pg_parquet is a new extension by Crunchy Data that allows a PostgreSQL instance to work with Parquet files. With pg_duckdb, pg_analytics and pg_mooncake all of which can access Parquet files, is there need for yet another extension?
Well actually if you don't need the full strength of duck_db behind the covers, but just want to import a Parquet file as a Postgres table and work with it, then this is the appropriate extension for you. In other words, pg_parquet is the lightweight counterpart to the other mentioned extensions that does not summon a duck_db instance. Instead it does just a few things, but does them right:
- Exporting tables or queries from Postgres to Parquet files
- Ingesting data from Parquet files to Postgres
- Inspecting the schema and metadata of existing Parquet files
That goes for any Parquet files residing on S3 silos or the local file system.
The mechanism employed to ingest a Parquet file into Postgres happens simply via the familiar COPY TO/FROM commands.
-- Copy a query result into Parquet in S3
COPY (SELECT * FROM table) TO 's3://mybucket/data.Parquet' WITH (format 'Parquet');
-- Load data from Parquet in S3
COPY table FROM 's3://mybucket/data.Parquet' WITH (format 'Parquet');
That aside, pg_parquet can also handle complex table types, to and from Parquet files:
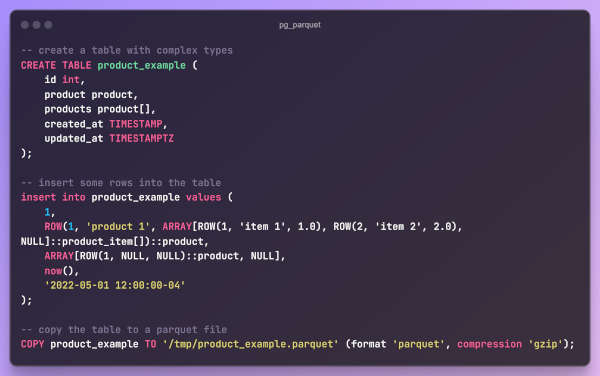
plus you can also inspect Parquet metadata and schemas.
After installing a Postgres instance, you need to set up
rustup and cargo-pgrx to build the extension; full instructions on its Github repo.
In conclusion, pg_parquet offers yet another convenience that again confirms the 'use PostgreSQL for everything' motto; a tool to rule them all.
![]()
More Information
Related Articles
DuckDB And Hydra Partner To Get DuckDB Into PostgreSQL
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info