AMD, Intel, Nvidia, Arm, and Qualcomm are all selling datacenter CPUs into the AI buildout. The previous piece mapped them across five sockets orbiting the GPU and ranked those sockets by value: coherent host, standard host, thinker, doer, traditional cloud.

The coherent host is the most valuable. The traditional cloud CPU is the least.
Many readers asked if it matters whether the CPU is x86 or Arm.
Honestly, not as much as made out to be. But let’s go socket by socket.
The ISA is the language a CPU speaks. Software gets compiled into that language, and a chip can only run code written for its dialect.
x86 has been the server default for decades. Yet Arm has been gaining in servers, first slowly, then quickly as Graviton, Axion, and Cobalt took hold in cloud, and now inside AI infrastructure as hyperscalers build Arm into their GPU server stacks.
Naturally, everyone asks which ISA is “better” for agentic AI; they’re both just fine.
The more interesting question at each socket is whether the software running there cares which ISA it runs on? Specifically, is the ISA a “moat” at any of the agentic sockets? Let’s see:
The coherent host’s moat is the coherent link to the GPU, not its ISA.
NVLink-C2C connects Nvidia’s Grace CPU to the Blackwell GPU at 900 GB/s, providing a shared address space in which the GPU reads CPU DRAM as if it were local. Vera doubles that to 1.8 TB/s with Rubin. Infinity Fabric ties AMD’s EPYC to the Instinct MI455X at comparable bandwidth. The coherent link is what makes this socket valuable. It’s what no other CPU can replicate without a bilateral design agreement with the GPU vendor... like NVLink Fusion...
Before Grace, Nvidia GPU servers shipped with standard x86 hosts (Intel Xeon or AMD EPYC) connected over PCIe. Grace Hopper (2023) was Nvidia’s first coherent superchip: Grace CPU (Arm, Neoverse V2) connected to the Hopper GPU via NVLink-C2C at 900 GB/s — and Nvidia’s first deployment of the full datacenter CUDA stack on an Arm server CPU. CUDA already ran on Arm through the Jetson embedded line, but this was the server-grade debut.
Grace Blackwell carried that forward; Vera Rubin extends it with a custom Arm CPU (88 Nvidia-designed cores) at 1.8 TB/s to Rubin.
So clearly, ISA isn’t a differentiator for the 800-lb gorilla. Host software runs on either.
What about AMD? ROCm is effectively x86-native. AMD’s coherent platform is built around EPYC, so an Arm port has naturally never been a priority.
The main takeaway is that the ISA is baked into the accelerator platform choice.
NVLink Fusion is Nvidia’s move to open the coherent-host socket to third-party CPUs. Previously, the only CPU that could claim a coherent seat on Nvidia’s backend was the one Nvidia built (Grace/Vera). NVLink Fusion allows other vendors to couple their processors to Blackwell GPUs over the same high-bandwidth coherent link Grace uses. Note that no NVLink Fusion product has actually shipped yet, these are simply announced partnerships. But the partner list includes Qualcomm (Arm), Fujitsu, Intel (x86), and SiFive (RISC-V).
If and when these ship, the coherent-host socket will be accessible to any ISA, so the moat is most definitely not the ISA. RISC-V even... although lots of software porting required.
The standard host’s job is to keep the GPU fed: tokenize inputs, batch requests, stage data over PCIe, manage memory. The CPU needs to work as fast as possible and also move a lot of data. PCIe can become a bottleneck here… hence the coherent host.
The hyperscalers started with x86 standard hosts paired with their XPUs, but that has moved toward Arm. AWS pairs Graviton with Trainium. Google pairs Axion with its gen 8 TPUs.
The feed-the-XPU stack runs on x86 or Arm interchangeably; ISA is not the moat.
Note that there is still an x86 standard-host business in smaller deployments, specifically enterprises and small neoclouds running DGX, Instinct MI355X, RTX Pro 6000 servers, and so on.
In these setups, the host often runs double duty with GPU feeding and application-tier workloads on the same box. That brings legacy x86 software dependencies back into the picture, and ISA does matter. Lower volume, but will grow.
Takeaway: if the host is doing double duty as application processor, then ISA matters. Otherwise, nope.
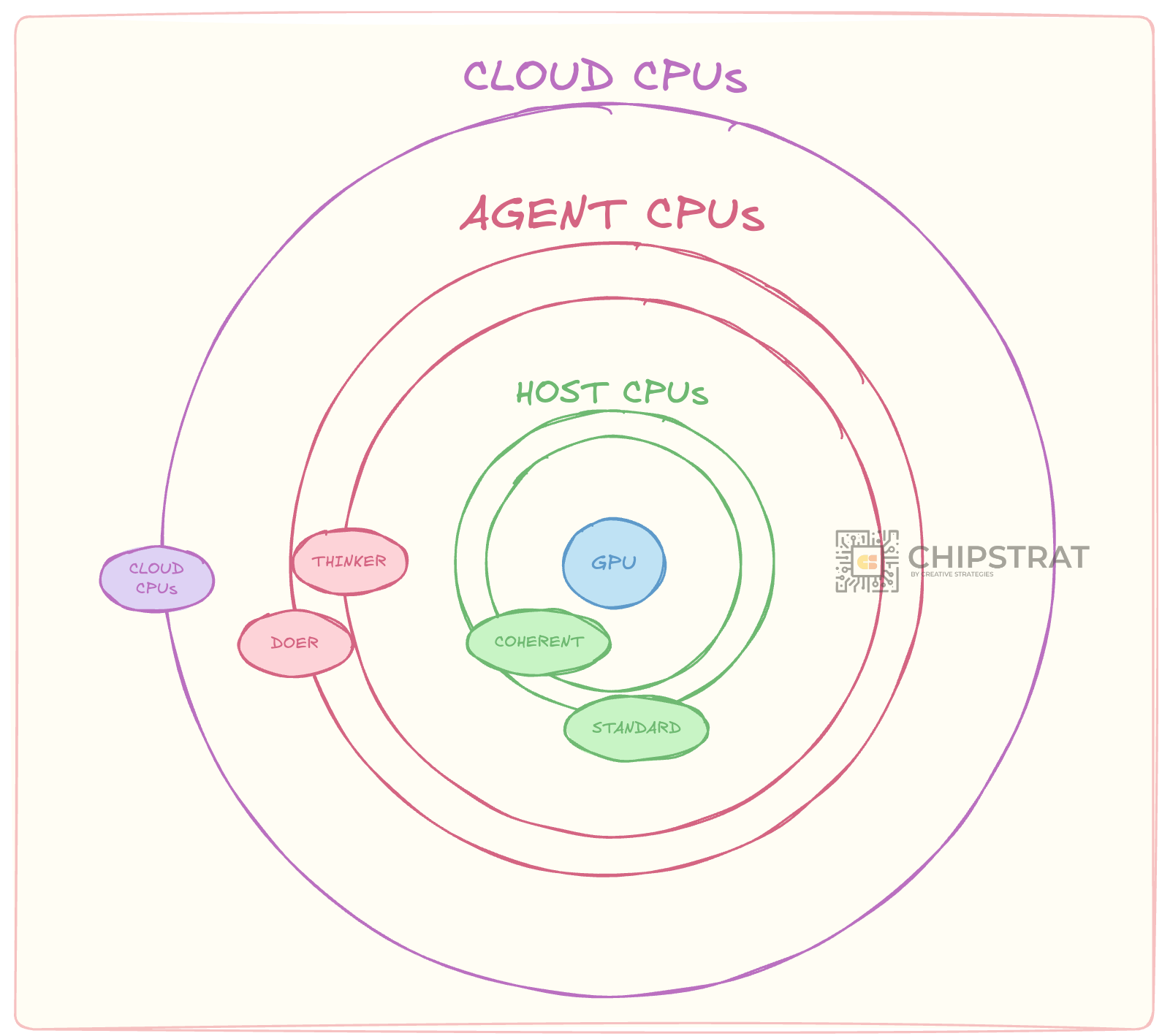
The two orbits closest to the GPU give the same answer: ISA does not matter there. The three that remain do not all agree. One has a real x86 lock-in story. One has a wrinkle. One… not so much.
The thinker is the GPU-coupled agent: reasoning-heavy work that runs close to the GPU on the scale-out backend, passes large contexts to the model, and needs per-core performance and low round-trip latency above all else. Real-time world model controllers, agents driving tight perception-action loops, anything where a single network hop eats the frame budget.
The thinker commands a higher ASP than the doer. That premium is earned on per-core performance and bandwidth, not protected by a proprietary link. The scale-out backend runs over open InfiniBand or Ethernet, reachable by any NIC-equipped CPU. AMD Venice Classic (Zen 6, high-frequency cores), Intel Diamond Rapids (P-cores, 2027), Nvidia Vera, Qualcomm Oryon, and Arm AGI in its thinker-flex configuration can all reach it. Every major ISA in the same fight.
The software stack for thinker agents consists of Python, orchestration frameworks, and custom agent runtimes built over the last two years, running in containers and targeting both architectures from day one. There is no installed base of thinker software to be locked into, because the thinker socket barely exists at volume yet. Most agentic work today is coding agents, and that is a doer workload. So when the thinker software stack gets written at scale, it will be ISA-agnostic by default.
Hence, the ISA question is already settled before the volume arrives.
The doer is the most valuable orbit where ISA matters.
The doer is the action agent: coding, tool use, web search, API calls, compiling, running tests, filing pull requests. The metric is threads per watt — run as many agents as possible per rack. The agent’s own orchestration code is ISA-agnostic. Python runs anywhere. The frameworks that drive agents are all multi-architecture.
Yet the ISA matters in the execution environment the agent spins up.
If the target codebase compiles x86 binaries, e.g. a C++ service, a Go application, a Rust binary targeting x86 Linux and runs x86 test suites, you need x86. Yes technically you could use an x86 CPU emulator on Arm but that would kill performance.
So the doer’s ISA dependency is a dependency on what the target codebase compiles to, not on the agent runtime itself. A coding agent deployed to assist a Python web shop has no meaningful ISA dependency, but a coding agent deployed against a legacy enterprise C++ codebase does!
This matters for companies running agents against their own internal codebases. Their internal build pipelines, CI systems, and test suites were likely written assuming x86. Years of accumulated toolchain dependencies. The long tail of enterprise repos still carries enough x86-specific build logic that moving to Arm would require real migration work. That’s where ISA creates genuine friction today. LLMs make it easier than ever, but it’s still work. Maybe Fable can one shot it though...
So doer agentic CPUs, especially in bigger enterprise deployments, have an ISA dependence.
Agentic AI is also driving traditional cloud workloads. Agents ultimately query ERPs, hit databases, and call APIs, all of which run on general-purpose cloud CPUs.
This is the orbit with real x86 legacy lock-in. Proprietary enterprise software from the 2000s and 2010s shipped as x86 binaries, sometimes with no source code and no porting path.
Definitely an ISA moat here. But the least value capture in the agentic AI path. Moreover, this ISA moat is shrinking over time.
But it’s real, especially for enterprises.
x86’s moat lives at the outer orbits: the traditional cloud socket, where old software licenses and ISV certifications built a real moat, and the doer socket, where it depends on what the agent actually executes.
The playing field is level at the inner orbits where the software is new, the frameworks were built for containers, and competing on power efficiency matters more than installed base.
The most valuable socket, the coherent host, does not care about the ISA. It cares about which accelerator agreed to share a coherent address space with you.
The closer you get to the GPU, the newer the software and the less the ISA matters.