
"Web search API" now covers three genuinely different products: SERP scrapers, AI-native retrieval pipelines, and deep research agents. Here's how to tell them apart and pick the right one.
Serper charges $1.00 per 1,000 queries. CatchAll charges $0.10 per returned record. Put those two numbers next to each other, and CatchAll looks 100x more expensive.
It isn't. They're not selling the same thing.
That pricing confusion is a symptom of a wider problem: "web search API" now covers three genuinely different product categories, and the market hasn't sorted out what to call any of them. A SERP scraper, an AI retrieval pipeline, and an LLM research agent all carry the same label — web search. Treating them as interchangeable — especially on price per query — is how teams end up building extraction, validation, and deduplication infrastructure they thought they were buying.
This post maps the three categories, explains what you actually get in each, and gives you a framework for deciding which one you need.
TL;DR
- "Web search API" covers three distinct categories: SERP scrapers, AI-native retrieval APIs, and deep research agents — each with different outputs and different downstream build requirements
- A SERP API gives you search result metadata; everything downstream is yours to build
- AI-native retrieval APIs span a wide range, from basic text extraction to full validation and enrichment pipelines
- Deep research agents are built for synthesis, not exhaustive enumeration — our Q1 benchmark showed this clearly: Manus and OpenAI Deep Research scored F1 0.104 and 0.017 on event-detection queries, not because they're weak tools, but because that's not what they're for
- Comparing cost per API call across these categories is meaningless; the right unit depends on what you're actually trying to produce
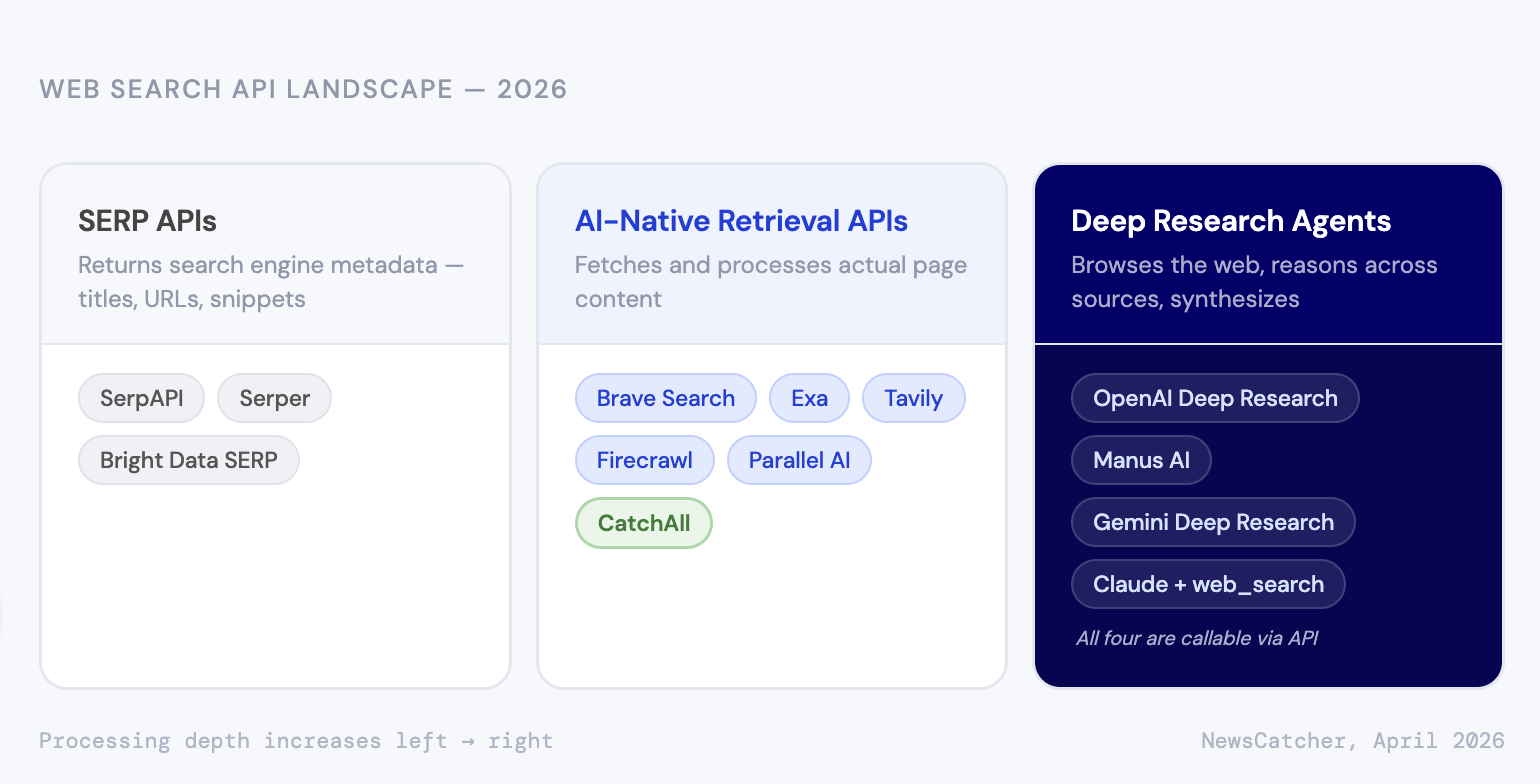
Three different products, one label
The term "web search API" started with a specific thing: programmatic access to Google's search results. When the AI wave hit, new tools launched with similar positioning, even though they worked very differently under the hood. Now the label covers everything from a raw Google result to a multi-agent research system.
Here's how we'd draw the boundaries:
SERP APIs return what a search engine would show a human — titles, URLs, snippets, plus feature data like knowledge panels and People Also Ask boxes. The data comes from Google, Bing, or both, and responses typically land in under a second.
Tools: SerpAPI, Serper, Bright Data SERP, and others.
AI-native retrieval APIs go further: they fetch and process the actual page content behind the search results, not just what the search engine says about it. How far varies a lot by provider. Some return cleaned text excerpts; others run full validation pipelines, cluster duplicate content, extract structured fields, and hand back machine-ready records.
Tools: Brave Search API, Exa, Tavily, Firecrawl, Parallel AI, CatchAll.
Deep research agents are different in kind. You submit a query; an LLM-backed agent browses the web, reasons across what it reads, and produces a synthesized response. The output is narrative text or structured JSON generated via a prompt — not a record set pulled from an index.
Tools with dedicated deep research endpoints include OpenAI Deep Research, Manus AI, and Gemini Deep Research. Others, like Claude, use a standard API and a web search tool accessible via code, with a deep research feature available only in the UI. The main difference is the endpoint's purpose-built nature.
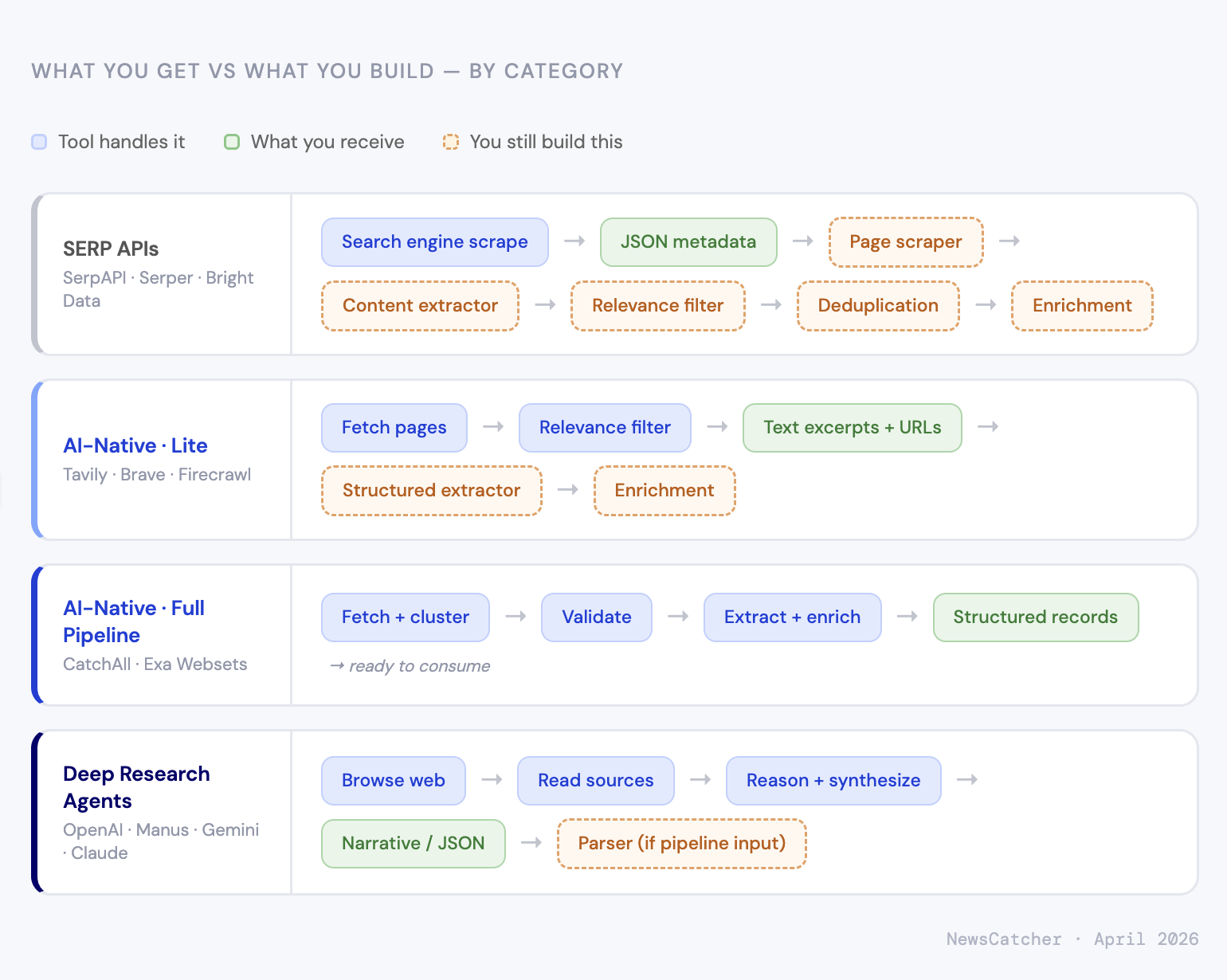
What you're actually buying
SERP APIs
You get a JSON payload: titles, URLs, snippets, and whatever SERP features are on the page. Under a second, $0.30–$25.00 per 1,000 queries, depending on volume and provider.
What's not included: page content. If your use case needs what's at the URL — not just what Google says about it — you're building a scraper. Add an extraction pipeline for structured data, deduplication logic, and relevance filtering. The SERP API answers "What does Google return for this query?" The rest is yours.
This makes sense for SEO monitoring, rank tracking, SERP feature analysis, and any case where the search result metadata is the actual data you need. It also works as a cheap URL-discovery layer when you've already built the downstream pipeline and just need to feed it.
AI-native retrieval APIs
The range here is wide. At the lighter end, you get fetched and cleaned page text with basic relevance filtering — still no structured extraction, still no enrichment. At the heavier end, pipelines that cluster near-duplicates, validate records against custom boolean criteria, extract named entities and numeric values, and return deduplicated structured records.
That difference matters a lot for pricing comparisons. A tool charging $0.10 per returned record with full enrichment is doing something fundamentally different from one charging $0.007 per request for raw text. Cheaper per call is not cheaper per result.
CatchAll sits at the heavier end. Base mode processes thousands of candidate pages per query through a five-stage pipeline (analyze → fetch → cluster → validate → extract) and returns enriched records. Lite mode is faster and flatter — binary relevance validation, titles and citations, $1.00 per search.
Deep research agents
These tools were built for a different job. They don't index the web or retrieve records from it; they research a question, read sources, and write up what they found.
In our Q1 2026 benchmark — 32 event-detection queries across funding, labor, regulatory, accidents, and real estate categories — Manus 1.6 scored F1 0.104 and OpenAI o3-deep-research scored F1 0.017. CatchAll scored F1 0.705. But calling that a performance ranking misses the point. A research agent finds representative examples of a product recall and explains what they mean. A retrieval API finds every product recall issued that week. Those are different outputs for different needs.
The flip side holds too. Ask a retrieval API to "analyze the strategic implications of these five acquisitions," and you get records, not reasoning. Deep research agents are the right tool when the output is meant to be read by a person, not consumed by a pipeline.
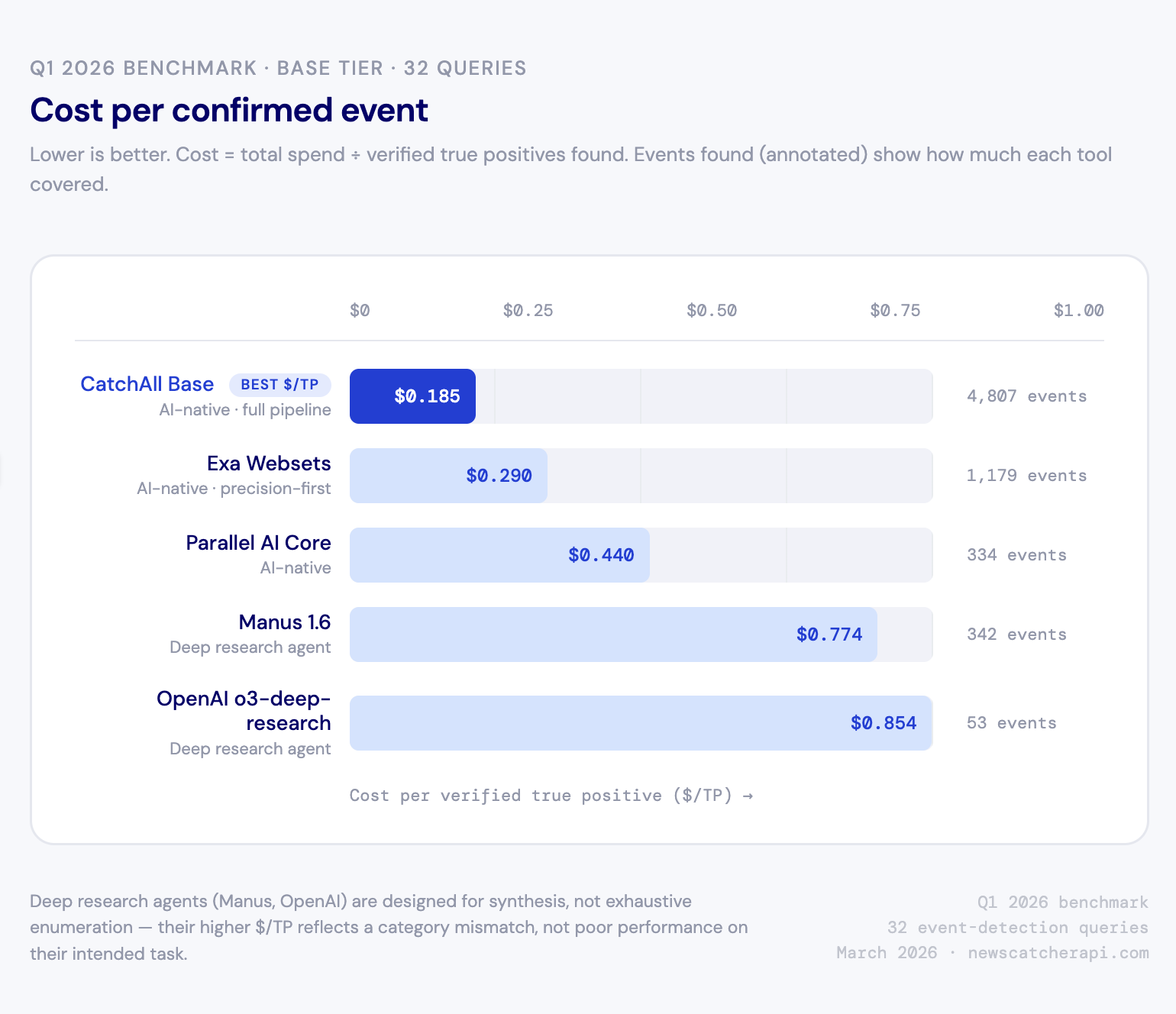
What things actually cost
Comparing the price per query across these three categories is like comparing the price of flour to the price of bread. Here's the pricing for each, from official sources, alongside what you're actually buying:
SERP APIs — search result metadata:
| Tool | Per 1K queries | Entry |
|---|---|---|
| Serper | $1.00 | $50 credit pack |
| Bright Data SERP | $1.50 (PAYG) | No commitment |
| SerpAPI | $25.00 | $25/month |
AI-native retrieval APIs — processed web content at varying depths:
| Tool | Unit | Cost |
|---|---|---|
| CatchAll Base full pipeline | Per valid structured record | $0.10 |
| Firecrawl | Per 1K scrape credits | $0.83 |
| CatchAll Lite | Per search | $1.00 |
| Brave Search API | Per 1K requests | $5.00 |
| Parallel AI | Per 1K requests | $5.00 |
| Exa | Per 1K requests | $7.00 |
| Tavily | Per 1K credits | ~$7.25 |
Deep research agents — synthesized research output:
| Tool | API pattern | Notes |
|---|---|---|
| OpenAI o3-deep-research | Responses API, background mode | $0.85/confirmed event from Q1 benchmark |
| Manus 1.6 | Tasks API, poll for completion | Variable per task |
| Gemini Deep Research | interactions.create(agent=) | Preview API; no cancel, indefinite runtime |
| Claude + web_search | Messages API + web_search tool | No dedicated model; closest equivalent |
Our Q1 2026 benchmark measures the cost per verified true positive — what you spend divided by the number of confirmed relevant events found. On that measure: CatchAll Base $0.185, Exa $0.290, Parallel AI $0.440, Manus $0.774, OpenAI $0.854. CatchAll spent more in absolute terms ($890 vs OpenAI's $45 for 32 queries) and found 91x more verified events.
The takeaway isn't that cheaper tools are worse — it's that cost per API call is the wrong metric. Figure out what a useful result looks like for your use case, estimate how many you need from each tool, then price it out. Per-call comparisons skip that step.
Choosing
| Use case | Category | Tools |
|---|---|---|
| SEO, rank tracking, SERP features | SERP APIs | Serper (cost), Bright Data (multi-geo), SerpAPI (multi-engine) |
| Research synthesis, briefings, narrative output | Deep research agents | OpenAI, Manus, Gemini, Claude |
| Comprehensive event monitoring | AI-native, full pipeline | CatchAll Base |
| Funding, regulatory, compliance, incident feeds | AI-native, full pipeline | CatchAll Base |
| Small, well-bounded event universes (<150 events) | AI-native, precision-first | Exa Websets |
| Hyper-local or entity-specific queries | AI-native | Parallel AI, Exa |
| High-frequency monitoring, budget-constrained | AI-native Lite | CatchAll Lite, Parallel AI |
| URL discovery before a custom pipeline | SERP APIs | Serper, Bright Data |
A few things the table doesn't capture:
SERP APIs and AI-native APIs aren't substitutes. A SERP API tells you what Google thinks is relevant. An AI-native API processes what's actually at those URLs. If your use case needs page content — event detection, entity extraction, anything requiring what the article actually says — a SERP API alone doesn't get you there.
Deep research agents and AI-native retrieval APIs work better together than apart. An LLM agent that retrieves records from a structured index before synthesis produces better results than one that browses the live web directly. The natural split: the retrieval API finds the facts, and the research agent reasons about them.
Date filtering is less universal than you'd expect. For time-bounded queries — all recalls announced in a specific week, all funding rounds in a specific month — there's a real difference between tools that treat date as a soft hint and tools that enforce it as a hard pipeline constraint. The latter produces fewer false positives and requires less cleanup downstream.
Where we sit
CatchAll is an AI-native web search API at the full-pipeline end of the spectrum. The architecture is built for high-volume event retrieval across broad geographic and topic scope — monitoring feeds, compliance databases, funding trackers — where recall matters and output goes into a machine pipeline, not a human inbox.
That also defines the current trade-offs. Narrow, precision-first queries — small event universes, hyper-local scope — are areas we're actively improving. We run a dedicated local news index and are expanding source coverage, making these query types increasingly competitive.
None of this is a knock on other tools. It's just what the taxonomy tells you once you've drawn it properly.
Try CatchAll with 2,000 free credits at platform.newscatcherapi.com — that's 20 Lite searches or a reasonable exploration of Base mode across a few event types.
Further reading: Q1 2026 benchmark · Why recall beats precision · How we built the recall-first pipeline

Structured Data Extraction from Web Search Results: JSON Schemas, Validation Prompts, and What Goes Wrong
Artem Bugara CEO & co-founder
Web Search API for Risk Monitoring: How Risk Teams Catch Signals Early
Artem Bugara CEO & co-founder
How to Evaluate Your AI Agent's Web Search Quality (Without Manual Labeling)
Artem Bugara CEO & co-founder
How Investment Teams Use Web Search APIs for Real-Time Market Intelligence
Margaretha Boetticher Head of Growth
Best Web Search API: An In-Depth Comparison of Available Tools in 2026
Margaretha Boetticher Head of Growth
Web Scraping API vs Web Search API: A Developer's Guide to Choosing the Right Tool
Margaretha Boetticher Head of Growth
Introducing Company Watchlist: Scope Any Query to Your List of Companies
Margaretha Boetticher Head of Growth
Tutorial
February 25, 2026
Beyond the Scoreboard: Building a Live Olympics 2026 Incident and Medal Dashboard with CatchAll
Introducing CatchAll: A SOTA Web Search API for Real-World Events
Margaretha Boetticher Head of Growth
How Transparency International Uses NewsCatcher Data to Fight Health Corruption
Jonathan Cushing Programme Director
NewsCatcher Partners With Reworkd To Streamline Access To Actionable Web Data
Artem Bugara CEO & co-founder
Top Media Outlets: 50 Essential News Sites to Consider for Your News Analysis in 2025
Mariia Platonova Head of Marketing
Tutorial
November 25, 2024
Detecting Events in News Using NewsCatcher’s Events Intelligence API
Aditya Singh Head Of Product
Using News API For Share Of Voice (SOV) Measurement & Competitor Tracking
Artem Bugara CEO & co-founder
Product


July 27, 2026
News API vs Web Search API: Picking the Right Tool
Margaretha Boetticher
,
Head of Growth
Product

July 22, 2026
Tavily Alternatives: Which Is Best for Enterprise AI Workflows?
Artem Bugara
,
CEO & co-founder
Company
.png)
July 17, 2026
What is Event-Driven Web Search?
Margaretha Boetticher
,
Head of Growth
Product

July 14, 2026
All 272 Security Breaches in 3 Days: How CatchAll Found What Others Missed
Company

July 6, 2026
Structured Data Extraction from Web Search Results: JSON Schemas, Validation Prompts, and What Goes Wrong
Artem Bugara
,
CEO & co-founder
Company

July 1, 2026
What Is Recall in AI Search? Why Your AI Agent Might Be Missing 80% of Results
Tutorial

June 23, 2026
How to Track New Local Business Openings: Build an Automated Local Business Tracker
Company

June 15, 2026
Web Search API for Risk Monitoring: How Risk Teams Catch Signals Early
Artem Bugara
,
CEO & co-founder
Tutorial

June 10, 2026
How to Evaluate Your AI Agent's Web Search Quality (Without Manual Labeling)
Artem Bugara
,
CEO & co-founder
Product

June 5, 2026
Web Scraping API vs. Custom Scraper: Which One Should You Use?
Margaretha Boetticher
,
Head of Growth
Tutorial

June 2, 2026
How Investment Teams Use Web Search APIs for Real-Time Market Intelligence
Margaretha Boetticher
,
Head of Growth
Tutorial

May 27, 2026
How to Build a Deep Research Agent with CatchAll and LangChain
Artem Bugara
,
CEO & co-founder
Tutorial

May 25, 2026
How to Monitor M&A Activity: Build an Automated Mergers & Acquisitions Tracker
Product

May 5, 2026
Best Web Search API: An In-Depth Comparison of Available Tools in 2026
Margaretha Boetticher
,
Head of Growth
Product

April 29, 2026
Web Scraping API vs Web Search API: A Developer's Guide to Choosing the Right Tool
Margaretha Boetticher
,
Head of Growth
Product

April 20, 2026
Introducing Company Watchlist: Scope Any Query to Your List of Companies
Margaretha Boetticher
,
Head of Growth
Company

April 14, 2026
What Is a Web Search API? A Guide for Developers and Analysts
Margaretha Boetticher
,
Head of Growth
Product

April 8, 2026
Web Search API Benchmarks: Q1 2026 — CatchAll vs Exa, OpenAI, and More
Company

March 26, 2026
Why We're Building a Different Type of Web Index
Artem Bugara
,
CEO & co-founder
Tutorial
February 25, 2026
Beyond the Scoreboard: Building a Live Olympics 2026 Incident and Medal Dashboard with CatchAll
Product

February 3, 2026
Google found 69 results. We found 3,261. Here's how
Company

January 28, 2026
Why Recall Beats Precision for Real-World AI Research
Tutorial
January 14, 2026
Building a Deep Research Agent with CatchAll and CrewAI
Product

January 13, 2026
Evaluating Recall in Web Search APIs: OpenAI vs Exa vs Parallel AI vs CatchAll
Tutorial

December 29, 2025
Building a Supply Chain Risk Monitor Using CatchAll and CrewAI
Product

November 21, 2025
Introducing CatchAll: A SOTA Web Search API for Real-World Events
Margaretha Boetticher
,
Head of Growth
Company
![]()
June 10, 2025
How Transparency International Uses NewsCatcher Data to Fight Health Corruption
Jonathan Cushing
,
Programme Director
Product

March 14, 2025
Comparing News Data Search: LLMs, Analyst, and NewsCatcher Pipelines
Aditya Singh
,
Head Of Product
Product

March 6, 2025
Measuring Product Launch Impact with News Data
Mariia Platonova
,
Head of Marketing
Company

January 24, 2025
NewsCatcher Partners With Reworkd To Streamline Access To Actionable Web Data
Artem Bugara
,
CEO & co-founder
Tutorial
January 22, 2025
Fake News Detection Using Python
Karthik Devan
,
Tech Copywriter
Company

December 16, 2024
Top Media Outlets: 50 Essential News Sites to Consider for Your News Analysis in 2025
Mariia Platonova
,
Head of Marketing
Product

December 9, 2024
How Does Our Local News API Work?
Aditya Singh
,
Head Of Product
Tutorial

November 25, 2024
Detecting Events in News Using NewsCatcher’s Events Intelligence API
Aditya Singh
,
Head Of Product
Product

November 5, 2024
Introducing NewsCatcher's Local News API
Aditya Singh
,
Head Of Product
Company

October 15, 2024
How to Choose a News API
Artem Bugara
,
CEO & co-founder
Product

September 17, 2024
Using Sentiment Analysis for Market Research
Artem Bugara
,
CEO & co-founder
Company

August 8, 2024
60,000 AI-generated news articles are published every day
Bradley Emi
,
CTO Pangram Labs
Product

May 7, 2024
Top 4 Free & Open-Source News API Alternatives
Artem Bugara
,
CEO & co-founder
Tutorial

May 7, 2024
Ultimate Guide To Text Similarity With Python
Aditya Singh
,
Head Of Product
Tutorial

May 7, 2024
Using News API For Share Of Voice (SOV) Measurement & Competitor Tracking
Artem Bugara
,
CEO & co-founder
Tutorial
May 7, 2024
How To Train Custom Named Entity Recognition [NER] Model With SpaCy
Aditya Singh
,
Head Of Product
Company
May 7, 2024
Top 15 Takeaways From Running A Bootstrapped Startup For 1 Year
Artem Bugara
,
CEO & co-founder
Tutorial

May 7, 2024
Named Entity Recognition (NER) with SpaCy [with code example]
Aditya Singh
,
Head Of Product
Product

May 7, 2024
How We Built A News API Beta In 60 Days
Artem Bugara
,
CEO & co-founder
Tutorial
May 7, 2024
How To Annotate Entities With Spacy PhraseMatcher
Aditya Singh
,
Head Of Product
Tutorial
May 7, 2024
How To Present/Show Open-Source Projects [Practical Guide]
Artem Bugara
,
CEO & co-founder
Tutorial
May 7, 2024
Google Kubernetes Engine as an alternative to Cloud Run
Product
May 7, 2024
Google News RSS Search Parameters: The Missing Docs
Artem Bugara
,
CEO & co-founder
Tutorial
May 7, 2024
Building A PR/Communication Media Monitoring Tool With News API
Artem Bugara
,
CEO & co-founder
Product

May 7, 2024
100k+ Rows Topic Labeled News Dataset
Artem Bugara
,
CEO & co-founder
Product

May 7, 2024
Announcing Free COVID-19 News API
Artem Bugara
,
CEO & co-founder
Tutorial
March 14, 2024
SpaCy vs NLTK. Text Normalization Comparison [with code]
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
Top 6 Text Annotation Tools
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
Sentiment Analysis Using Python
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
Mining Financial Stock News Using SpaCy Matcher
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
Learning Natural Language Processing (NLP) Made Easy
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
How To Classify Text With Python, Transformers & scikit-learn
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
How To Build Your Own Crypto News Aggregator
Aditya Singh
,
Head Of Product
Tutorial
March 14, 2024
4 Python Web Scraping Libraries To Mining News Data
Aditya Singh
,
Head Of Product