I had the privilege to speak at the recent AI-by-the-Bay Conference in Oakland, CA, on the topic of how Artificial Intelligence (AI) and real-time data streaming systems are converging in their evolution and application to enterprise-scale systems. This talk was not a “vendor pitch,” but an exploration of the state of the industry today—a brief look back at recent years, and my views of the trajectory we’re all headed in.
To go more in-depth into topics I could only gloss over in a few minutes during the live session, this blog series is divided into four parts:
- Part 1: The coming brick walls (this post)
- Part 2: Adaptive strategies for LLMs and applications development
- Part 3: AI observability and evaluation
- Part 4: Real-time streaming & AI
Buckle up! This is going to be quite a ride. In this first part, I’ll lay out the juggernaut that is the AI industry since the advent of the transformer model kicked it into high gear, and point out how it’s basically batch trained. Over time, I’ll show how this batch-oriented thinking leads to inherent systemic limits and how, increasingly, real-time data enrichment and streaming are needed to take the AI industry to new levels of capabilities.
(Note: this blog includes some updates and a gentle correction or two in feedback, so you can watch the full video below, but keep reading to see what’s new since I gave the talk!)
Watch on-demand on YouTube
Preamble: the d20 Test
In the age of AI, everyone seems to have their own AI evaluation tool, and the “d20 test” is mine. For the unaware, a “d20” is a twenty-sided die most often associated with tabletop roleplaying games (TTRPGs) like Dungeons & Dragons®.
Prompt: Draw a photorealistic d20 with a 20 on the top face, which is the face opposite from and parallel to the surface the die is resting on. Make sure every other face of the die has one and only one number in the range of 1 to 19, and no number in that sequence occurs more than once.
This is a deceptively simple but sophisticated test for the following:
- Geometry: Did it successfully draw an icosahedron (a Platonic solid comprised of 20 equilateral triangles)?
- Topology/preposition: Did it successfully draw the 20 “on top?” Or did it put it on the “front” face—the one directly facing the viewer?
- Number sequence: Did it successfully draw numbers within a range of 1-20, with no numerical value repeating?
- Numbers: Did it actually successfully draw Arabic numeric values, or did it create non-numeric, even nonsensical glyphs?
Here’s an example using ChatGPT 5.1:

Hilarity ensues when you run it, and I encourage you to all try it and post your results on LinkedIn. (Tag me in your posts!)
To date, only Gemini 3.0 Thinking has accomplished it successfully (the week after I gave the talk!), but not consistently. Gemini / Nano Banana Pro failed a more recent run. Google Veo also failed to produce a realistic video. Yet Gemini 3.0 is markedly better than Gemini 2.5 Pro (another run here and here); at least 3.0 now consistently creates icosahedrons.
ChatGPT also keeps repeatedly failing; generally messing up on duplicate numbers.
Midjourney also fails—but creatively!
Meta AI also fails repeatedly.
Grok fails a lot, I mean a lot. It is the worst.
Claude, poor thing, is limited to SVG graphics, and it does a miserable job.
Suffice it to say, there’s still a long way to go before AI masters the basic physics of magical math rocks. And, while this seems like a trivial test, I treat it as a sober conversation opener:
“If we can't even get an AI to draw a realistic d20, why would we 'roll the dice' and spend a million dollars a year or more on it?”
Collectively, humankind spent $1.5 trillion on AI in 2025 alone. I can just take out my mobile phone and take a picture of a d20 with a 20 on top. It’d cost me zero tokens and actually solves the problem.
For now, let’s leave the d20 test there as a bookmark. It’s not the only problem AI faces.
The convergence of data science and data engineering
AI and data streaming are all too often worlds apart. The data scientists working on AI and the platform, and data engineers working on data streaming technologies, typically live on separate ends of the business campus.
The world of AI is based on batch data training and often unstructured documents.
The world of data streaming is tied more to structured data and databases.
If you’re interested in breaking down the social and organizational silos in your own business, check out the book Data Teams by Jesse Anderson.
So, how do we cross the [data] streams with AI without “all life as you know it stopping instantaneously and every molecule in your body exploding at the speed of light,” as Egon Spengler warned us?
Let’s look at how we ended up in our current situation.
Transformer models broke onto the scene in 2017 and have since grown by orders of magnitude. GPT-1 “only” had 117 million parameters. It’s now estimated GPT 5/5.1 could grow anywhere upwards of 50 trillion parameters and 400,000 token context windows.
That’s five orders of magnitude larger in eight years.
To achieve that scale, they broke the model apart, creating what’s known as a Mixture of Experts (MoE): a large number of parallel models with a router in front of them. For example, it was leaked by George Hotz (geohotz) in 2023 that OpenAI’s GPT-4 was actually not a single 1.76 trillion parameter model, but 8 × 220 billion parameter models running in parallel. We can presume something similar is true of GPT-5 and 5.1.
We also know Google Gemini has been an MoE since 1.5; xAI Grok has been an MoE since Grok-1. However, Anthropic Claude remains a single model, known as a Dense Transformer.
Yet, regardless of their dense or MoE architectures, they’re still all batch trained.

However, a bigger model doesn’t always mean better results. They realized that going up to or even beyond 1,536 vector embedding dimensions can have diminishing returns. GPT-5.1 actually produced slightly worse results than GPT-5.0 on some recent evaluations. Plus, we’ve seen that models can actually degrade in performance with usage over time, even over the span of a few months.
To maintain accuracy, AI models need to be periodically recalibrated. Unlike an API, if you fire it up and it works in January, it should still work in June, and provide the same, correct answer each time. With LLMs, each answer is a special snowflake, and those snowflakes can melt over time.
The coming brick walls for AI
There are actually a number of them. To be brief, let’s consider three:
1. Limitations in “ethically-sourced” public data
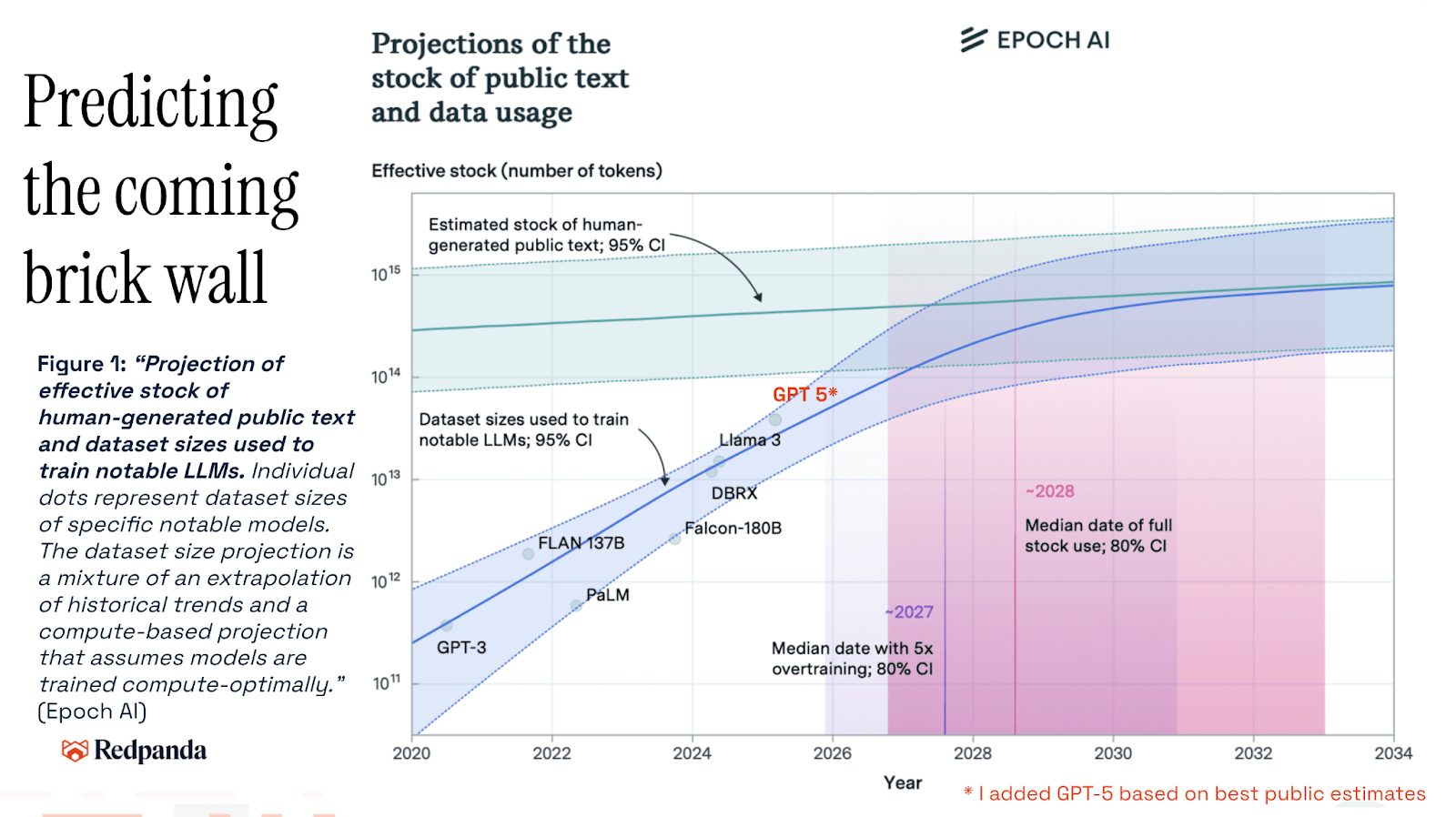
Epoch AI did an analysis in 2024, and I updated their graphic by plotting the best estimate of where we are with ChatGPT 5.x. Simply put: frontier AI models are running out of public data to train against.
This means that AI is facing a brick wall problem. That there’s a top to the S-curve, at least in terms of public training data. However, those who know their orders of magnitude will notice something in the chart above: it’s talking about data on orders of magnitude of petabytes (1015). Yet just one mobile network, AT&T, sent more than one exabyte (1018) of data in 2025.
Now, all data generated and stored around the world is measured in zettabytes (1021), and this requires a complete rethink of how to deal with data at massive scale. Transformer models are one method, of many, to sift through, process, analyze, and use data at that scale.
By the end of 2025, we generated an estimated 180 zettabytes in just one year and stored more than 200 zettabytes of total data globally. If those estimates are accurate and my math is correct, from 2016 to 2025, that’s a CAGR of 78%.
Presuming that explosive growth holds up, we’ll be entering the Yottabyte Era sometime this decade, maybe as soon as 2028 and probably by 2030. We might even hit the Ronnabyte Era (1024) by the 2040s. Then again, I believe in S-curves. So expect to hit some level of diminishing returns regarding raw data generation as well.
Nonetheless, the vast majority of these oceans of data is currently in private hands. Corporate IIoT systems, banking systems, and cybersecurity systems. But moreover, your phone. Your kid’s phone. Your camera doorbell (and the corporate systems that store its raw video).
This is where the AI systems want to go next: from publicly scrapable data to the vast oceans of private data reservoirs. This is where the war of the frontier AIs is being fought. We already have multiple parties, from individual creators and coders to small publishers, large companies and consortia pushing back and suing, everywhere, all over the place on the unauthorized use of their copyrighted material. There are even AI lawsuit case trackers you can follow like a new sports league.
And this is just on the misuse of publicly-available copyright data. Now imagine it has access to your private corporate data. To your company's confidential information and trade secrets. There’s a desperate need to recognize “ethically-sourced” public data to train against. And even if it is ethically sourced, that does not prevent it from being used with nefarious intent.
Regardless of your stance on the ethics of such data hoovering, it doesn’t fix fundamental issues with transformer models like hallucinations. It doesn’t fix human factors issues of poisoning, slop, or misuse. It only exacerbates the enormous cost of running them.
2. Inefficiency: costly, large, slow to pre-train base models
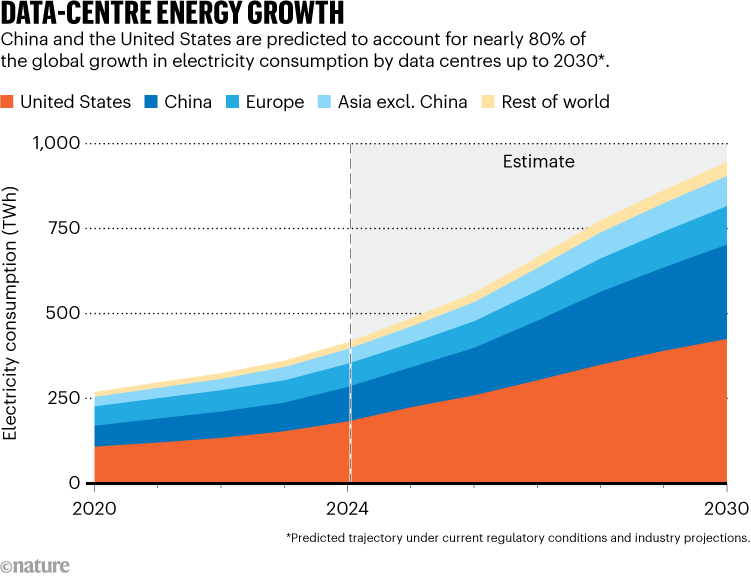
Energy intensity is a known problem with the current transformer models. Energy usage is driven up-front by the size, scale, and cost of just training—before even a single query is made against them. Epoch AI predicts that training frontier models will cost over a billion dollars by 2027. Just imagine the power requirements behind that investment. Any free queries by consumers further serve as an additional cost center and as an additional draw from power grids.
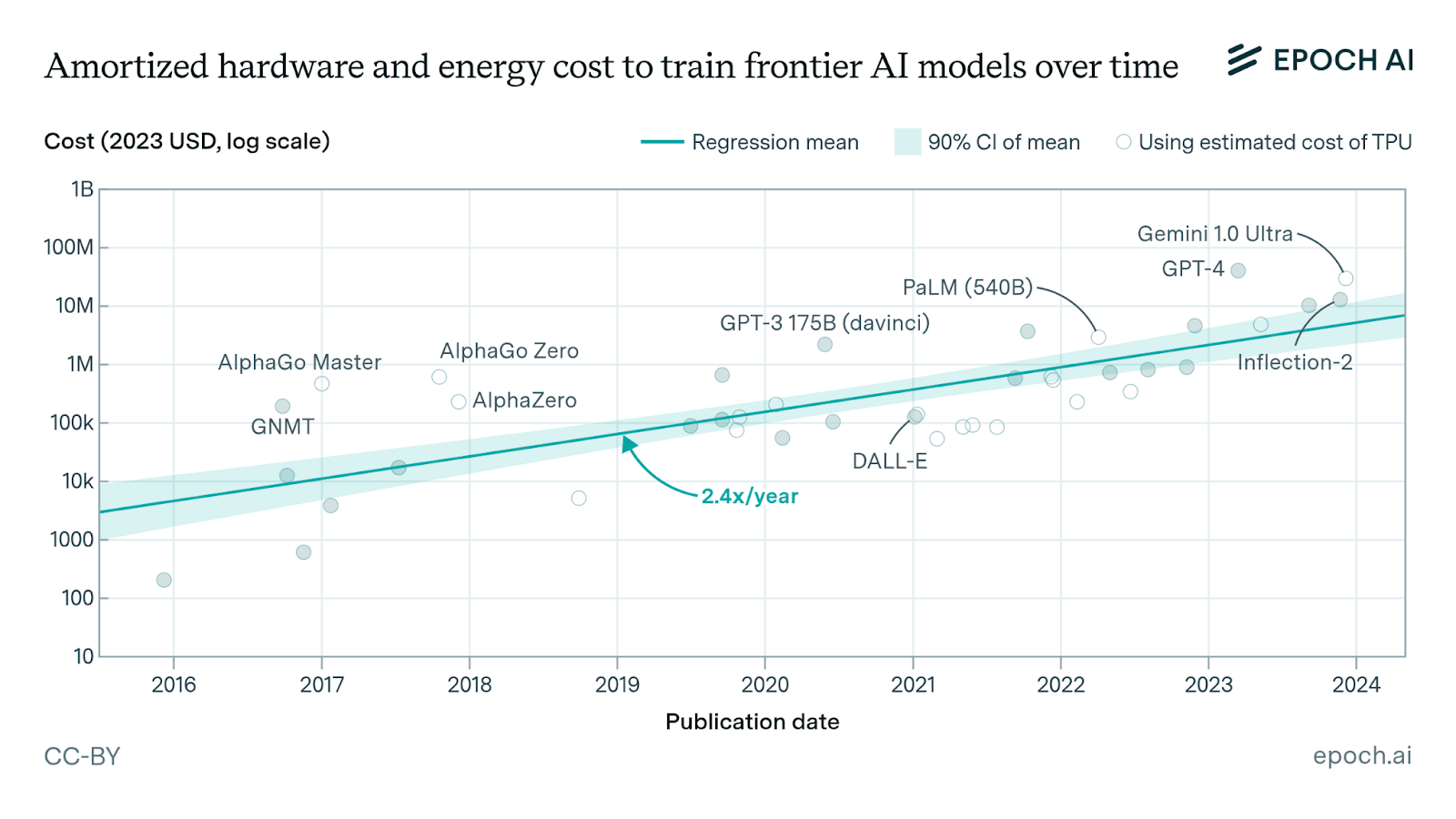
A naive glance at this chart might just see a straight line, but a consideration of the Y-axis shows the cost to train AI models is actually growing around 260% annually. While this isn’t a hard brick wall, it’ll be governed by the Law of Diminishing Returns.
At some point, we’ll reach a state where, even if we could technically continue to grow a model, it might be simply infeasible economically, as well as producing a computationally negligible return on investment.
It would also result in the end of unparalleled growth and herald the coming plateau of an S-curve. However, if efficiencies in training can be found—bringing down training costs and power requirements—then we can extend the duration of this growth curve.
3. Limited capabilities for real-time training/re-training
As I said before, frontier models are still all batch-trained. While they can increasingly access and reason upon data presented in real time, such as scouring social media video and the latest posts and newsfeeds, or accessing a database in a RAG or MCP architecture, this is at inference time.
Their extensive pre-training and much of their fine-tuning, such as Reinforced Learning from Human Feedback (RLHF), is still inherently offline, batch-mode oriented. RLHF also has numerous limitations; some are tractable, others are fundamental and inherent to it, including misalignment and safety
In the meantime, you can watch my full talk from AI-by-the-Bay on YouTube. If you want to chat about this series, find me in the Redpanda Community on Slack.
Up next: adaptive strategies and beyond
The next chapter of this series will deal with the adaptive strategies being employed to try to avoid, obviate, or obliterate these known brick walls, both within the AI models themselves, as well as on the applications development front.
Note that even then, we’ll only touch on data streaming as a technology. For now, most of the work being done on these adaptive strategies is still well entrenched in batch-oriented thinking.
In the chapters beyond that, I’ll showcase how data streaming plays a central role in AI evaluation and observability—as well as in unlocking the future of enterprise AI architectures—to combine real-time data signals with the power of transformer-model-based AI systems.
Sources
“Attention Is All You Need” & other LLM resources
- Attention is All You Need, Vaswani, et al., Google
(Jun 2017): https://arxiv.org/abs/1706.03762 - Transformers, the tech behind LLMs | Deep Learning Chapter 5
3Blue1Brown (April 2024): https://www.youtube.com/watch?v=wjZofJX0v4M - A History of Large Language Models Gregory Gunderson, October 2025: https://gregorygundersen.com/blog/2025/10/01/large-language-models/
- Train Your LLM Better & Faster - Batch Size vs Sequence Length Vuk Rosić (October 2025):
https://www.youtube.com/watch?v=bu5dhaLmr7E - GPT 5.1 - The AI Update Nobody Expected…
The AIGrid (14 Nov 2025): https://www.youtube.com/watch?v=0dLfE_ek-WM - Artificial Analysis Intelligence Index Artificial Analysis: https://artificialanalysis.ai/evaluations/artificial-analysis-intelligence-index
“The Coming Plateau” resources
- The Coming Plateau of AI ModelScaling–An Opportunity for AI Innovation Tensility Venture Partners (Jan 2025): https://www.tensilityvc.com/insights/the-coming-plateau-of-ai-modelscalingan-opportunity-for-ai-innovation
- Will we run out of data? Limits of LLM scaling based on human-generated data, Epoch AI (2024):
https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data - Can AI scaling continue through 2030?, Epoch AI (August 2024):
https://epoch.ai/blog/can-ai-scaling-continue-through-2030 - The World Will Store 200 Zettabytes Of Data By 2025 (Feb 2024):
https://cybersecurityventures.com/the-world-will-store-200-zettabytes-of-data-by-2025/ - Trade Secrecy Meets Generative AI, Camilla A. Hrdy (August 2025):
https://scholarship.kentlaw.iit.edu/cgi/viewcontent.cgi?article=4489&context=cklawreview - The LLM Plateau: Why Language Models Aren’t Getting Any Smarter and How GPT-5 Might Solve This, Ethan Brooks (2024): https://medium.com/@ethanbrooks42/the-llm-plateau-why-language-models-arent-getting-any-smarter-and-how-gpt-5-might-solve-this-571b9f4153ef
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback Caspar, et alia (2023): https://arxiv.org/abs/2307.15217
- How much does it cost to train frontier AI models? Epoch AI (June 2024) https://epoch.ai/blog/how-much-does-it-cost-to-train-frontier-ai-models