1Netflix 2INSAIT, Sofia University "St. Kliment Ohridski"
Abstract
Existing video object removal methods excel at inpainting content "behind" the object and correcting appearance-level artifacts such as shadows and reflections. However, when the removed object has more significant interactions — such as collisions with other objects — current models fail to correct them and produce implausible results.
We present VOID, a video object removal framework designed to perform physically-plausible inpainting in these complex scenarios. To train the model, we generate a new paired dataset of counterfactual object removals using Kubric and HUMOTO, where removing an object requires altering downstream physical interactions. During inference, a vision-language model identifies regions of the scene affected by the removed object. These regions are then used to guide a video diffusion model that generates physically consistent counterfactual outcomes.
Experiments on both synthetic and real data show that our approach better preserves consistent scene dynamics after object removal compared to prior video object removal methods.
Method
A user clicks on an object to remove it. A VLM-based reasoning pipeline then identifies which other regions of the scene will be causally affected — objects that will fall, collide, or change trajectory — and encodes this into a quadmask that guides the diffusion model. VOID's first pass generates a physically plausible counterfactual video with the object and its interactions removed. If the model detects object morphing — a known failure mode of smaller video diffusion models — an optional second pass re-runs inference using flow-warped noise derived from the first pass, stabilizing object shape along the newly synthesized trajectories.
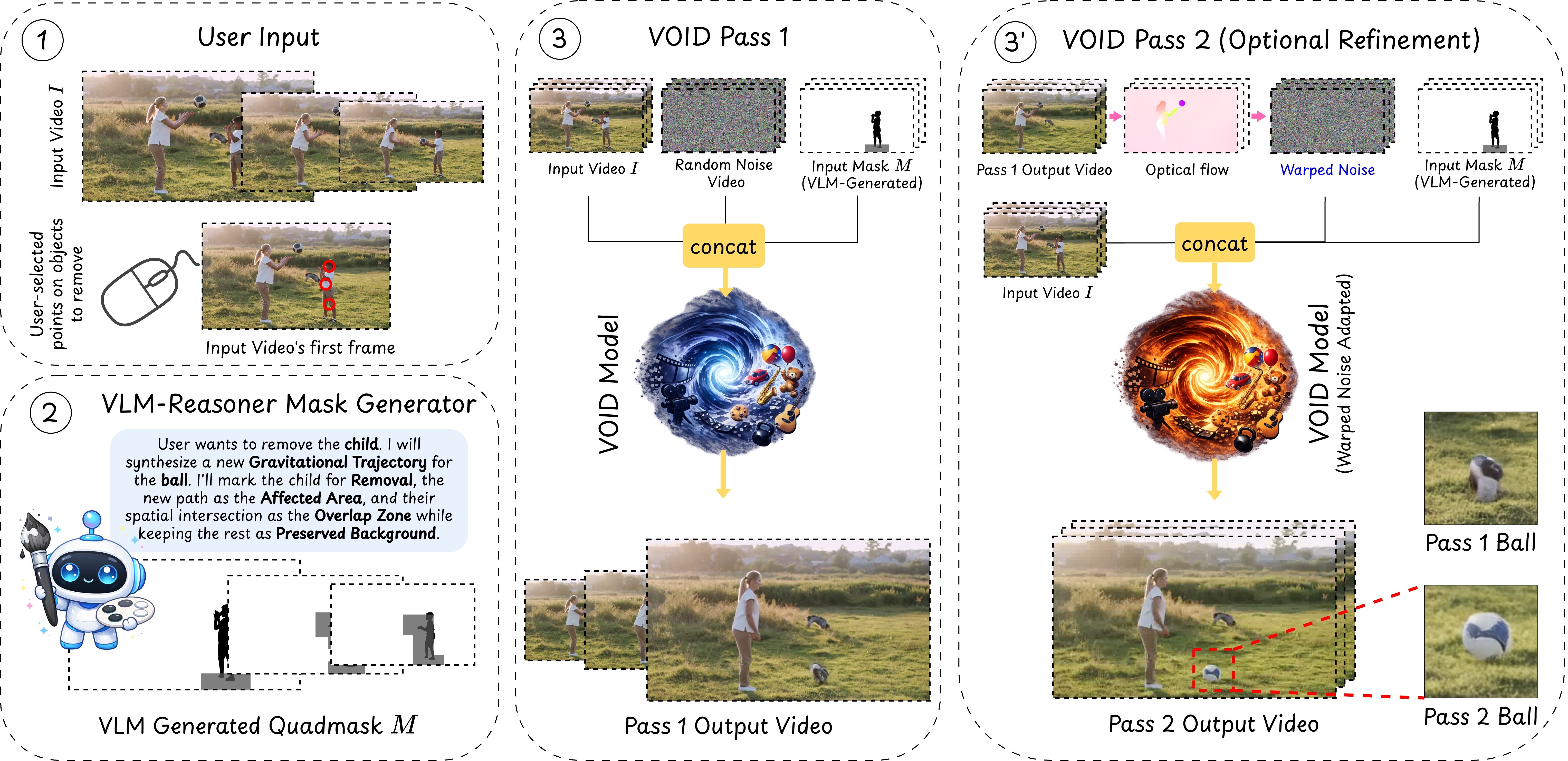
Pass 2 Refinement
When the first pass produces object morphing artifacts, a second pass re-runs inference using flow-warped noise to stabilize shape along synthesized trajectories. Drag the slider to compare Pass 1 (left) vs Pass 2 (right).
Training Data
We generate paired counterfactual removal examples from Kubric (synthetic) and HUMOTO (human motion). Each triplet shows the input video, the quadmask, and the ground-truth counterfactual output.
Counterfactual Video
(Ground Truth)
Counterfactual Video
(Ground Truth)
Podcast Overview
An AI-generated audio overview of the paper.
📄 Citation
If you find our work useful, please consider citing:
@misc{motamed2026void,
title={VOID: Video Object and Interaction Deletion},
author={Saman Motamed and William Harvey and Benjamin Klein and Luc Van Gool and Zhuoning Yuan and Ta-Ying Cheng},
year={2026},
eprint={2604.02296},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.02296}
}