Overview
🏆
Vision Banana is a SOTA unified model for both image understanding and generation.
🧠
Generative vision pretraining is an effective paradigm for visual understanding.
🔗
Image generation serves as a universal interface for diverse vision tasks.
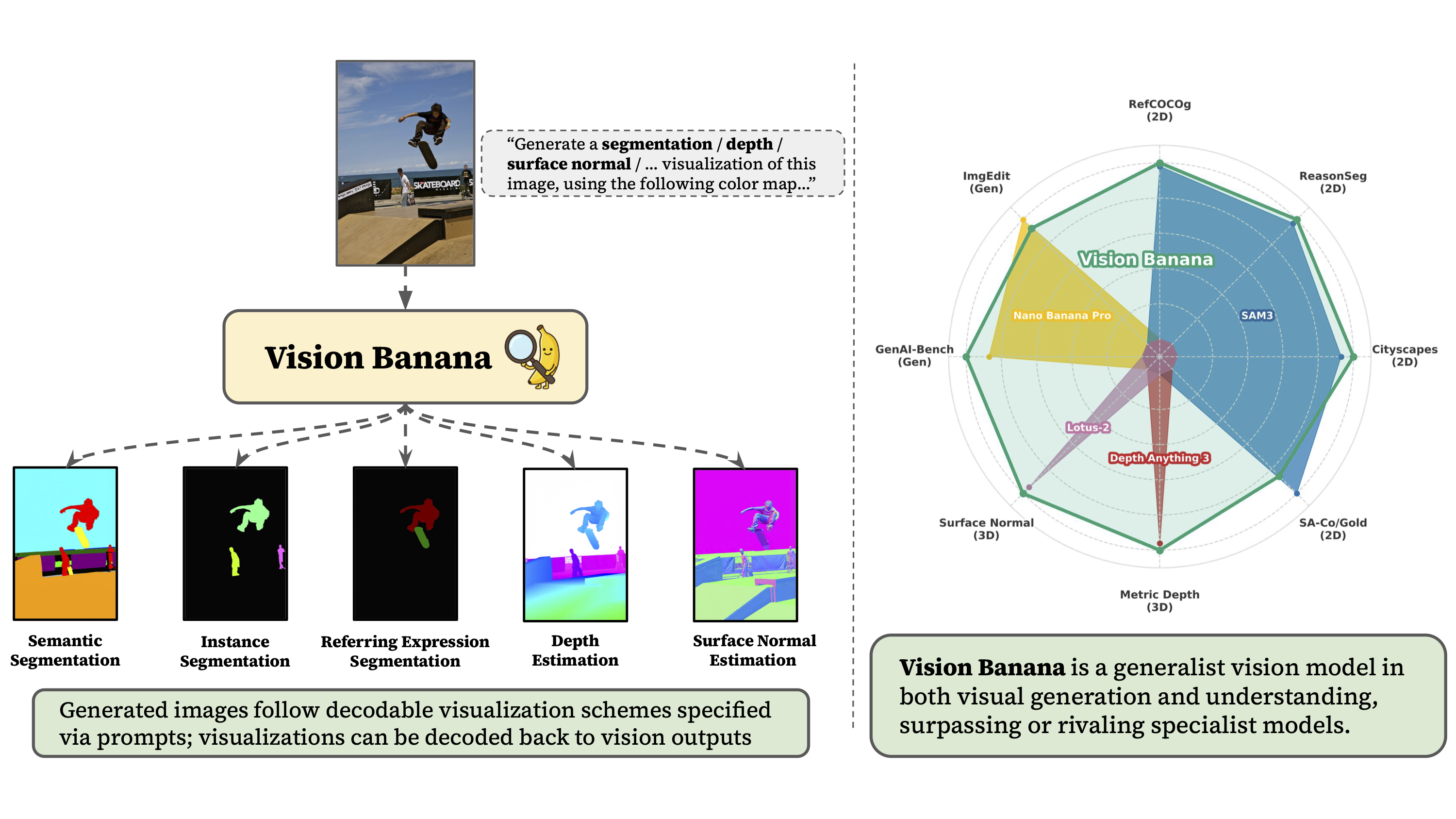
Capabilities
Hover over any image to reveal Vision Banana's generation results. On mobile, tap to toggle.
Semantic Segmentation


Input Segmentation
Prompt: This image is a per-pixel class labeling of the input. The macaron cakes are represented by (255, 255, 0). The round plates are represented by (255, 192, 128). The slice cakes are depicted in (64, 192, 64). The flowers are shown in (128, 0, 64). The tongs are (255, 0, 192).


Input Segmentation
Prompt: Generate a visualization image of semantic segmentation, using this color mapping: {"cat ears": <255, 165, 0>, "exit sign": <0, 0, 255>, "background": <125, 0, 125>}


Input Segmentation
Prompt: Conduct per-class semantic segmentation for the given image. The sitting person are represented by (255, 255, 0). The standing and walking people are represented by (255, 192, 128). The ocean is depicted in (64, 192, 64). The street lights are in (128, 0, 64). The sky is in (255, 0, 192). The fence is in (0, 0, 255). The backpack is in (255, 0, 0).
Hover to reveal segmentation masks
Instance Segmentation

Input Segmentation
Prompt: Generate an instance segmentation visualization of this image. Each piece of garlic is colored differently.


Input Segmentation
Prompt: Generate an instance segmentation visualization of the input image. Segment all the price on the price tags, color them differently.


Input Segmentation
Prompt: Generate an instance segmentation visualization of this image. Each price tag is colored differently.


Input Segmentation
Prompt: This image shows segmentation masks for the basketballs from the input image. The background is set to #10aa05. Each basketball instance is represented by a solid circular mask, and a different color is used for each mask.
Hover to reveal instance masks
Referring Expression Segmentation


Input Segmentation
Prompt: This image shows segmentation masks from the given image. The background is black color. The chef's names in both Chinese and English are rendered as cyan color.


Input Segmentation
Prompt: A segmentation map image. The stretching cat is rendered in green, the cat that is cleaning itself is in cyan.


Input Segmentation
Prompt: This image shows segmentation masks from the given image. The background is black color. The game control device is represented by a solid yellow.


Input Segmentation
Prompt: A segmentation map image. The area that corresponds to the man in pink t shirt is rendered solid white; the other man is rendered in green.


Input Segmentation
Prompt: A segmentation map of the input image. The pig not in the glass is rendered cyan, and the pig in the glass reflection is rendered yellow.
Hover to reveal referred object masks
Monocular Metric Depth Estimation


Input Depth
Prompt: Predict the metric depth of this scene as an image. Visualized in the rainbow colormap.


Input Depth
Prompt: Predict the metric depth of this scene as an image. Visualized in the rainbow (black-red-yellow-green-cyan-blue-violet-white) color palette.


Input Depth
Prompt: Predict the metric depth of this scene as an image. Visualized in the rainbow (black-red-yellow-green-cyan-blue-violet-white) color palette.


Input Depth
Prompt: Generate a metric depth map of the provided image.


Input Depth
Prompt: Generate a metric depth map of the input image.


Input Depth
Prompt: Generate a metric depth map of the input image.


Input Depth
Prompt: Generate a metric depth map of the input image.
Hover to reveal depth maps
Surface Normal Estimation


Input Surface Normal
Prompt: Predict the surface normal of this scene.


Input Surface Normal
Prompt: Generate a surface normal map of the input image.


Input Surface Normal
Prompt: Generate a surface normal map of the input image.


Input Surface Normal
Prompt: Generate a surface normal map of the input image.


Input Surface Normal
Prompt: Generate a surface normal map of the input image.
Hover to reveal surface normal maps
Results
Vision Banana achieves state-of-the-art under the zero-shot transfer setting across 2D and 3D vision tasks.
2D Understanding
SegMan-L
(Non
Zero-Shot)
APE-D
OpenSeeD
X-Decoder
SAM 3
Vision Banana ![]()
SAM 3
(Non
Zero-Shot)
APE-D
OWLv2
Gemini 2.5
Vision Banana ![]() DINO-X
DINO-X
* Evaluated on 500 randomly sampled queries.
HyperSeg
+ Phi2
(Non
Zero-Shot)
X-SAM
+ Phi3
(Non
Zero-Shot)
HybridGL
Kang
+ LLaVA
SAM 3
+ Gemini 2.5 Pro
Vision Banana ![]()
X-SAM
+ Phi3 3.8B
(Non
Zero-Shot)
LISA-13B-LLAVA1.5(Non
Zero-Shot)
SegZero
RSVP
+ GPT-4o
SAM 3
+ Gemini 2.5 Pro
Vision Banana ![]()
+ Gemini 2.5 Pro
Methods paired with MLLMs for reasoning.
3D Understanding
Depth Pro
MoGe-2
UniK3D
Vision Banana ![]()
Vision Banana does not use camera intrinsics in training or inference.
Marigold
StableNormal
DSINE
Lotus-2
Vision Banana ![]()
Contributors
Project Leads
Valentin Gabeur* · Shangbang Long* · Songyou Peng*
* Equal contribution
Core Contributors
Paul Voigtlaender · Shuyang Sun · Yanan Bao · Karen Truong · Zhicheng Wang · Wenlei Zhou · Jonathan T. Barron · Kyle Genova · Nithish Kannen · Sherry Ben · Yandong Li · Mandy Guo · Suhas Yogin
Project Advisors
Yiming Gu · Huizhong Chen
Leadership Sponsors
Oliver Wang · Saining Xie · Howard Zhou · Kaiming He · Thomas Funkhouser · Jean-Baptiste Alayrac · Radu Soricut
Acknowledgements
We thank Xi Chen, Fei Xia, Kaushik Shivakumar, Abhishek Sinha, Phillip Lippe, Yilin Gao, Javier Rey, Sanghyun Woo, Renshen Wang, Wentao Yuan, Keran Rong, Rundi Wu, Manoj Kumar, Manli Shu, Francesco Piccinno, Ishita Dasgupta, Benigno Uria, Miki Rubinstein, Aäron van den Oord, and Jon Shlens for their helpful discussions, advice, and technical guidance.
BibTeX
@article{visionbanana2026,
title={Image Generators are Generalist Vision Learners},
author={Gabeur, Valentin and Long, Shangbang and Peng, Songyou and Voigtlaender, Paul and Sun, Shuyang and Bao, Yanan and Truong, Karen and Wang, Zhicheng and Zhou, Wenlei and Barron, Jonathan T and Genova, Kyle and Kannen, Nithish and Ben, Sherry and Li, Yandong and Guo, Mandy and Yogin, Suhas and Gu, Yiming and Chen, Huizhong and Wang, Oliver and Xie, Saining and Zhou, Howard and He, Kaiming and Funkhouser, Thomas and Alayrac, Jean-Baptiste and Soricut, Radu},
journal={arXiv preprint arXiv:2604.20329},
year={2026}
}