Model-Agnostic Text Summarization
For long-format content, like an ArXiV research paper, Large Language Models (LLMs) can expedite your learning by summarizing multiple pages of a PDF into bite-size paragraphs.
In this case, we want to summarize this excellent paper on the unification of LLMs and knowledge graphs.

Anthropic Claude 2.1
With Anthropic releasing their new Claude 2.1 LLM recently, let's see how it does for summarizing this paper.

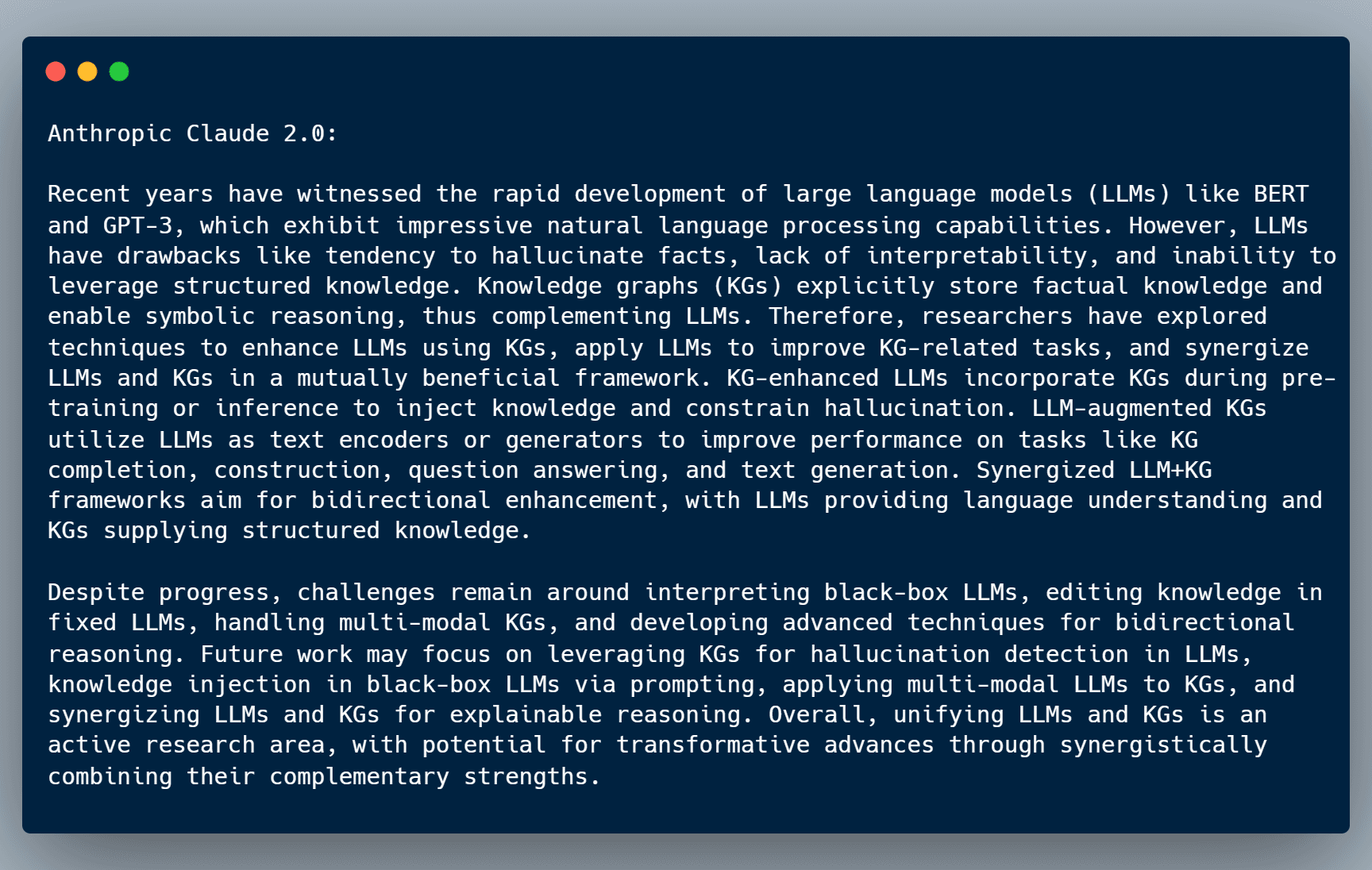
Compared to their previous Claude 2.0 model, the results look very good for such a short summary.
Walkthrough
Let's see how to use Graphlit to summarize this ArXiV PDF.
With Graphlit's model-agnostic approach, we can use the same content workflow to ingest the PDF, using different LLMs for summarization.
We will be using the GraphQL API for the code samples, which can be called from any programming language, such as Python or Javascript.
Completing this tutorial requires a Graphlit account, and if you don't have a Graphlit account already, you can signup here for our free tier. The GraphQL API requires JWT authentication, and the creation of a Graphlit project.
LLM Specification
First, we need to create a specification, which defines which LLM to use for summarization. Think of this as a 'preset' which specifies that we're using the CLAUDE_2_1 model, with a temperature of 0.1 and top_p (aka probablility) of 0.2. We are asking for a maximum of 512 tokens in the summary response.
Content Workflow
Next, we create a workflow, which uses this specification for summarization.
Here we are asking for 2 paragraph summary, with a total of 512 tokens, and assigning the Claude 2.1 specification.
This workflow only needs to be created once, and can be reused, as you ingest any form of content to be summarized.
Any content type can be summarized: web pages, PDFs, Notion pages, Slack messages, or even audio transcripts.
Ingest PDF
Now we can ingest the ArXiV PDF, simply by assigning this Anthropic Summarization workflow.
Graphlit will extract all pages of text from the PDF, and then use recursive summarization to generate the two paragraphs of summary. Graphlit adapts to the context window of the selected model, and since Claude 2.1 supports 200K tokens, the summarization can be done in one pass for long PDFs.
Get Content
The PDF will be ingested asynchronously, and you can poll the content by ID, and check for completion. (Alternately, Graphlit supports webhook actions, where you can be notified on every content state change.)
When the state field is FINISHED, the content workflow has completed, and the summary field has been populated.
LLM Summarization Comparison
Again, here is what Claude 2.1 has returned for the summary:
By changing the specification to use the Azure OpenAI GPT-3.5 16K model, we get the summary:

Or, by changing the specification to use the Azure OpenAI GPT-4 model, we get the summary:

We can even use the newly released OpenAI GPT-4 Turbo 128K model, and get this summary:

Change the Specification LLM
To use different models with your specification, you will need to assign the serviceType as AZURE_OPEN_AI, OPEN_AI or ANTHROPIC. Then, you can fill in the model-specific fields such as azureOpenAI.model, as shown here.
Specifications can be updated in-place, without needing to change your workflow.
Summary
Graphlit provides a model-agnostic approach to using LLMs for text summarization, and simplies the integration of new models like Anthropic Claude 2.1 in your knowledge-driven applications.
We look forward to hearing how you make use of Graphlit in your applications.
If you have any questions, please reach out to us here.
Ready to Build with Graphlit?
Start building AI-powered applications with our API-first platform. Free tier includes 100 credits/month — no credit card required.
No credit card required • 5 minutes to first API call