As promised, let's deep dive into the learnings from my text-to-3D agent project. The goal was to go beyond simple shapes and see if an AI agent could generate complex 3D models using Blender's Python API.
The short answer: yes, but the architecture is everything.
The Core Challenge: Reasoning vs. Syntax
Most LLMs can write a simple Blender script for a cube. But a "low poly city block"? That requires planning, iteration, and self-correction—tasks that push models to their limits. This isn't just a coding problem; it's a reasoning problem.
My Approach: A Hybrid Agent Architecture 🧠
I hypothesized that no single model could do it all. So, I designed a hybrid system that splits the work:
- A "Thinker" LLM (SOTA models): Responsible for high-level reasoning, planning the steps, and generating initial code.
- A "Doer" LLM (Specialized Coder models): Responsible for refining, debugging, and ensuring syntactical correctness of the code.
I tested three architectures on tasks of varying difficulty:
- Homogeneous SOTA: A large model doing everything.
- Homogeneous Small: A small coder model doing everything.
- Hybrid: The "Thinker" + "Doer" approach.
The Results: 3 Key Takeaways 🏆
The data from the experiments was incredibly clear.
1. The Hybrid Model is the Undisputed Winner
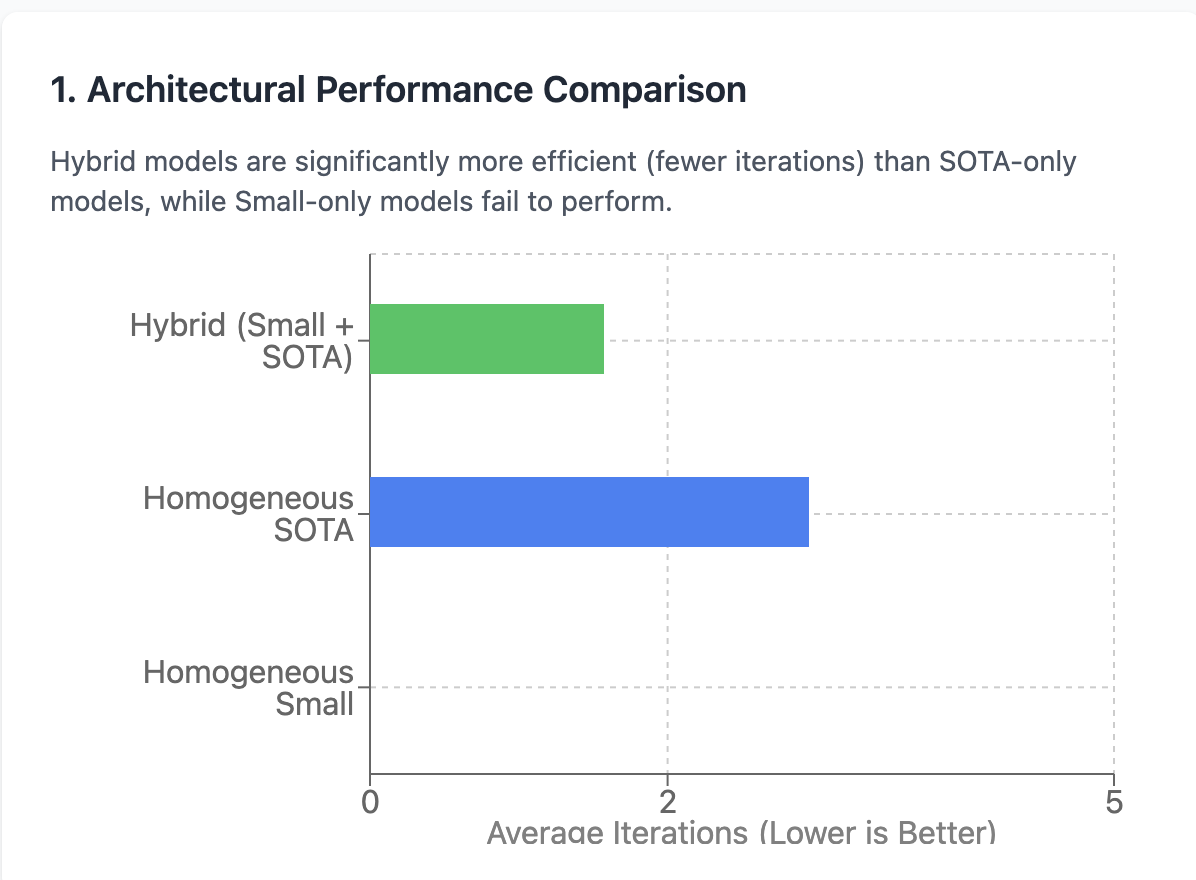
Pairing a powerful reasoning LLM with a specialized coder LLM was significantly more efficient (fewer iterations) and reliable than using a single SOTA model for everything.
2. Homogeneous Small Models are a Trap 💥
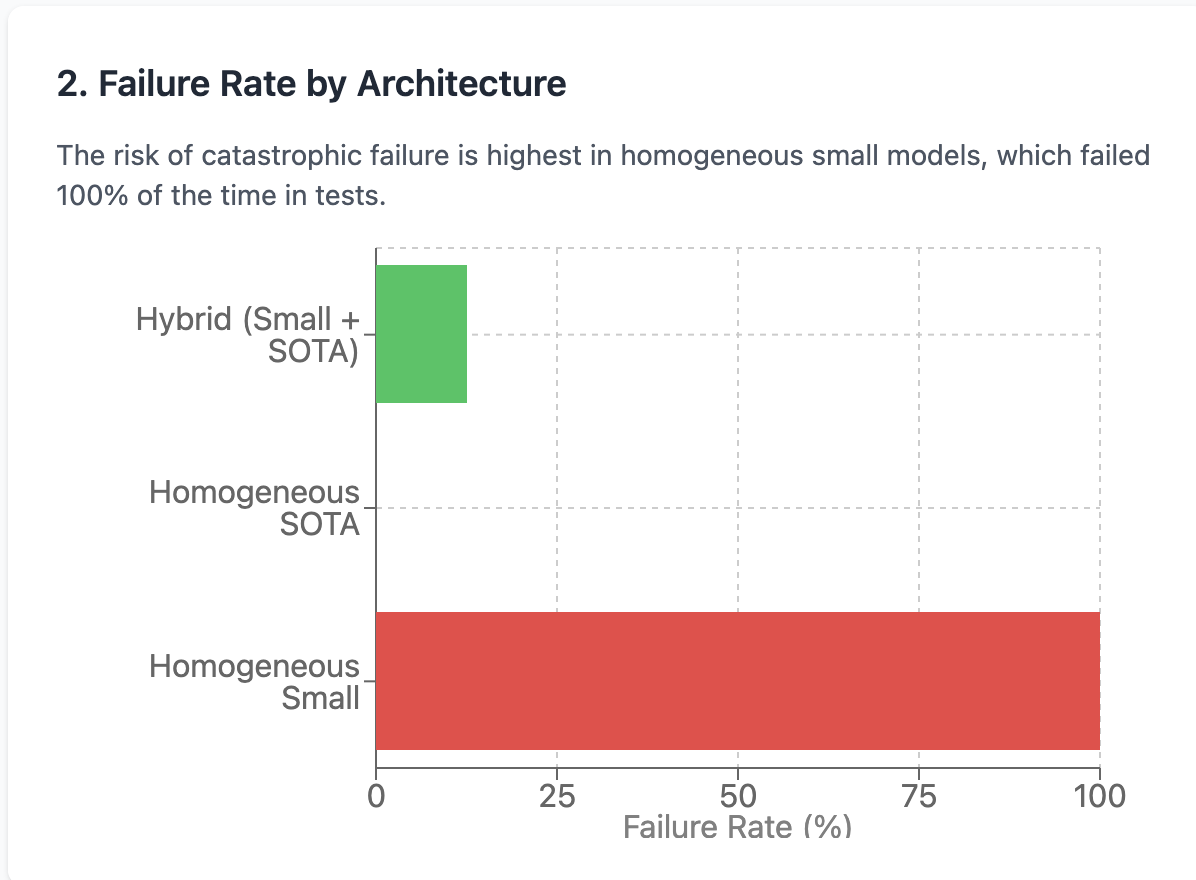
Using only a small coder model for both reasoning and syntax was a recipe for disaster. This architecture failed 100% of the time, often getting stuck in infinite "tool loops" and never completing the task.
3. Memory Had an Unexpected Impact. 🧐
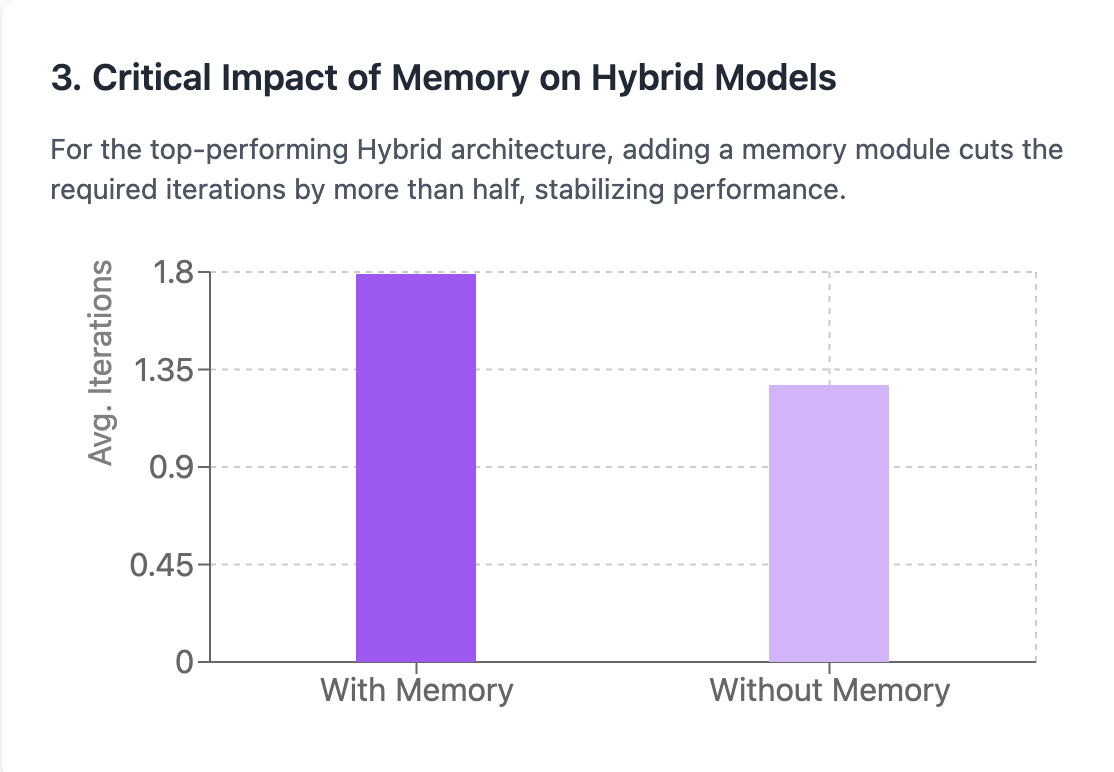
Contrary to my initial hypothesis, adding a memory module in this setup actually increased the average number of iterations. This suggests that the current memory implementation might be introducing overhead or causing the agent to over-index on past actions rather than improving efficiency. Interesting problem that needs more investigation.
Qualitative Insights: How the Models Behaved
- Model Quality: For visual appeal and creativity, the SOTA models were unmatched. Gemini and Claude produced the most impressive geometry.
- Tool Looping: Qwen had the highest tendency to get stuck in loops, making it unreliable as a standalone agent.
- Context Issues: GLM performed reasonably well but struggled to maintain structured output with a long context history.
Implementation Considerations
When building your own hybrid agent architecture, consider these factors:
- Task Decomposition: Clearly separate reasoning tasks from execution tasks
- Model Selection: Choose models that excel in their specific domain (reasoning vs. code generation)
- Error Handling: Build robust loops detection and recovery mechanisms
🖼️ The Big Picture
Building effective AI agents isn't about finding one "god-tier" model. It's about smart architecture. By composing specialized models and giving them memory, we can create agents that are far more capable than the sum of their parts.
This unlocks a new wave of gen AI tools for complex creative work. The future of AI agents lies not in bigger models, but in better orchestration of specialized models working together.