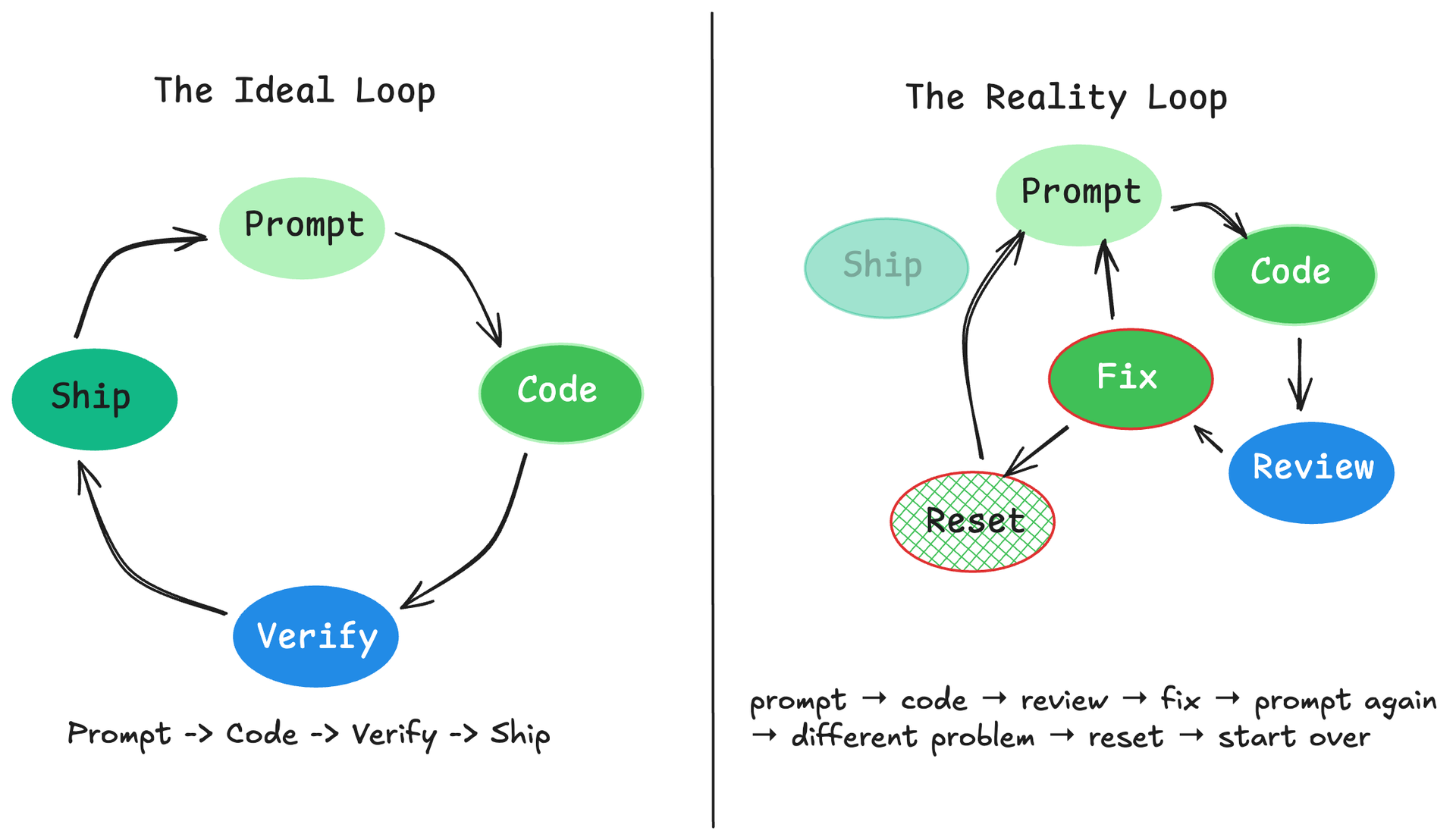
If you don't know what you're doing, AI fails with death by a thousand cuts.
This post is for subscribers only
Subscribe to continue reading
If you don't know what you're doing, AI fails with death by a thousand cuts.
This post is for subscribers only
Subscribe to continue reading

Claude Code skills work best when you treat them as workstations, not prompts: folders with scripts, gotchas, templates, and progressive disclosure that manage the agent's attention budget at runtime.
Because "it seemed fine when I tested it" is not a deployment strategy. Part 4 of 4: Evaluation-Driven Development for LLM Systems
Your evaluation technique should match the question you're asking, not your ambition.
Most teams spend weeks perfecting prompts and minutes on evaluation data. That's backwards. Part 2 of 4: Evaluation-Driven Development for LLM Systems
If five correct responses are enough to ship an LLM feature, what are you actually measuring: quality, or luck? Part 1 of 4: Evaluation-Driven Development for LLM Systems

Boris Cherny created Claude Code at Anthropic. Over three Twitter threads (early January, late January, and February 2026), he shared