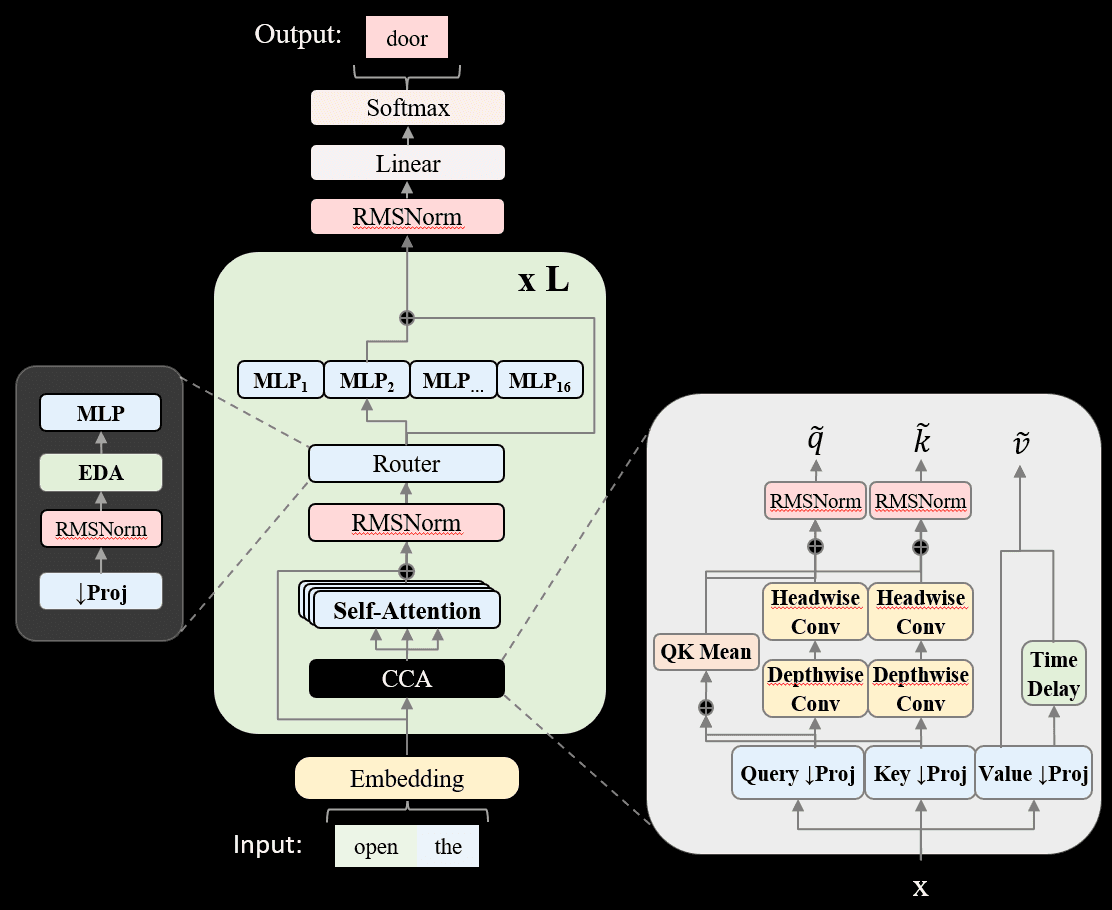
For attention, ZAYA1 uses our recently published CCA attention, which utilizes convolutions within the attention block itself to perform the full attention operation within a compressed latent space. CCA achieves a substantial reduction in attention FLOPs for prefill and training, and achieves better perplexity, while also matching existing state of the art methods in KV cache compression.
ZAYA1 also makes fundamental improvements to the linear router used in almost all existing large-scale MoE models. We discover that improving the expressiveness of the router substantially improves performance of the overall MoE model, as well as changing the routing dynamics and encouraging greater expert specialization. Our novel ZAYA1 router replaces the linear router with a downprojection and then performs multiple sequential MLP operations within the compressed latent space to obtain the final routing choices.
Together, these architectural innovations reduce the fundamental compute and memory bottlenecks of attention and also improve the expressiveness of routing. They pave the way for further advancements to unlock true long term memory, and the ability for models to dynamically adapt compute and memory to the task at hand.
We look forward to releasing further details of our experience training on AMD and benchmarks for the ZAYA1 post-trained models.
The Zyphra AMD Cluster
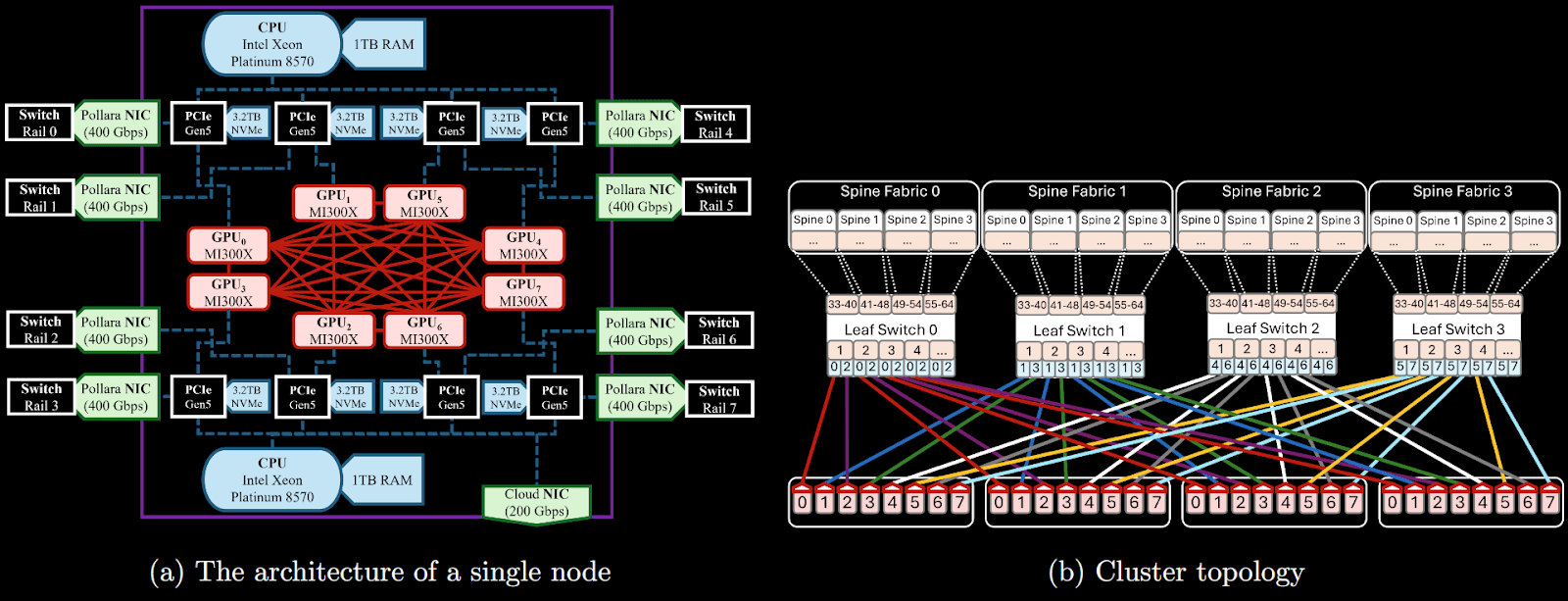
The Zyphra training cluster, built in partnership with IBM, delivers over 750 PFLOPs of real-world training performance. There are 128 nodes, each containing 8 AMD MI300X GPUs connected together with AMD InfinityFabric (see above figure). Each GPU has a dedicated AMD Pollara 400Gbps interconnect, and nodes are connected together in a rails-only topology.
Not only was an AMD-native model training framework developed, but the unique model architecture of ZAYA1 required significant co-design to enable rapid end-to-end training. Such co-design included custom kernels, parallelism schemes, and model sizing. See the accompanying technical report for details on optimization, in addition to often-overlooked aspects of training at scale such as fault tolerance, and checkpointing.