adamw is as of 2025 the most used optimizer to train deep neural network
adamw is momentum based though

empirically momentum based optimizer tend to favor few update directions over the rest
update matrix look suspiciously low-rank
it’s like trying to roll a boat down the cost plane

muon’s contributor thinks that if we could dampen these directions and boost rarer ones it would lead to better convergence
kinda bringing the boat back to ball shape
muon’s contributor says that if we run svd on momentum update matrix and throw away the singular value then we get roughly unit vector length in all directions
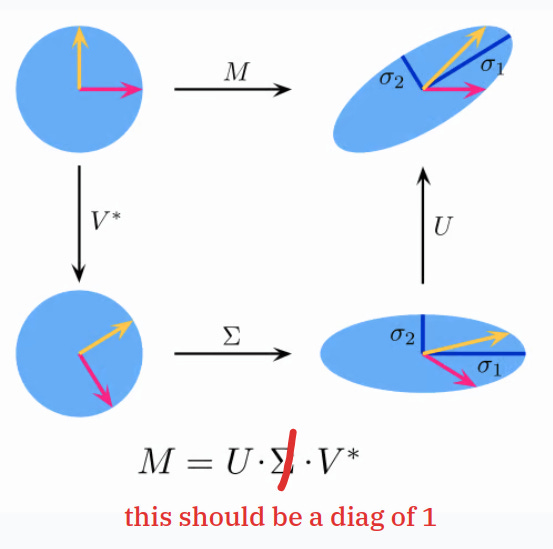
can’t run a svd on each update step though too costly
we don’t have to be that precise so we can look at faster iterative algorithms
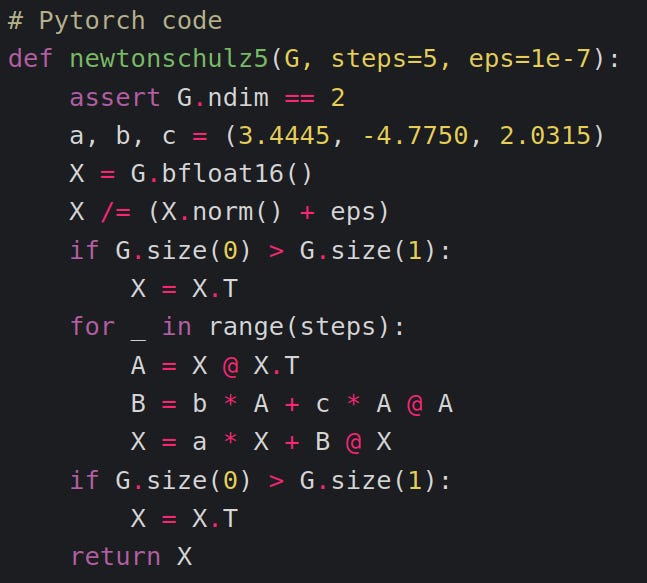
newtonschulz is one such algorithm
basically if you take an odd-matrix polynomial and apply it to a matrix it’s like applying it straight to the singular values while U and V.T are left unchanged
would be neat to apply the sign function to the singular value because then we would just have 1s on that diagonal
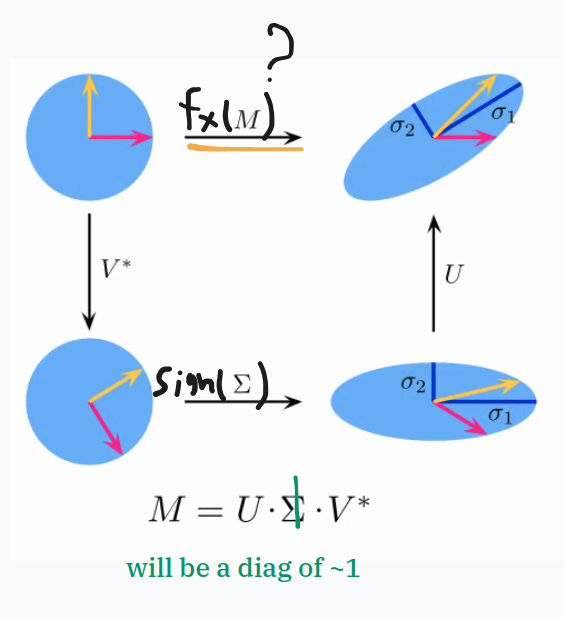
cant use sign because it’s not a polynomial even though it’s odd
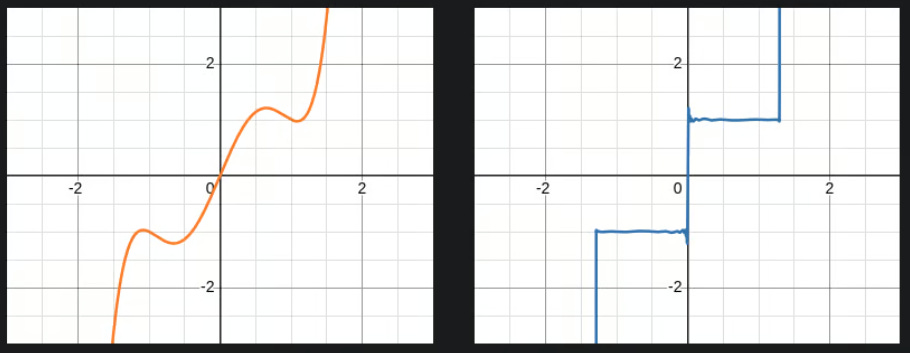
we can approximate the sign function though with cubic/quintic polynomial if we apply the function multiple times on itself (not well but close enough around [-1,1])
5 iterations (or steps) are good enough
if we normalize the update matrix between [0,1] we are always sure that the approximation is sign-like and gives us a 1 out
actually, empirically, we don’t even need to be at 1 straight, if we are at [0.7,1.3], that’s good enough
the cursed quintic gives us one ugly-looking sign function but has all the right characteristics + it’s fast
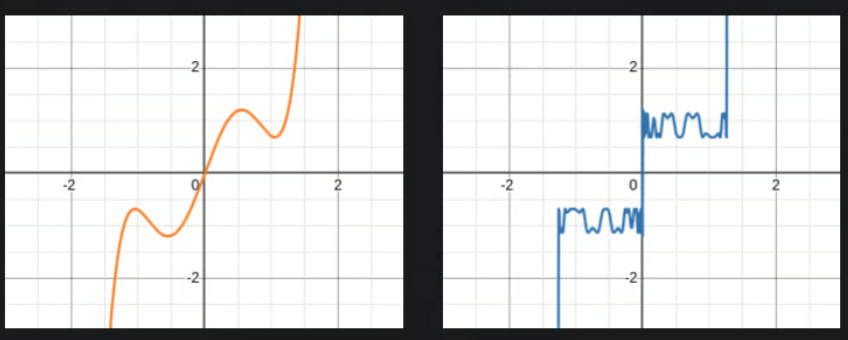
it’s parameter are `a, b, c = (3.4445, -4.7750, 2.0315)`
that’s muon

ps:
nesterov better than sgd-momentum
muon only work on 2d hidden dense linear layer
so no bias and no embedding
convolutional filters are good you just need to put them back in 2d
also empirically first and last layers should use adamw
32 min step-by-step breakdown here:
big shout out to SJ and Adrian for supporting the content!
also
more paper for deepdive:
📌 overview: https://rixhabh.notion.site/Muon-2302d1eca8f6801c88e3f80e43c316da?pvs=74
📌 Keller blog: https://kellerjordan.github.io/posts/muon/
📌 Jeremy blog: https://jeremybernste.in/writing/deriving-muon
📌 newtonschulz overview: https://docs.modula.systems/algorithms/newton-schulz/