Introduction
Stable Diffusion is a deep learning model which is seeing increasing use in the content creation space for its ability to generate and manipulate images using text prompts. Stable Diffusion is unique among creative workflows in that, while it is being used professionally, it lacks commercially-developed software. It is instead implemented in a variety of different open-source applications. Additionally, unlike similar text-to-image models, Stable Diffusion is often run locally on your system rather than being accessible with a cloud service.
Stable Diffusion can run on a midrange graphics card with at least 8 GB of VRAM but benefits significantly from powerful, modern cards with lots of VRAM. We have published our benchmark testing methodology for Stable Diffusion, and in this article, we will be looking at the performance of a large variety of Consumer GPUs from AMD and NVIDIA that were released over the last five years. If you are interested in the performance of Professional GPUs, we have also published an article covering over a dozen of those.
We want to point out that Tom’s Hardware also published their results in January for an even wider variety of consumer GPUs. However, we could not fully replicate their results, so the numbers we are showing are slightly different. We do not believe that this is due to any issue with testing methodology from each party but rather that Stable Diffusion is a constantly evolving set of tools. How it works today is very different than how it did even six months ago.

Below are the specifications for the cards tested:
| GPU | MSRP | VRAM | CUDA/Stream Processors | Base / Boost Clock | Power | Launch Date |
|---|---|---|---|---|---|---|
| RTX 3090 Ti | $2,000 | 24 GB | 10,752 | 1.56 / 1.86 GHz | 450 W | Jan. 2022 |
| RTX 4090 | $1,600 | 24 GB | 16,384 | 2.23 / 2.52 GHz | 450 W | Oct. 2022 |
| RTX 3090 | $1,500 | 24 GB | 10,496 | 1.395 / 1.695 GHz | 350 W | Sept. 2020 |
| RTX 4080 | $1,200 | 16 GB | 9,728 | 2.21 / 2.51 GHz | 320 W | Nov. 2022 |
| RTX 3080 Ti | $1,200 | 12 GB | 10,240 | 1.365 / 1.665 GHz | 350 W | June 2021 |
| RTX 2080 Ti | $1,000 | 11 GB | 4,352 | 1.35 / 1.545 GHz | 250 W | Sept. 2018 |
| Radeon RX 7900 XTX | $1,000 | 24 GB | 6,144 | 2.3 / 2.5 GHz | 355 W | Dec. 2022 |
| Radeon RX 6900 XT | $1,000 | 16 GB | 5,120 | 1.825 / 2.015 GHz | 300 W | Oct. 2020 |
| RTX 4070 Ti | $800 | 12 GB | 7,680 | 2.31 / 2.61 GHz | 285 W | Jan. 2023 |
| GTX 1080 Ti | $700 | 11 GB | 3,584 | 1.481 / 1.582 GHz | 250 W | March 2017 |
| RTX 4070 | $600 | 12 GB | 5,888 | 1.92 / 2.48 GHz | 200 W | April 2023 |
| RTX 4060 Ti (8GB) | $400 | 8 GB | 4,352 | 2.31 / 2.54 GHz | 160 W | May 2023 |
| RTX 3060 Ti | $400 | 8 GB | 4,864 | 1.41 / 1.67 GHz | 200 W | Dec. 2020 |
Test Setup
Test Platform
Benchmark Software
In order to test the performance in Stable Diffusion, we used one of our fastest platforms in the AMD Threadripper PRO 5975WX, although CPU should have minimal impact on results. All of our testing was done on the most recent drivers and BIOS versions using the “Pro” or “Studio” versions of the drivers. However, we found compatibility issues between SHARK and the AMD PRO 22.Q4, so testing was redone using AMD Adrenaline drivers instead. Following our test methodology, we used three different implementations of Stable Diffusion: Automatic 1111, SHARK, and our custom in-development benchmark and the prompts given in our methodology article.
It is important to note that our primary goal is to test the latest public releases of the most popular Stable Diffusion implementations. While many would consider these to be cutting-edge already, there are even newer things that could be implemented, such as updated CUDA and PyTorch versions. However, these are not always stable and are not yet integrated into the public releases of Automatic 1111 and SHARK. We want to focus on what end-users would most likely use for real-world, professional applications today, rather than testing right at the bleeding edge. However, We will note that our “PugetBench” version of Stable Diffusion uses the latest versions of CUDA and PyTorch (among others) at the time of this article.
We decided to test nearly every card from NVIDIA’s 4000 series of GPUs alongside the top-tier cards from their last three generations. We also included the 3060 Ti, which is currently the lowest-spec consumer GPU we offer in our product line. Additionally, we tested the Radeon RX 7900 XTX. Although we attempted to benchmark both the Radeon RX 580, we experienced compatibility issues and were not able to get results. It may have been possible to adjust the implementations to improve compatibility, but we wanted to run these tests as close to “stock” as possible.
Automatic 1111
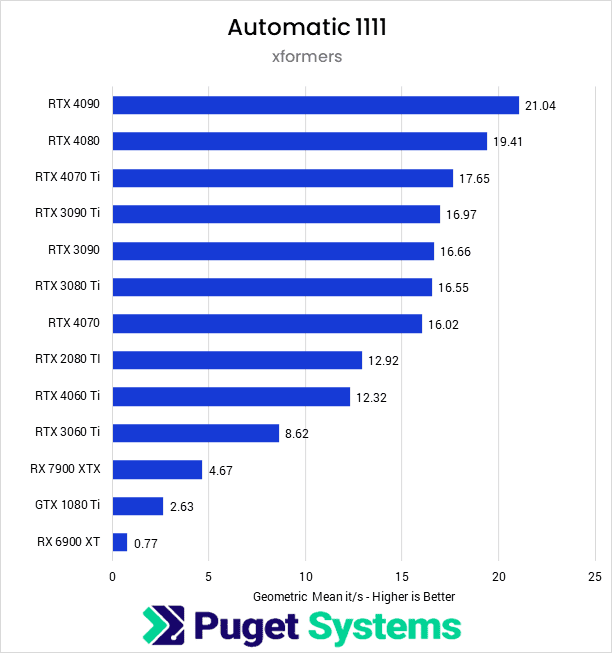
The implementation we benchmarked first was Automatic 1111, Stable Diffusion’s most commonly used implementation, which usually offers the best performance for NVIDIA cards. NVIDIA soundly outperforms AMD here, with only the GTX 1080 Ti having lower performance than the RX 7900 XTX and the RTX 3060 Ti having twice the iterations per second of the Radeon card.
While most cards perform about as you would expect based on their positioning in NVIDIAs product stack, we see that the newer 4000 series cards offer a clear advantage in image generation speed while also offering a relatively linear increase in performance with price. This is well illustrated by the RTX 4070 Ti, which is about 5% faster than the last-gen RTX 3090 Ti, and the RTX 4060 Ti, which is nearly 43% faster than the 3060 Ti. If you still have a card from the 2000 or 1000 series, even a mid-tier 4000 series card will be a noticeable upgrade in performance.
SHARK
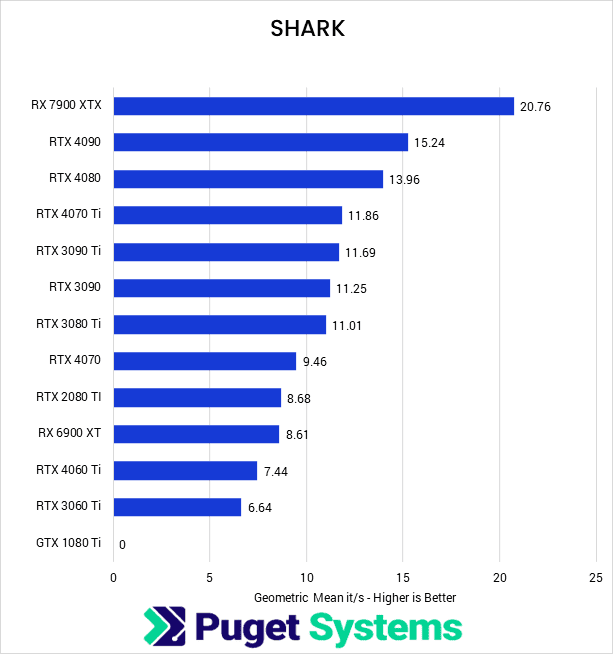
Although less commonly used than Automatic 1111, SHARK is the preferred Stable Diffusion implementation for many AMD users, and it is clear why. The RX 7900 XTX quadruples its performance over the Automatic 1111 implementation, resulting in iterations per second that nearly matches the RTX 4090 under 1111. Similarly, the RX 6900 XT has an even larger 1100% performance increase, although this only makes it competitive with the low-end NVIDIA GPUs we tested.
NVIDIA cards performed about 30% worse with SHARK than Automatic 1111, although they maintained the same relative performance. However, the GTX 1080 Ti could not run the SHARK implementation in our testing. It is important to use the proper implementation of Stable Diffusion as it can greatly impact the number of iterations per second a graphics card can achieve: from a 30% performance decrease to a massive 1100% increase.
PugetBench for Stable Diffusion
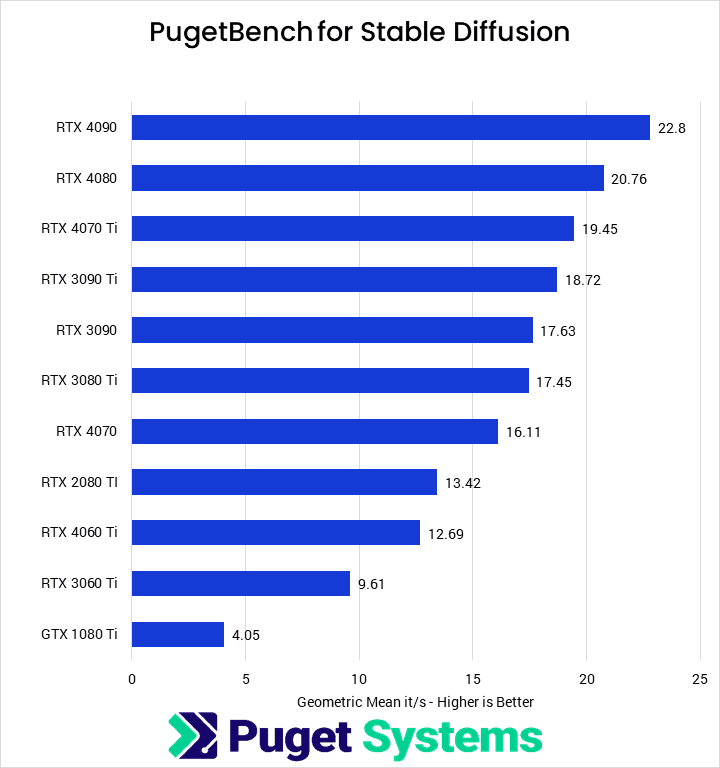
Alongside the two most common packages for Stable Diffusion, we also have our own in-development implementation. As we are focused on benchmarking, it is a more stripped-down version than Automatic 1111 or SHARK. However, it only supports NVIDIA cards, although we plan to add AMD support.
This implementation performs very similarly to the Automatic 1111 implementation with xFormers, although it uses an updated version of PyTorch rather than the xFormers library. The only notable exception is that the GTX 1080 Ti has nearly double the performance with our implementation, although, at only 4.05 it/s, it is still a relatively weak card for this workflow. We expect that we won’t see a significant performance shift when Automatic 1111 and SHARK update to the latest version of PyTorch.
IS NVIDIA GeForce or AMD Radeon faster for Stable Diffusion?
Although this is our first look at Stable Diffusion performance, what is most striking is the disparity in performance between various implementations of Stable Diffusion: up to 11 times the iterations per second for some GPUs. NVIDIA offered the highest performance on Automatic 1111, while AMD had the best results on SHARK, and the highest-end GPU on their respective implementations had relatively similar performance.
If you are not already committed to using a particular implementation of Stablie Diffusion, both NVIDIA and AMD offer great performance at the top-end, with the NVIDIA GeForce RTX 4090 and the AMD Radeon RX 7900 XTX both giving around 21 it/s in their preferred implementation. Currently, this means that AMD has a slight price-to-performance advantage with the RX 7900 XTX, but as developers often favor NVIDIA GPUs, this could easily change in the future. AMD has been doing a lot of work to increase GPU support in the AI space, but they haven’t yet matched NVIDIA.
Stable Diffusion is still somewhat in its infancy, and it is worth noting that performance is only going to improve in the coming months and years. While we don’t expect there to be many massive shifts in terms of relative performance, we want to be clear that the exact results in this article are likely to change over time.
If you are looking for a workstation for using Stable Diffusion, you can visit our solutions page to view our recommended workstations for various workflows. If you are a developer, we also have a range of workstations and servers for Machine Learning and AI. Feel free to contact one of our technology consultants for help configuring a workstation that meets the specific needs of your unique workflow.
Looking for a content creation workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.