You don't orchestrate your engineering team with a flowchart. So why are you orchestrating your agents that way?
If you've built anything with multiple AI agents in 2025, you probably started the same way everyone does: you drew a diagram. Agent A calls Agent B. Agent B passes output to Agent C. Maybe there's a conditional branch. Maybe some fan-out parallelism. You wired it up in LangGraph or CrewAI, stared at your beautiful directed acyclic graph, and felt like an architect.
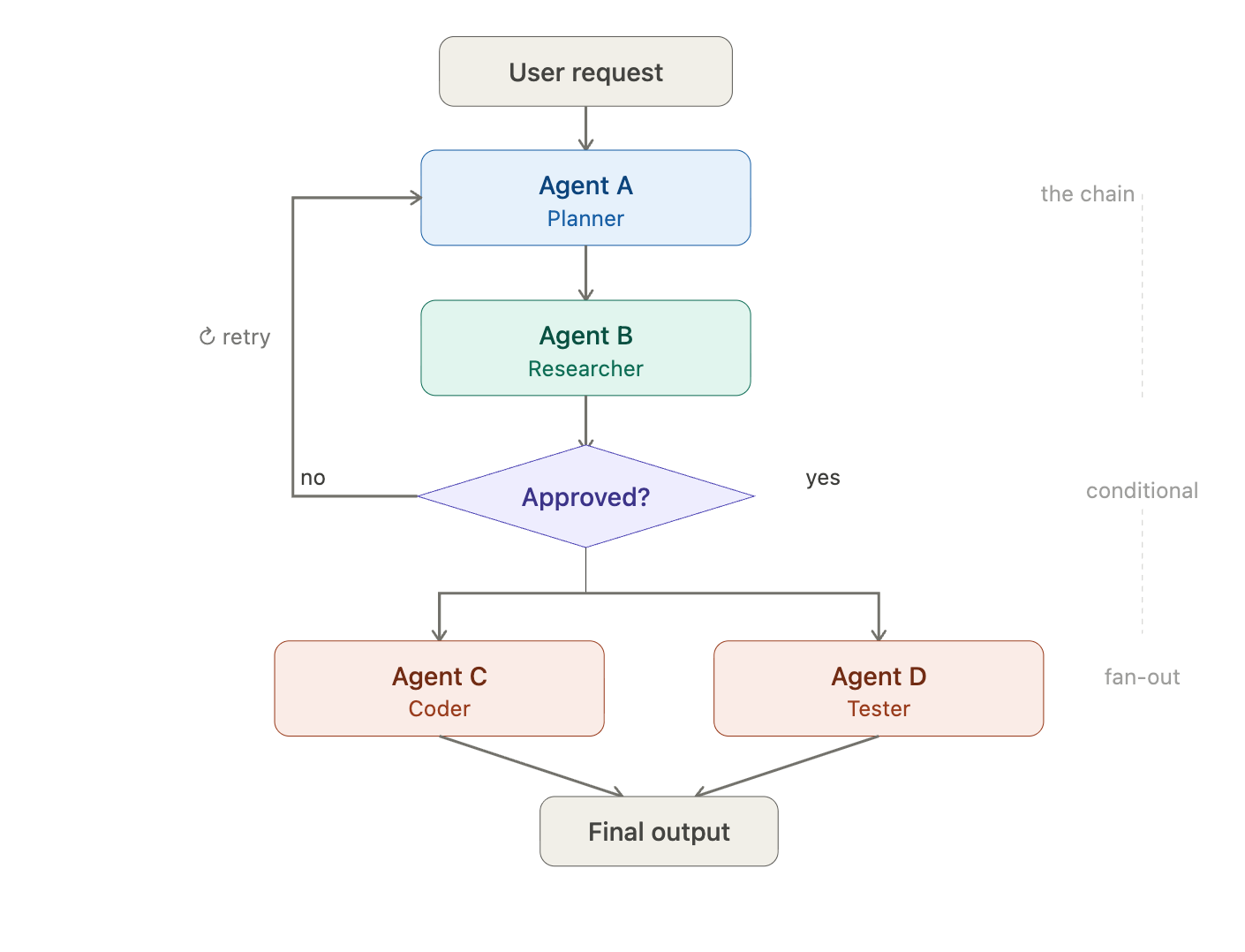
Then you tried to make it do something real, and the whole thing fell apart.
We've been there. And after building in this space for a while, I've become convinced the DAG - the dominant mental model for multi-agent orchestration - is fundamentally the wrong abstraction for the AI applications developers actually need to build.
The DAG Feels Right Until It Doesn't
Let's be fair to the DAG.
For linear, predictable workflows - extract this document, classify it, summarize it, done - a graph of nodes and edges works beautifully. The execution order is known and predictable. The state transitions are clean. You can visualize it, debug it, and check-point it.
But here's the thing: those aren't the hard problems anymore. A single well-prompted agent with tool access can handle most linear pipelines without an orchestration framework at all. The moment you reach for multi-agent coordination, it's almost always because the task is not linear. It's dynamic. It's collaborative. It involves judgment calls that can't be hardcoded into edge conditions.
Consider what happens when you try to build something like a code review workflow with a DAG:
A planning agent designs an implementation approach.
A coding agent writes the implementation.
A review agent evaluates the code for correctness and style.
If issues are found, loop back to step 2 for revisions.
Once approved, CI runs tests.
Merge.
Simple enough on a whiteboard. But what if the reviewer has a question - not a rejection, but a clarification? What if the planner realizes mid-plan that it needs input from a third agent that understands the existing codebase? What if a human developer jumps in with a constraint that invalidates the whole graph?
In a DAG, every one of these scenarios requires you to anticipate and encode the path in advance. You're not building an intelligent system.
You're writing a very elaborate if/then/else statement with LLM calls inside it.
The Fundamental Mismatch
The deeper issue is philosophical. DAG-based orchestration assumes that the developer is the coordinator. You, the human, define every possible flow at design time. The agents are just functions that execute within the boundaries of your graph. The "intelligence" is in the topology, not in the agents.
This made sense in the era of chains - when an LLM was essentially a fancy text-in, text-out function. But modern agents aren't functions: they can reason, they can plan, they can decide who to talk to and when. Forcing them into a predefined execution graph is like hiring senior engineers and then handing them a minute-by-minute task schedule. You've negated the thing that makes them valuable.
The result is a predictable set of failure modes that anyone who's built with these frameworks will recognize:
Brittle branching. Your conditional edges handle the three scenarios you thought of. The fourth one - the one that actually happens in production - routes to a dead end or triggers an infinite loop.
Context starvation. Agent B needs something Agent A knew but didn't pass through the state object, because you didn't anticipate that dependency when you designed the graph.
Combinatorial explosion. Every new agent or capability multiplies the number of possible paths. What started as a clean five-node graph becomes a spaghetti diagram that nobody wants to maintain.
The human-in-the-loop afterthought. DAG frameworks treat human intervention as an interrupt - a checkpoint where execution pauses. But real collaboration isn't a pause. It's an ongoing conversation.
What Actually Works: Look at How Humans Coordinate
Here's an observation that should be obvious but somehow isn't: we already solved multi-agent coordination - it's called a group chat.
When a team of engineers collaborates on a complex task, they don't draw a DAG and execute it. They join a shared channel. They post messages. They @mention the person (or bot) whose input they need. They share context asynchronously and self-organize around the problem.

The coordination primitives are remarkably simple:
A shared space where work happens in the open.
@mentions to direct attention and route relevant context to the right participant.
Messages as the unit of communication - rich, contextual, flexible.
Scoped visibility: agents see what they need when they need it, not a firehose of everything.
Asynchronous flow where agents respond when they have something to contribute, not when a graph edge tells them to.
This isn't a metaphor - it's a protocol, and it maps almost perfectly to how agents actually need to work together.
When a planning agent finishes a design and writes "@Reviewer, take a look at this plan," something powerful happens: the reviewer gets context, intent, and a clear delegation - all in a single, natural interaction. There's no state schema to maintain. No edge condition to encode. No graph to redraw when the reviewer decides to loop in a third agent.
The Code Review, Revisited
Remember the three scenarios that broke our DAG? Here's how each one plays out in a chat-based model.
The reviewer has a clarification question - not a rejection. In a DAG, there's no edge for "question." You'd need a new branch, a new state, a new handler. In a chat, the reviewer just posts: "@Coder, is this auth flow supposed to handle expired tokens, or just invalid ones?" The coder responds in the same thread. The conversation continues. No new edges required.
The planner realizes mid-plan that it needs input from an agent that understands the existing codebase. In a DAG, this is a redesign - add a node, wire it in, update the state schema, retest. In a chat, the planner writes: "@CodebaseAgent, what pattern does this repo use for middleware?" It gets an answer and incorporates it. The other agents didn't even need to know this happened.
A human developer jumps in with a constraint that changes the approach. In a DAG, this is an interrupt - execution pauses, the human modifies state, and you pray the graph can resume cleanly. In a chat, the developer posts: "Hey, we can't add new dependencies to this service - it's in a dependency freeze until the next sprint." Every agent in the room reads this. The planner revises. The coder adjusts. Nothing broke because there was nothing rigid to break.
Same scenario, same complexity. The difference is that the chat model didn't require you to anticipate any of it.
The asymmetry shows up clearest when you try to extend the system. Adding a new agent to a DAG means defining the node, wiring every edge in and out of it, updating the state schema to pass the right context, handling every new conditional branch, and retesting the whole graph because you've changed the topology. Adding a new agent to a chatroom means connecting it, giving it a role prompt, and telling the other agents it exists. The agents figure out when to involve it from context, not because you drew an arrow.
No graph. No state machine. Just structured conversation.
"But What About Control?"
Wait, but chat sounds chaotic. How do you prevent infinite loops? How do you enforce an execution order? How do you debug?
Fair questions.
Here's the thing - the chaos isn't in the coordination model. It's in the lack of guardrails. And guardrails work just as well (better, actually) in chat-based systems.
Loop prevention. A simple protocol does most of the work: @mentioning an agent triggers a response, and after responding, agents go silent until @mentioned again. This prevents the runaway ping-pong that plagues naive multi-agent setups. It's a social contract, enforced through role prompts, not a topological constraint.
Execution order. When order matters, agents express it naturally: "I'll draft the plan first, then @Reviewer can evaluate it." Sequencing emerges from the task, not from your infrastructure. And when the task doesn't require strict ordering (which is more often than you'd expect) agents can work in parallel without you having to draw fan-out/fan-in edges.
Debugging. Every interaction is a message in a chat log. It's the most human-readable execution trace you could ask for. Do you really want to be stepping through a state graph where you're inspecting serialized dictionaries at each checkpoint, if you can avoid it?
Error handling. When an agent produces bad output, any participant - human or agent - can flag it in the chat and @mention the responsible agent for a retry. Because the full conversation history is available as context, the retry is informed by why the first attempt failed, not just that it failed. This is richer than a DAG node retry, which typically just re-executes the same function with the same inputs.
Human oversight. In a chat-based system, the human isn't a checkpoint in a graph. They're a participant in the conversation. They can jump in at any time, redirect agents, add context, or override decisions - without breaking the execution model, because the execution model is just conversation.
The Real Architecture of Agentic Work
The AI industry is going through a necessary correction. The first wave of multi-agent frameworks optimized for control - give the developer total authority over the execution path. That was the right instinct when models were less capable and agents were essentially fancy API wrappers.
But agents are getting good. Claude Code can autonomously resolve real GitHub issues across complex codebases. Codex can implement features end-to-end from a natural language spec. These aren't autocomplete tools anymore - they have judgment.
The bottleneck isn't the individual agent anymore - it's the coordination layer between them. And that coordination layer needs to be as flexible and expressive as the agents it connects.
DAGs aren't useless. They're a perfectly good tool for batch processing pipelines, ETL workflows, any task where the steps are known, fixed, and independent of runtime context. If your pipeline always goes extract → classify → summarize → store, a DAG is the right call.
But if you're building a system where agents need to collaborate - where tasks emerge dynamically, where the right next step depends on what an agent just discovered, where humans and machines need to work together fluidly - the DAG will fight you every step of the way. We're building Band on this premise, allowing agents to communicate via structured messages instead of predefined graphs.
The mental model shift is simple: stop thinking of agents as nodes in a graph and start thinking of them as participants in a conversation. The coordination primitives you need aren't edges and state schemas. They're messages, @mentions, and shared context.
The next time you reach for a multi-agent framework, ask yourself one question: am I defining a pipeline, or am I coordinating a team? If it's a pipeline, draw your DAG. If it's a team, open a chatroom.