Oracle to PostgreSQL migrations always fascinate us as there is so much to learn from both databases. One has been ruling enterprise workloads for decades, and the other is appealing enough for almost every enterprise to seriously evaluate.
Most enterprises still run on Oracle, and it’s tempting to explore how the same applications would function on PostgreSQL as an ideal open source transactional database alternatives. Migrations are always liberating and at the same time a real pain if proper due diligence is not followed from day one.
In this blog series, we will share key considerations for DDL migration that we have curated as part of continuous migrations we supported for our enterprises customers across all domains and highlight key common gotchas you should be aware of, regardless of the tools or LLM you use.
This blog focuses specifically on DDL Conversion that typically involves translating all table DDLs, including data types, columns, constraints, indexes, partitions, and even statistics.
Translating table DDL is usually the first task any migration engineer performs post assessment.
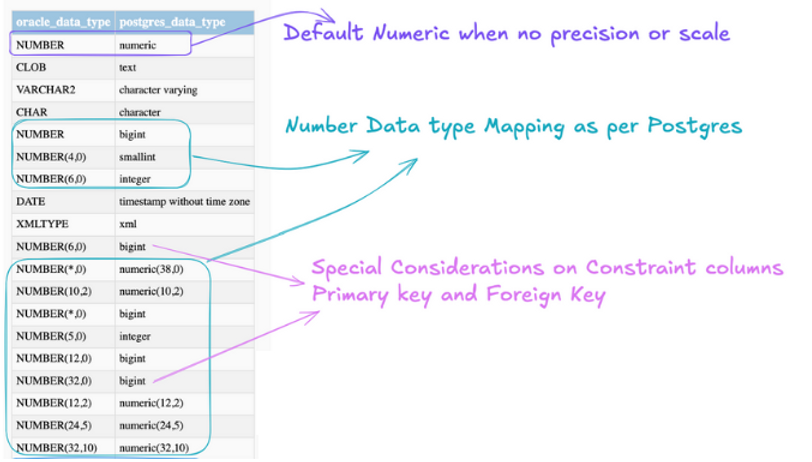
Data Type Mapping — NUMBER Data Type
NUMBER, VARCHAR, and DATE are the core foundational data types that are widely used across applications. In traditional Oracle databases, it is very common to just use NUMBER without precision and scale as a generic data type for many columns.
When a column is defined simply as NUMBER, It is important to translate it carefully into an appropriate PostgreSQL type such as INTEGER, BIGINT, or NUMERIC based on both the underlying data characteristics as well as on the constraints defined on the column.
If the column is a primary key, there is a high chance that it belongs to the integer family and should be mapped accordingly.
⚠️ Tooling Tip When choosing a conversion tool, be cautious.If your preferred tool blindly converts every NUMBER column into NUMERIC, please run away from it as fast as possible 😄

Why not always use NUMERIC?
NUMERIC is attractive because it avoids data precision and overflow issues but it is also an expensive choice in terms of performance and storage.

Use NUMERIC only when you truly need arbitrary precision, such as:
Monetary values
Scientific or analytical values requiring exact precision
For most counters, identifiers, and range-based values, INTEGER or BIGINT is faster, smaller, and more efficient. If the column is a primary key on an ever-increasing sequence, BIGINT is usually the safer and more future-proof choice.
Sharing an sample data type mapping from an actual migration.
🚀 Want to level up your database migration skills? Check out our hands-on course at DatabaseGyaan
2. Partitioned Tables with Primary Keys Excluding Partition Columns
PostgreSQL is quite mature when it comes to partition management and supports multiple partitioning strategies such as RANGE, LIST, and HASH. However, one important concept that PostgreSQL does not support (unlike Oracle) is global indexes.
This difference becomes critical when your primary key in Oracle does not include the partition column.
In PostgreSQL, a primary key on a partitioned table must include all partitioning columns. If your Oracle design has a primary key defined on columns other than the partition key, it cannot be migrated directly.

To resolve this, you typically need to:
Change the overall partitioning strategy, or
Add the partition column to the existing primary key (usually as a non-leading column),
Partitioned Tables with Foreign Keys When the Partition Column Is Not Part of the Original Primary Key
If you choose to modify the primary key by adding the partition column to it, you must also account for any existing foreign key references.
This change introduces additional complexity in translating foreign key constraints, because all referencing tables must now include the partition column as part of their foreign key definition as well.
As a result, you typically need to choose between:
Propagating the partition column into all child tables and updating their foreign key definitions accordingly, or
Dropping foreign key constraints at the database level and enforcing referential integrity at the application tier, or
Using a legacy-style approach with custom triggers to maintain consistency manually.
Each of these options comes with trade-offs in terms of correctness, complexity, and operational risk, and should be evaluated carefully based on your workload and data integrity requirements.

4. Oracle to PostgreSQL - Boolean Transformation
Traditional Oracle versions did not have a native BOOLEAN data type (until Oracle 23ai). As a result, boolean-like values were commonly represented using types such as CHAR(1) or NUMBER(1) to indicate true / false. These representations were also compatible with many Java frameworks and libraries that performed implicit boolean mapping.
However, if you migrate such columns as-is into PostgreSQL, the database-level conversion may look correct but things often start to fall apart when the application begins interacting with the new schema.
This is because PostgreSQL has a proper BOOLEAN type, and application drivers, ORMs, and query logic typically expect true boolean semantics rather than encoded values.
It is therefore advisable to:
Identify columns that semantically represent boolean values,
Validate their actual data patterns (Y/N, 1/0, T/F, etc.),
And explicitly transform them into BOOLEAN during migration.
For example, a column storing 'Y'/'N' or 1/0 in Oracle should be transformed to BOOLEAN with an explicit conversion during data migration.
This small transformation significantly improves schema clarity, application compatibility, and long-term maintainability.
Partitioned Tables with Interval or Reference Partitioning
Oracle provides advanced partitioning features such as interval partitioning and reference partitioning, which allow new partitions to be created automatically as new data arrives, or based on referential relationships between tables.
PostgreSQL does not manage the creation of new partitions automatically. To achieve similar behavior, you typically need to rely on extensions such as pg_partman and schedulers like pg_cron to create and manage future partitions.
However, choosing a solution is only part of the problem. You must also decide how to handle the migration of existing partitions:
Do you migrate them exactly as they are and later use pg_partman for future partitions only.
Do you recreate them using a tool like pg_partman based on a defined start date or range?
This decision is important because migrations are not only about reproducing the current state they are also about ensuring that the system behaves correctly for future data.
We have seen cases where systems passed testing successfully, but later failed in production because future partition creation was not handled as part of the migration design.
Database Objects with the Same Name
This is an interesting difference between Oracle and PostgreSQL.
In Oracle, it is possible for different object types such as a table and a constraint to share the same name within a schema. PostgreSQL does not allow this.

PostgreSQL requires object names to be unique within a schema across certain object types. As a result, if a table, constraint, or index shares the same name, the migration will fail.
Therefore, it is important to proactively identify such cases and rename the conflicting objects before or during migration.
If you attempt to deploy such a schema directly into PostgreSQL without resolving these conflicts, you will encounter errors during DDL execution.

⚠️ Tip A simple pre-migration audit query to detect name conflicts can save a lot of deployment-time surprises.
Internally, PostgreSQL stores metadata for relations (tables, indexes, sequences, etc.) in the pg_class catalog, which enforces uniqueness on the combination of object name and schema. This is why two objects with the same name cannot coexist in the same schema.
DEFAULT ON NULL Constraint
Oracle supports the DEFAULT ON NULL clause, which allows a default value to be applied when a column is explicitly set to NULL. PostgreSQL does not currently support this behavior.
To avoid deployment errors, some conversion tools translate DEFAULT ON NULL into a regular DEFAULT or even into a NOT NULL + DEFAULT combination. This changes the semantics, because the default then applies in more situations than intended not only when NULL is explicitly provided.
As a result, it is important to:
Identify columns that use DEFAULT ON NULL in Oracle,
Understand the intended behavior,
And decide how (or whether) to emulate it in PostgreSQL.
Blindly translating it can lead to subtle data behavior changes that are hard to detect later.
Data Type Mismatch Between Primary Key and Foreign Key
During migration, many hidden inconsistencies in the schema start to surface. These often get interpreted as “PostgreSQL is not behaving as expected,” while in reality they are design mismatches that were silently tolerated earlier.
One common example is a data type mismatch between primary keys and their corresponding foreign keys.
If a primary key is defined as one numeric type (for example NUMBER(10) mapped to BIGINT) and the foreign key is mapped to a different type (for example NUMERIC or INTEGER), it can lead to:
Implicit casts during joins,
Index usage issues,
And unnecessary performance overhead.
To avoid this, primary key and foreign key columns should always belong to the same numeric family and have compatible definitions in PostgreSQL.
Taking conscious steps to standardize these mappings during DDL conversion significantly reduces both functional surprises and performance issues post-migration.
Special Attention to Data Types
One thing you will both love and hate about PostgreSQL is how strict it is about data types.
At the same time, one thing you may love and later regret about Oracle is how much it hides from the user on implicit casting , sometimes at the cost of performance or long-term clarity.
In PostgreSQL, data type consistency really matters. Comparisons across columns, and even comparisons with constants, must be handled carefully to avoid implicit casts, unexpected plans, or subtle performance problems.
Take a look at the default assumptions PostgreSQL makes for constants and their underlying data types:

Prioritize data types at the start of your project or spend a lifetime fixing them.
If you are in the migration phase, evaluating conversion tools, or considering a “fancy AI-enabled” solution, make sure it does more than just convert syntax. It should help you arrive at an optimal, consistent schema one that is built to last and does not break down in the initial stages and erode confidence in PostgreSQL.

Don’t Miss the Extended Statistics
When we talk about a typical database migration, we usually focus on schema, code, data, and configuration. However, one critical component that is often overlooked is extended statistics.
Extended statistics are expression-based or dependency-based statistics computed on one or more columns. They help the query planner make better cardinality and selectivity estimates.
In most migrations, extended statistics are either skipped or ignored. But a successful migration is not just one that is PostgreSQL compatible or functionally equivalent, it must also be predictably performant.
In Oracle, extended statistics are automatically created for function-based indexes.
For example, if you have a function-based index like:
Oracle internally creates extended statistics on this expression, which can then be used by the optimizer to produce better estimates when the expression appears in query predicates.
If we migrate the index but not the corresponding statistics, the PostgreSQL planner may not have enough information to choose an optimal execution plan. This often results in unexpected plan changes and performance regressions.
Migration is more than just moving code and data. To ensure stable and predictable performance, we must also migrate or recreate supporting components such as extended statistics. Ignoring them can turn a technically correct migration into an operationally inefficient one.
A successful Oracle to PostgreSQL migration requires addressing all of these schema and DDL considerations not just converting syntax.
DDL migration is a critical part of any database migration and deserves special attention. Ignoring these considerations leads to an incomplete and fragile migration.
