Our senior Android engineer pinged the team Slack at 11 PM PST. “Blocked. Need design mock for payment flow before I can merge this PR.” The designer was halfway across the world, just wrapping up their day. Eight hours minimum before anyone could respond. Sprint goal at risk. PR goes stale. Engineer context-switches to something else, losing flow.
This wasn’t a one-time issue. It was a symptom. Our distributed team was chronically blocked when it came to external dependencies. Engineers spent significant time waiting for something - designs, PR feedback, API approvals, QA cycles. Sprint predictability plummeted as soon as any dependency popped up, causing frustration and delays. We needed a solution.
Further discussions revealed that all blockers for the team were caused by three high level structural problems. All the specific blockers we identified (listed later in this post) were caused by one or more of these problems.
Organizations now expect teams to be more cross-functional than ever. The lines between specializations within engineering are already blurring. Our teams have already seen engineers successfully (and quickly) transitioning into full stack roles without much guidance. In this situation, “old” processes cause more harm than benefit and prohibit engineers from moving fast. E.g. security reviews require three approvals for database schema changes. Engineers learned to batch changes, creating integration risk. As AI adoption raises expectations from engineering teams, teams must re-evaluate processes to avoid unnecessary friction.
Cross-team work like approvals, reviews, or key architecture decisions created these bottlenecks. In a high functioning, well thought engineering org, these dependencies are expected. I’d argue they are necessary to ensure a balance between speed and accountability. With AI adoption increasing the committed LOC by many factors, teams need to rethink these dependencies to avoid creating bottlenecks. In a recent AI meetup I attended, the entire room(100+ engineers) raised their hand when asked if they(or their teams) are struggling with PR review as their primary bottleneck. Dependencies become blockers especially when they require synchronous coordination of teams with different priorities.
Timezone differences exacerbate any bottleneck or friction by multiple factors. Quick clarifications don’t happen. Add a separate holiday calendar on top of this, teams lose weeks of productivity just overcoming this blocker. Because of the cross functional expectations(as mentioned earlier), even if your immediate team is co-located, they’ll still be expected to work with other teams or even customers in a different timezone.
Research shows median lead time increases 2-3x when blocking dependencies exist. Our throughput looked fine on paper. But engineers spent 20% of their time waiting.
The breakthrough came during a sprint retro.
We’re not blocked by technology. We’re blocked by how we organize work.
Three insights emerged from our discussions during sprint retros and AI adoption discussions:
Dependency blockers signal synchronous process. If Team A constantly waits for Team B, the scope boundary is wrong. Event-driven team architectures eliminate synchronous dependencies. Think of event-driven team architecture as similar to the widely popular Event Driven Architecture. Teams publish events, consumers process asynchronously.
This method is probably a reverse approach to Conway’s Law, in that we’re modelling the organizational structure based on the software architecture. This works because it’s a safe assumption that most architectures today are microservices based, even if teams are small. We’ll maybe see a new variant of Conway’s law as smaller teams start shipping more complex architectures.
Approval blockers signal trust gaps. Engineering teams traditionally guard their domain because they’re accountable for the quality. e.g. DevOps teams protect infrastructure code aggressively to avoid production breakdowns. Any mature system requires these checks and balances. We don’t expect all engineers to suddenly gain subject matter expertise in areas unknown to them previously.
At the same time, walls need to come down if teams have to move fast collectively. Why 5x Engineers Don’t Make 5x Teams explores why it’s important for systems to evolve to enable high team throughput.

Information blockers signal silos. Systems don’t self-service their consumers. Most of the times, they’re also heavily gated. Figma doesn’t need to be gated only for designers. Feature flags need to be available for faster iteration. Waiting for QA to run tests or designers to generate mocks means you haven’t automated the routine stuff.
Async-first distributed teams achieve 3+ hours of uninterrupted deep work consistently. We were achieving 45 minutes.
We established a simple rule:
If you’re blocked for more than two hours, you’re choosing to be blocked.
This wasn’t about blaming engineers. It was about changing how we think about blockers. Every blocker can have five responses. Each response has a tradeoff and as a manager, you want to avoid trust busting responses.
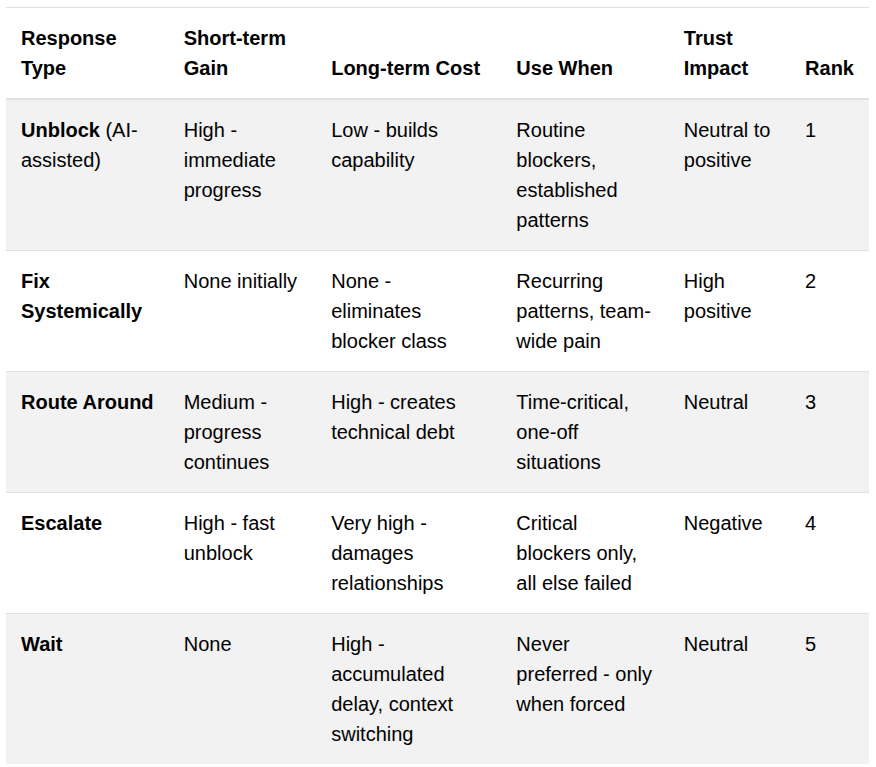
The principle forced us to confront reality: most blockers weren’t technical constraints. They were organizational choices we could change.
We made few systematic changes to operationalize the “Never blocked” principle:
Document every blocker pattern in retros. Track them like bugs. Fix them systemically by adopting ai tools and augmenting our processes. The team owns their velocity. For example, the team consistently needed multiple reviews every time they had a dependency on the SRE team. Solution was to codify all the practices of SRE team and use persona-driven code reviews (AI Adoption Framework) before sending the PR. This eliminated most of the tactical feedback and also solidified the event driven team architecture.
Eliminated cross-team approval gates for routine changes. Built a decision framework: delegate authority for reversible decisions under $10K impact. Everything else escalates with clear SLAs. We recently removed 2 mandatory human reviewers on each PR to one human and one automated review tool. This can be improved further. Let’s try this: Each PR immediately triggers an automation pipeline to assign a risk/criticality rating to the PR. The team owning the code defines the rating criteria. If the risk rating is <=5, the mandatory human reviewer can be anyone from the team sending the PR.
After identifying specific day to day blockers, we addressed them by category with each requiring different solutions:
")
Waiting for other teams’ APIs, services, or approvals:
Event-driven team architecture eliminated synchronous dependencies
API contract definitions in shared repos - teams develop against contracts, not implementations
No timezone coordination required for routine work
Teams auto update their external contracts as they (or their agents) write code
Waiting to understand legacy code, architecture decisions, or domain context:
AI-powered codebase exploration tools reduce “Who wrote this?” questions
Architecture documentation auto-generated from code structure
Historical decision context retrievable without tribal knowledge
Eliminated “Dave wrote this 6 months ago” bottleneck
Waiting for QA cycles, staging environments, or production access:
Sitemap Navigator knows entire website structure for automated testing
Uses bug information to automatically repro and test fixes
What took QA a day takes CI pipeline 15 minutes
Automated rollback detection and staging environment management
From months to weeks turnaround for deployments
Waiting for mockups, design reviews, or visual specs:
Built a UI Agent that generates pixel-perfect component mocks matching our design system
Designer creates the system once. Engineers self-serve implementation mocks
No waiting. No approximations. Mock matches production design
Applied to vehicle deployment UI before designs ready - development continued without blocking
Sprint predictability improved from 60% to 85% completion rate. Idle time, which we tracked in retros as “hours waiting for unblock”, dropped from 12 hours per engineer per sprint to under 8.
Most importantly: cultural shift. Engineers now own their velocity. When blocked, they don’t wait - they escalate or solve. 80%+ of potential blockers self-resolve without manager intervention.
The before-after is stark:
")
Week 1: Measure your team’s blocked time. Track every instance where work stopped waiting for something. Categorize by type:
Dependency blockers: Waiting for other teams’ APIs, approvals, or services
Knowledge blockers: Waiting to understand code, decisions, or domain context
Validation blockers: Waiting for QA cycles, environments, or production access
Design blockers: Waiting for mockups, specs, or visual assets?
Week 2-3: Pick your top blocker category. Design a self-service solution:
Dependency blockers → Event-driven team architecture, contract definitions
Knowledge blockers → Documentation automation + AI code exploration
Validation blockers → CI/CD automation + environment self-service
Design blockers → Component libraries + automated mock generation
Week 4: Establish the “never blocked” operating principle. Two-hour rule. Document and fix systemically.
For distributed teams specifically: identify the most common timezone-blocked interaction. Build async infrastructure like documentation, automation so teams don’t need synchronous coordination for routine work.
The goal isn’t zero blockers. The goal is zero blockers you haven’t systematically addressed.
If you’re navigating distributed team challenges or have creative unblocking strategies that worked for your team, I’d love to hear your approach. Reach out to continue the conversation.