Part of the Italian lore infused on me when growing up is to be disillusioned when it comes to interactions with politicians. Assuming that what a politician promises carries information about what they’re going to do is not the wisest way of living one’s life. This is a gut feeling and it could be completely wrong. It asks for verification and data: is it true that what politicians do in parliament is not similar to how they present themselves to the public?
The data to answer this question is what the excellent Christian Ivert Andersen provided, which eventually led to the publication of the paper “Disconnect between the Public Face and the Voting Behavior of Political Representatives,” which recently appeared in the journal Applied Network Science.
Christian had spotted some promising features about how elections are handled here in Denmark. Like in some other countries in the world, Denmark has a number of voting advice applications. These apps ask politicians for their position on a number of salient issues. This allows them to place the politicians somewhere into a political ideological space. The citizen can answer the same questions and figure out which politician is the closest to them — with the assumption they should vote for them, if they do not want to heed the Italian cautionary tales.
We decided to represent this data as a network: each node is a politician and each pair of politicians is connected if they agree on a significant number of issues. Altinget was kind enough to share their data with us for our work. We’ll get to the why we represent this data as a network, but for now let’s verify whether these networks make sense:

It seems they do! We clearly see the two blocks (red and blue) that are the ideological coalitions typical of the Danish political environment.
This data by itself is fascinating, but not enough to answer our question. It represents the “public face” of a politician: their explicitly stated position they use to campaign and attract votes. We need a data source for the actions they take once they are elected.
Luckily, Denmark publishes excruciatingly detailed reports of parliament actions in an open format. Unluckily, such an open format is a nightmare to work with, is highly fragmented, and I’m a bit concerned about Christian’s mental health after he had worked with it (get well soon, Christian!). With this data we can build a different network, this time connecting politicians according to their voting behavior similarity in parliament:

By analyzing the connections in these two networks we can create a numerical score which summarizes the ideology of a politician, depending on the politicians they’re connected to in the network — and who they are connected to and so on. I’ve been using such score as the node color in the network pictures in this post.
So: why networks? “Why not?” I would reply as a person whose obsession with networks has now reached pathological levels. But I know that’s not going to cut it. The reason we use networks is that they allow to calculate the distance between the two ideological scores we just built — one based on the politicians’ words, the other on their actions — in a more nuanced way.
Trivially, with two ideological scores, one would simply check their difference. However, the difference between ideological scores matters most for those politicians that are supposed to be ideologically close. It matters a lot if you’re shifting your position relative to the other members of your own party, more than if you do it relatively to parties that are not ideologically similar to you.
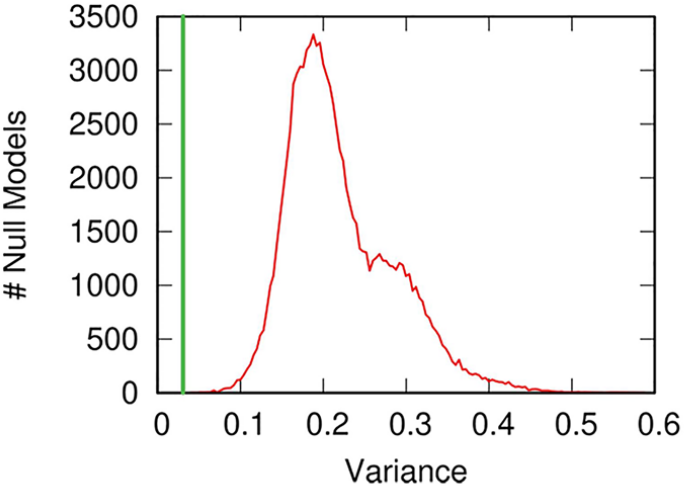
This nuanced distance estimation can be achieved by calculating the good old network distance measure I’ve been working with for the past few years. The only issue with it is that we just get a distance value and we need to contextualize it. To do so, we compare it with a null model: we calculate the same distance but we randomly shuffle the ideological scores on the networks. This way, we know what distance we should be seeing when there is no connection between the two ideological scores on the network.

Above you see the distribution of expected distances in the null model in red, and the distance we observe as the green bar. Distressingly, the green bar is to the right of the expectation, and almost always significantly so. This means that the distance we observe — the actual difference between promises and actions — is larger than what we would expect in the scenario in which the two are randomly picked! To put it bluntly: how politicians present themselves during a campaign is significantly different from what they do in parliament once elected. Looks like my Italian guts were right.
But we shouldn’t put it bluntly, not yet at least. This study is just the first step and it does require substantial robustness checks. The most important of which is that the topics representatives in parliament vote on are not necessarily the same issues they’re asked about during the campaign. The most blatant case for this is that no one had asked anything about COVID during the 2019 campaign, but we all know what politicians had to deal with starting from early 2020. We should match the votes with specific questions and use only votes sufficiently similar to at least one question to build the parliament networks. We can do this, using some natural language processing magic, so that will come next.
From these very preliminary results, the most cautious lesson learned should be: maybe be wary of making your voting decisions based on a voting advice app. There are a number or reasons — not necessarily shady, as the COVID case exemplifies — that make them not exactly a faithful representation of what you’re voting for.