My last story about ChatGPT scraping Google and leaking prompts received a lot of attention, and I was especially pleased to see that OpenAI said that they’ve fixed the issue. So what was “the issue”, and what did they fix?
My research with Slobodan Manić on the topic showed two things:
- Some raw ChatGPT prompts were getting leaked into Google Search Console.
- OpenAI is scraping Google (otherwise how would #1 happen).
Lacking a more detailed confirmation from OpenAI, my assumption is that they fixed #1 (leaked full prompts), but #2 (scraping) continues.
I’ve now verified continued scraping with a simple experiment based upon the method described by Abhishek Iyer here and dating back to Google’s own sting against Bing in 2011.
- I created a fake website for a made-up company called “Ailinemint Intelligence”
- I submitted that website to Google Search Console only.
- A couple days later, I was able to find it in ChatGPT.
Here’s the receipts.
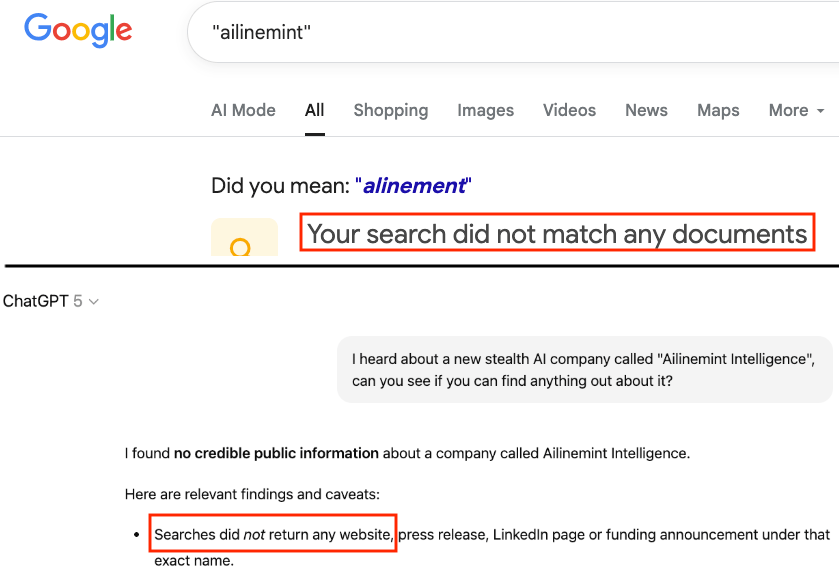
Before site creation, neither ChatGPT nor Google Search knows about it:
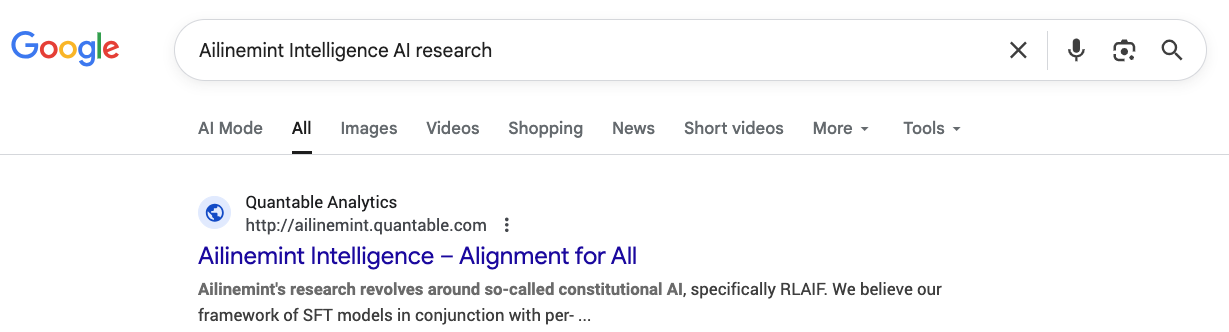
After creation and submission to GSC, a day or so later Google Search knows about it, but ChatGPT still doesn’t:
Then day after Google had indexed the page, ChatGPT suddenly knows about it (using a web search prompt)!
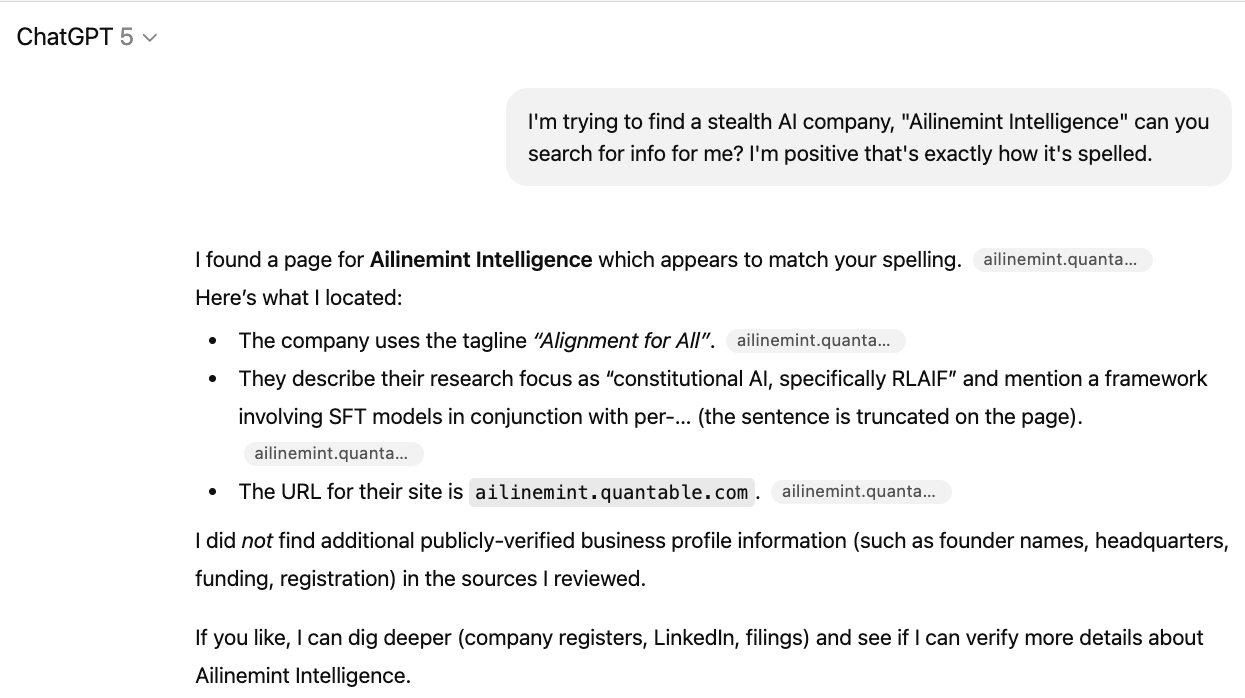
The public chat log is here: https://chatgpt.com/share/69129f36-a1fc-8001-a778-7575ea9ec6e9
(note I added the part about spelling the second time because in some attempts it kept wanting confirmation about spelling because it couldn’t find anything).
ChatGPT knows about the site, but still the only hits to the website have been from Googlebot. The raw web logs from the site (with no upstreaming caching/CDN) at the time of the screenshot above only had seen 3 IPs:

Those are the only 3 IPs that hit this site (::1 is the server itself, which I used to check the site to avoid leaking anything from my own browser or DNS), and all 3 verify as being Googlebot.
At this point, only Google Search knows about this site’s existence, and yet ChatGPT can still find it. If you’re still not 100% convinced, I’ve got still more evidence…
ChatGPT’s information on our test site is very limited, and its grounded knowledge matches a SERPs (search engine results page) snippet in length and content. In other words, the only information ChatGPT has is what they might have pulled from a Google Search. If they had spidered the whole page themselves they would have more.

All the accurate information that ChatGPT returns is limited to what’s in that SERP snippet.
This is the full text of the snippet from Google:
Ailinemint Intelligence - Alignment for All Ailinemint's research revolves around so-called constitutional AI, specifically RLAIF. We believe our framework of SFT models in conjunction with per-…
ChatGPT even thinks that “per-” is truncated, which is true in the snippet, but not true on the page itself (it says “per-organizational”). This is consistent with the assertion that all ChatGPT knows was from the scraped search results page. There are other searches that would have given different SERPs snippets, but I was able to recreate the same exact snippet very easily.
The limited information means ChatGPT is also giving incorrect information. For example, ChatGPT says there’s no information on headquarters, yet the full webpage does contain that information, while the snippet does not.
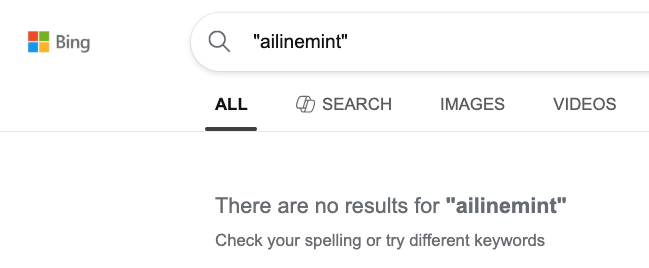
Bing remained clueless throughout (sorry Bing, but in this case that’s good).
Now, some details about methods and another interesting tidbit.
The method is pretty straightforward, but I had to take a lot of care to make sure nobody but Google ever saw this site. Generally when you create a new website or even a new page on existing your website there’s a lot of ways this could be discovered. New domains are discoverable info, your ISP or site host could be selling DNS information, your browser could be reporting URLs it visits, etc, etc.
The source of data that was new to me is that TLS cert creation isn’t private!
Eagle-eyed readers may have noticed that my fake company website is http://ailinemint.quantable.com and not https://ailinemint.quantable.com.
This is because there are data feeds available of all certs that are being created, via the Certificate Transparency Monitoring system.
Whether you generate your cert — whether it’s a free one via Let’s Encrypt or paid via GoDaddy, etc. — the domain name of the cert you create is public. All Certificate Authorities report this. In other words, if I created a certificate for ailinemint.quantable.com to allow me to serve the site over HTTPS, that would have allowed anyone watching that list to see the new domain created.
I found this out the hard way with an earlier iteration of this experiment (for a different fake name) where I generated a new cert and within 2 hours the OpenAI OAI-SearchBot was asking for my robots.txt from a Microsoft Azure IP. With Cloudflare Radar showing hundreds of millions of new certs being created monthly, this seems like a very noisy feed to be bothering to check, yet every time I tried it OAI-SearchBot was there within hours. A huge number of these certs are not new websites waiting to be crawled, but things like mail servers, API endpoints, CDNs, etc. I created a cert for api.quantable.com just to check if OAI-SearchBot would show up, and it did.
Despite its name, OAI-SearchBot did not try to crawl my new sites, it only requests their robots.txt. My guess is that it is doing this to know ahead of time if it can actually request something from that site in the future for an end-user if it’s needed.