A New Standard in SOTA Embeddings
👉 TL;DR:
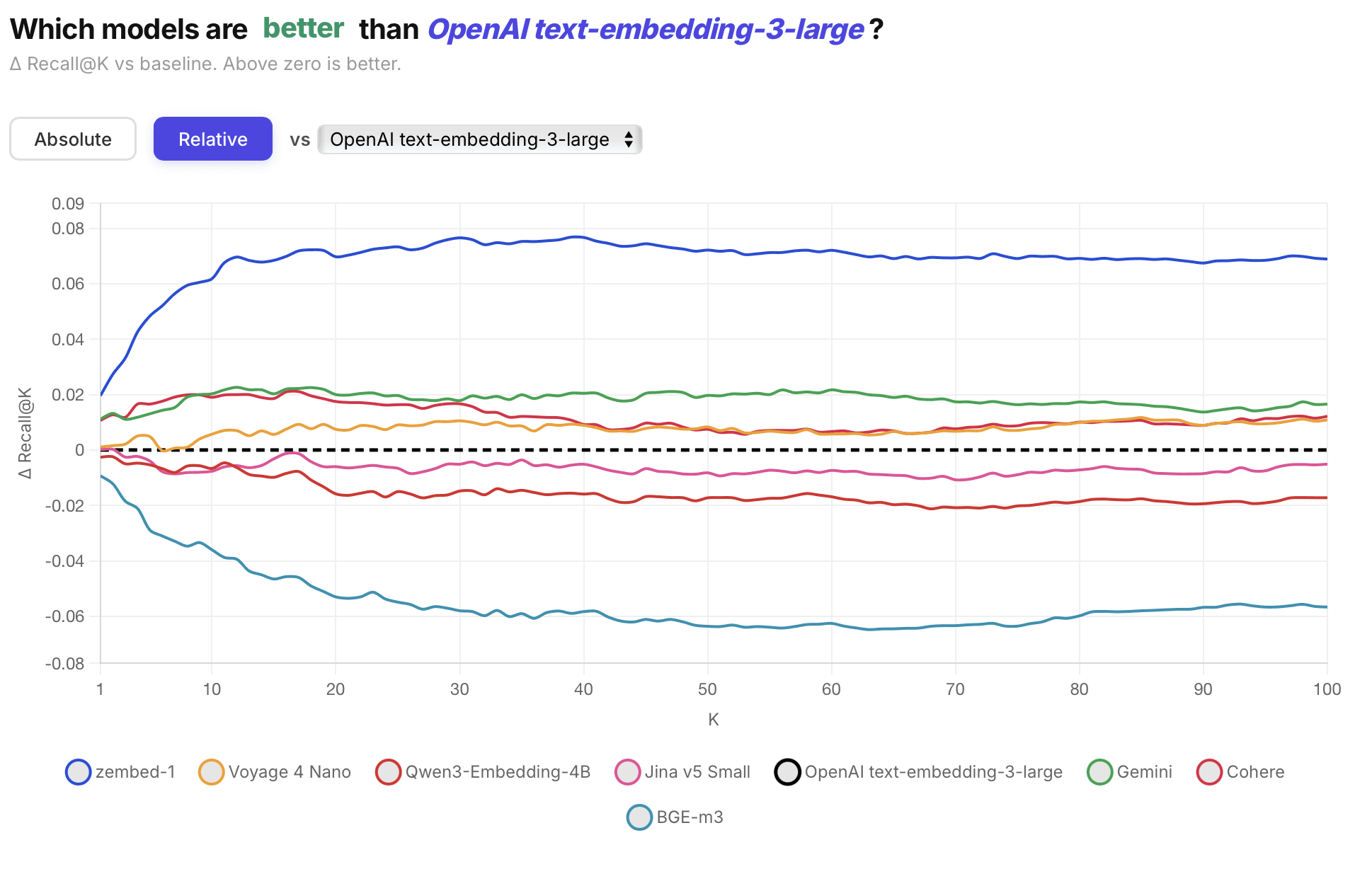
Today, ZeroEntropy is launching the world's most accurate embedding model, which outperforms all other embedding models by up to +7% on Recall@100, including OpenAI Large, Qwen3 4B, BGE-M3, Gemini Embeddings, Cohere v4, and Voyage-4-nano.
zembed-1 is a 4B open-weight multilingual embedding model distilled directly from our own state-of-the-art reranker zerank-2.
zembed-1 is available now through the ZeroEntropy search engine, our API, HuggingFace, and AWS Marketplace.
🎉 We are offering 50% off on document embeddings until June 1st!
State-of-the-Art Accuracy Across Verticals
zembed-1 delivers the highest retrieval accuracy of any embedding model available today. Across a broad evaluation spanning private and public benchmarks, zembed-1 outperforms every model we tested — and when paired with our reranker zerank-2, the gap widens further.
The gains hold across verticals. zembed-1 shows particularly strong performance on finance, healthcare, and legal, where specialized domain vocabulary and nuanced relevance ranking matter most.
Accuracy, Latency, Affordability: Pick Three
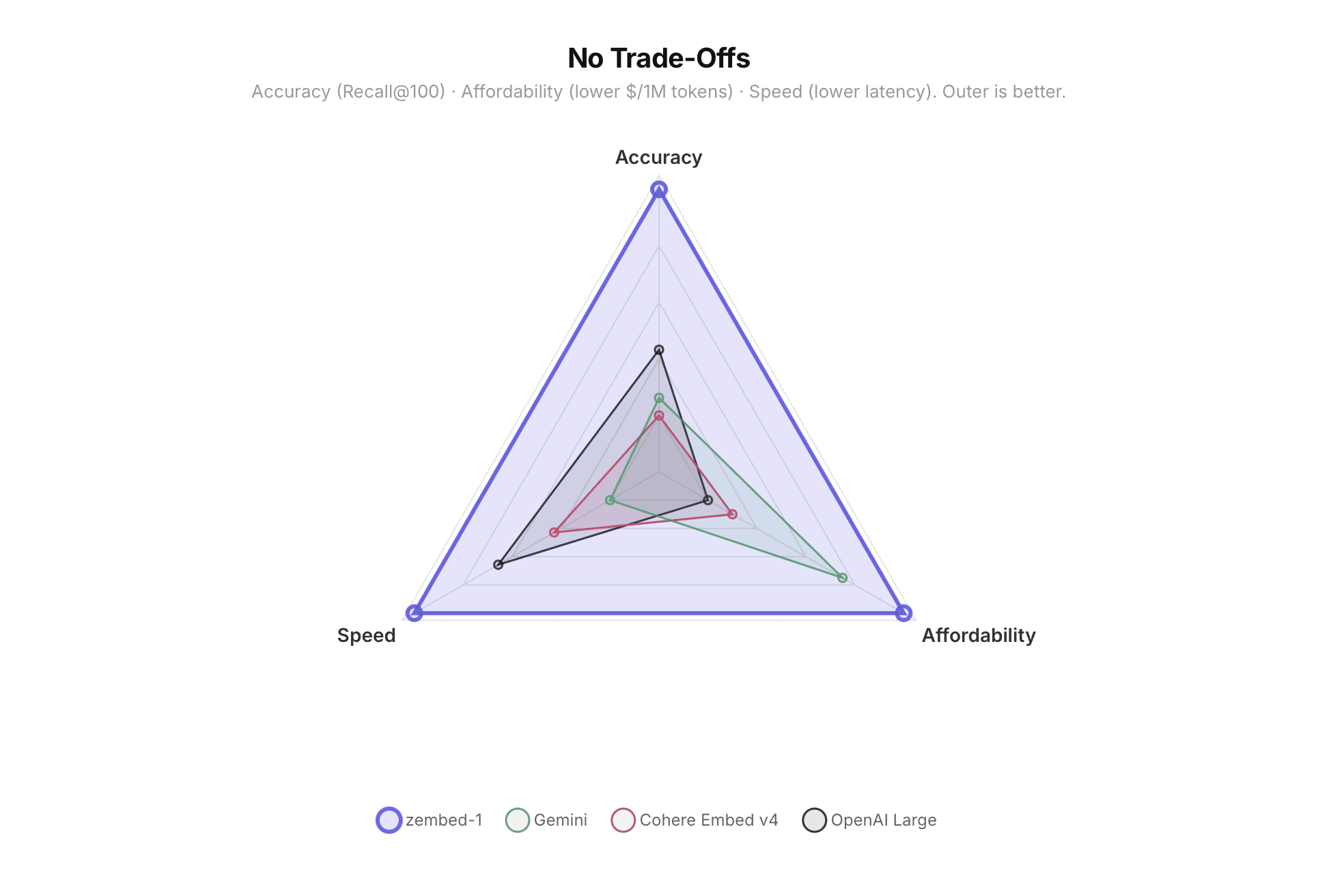
Most embedding models force a trade-off between accuracy, speed, and cost. zembed-1 doesn't.
We invested heavily in performance engineering, quantization, and dimensional flexibility — three levers that let you tune the accuracy-cost trade-off at inference time, without retraining. Quantization compresses each dimension from 32-bit floats down to 8-bit integers or single-bit binary, cutting storage per vector by 4× or 32×. Flexible dimensionality lets you truncate embeddings from the full 2048 dimensions down to as few as 40, discarding the least informative components while preserving the most. Combine both, and you can shrink a vector from 8 KB to under 128 bytes — with a controlled, predictable accuracy trade-off at every step.
Detailed Evals: Multilingual and Vertical Breakdown
Zembed's accuracy advantage isn't limited to English or general benchmarks. Here's how our model compares across verticals and languages against the full competitive field.
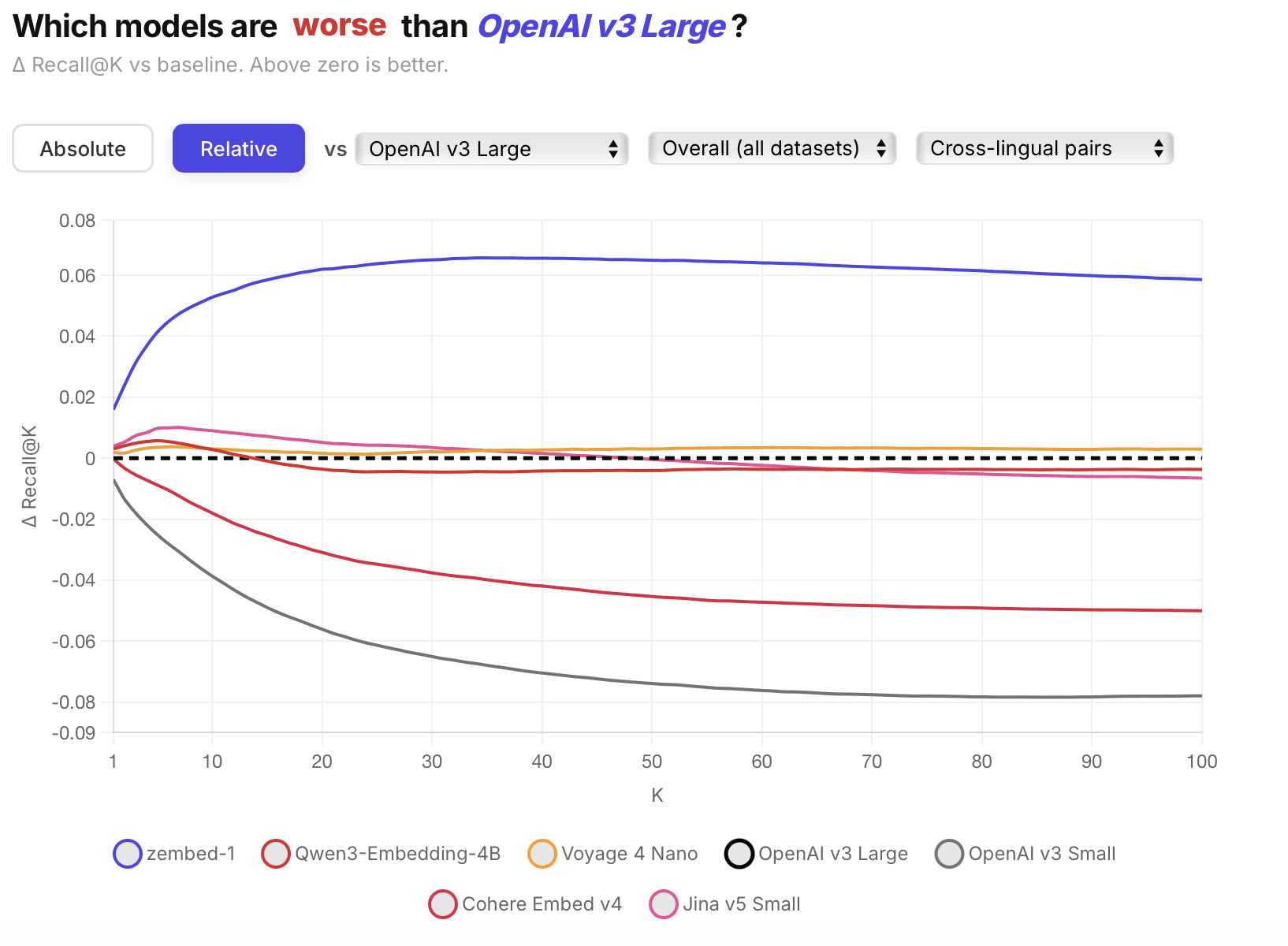
zembed-1 is multilingual from the ground up. Over half of the training data used to create zembed-1 was in languages other than English. With our focus on well-calibrated cross-lingual query-document pairs, you get exactly the same Elo-trained relevance judgement whether the query is in English, Japanese, Arabic, or any other major language.
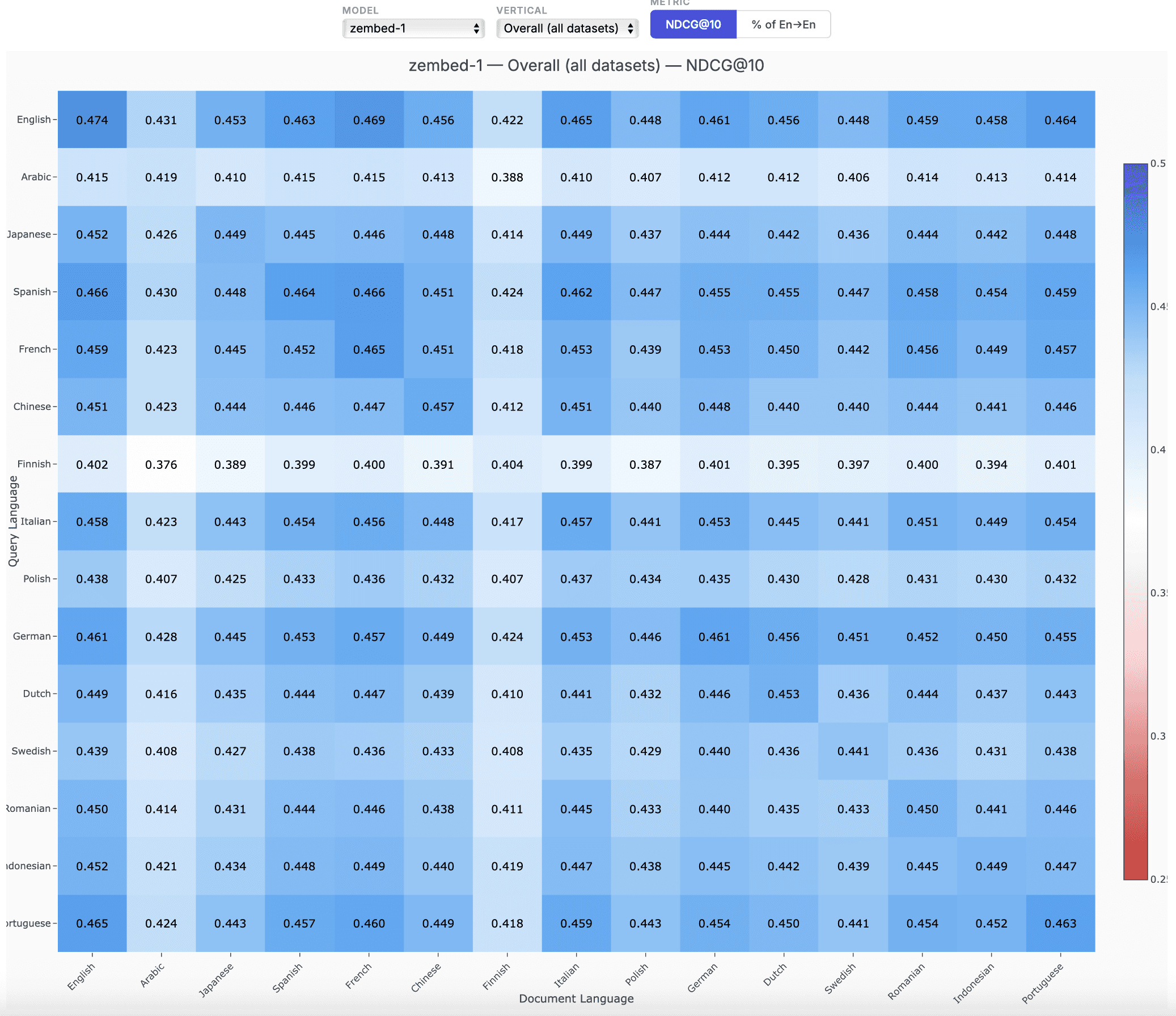
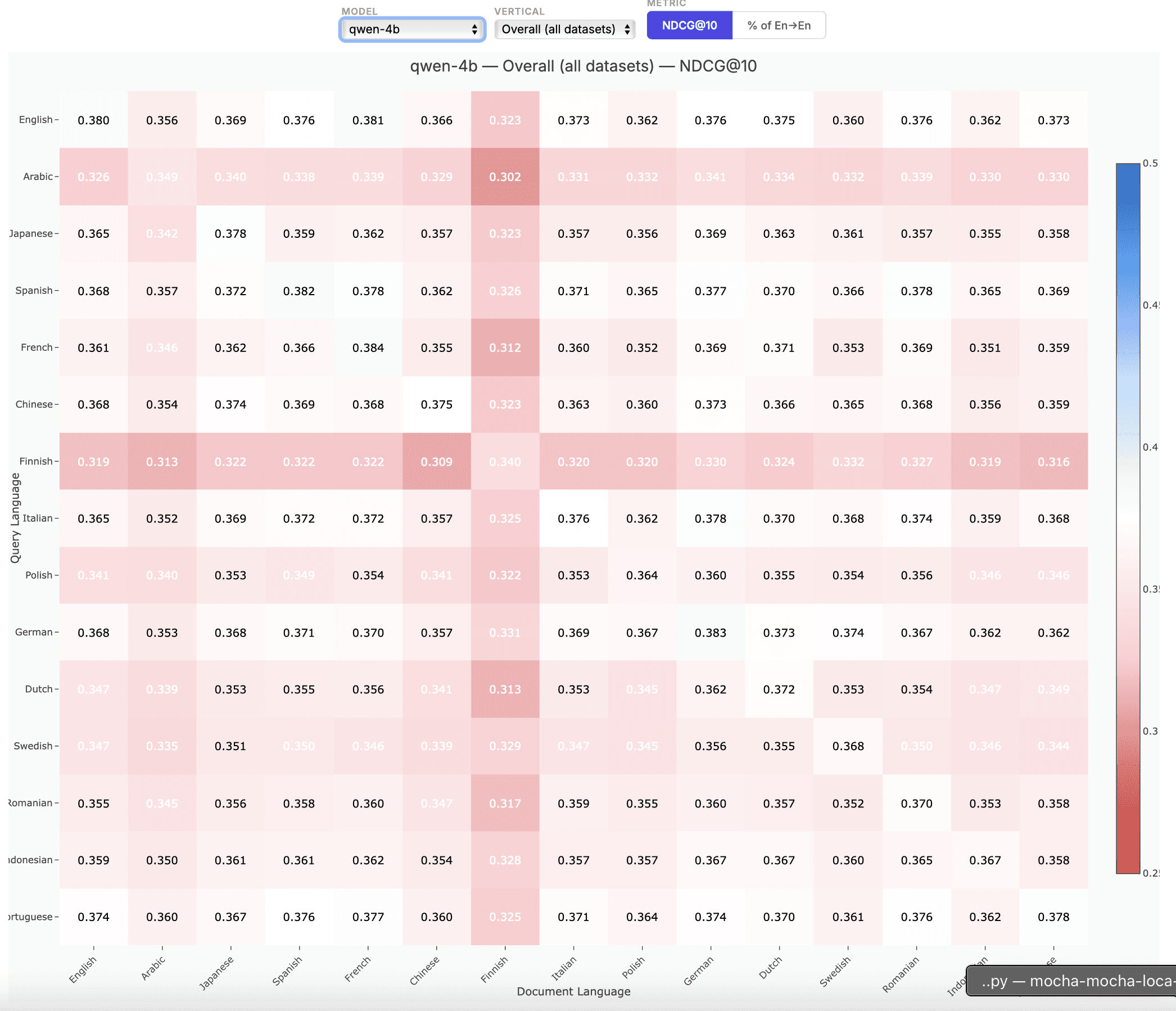
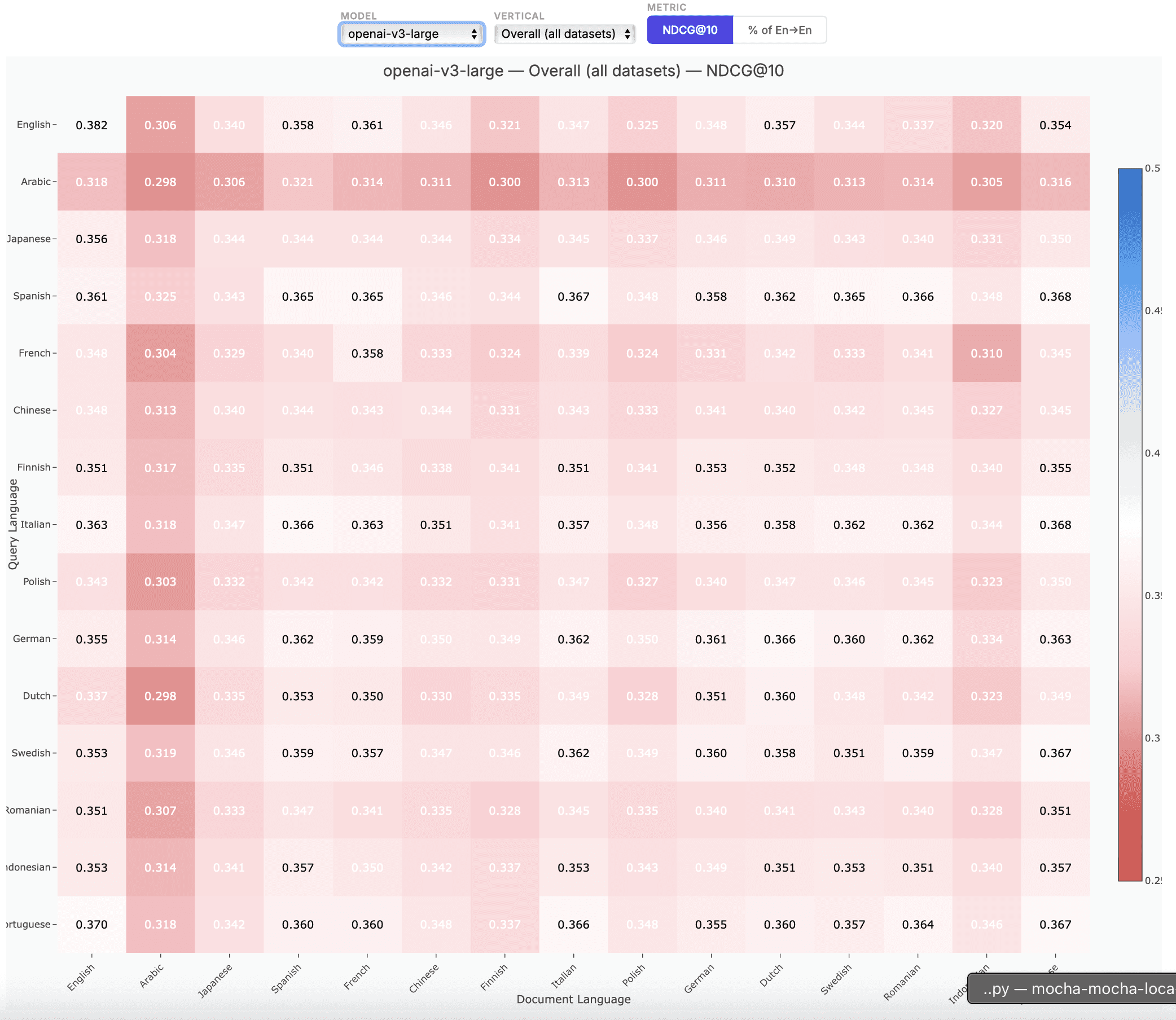
For full evaluation results across all datasets and configurations, see the detailed spreadsheet here.
What Model Configuration is Best for Me?
zembed-1 gives you two knobs to tune at inference time — no retraining required:
Dimensions (40 → 2056): You can truncate embeddings from the full 1024 dimensions down to as few as 40. Unlike Matryoshka-style training, we use a cheap client-side linear transformation that preserves more information at every dimension count — so you get better accuracy at the same storage cost.
Quantization (float32 / int8 / binary): Each dimension can be stored as a 32-bit float, compressed to an 8-bit integer (4× smaller), or reduced to a single bit (32× smaller). At full dimensions with float32, a single vector is 4 KB. At 256 dimensions with int8, it's just 256 bytes — with minimal accuracy loss.
For a full guide covering trade-offs and considerations when picking an embedding model, check out our latest blog here.
How We Trained zembed-1
Most embedding models are trained on binary signals: a document is either relevant or not relevant. For zembed-1, we took a fundamentally different approach by distilling zembed-1 from our state-of-the-art reranker, zerank-2.
What makes zerank-2 — and by extension zembed-1 — particularly good at correctly ordering and retrieving information is our signature zELO methodology. For each query, all candidate documents compete in pairwise battles and are assigned a continuous Elo score from 0 to 1 that represents their absolute relevance.
By distilling this signal into the model, zembed-1 inherits a relevance intuition that no standard contrastive training can match. This innovation unlocks disruptive accuracy gains, across verticals, and languages.
Get started
zembed-1 is available today with a context window of 32k tokens through multiple deployment options:
→ ZeroEntropy API: fully managed, lowest-friction path to production
→ HuggingFace: open weights, run it on your own infrastructure
→ AWS Marketplace: deploy within your existing AWS environment
Documentation: docs.zeroentropy.dev
HuggingFace: huggingface.co/zeroentropy
Get in touch: Discord community or contact@zeroentropy.dev
Talk to us if you need a custom deployment, volume pricing, or want to see how zembed-1 + zerank-2 performs on your data.