Frontier LLMs keep getting better and cheaper: GPT-5 nano costs $0.05 per million input tokens and Gemini 2.5 Flash Lite is $0.10. At these prices, is there still a case for running your own small models?
If you grab an off-the-shelf small model and point it at a production task, the answer is no. Base small models are simply not good enough. But there’s a third option that most teams overlook: fine-tuning changes everything. A small model that has been fine-tuned on your specific task doesn’t just close the gap with frontier LLMs, it matches or beats them, while running 10x cheaper on your own hardware.
We tested this across 8 datasets, comparing fine-tuned small models (0.6B to 8B parameters) against 10 frontier LLMs from OpenAI, Anthropic, Google, and xAI. The fine-tuned models ranked first overall on half the tasks and placed 3.2 on average, just behind Claude Opus 4.6 (2.5), while beating out Gemini 2.5 Flash (3.5) at 100x lower cost.
The fine-tuned models rank 3.2 on average, just behind Opus 4.6 (2.5). The cost difference: $3 for fine-tuned SLMs per million requests vs. $6,241 for Opus.
If you care about efficiency and LLM inference meaningfully shows up on your bill, let us walk you through the details. All the code, models, and data for this post are available in this repository, and you can reproduce everything using our platform.
What is distil labs?
distil labs is a platform for training task-specific small language models. You provide a task description and a handful of examples; we handle synthetic data generation, validation, fine-tuning, and evaluation. The result: models 50 to 400x smaller than frontier LLMs that maintain comparable accuracy and runs for 10% of the price. The hard part of fine-tuning, collecting data, picking the right base model, tuning hyperparameters, validating quality, is exactly what we automate. Check out our docs if you want to dive deeper.
Results: Same accuracy, 100x cheaper
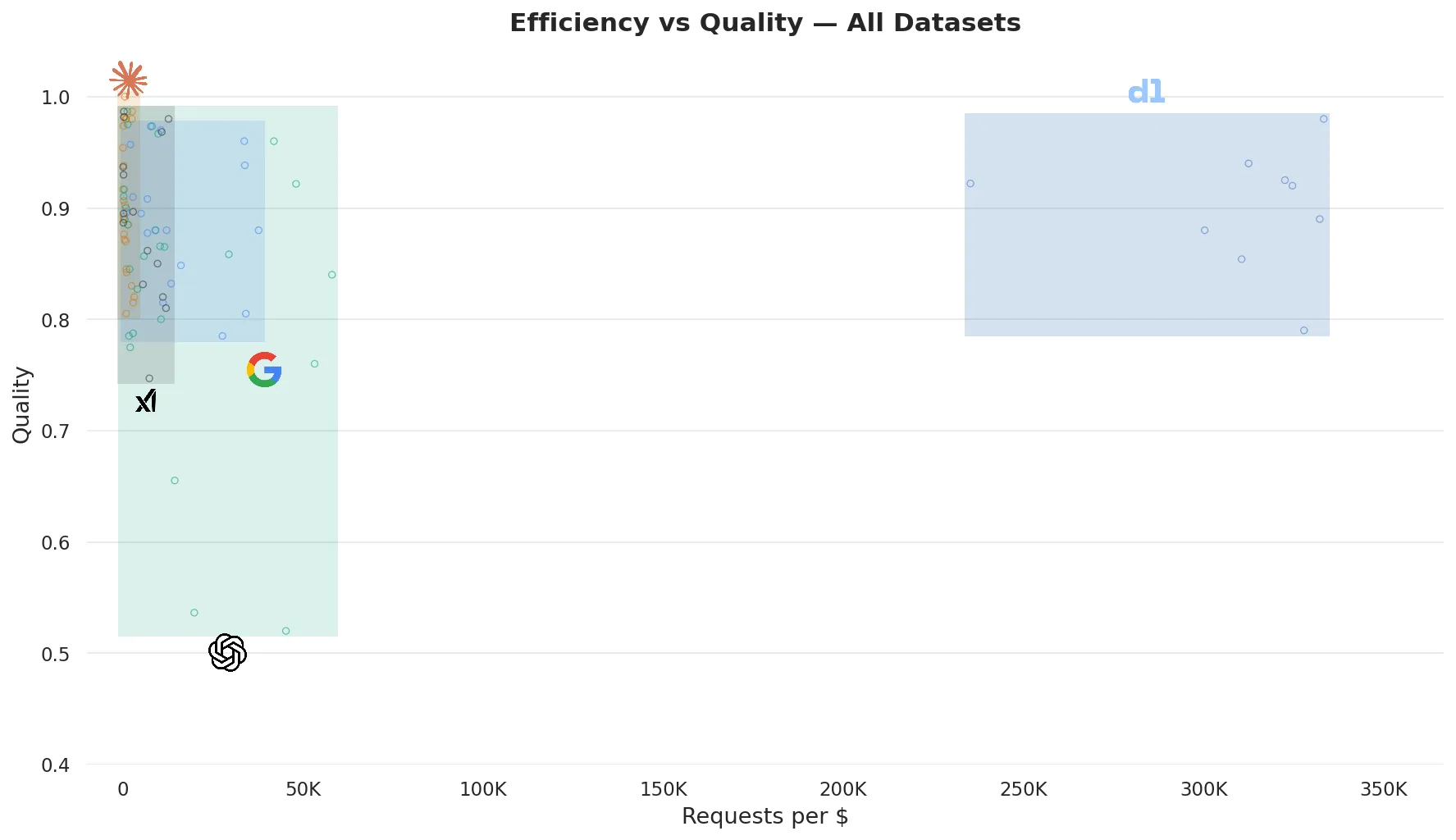
We evaluated fine-tuned models against up to 11 frontier LLMs per dataset, including both mid-tier (GPT-5 nano, Gemini 2.5 Flash Lite, Grok 4.1 Fast, GPT-5 mini, Gemini 2.5 Flash, Claude Haiku 4.5) and premium models (GPT-5.2, Sonnet 4.6, Grok 4, Opus 4.6). For each dataset, we ranked all models by accuracy. The “Avg Rank” column below is each model’s mean position across all datasets it was evaluated on: 1.0 means it came first on every task, higher is worse.
| Model | $/1M requests | Avg Rank |
|---|---|---|
| Fine-tuned SLMs (0.6B to 8B) | $3 | 3.2 |
| GPT-5 nano | $45 | 9.2 |
| Gemini 2.5 Flash Lite | $75 | 7.4 |
| Grok 4.1 Fast | $160 | 7.8 |
| GPT-5 mini | $222 | 8.4 |
| Gemini 2.5 Flash | $313 | 3.5 |
| Claude Haiku 4.5 | $1,331 | 6.0 |
| GPT-5.2 | $1,783 | 4.3 |
| Claude Sonnet 4.6 | $3,255 | 4.2 |
| Grok 4 | $4,613 | 4.2 |
| Claude Opus 4.6 | $6,241 | 2.5 |
Frontier model costs are averages across datasets, computed from measured API token usage over 3 runs each. Fine-tuned model costs are computed from sustained vLLM throughput on a single H100 GPU at $2.40/hr.
The fine-tuned models rank 3.2 on average, just behind Opus 4.6 (2.5). The cost difference: $3 for fine-tuned SLMs per million requests vs. $6,241 for Opus. The closest competitor on rank is Gemini 2.5 Flash (3.5), which costs $313 per million requests, over 100x more expensive for essentially the same quality.
If you’re processing a million requests per day on well-structured problems, a dedicated fine-tuned model will almost certainly save you money, even accounting for training and deployment overhead.
Results: For well-structured tasks, fine-tuned small models match or beat even the most expensive frontier models
The per-dataset breakdown shows where fine-tuned models win outright and where frontier models hold an edge. The fine-tuned model ranks first on 4 out of 8 tasks, beating every frontier model tested, including the most expensive ones. The gains are largest where the task is narrow and well-defined (function calling, classification, entity extraction), and smaller where broad reasoning or free-form generation is involved.
| Dataset | Fine-tuned | Best Frontier | Best Frontier Model | Fine-tuned Rank |
|---|---|---|---|---|
| Smart Home ★ | 98.7% | 92.0% ± 0.0pp | Claude Sonnet 4.6 | 1 of 12 |
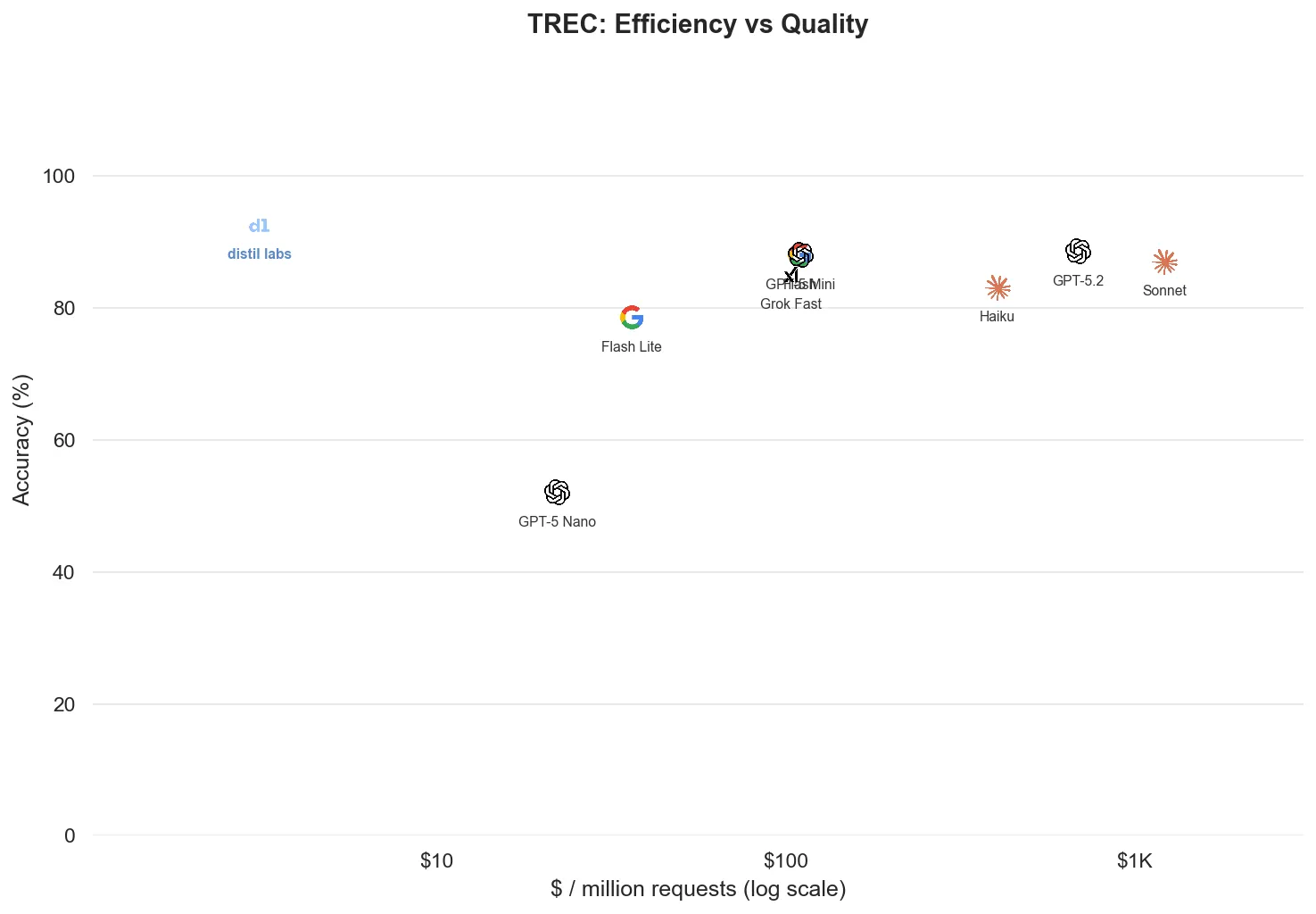
| TREC | 92.5% | 87.3% ± 0.3pp | Claude Sonnet 4.6 | 1 of 7 |
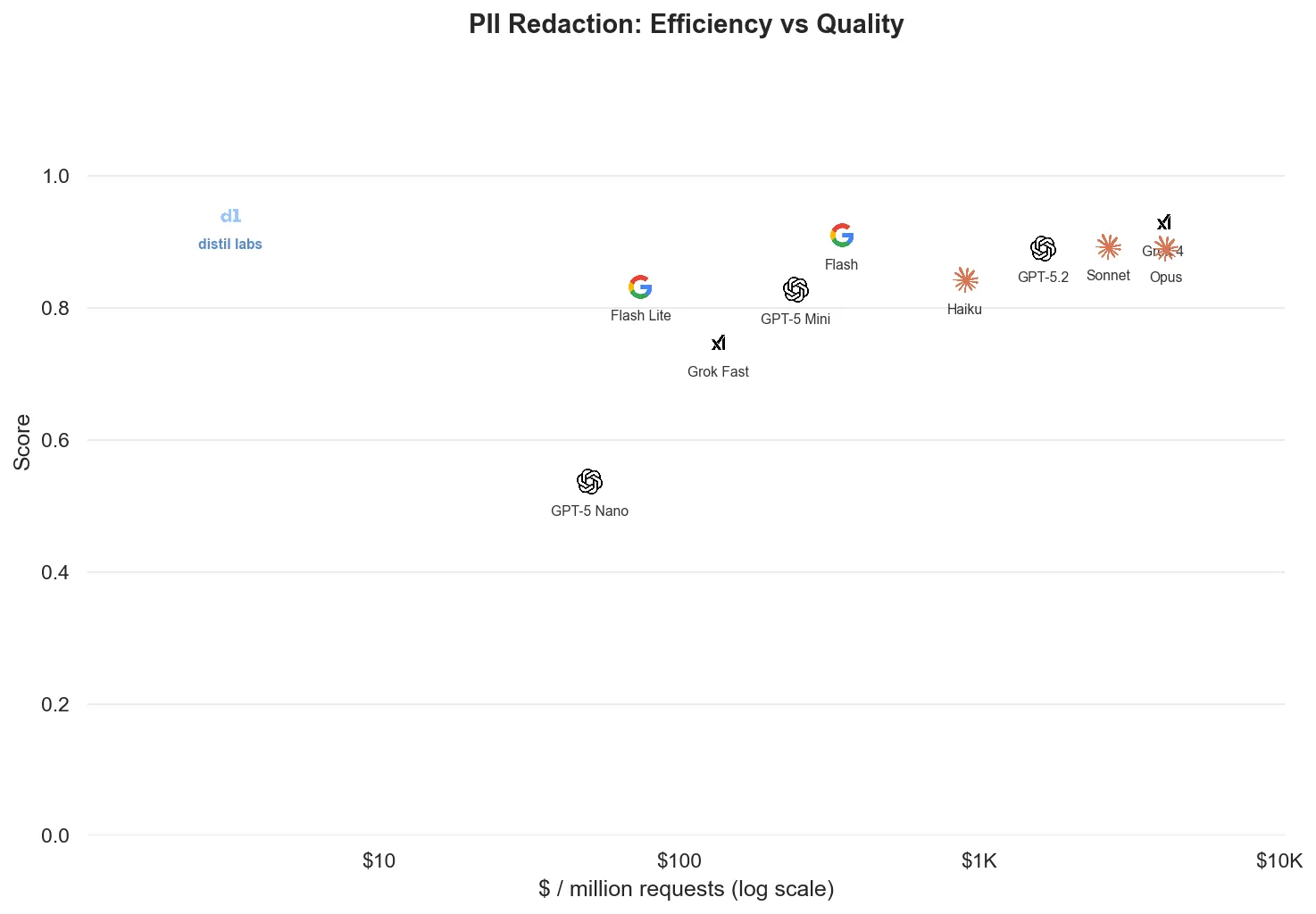
| PII Redaction | 94.0% | 93.0% ± 2.4pp | Grok 4 | 1 of 11 |
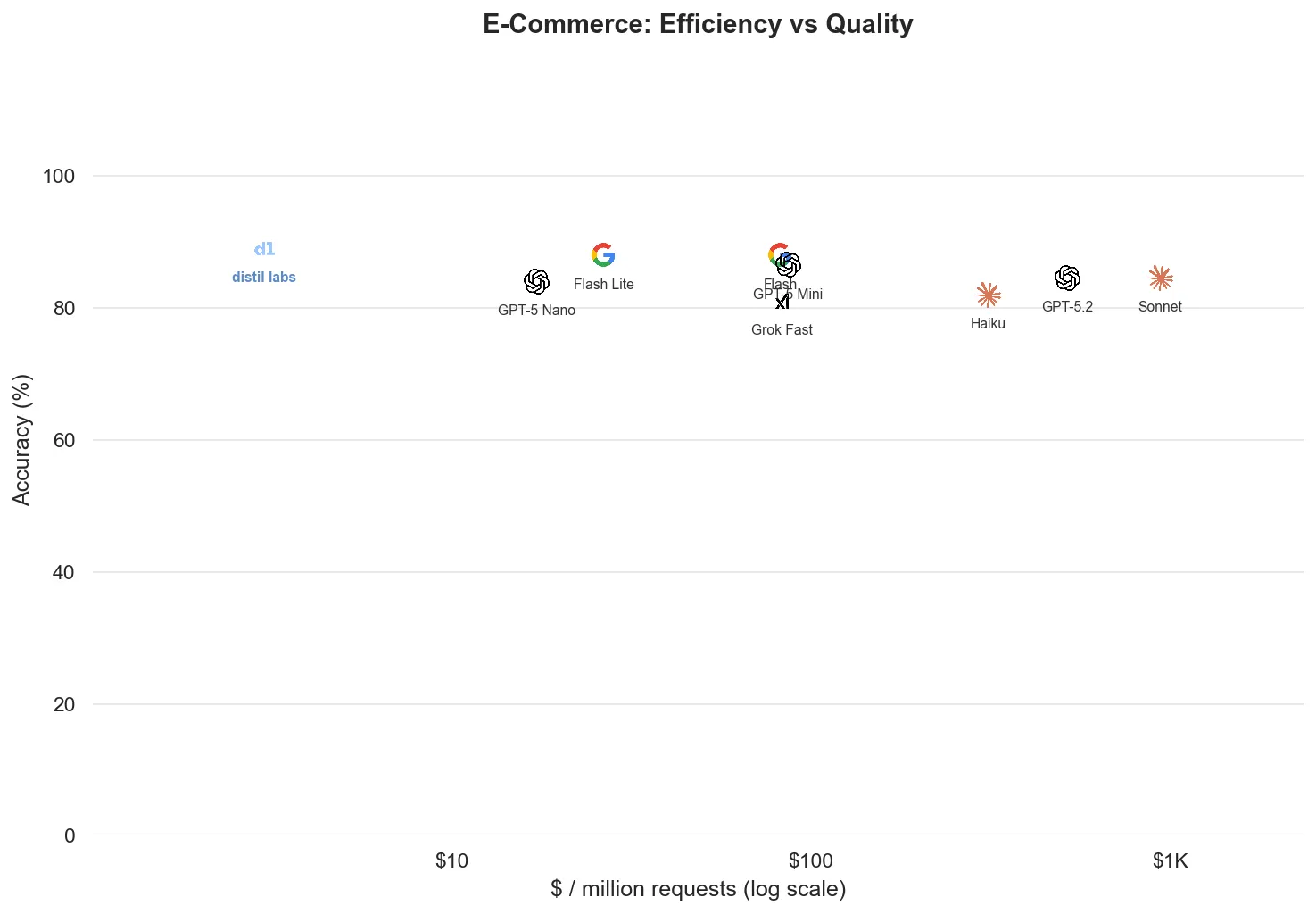
| E-commerce | 89.0% | 88.7% ± 0.8pp | Gemini 2.5 Flash | 1 of 7 |
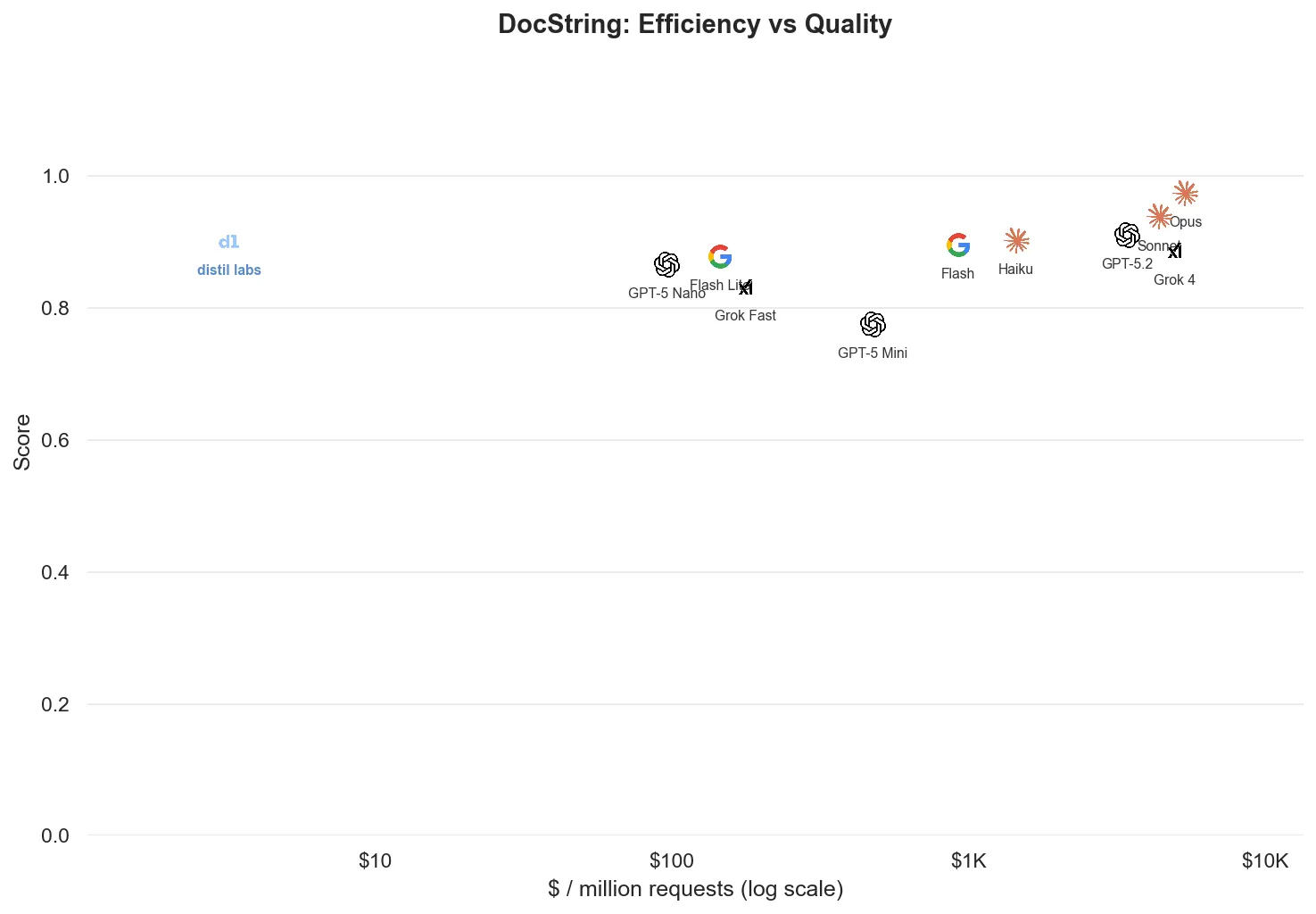
| Docstring ★ | 90.1% | 97.4% ± 0.8pp | Claude Opus 4.6 | 5 of 11 |
| Text2SQL | 98.0% | 100.0% ± 0.0pp | Claude Opus 4.6 | 5 of 12 |
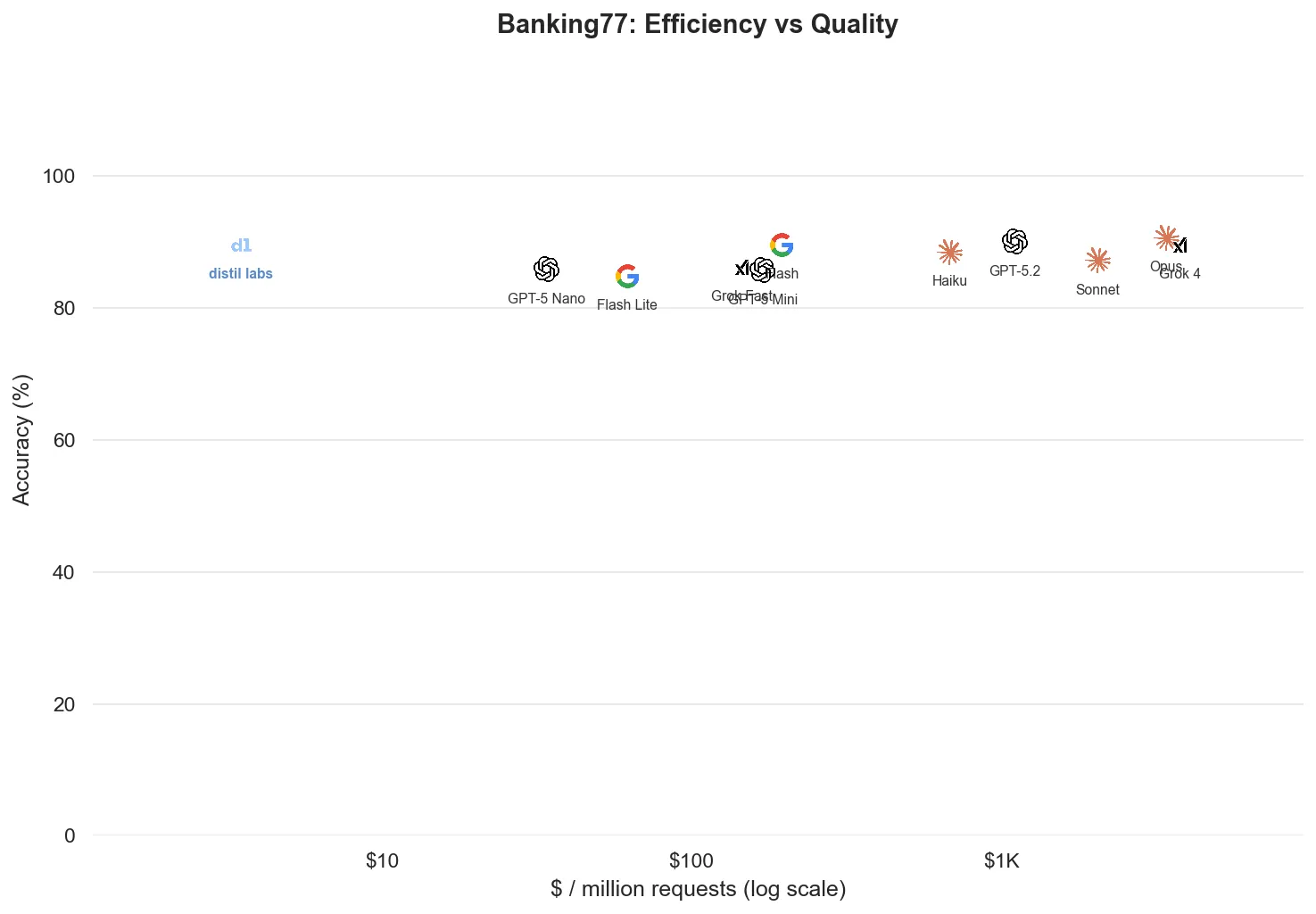
| Banking77 ★ | 88.0% | 90.7% ± 0.3pp | Claude Opus 4.6 | 6 of 11 |
| Git Assistant | 92.2% | 95.7% ± 0.0pp | Gemini 2.5 Flash | 4 of 11 |
★ Smart Home and Banking77 use Qwen3-0.6B; Docstring uses Qwen3-8B; all others use Qwen3-4B.
Setup
We compared fine-tuned models (0.6B to 8B parameters) against 10 frontier LLMs across 8 datasets. All task-specific models were fine-tuned using distil labs, mostly with the Qwen3 family as the base. All were served on a single GPU via vLLM using the Chat Completions API with thinking disabled. We used the following datasets:
| Dataset | Category | Test Size | Eval Metric |
|---|---|---|---|
| Smart Home | Function Calling | 50 | Tool call equivalence |
| Git Assistant | Function Calling | 116 | Tool call equivalence |
| PII Redaction Healthcare | Question Answering | 133 | LLM-as-a-judge |
| Text2SQL | Question Answering | 50 | LLM-as-a-judge |
| Docstring Generation | Question Answering | 253 | LLM-as-a-judge |
| Banking77 | Classification | 200 | Accuracy |
| E-commerce | Classification | 200 | Accuracy |
| TREC | Classification | 200 | Accuracy |
Every model was evaluated on the same test set with the same prompts, same evaluation criteria, and minimal reasoning/effort. For all LLM-as-a-judge runs, we used Claude Sonnet 4.6 with default effort. Frontier models were each run 3 times to measure variance; we report means with standard deviations. The fine-tuned models default to temperature 0, so we report a single run.
Pricing of SLMS
While Frontier LLM APIs charge per token, distil labs models run on dedicated GPUs, charged by uptime. This means exact pricing depends on utilization: the more requests you push through a GPU, the cheaper it gets. We report our numbers assuming full utilization since many real workloads get close to it (you only pay when the GPU is processing requests and we can scale down to 0). The conclusions still hold up even assuming a pessimistic 10% utilization.
Specifically, we report sustained throughput on a single H100 GPU node (~$2.40/hr). At the measured ceiling of 222 RPS for the Text2SQL 4B model, a single GPU handles over 19 million requests per day. Since these models are small, they fit on much smaller GPUs as well, however, most of our tasks are prefill-heavy and decode-light. In such scenarios, H100’s FLOP advantage really shines and outweighs the fact that 80GB of memory is an overkill.
Deep dive: Text2SQL
Text2SQL is a good test of the accuracy-cost tradeoff because it requires genuine reasoning: translating natural language questions into SQL queries across custom schemas spanning e-commerce, HR, healthcare, finance, education, and social domains.
For example, given this input:
Schema:
CREATE TABLE clinics (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
address TEXT,
phone TEXT
);
CREATE TABLE visits (
id INTEGER PRIMARY KEY,
clinic_id INTEGER REFERENCES clinics(id),
patient_name TEXT,
visit_date DATE,
diagnosis TEXT
);
Question:
How many patient visits per clinic this year?We want to get something like:
SELECT c.name, COUNT(*)
FROM clinics c
JOIN visits v ON c.id = v.clinic_id
WHERE v.visit_date >= '2024-01-01'
GROUP BY c.id, c.name;This task is straightforward, and the results make the case clearly. Our fine-tuned 4B model hits 98%, matching Claude Sonnet 4.6, GPT-5 mini, and Gemini 2.5 Flash, and only 2 points behind Claude Opus 4.6’s perfect score. Even the 1.7B model at 94% matches GPT-5 nano and Flash Lite (96.0% mean across 3 runs, with individual runs ranging 94 to 98%). Note the x-axis is log-scale.
| Model | Mean Score ± Std | $/1M requests |
|---|---|---|
| Claude Opus 4.6 | 100.0% ± 0.0pp | $1,623 |
| GPT-5.2 | 98.7% ± 1.2pp | $582 |
| Claude Haiku 4.5 | 98.7% ± 1.2pp | $378 |
| Grok 4 | 98.7% ± 2.3pp | $2,890 |
| Qwen3-4B (fine-tuned) | 98.0% | $3 |
| Claude Sonnet 4.6 | 98.0% ± 0.0pp | $1,042 |
| Grok 4.1 Fast | 98.0% ± 0.0pp | $78 |
| GPT-5 mini | 97.3% ± 1.2pp | $122 |
| Gemini 2.5 Flash | 97.3% ± 1.2pp | $130 |
| GPT-5 nano | 96.0% ± 2.0pp | $24 |
| Gemini 2.5 Flash Lite | 96.0% ± 2.0pp | $30 |
Grok 4 does not support setting reasoning effort, so its token counts and costs are inflated compared to other models.
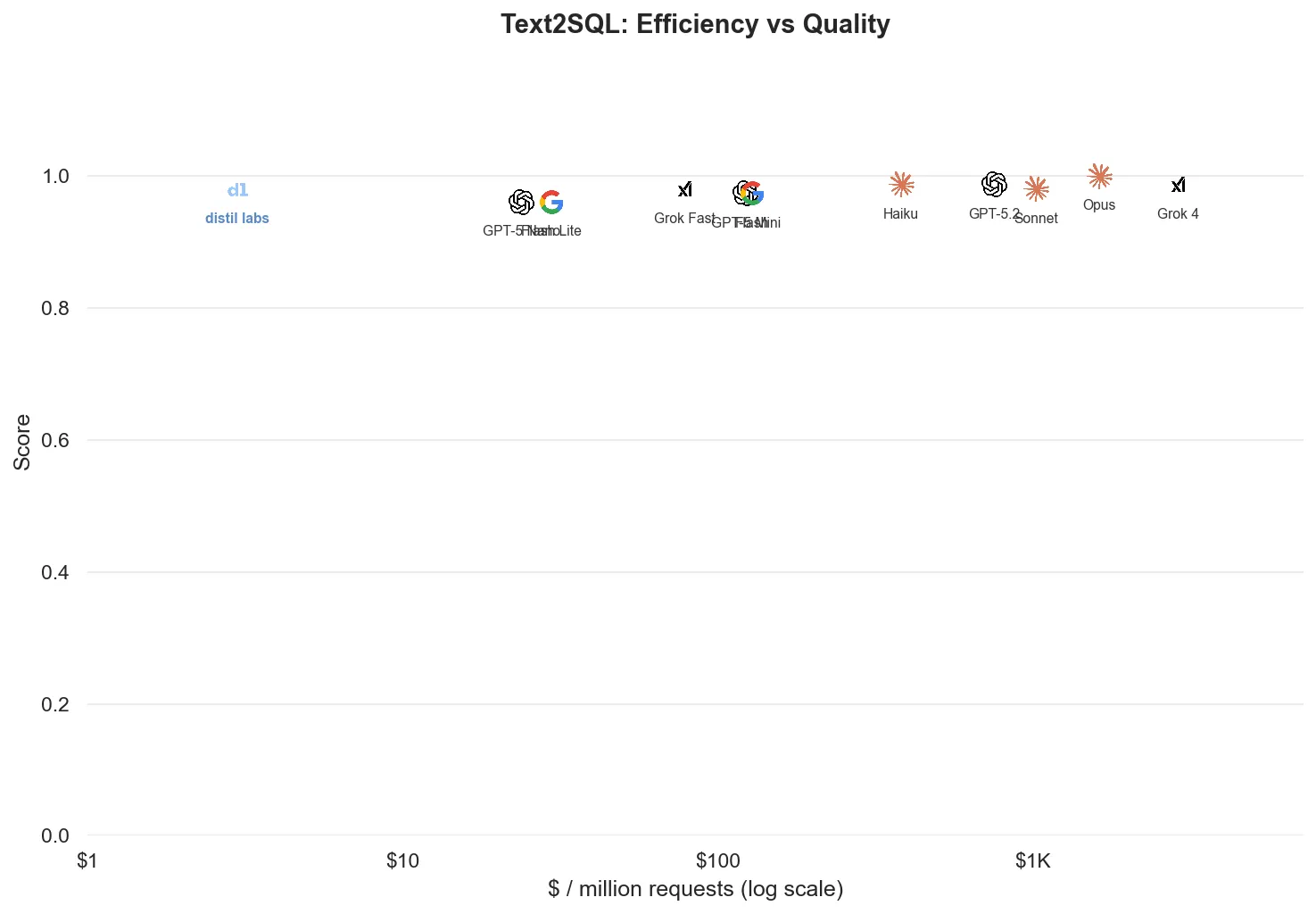
Same accuracy as Sonnet 4.6 and GPT-5 mini. $3 per million requests vs. $24 for GPT-5 nano. That’s an 8x cost reduction over the cheapest frontier option, at higher accuracy.
We report sustained throughput on a single H100 GPU node (~$2.40/hr). At the measured ceiling of 222 RPS for the Text2SQL 4B model, a single GPU handles over 19 million requests per day. Since these models are small, they fit on much smaller GPUs as well, however, most of our tasks are prefill-heavy and decode-light. In such scenarios, H100’s FLOP advantage really shines and outweighs the fact that 80GB of memory is an overkill.
| Metric | Value |
|---|---|
| Max sustained RPS | 222 |
| p50 latency | 390ms |
| p95 latency | 640ms |
| p99 latency | 870ms |
| GPU memory | 7.6 GiB |
We kept all models at BF16 and did not explore quantization here, though it can help. In brief experiments, FP8 quantization gave us an additional 15% throughput boost with 44% less memory and no measurable accuracy loss. Expect a follow-up post on quantization soon.
Per-dataset breakdowns
GPT-5 nano is the most cost-efficient frontier option on every dataset, though its answer quality mostly lags behind alternatives. On the other end, Opus 4.6 consistently provides the best answers in our benchmarks while being the most expensive model we tested.
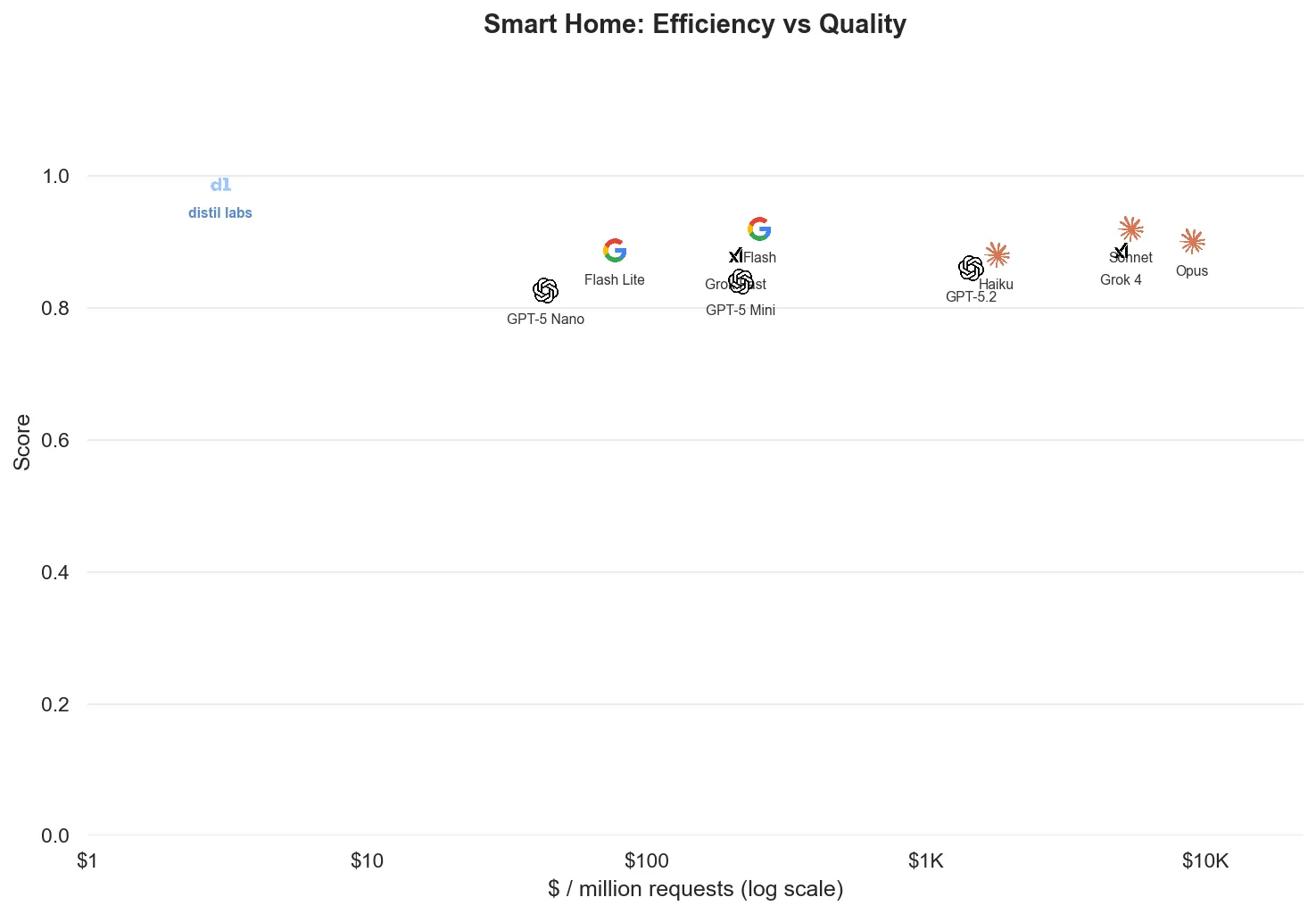
Tool-calling datasets get 2 to 4x fewer requests per dollar than classification or QA because tool schemas inflate prompt token counts. This is where fine-tuning shines brightest: a structured, well-defined problem can be solved by a tiny specialized model. For Smart Home we used Qwen3 0.6B, a model small enough to run on a phone, and it outperformed every frontier model on both quality and efficiency.
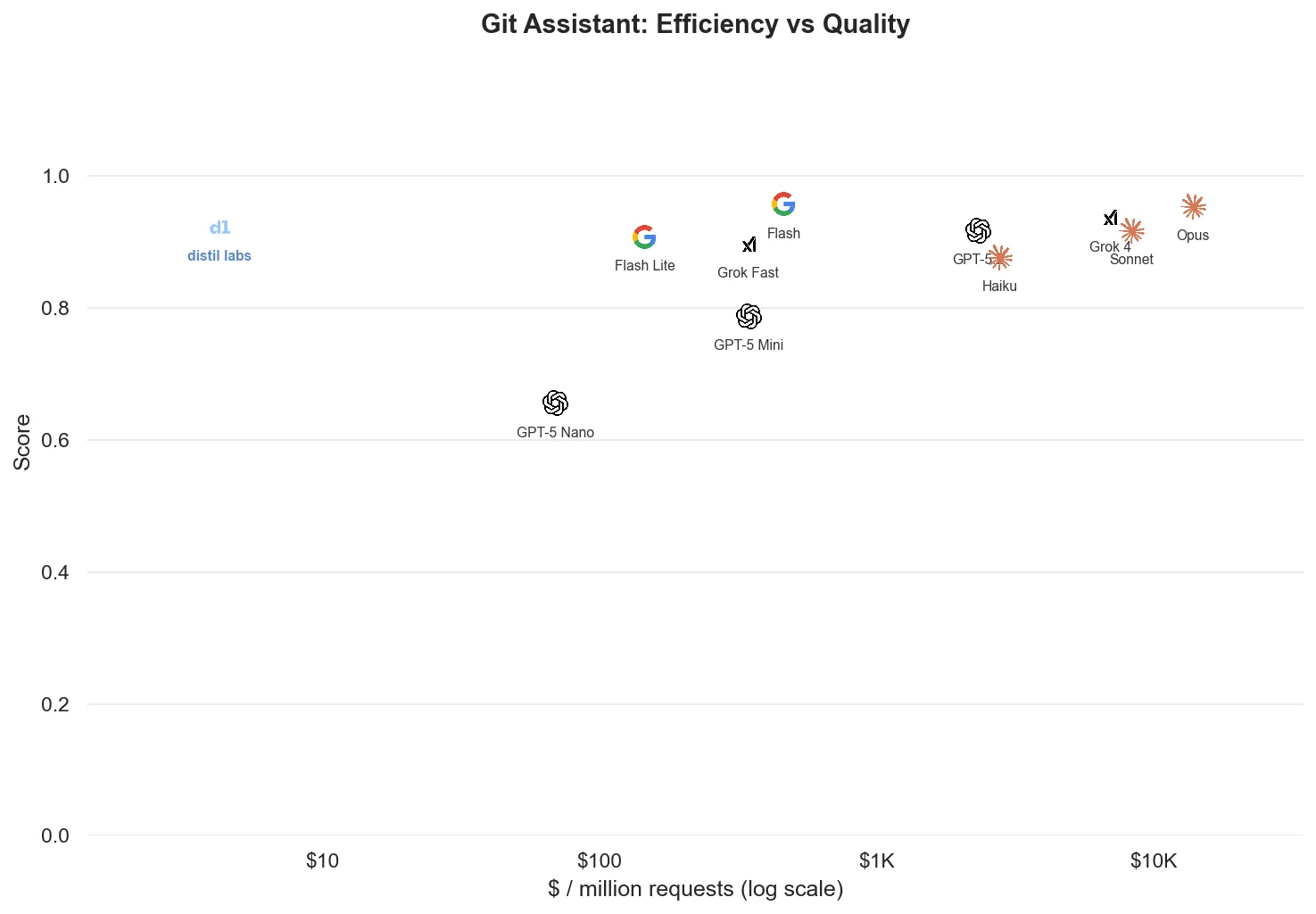
The Git Assistant dataset is also a function-calling problem, but the picture is more nuanced. Fine-tuning still wins decisively on efficiency, but frontier models are very good at git (it’s well-represented in their training data), so the quality gap narrows.
Information extraction and question answering
Non-function-calling problems with structured outputs also lend themselves well to fine-tuning. The PII Redaction Healthcare dataset demonstrates this: both efficiency and quality of the fine-tuned model outperform larger, more generic alternatives.
Text2SQL tells a similar story, though since existing models are already strong at SQL, there is less room to outperform them on quality.
The Docstring results illustrate an interesting boundary case: while the output is structured, part of it is a free-form, plain-language function description. Understanding and describing a function requires general reasoning capability, and that’s a harder area for a small model to compete in. This is where fine-tuning helps less: tasks that demand broad world knowledge rather than narrow specialization.
Classification
Classification is the most well-defined problem category, and the fine-tuned models are competitive with (and much cheaper than) frontier alternatives across the board.
When to fine-tune (and when not to)
Not every task is a good candidate for fine-tuning, and that’s OK. The best production setups combine both approaches. Fine-tune specialist models for your structured, high-volume tasks and route the open-ended problems to frontier APIs.
Fine-tune when:
- The task has well-defined structure: function calling, classification, SQL generation, entity extraction.
- Frontier models haven’t seen your specific schema or domain.
- Cost at scale matters: you’re making millions of requests per day.
- Data can’t leave your infrastructure: a self-hosted model means no patient records, financial data, or PII ever hits a third-party API. (Our PII Redaction Healthcare model scored 94.0% with everything running on-premise.)
Route to a frontier API when:
- The task requires broad world knowledge, like coding assistance or general conversation.
- Free-form generation quality matters more than structure.
- Volume is low enough that it doesn’t show up on your balance sheet.
Most production LLM spend goes to structured, high-volume tasks, exactly where fine-tuning delivers the biggest wins.
There’s also a system maturity angle: if a task doesn’t fine-tune well, it may be too broad. Breaking it into narrower subtasks often reveals better candidates. Instead of “answer any question about this domain,” split into entity extraction, classification, and targeted generation, then fine-tune each one separately.
Methodology notes
- Same test set for fine-tuned and frontier models on every dataset.
- Same evaluation criteria: exact-match accuracy for classification, tool_call_equivalence for function calling (JSON comparison after default parameter normalization), LLM-as-a-judge (Claude Sonnet 4.6) for generation tasks.
- Fine-tuned model training: 50 training examples per dataset (fewer for some). The distil labs platform handles synthetic data generation, validation, and model training from these seeds.
- Teacher models for data generation: a mixture of large open-weight models (not frontier APIs; we don’t train on outputs from closed models like GPT-5 or Claude).
- Student models: Qwen3-4B-Instruct for most datasets; Qwen3-0.6B through 8B for the Text2SQL deep-dive; Qwen3-0.6B through 1.7B for Smart Home.
- Variance: Frontier models were run 3 times per dataset; we report mean ± std. Fine-tuned models use temperature 0, so multiple runs would yield identical results.
- Cost calculation: Frontier costs computed from measured API token usage. Fine-tuned costs computed from H100 GPU time at $2.40/hr divided by measured sustained RPS.
- Pricing snapshot from February 2026.
Start saving
Most of your inference spend is going to structured tasks that a fine-tuned small model can handle just as well, or better, than a frontier LLM. The hard part has always been the fine-tuning itself: collecting training data, choosing the right base model, running experiments, validating quality. That’s what distil labs automates.
Give us a task description and 50 examples. We’ll generate synthetic training data, fine-tune a model, and deliver a production-ready small expert in under 12 hours. No ML team required.
Sign up at distillabs.ai and stop paying the inference tax.