tl;dr — Screening for rare problems — in medicine, security, AI content moderation, fraud detection (welfare, insurance, housing, academic…), spam detection, and more — is limited not by accuracy, but by the universal laws of mathematics. When prevalence is low, even highly accurate tests create huge numbers of false alarms or missed cases. This interactive simulator lets you play with prevalence, accuracy, and thresholds to see how.
When your target is rare, every test becomes a gamble. But the math showing the massive possible damage of such gambles is invisible. Making the invisible math visible may help ordinary people build clearer intuitions about risk — something most of us never get taught. So I built this free app showing these sorts of risks. It’s a small counterweight to techno-hype, big money, and cognitive bias.
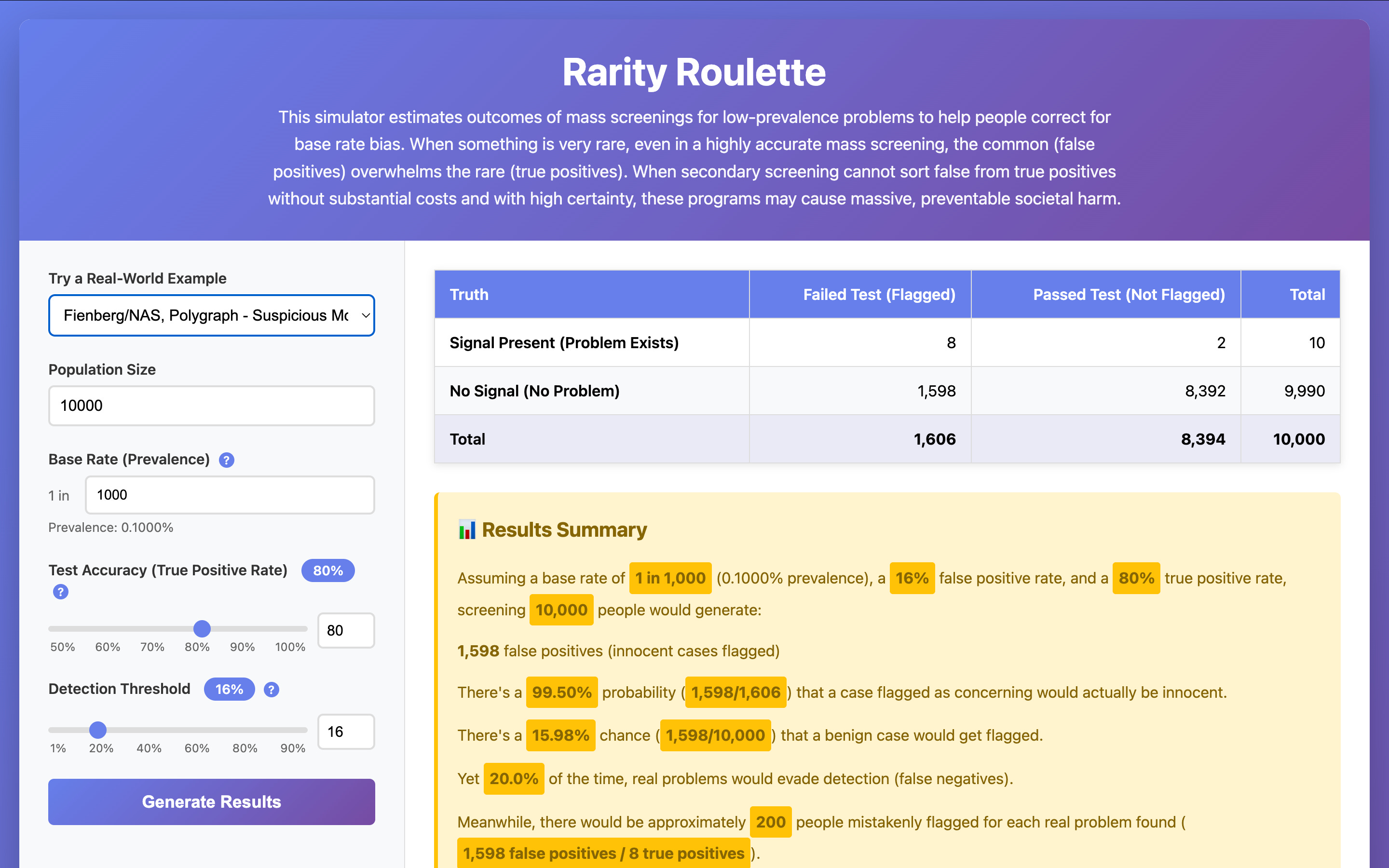
The app lets you adjust prevalence, population size, test accuracy, and detection threshold, and instantly see the range of hypothetical estimated outcomes. It’s a way to make the structural trade-offs visible instead of abstract. You can also select from a few examples to see what real-world implications of the same mathematical structure look like across diverse contexts.
Why Rare-Event Screening Is So Dangerous
Spotting the structure behind mass screenings for low-prevalence problems is a superpower: Once you see how the math behaves, you can see when “safety tools” are structurally prone to backfire.
Mass screenings for low-prevalence problems are common across diverse domains including security, health, (mis)information, and education. Examples include mass telecommunications surveillance for terrorism or pedophilia, screening entire populations for diseases like breast or prostate cancer, subjecting all pregnancies to prenatal diagnostics, polygraph testing all scientists in the National Labs, and testing all student papers for AI use or plagiarism — or all peer-reviewed publications for “trust markers.” Both AI/ML programs and analog screening methods, like “stop and frisk” policing, are implicated. Though rarely recognized as a class, these programs share a common mathematical structure that may endanger society.
The Math Problem No Technology Can Solve
As I’ve written and talked about previously, probability theory implies that programs with this structure backfire under conditions of rarity, uncertainty, and harm:
Rarity. Even with high accuracy and low false positive rates, the sheer volume involved in screening entire populations for low-prevalence problems generates either many false positives, or many false negatives (the accuracy-error trade-off).
Uncertainty. When real-world scientific testing cannot validate results, inferential uncertainty persists.
Harm. When secondary screening to reduce uncertainty carries substantial costs and risks, resultant harms may outweigh benefits for the overwhelming majority of affected people — and for society at large.
The simulator is built to let you begin to imagine how these three conditions interact: change the base rate, and the whole outcome pattern shifts.
Some assembly required: Then you still have to imagine persistent inferential and secondary screening harms affecting screenings’ costs and benefits. Suggestions welcome for how to help people visualize these components!
The bottom line: Classification mistakes (false positives and false negatives) are inevitable, and minimizing one increases the other.
Both types of errors have costs, creating what Stephen Fienberg et al writing on polygraphs called “an unacceptable choice” between too many false positives or too many false negatives.
For example, even if only 0.1% of emails are malicious and your detector is 99% accurate, most of what it flags will still be harmless. The math forces this: the rarer the target, the more your alerts turn into noise — unless you accept missing almost everything.
Many people think that technology will solve this problem as it increases accuracy.
But increasing accuracy rates don’t solve this problem. The accuracy-error trade-off is a function of the structure of the world (i.e., the probabilistic nature of most cues). Better technology cannot override the implications of universal mathematical laws. Thus, there is no escaping math — but we can do a lot of damage trying.
What the Simulator Shows You
This free, open-source app aims to help stem the tide of this massive damage by allowing users to see estimated outcome spreads of proposed screenings. Seeing these spreads helps users correct for base rate neglect, a common cognitive bias that involves ignoring how rarity impacts potential outcomes.
Using frequency formats (counts instead of percentages) improves Bayesian statistical intuitions, according to decision scientists Gigerenzer and Hoffrage: people reason far more accurately about “how many out of how many” than about percentages, and the simulator exploits this cognitive advantage to make the math of rare events visible. A plain language summary then highlights some of the most surprising implications.
The simulator’s structure mirrors and extends gold-standard analyses including the 2002 NAS polygraph report and 2020-2021 Harding Center fact boxes. I validated the core logic by plugging in published numbers from these sources and checking that the simulator reproduces their estimated hypothetical outcome spreads: when you match the base rates and accuracies they report, you get the same balance of true positives, false positives, and missed cases. That way, the examples in the app line up with serious analyses already used to guide real-world policy.
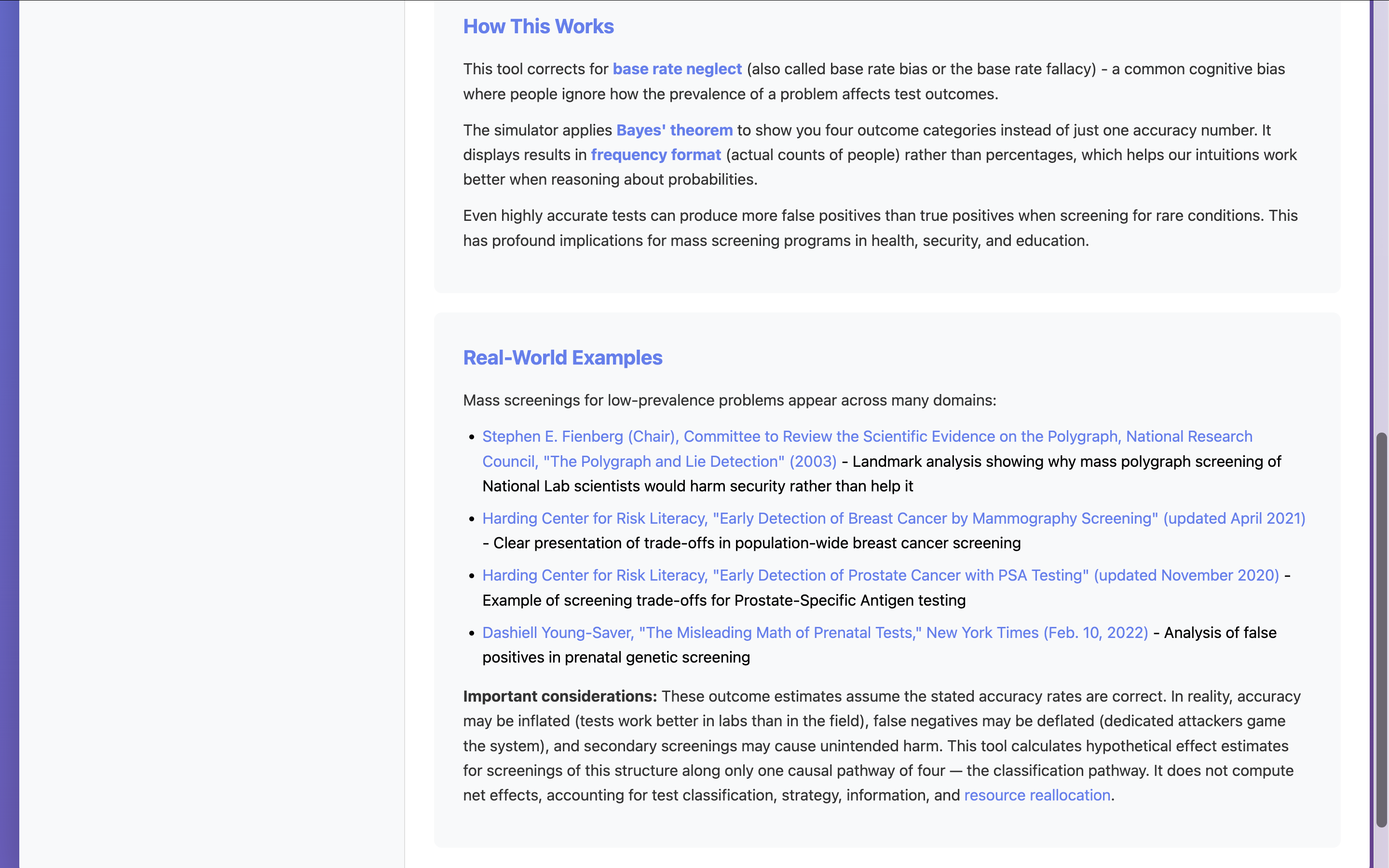
The ability to vary specifications lets users learn by simulating different conditions. It is hoped that users will also remember how uncertainty can persist and secondary screening harms may accrue, including across the categories of values or public goods with which they are often mistakenly equated.
Developed in HTML with CSS and JavaScript with help from Claude Code and hosted on GitHub Pages, this is my first app. Please try it out and let me know what you think.
No data are stored; all calculations run locally in your browser. This is an improvement over earlier versions that used R Shiny (which uses server-side computation), because keeping data client-side is safer and faster than running code on a server. This way there’s also no question of hosting costs (no backend, no database needed). There’s also less annoying latency.
If you get a technical error or problem, have a suggestion, or find a mistake, please email me.
Where This Tool Fits in a Bigger Project
Rare-event screening doesn’t exist in isolation. It’s part of a larger chain of reasoning problems. At the base are ordinary cognitive biases (Layer 1), some of which distort how we estimate uncertainty (Layer 2), and a smaller subset of which distort how we reason about rarity (Layer 3). This simulator sits on top of those (at Layer 4) by showing what mass screenings for low-prevalence problems actually do when you apply Bayes’ rule and look at outcomes in frequencies rather than percentages. On top of that is Layer 5: the real-world distortions from adversarial behavior, inflated accuracy claims, heterogeneous base rates, and equilibrium effects. This tool doesn’t model those layers, but it helps build the intuition required to think about them.
Since the tool only needs simple Bayesian arithmetic (no heavy computation), JavaScript suffices. But for application in modeling net program effects, it may need a Python and/or Julia version to connect to databases and do heavier computation (e.g., accounting for equilibrium effects using differential equations). Python also functioned as a nice scratch paper for debugging. For example:
pythonpopulation = 10000
base_rate = 1/1000
true_positive_rate = 0.20 # 20%
false_positive_rate = 0.0039 # 0.39%
# Calculate expected results...
true_positives = (population * base_rate) * true_positive_rate
# Result: 2 spies caught (not 5!)
How to Use the Simulator
The app lets you adjust four key parameters:
Population size
Base rate (prevalence)
Test accuracy [(true positives + true negatives) / total; aka, overall proportion of correct classifications)]
Detection threshold (controls how easily the test fires; lowering it catches more true cases but also makes more false alarms)
Changing these parameters shows how outcome patterns shift: how many true positives, false positives, missed cases, and secondary screenings a test might generate. By playing with different combinations and watching the outcome spreads change, users can build more accurate statistical intuitions about how programs of this structure behave — and why even very accurate tests may struggle to give society net gains when the problem’s prevalence is low.
Why You Actually Do Need This
All of this might be abstract if these programs weren’t rapidly scaling across society. But digitalization and AI/ML are enabling an enormous expansion of mass screenings for low-prevalence problems.
These programs are increasingly embedded everywhere: medicine, finance, content moderation, cybercrime detection, child-safety scanning, border control, welfare and insurance fraud scoring, academic integrity systems, and workplace risk assessments. Modern life runs on automated filters and classifiers. Rare-event math quietly determines who gets flagged, whose account freezes, who undergoes a biopsy, who is investigated, and whose digital traces trigger alerts.
These systems look may very different on the surface, but under the hood they share an identical mathematical structure — a dangerous one. We’re looking for a needle in a haystack using tools that were never designed for haystacks. This generates a second haystack and pricked fingers.
These are so-called signal detection programs — programs designed to help us sort signal from noise. The problem is: Many of these programs aren’t really signal detectors. They’re noise-makers.
The simulator’s job is to show when a proposed system is structurally likely to generate more noise than signal.
Even with excellent sensitivity and specificity, the underlying math forces a brutal trade-off:
if you tune for fewer false positives, false negatives explode
if you tune for fewer false negatives, false positives explode
There is no clever engineering that escapes this. It’s not a calibration issue, or a model issue, or a data issue — it’s a base-rate issue. No amount of accuracy eliminates it.
What makes this especially dangerous is that most of these screenings are iterated, not one-off.
Once you iterate:
false positives trigger more screenings
follow-up tests redirect scarce investigative or medical resources
negative results affect behavior and trust
enforcement responses feed back into the system
you get equilibrium effects and compound perverse incentives
Harms don’t just add; they propagate, amplifying errors across the entire system.
And yet: This doesn’t mean that every mass screening for a low-prevalence problem is doomed to fail.
Rather, it means that we must attend to the implications of the relevant conditions (rarity, uncertainty, secondary screening harms). And acknowledge that we often haven’t estimated such a program’s net effects. Doing that is hard in the real world where feedbacks are rampant, because equilibrium-effects modeling (accounting for feedbacks) is still at the cutting edge of AI/ML research and indeed of science.
Yet these systems are being deployed at scale anyway.
The point of this simulator isn’t to “solve” rare-event screening. It’s to let people see estimated outcome spreads in a way that builds real intuition about these screenings’ possible effects. If we can’t see these implications clearly, we risk building systems that quietly harm far more people than they help — and we don’t even notice.
Many readers assume they rarely encounter these systems. But that intuition breaks quickly once you see how widespread rare-event screening has become.
This simulator is for anyone who builds, evaluates, or is affected by large-scale screening systems: engineers working on classifiers, policymakers designing safety thresholds, doctors and public-health workers interpreting tests, researchers studying false positives, and ordinary people navigating systems governed by automated judgment. If you interact with risk assessments — or if risk assessments interact with you — this means you.
Limitations (Read This Before Interpreting Results)
Users should be wary of possible distorting factors not accounted for by this incarnation of this tool, such as:
inflated reported accuracy, for example, from bias and perverse incentives (e.g., when experts profit from selling the test as a product)
deflated false negatives, e.g., when dedicated attackers game the system
uncertain or heterogeneous base rates
screening-induced harms
Outcome estimates should never be mistaken for real-world net benefits or resolutions of moral trade-offs.
This tool calculates hypothetical effect estimates for screenings of this structure along only one causal pathway of four — the classification pathway. It does not compute net effects, accounting for test classification, strategy, information, and resource reallocation.
Final Thoughts
Rare-event screening isn’t a niche technical problem. It’s a structure increasingly woven into decisions that shape ordinary life. We’re building systems faster than we’re building the intuitions needed to understand them, and the costs of misunderstanding the math are often borne by the people least able to see what went wrong — or fix it.
This simulator doesn’t solve those problems. And it can’t replace careful empirical research or difficult, value-focused decisions. But it can make one crucial piece of the puzzle visible: how quickly rare targets may turn even very accurate screening tools into noise generators, and how this structure constrains what screening tools can deliver.
If you try the tool and find it useful — or surprising, or unsettling — share it. Send it to someone who designs screening systems, or someone subjected to them. The more people who can see the underlying structure, the harder it becomes to normalize mass screenings that may hurt far more people than they help.
Try the simulator here: