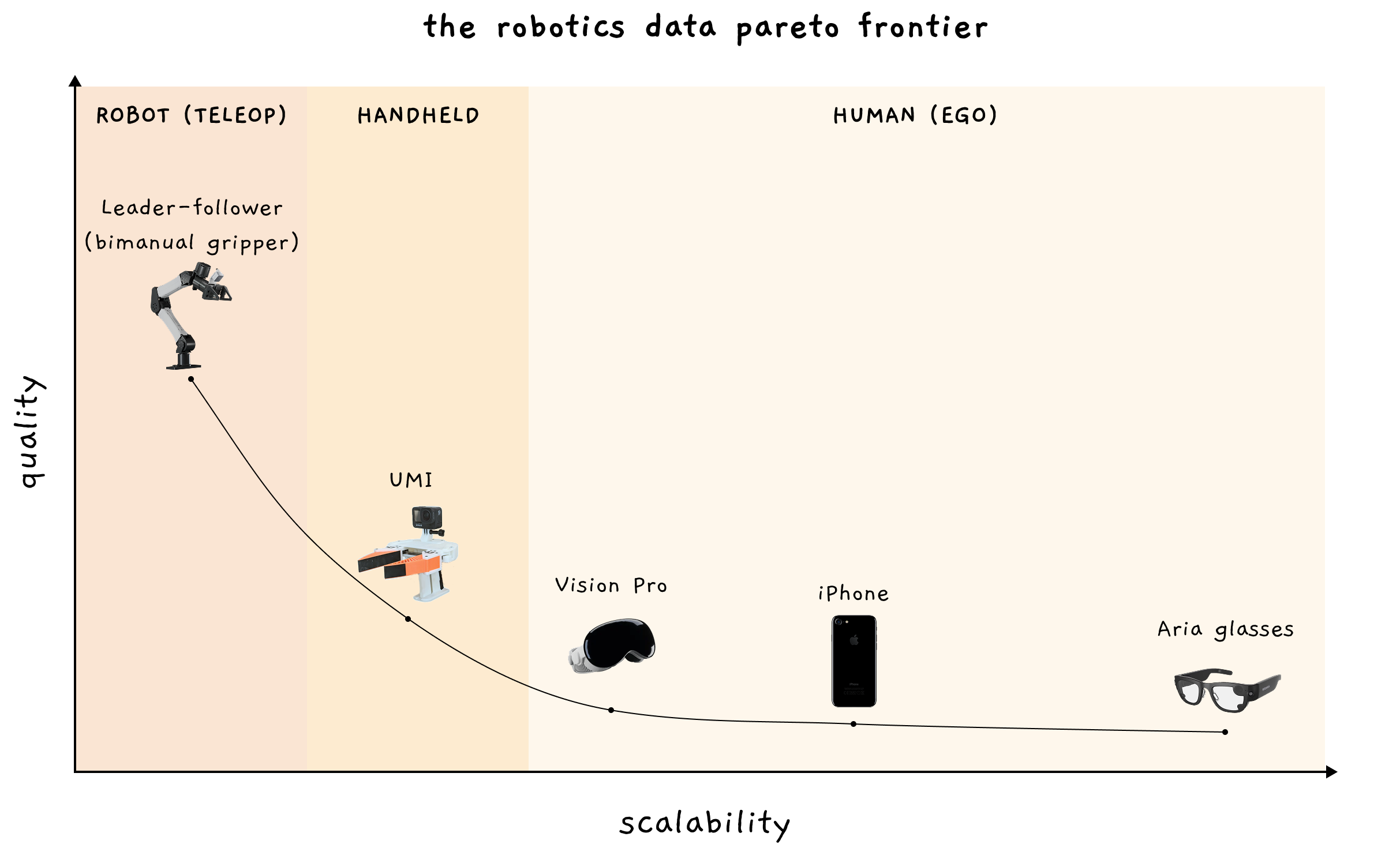
The defining narrative of robotics in 2025 was not a new model architecture, but an enthusiasm for data. Despite a consensus around teleoperation as the gold standard, interest blossomed in the data and training recipes that transcend it. This appetite defined a new market category and spurred the creation of innumerable data collection startups aiming to address the heterogeneous robotics data problem. At the intersection of data companies and robotics research lies a recurring theme: human data. In just the last month, the industry’s largest players—whose initial hypotheses were staked on either hardware, teleoperation, or simulation—have all announced breakthroughs in learning from human data1 2 3. Structurally, this resurgence is not merely a quest for scale, but an inevitability. Real-world data collection is a product, and the user experience of that product dictates a Pareto Frontier between embodiment specificity and long-tail task diversity.
Data collection as a product
If we define a product as a tool designed to facilitate a specific human activity at scale, then data collection should be evaluated by how it manages the exchange between human behavior and digital output. Like any product, its success is governed by a trade-off between utility (the value of the data) and friction (the burden of incentive alignment and distribution). The ideal user experience (UX) of data collection is invisible: the user maintains their natural workflow and the data, captured as a seamless byproduct of their labor, is effective for robot learning. The product of data collection is the bridge that tries to reconcile the robot’s need for data with the human’s need to perform their job.
Perfect data, as Sergey Levine puts it, is a robot observing itself completing a task4. Teleoperation is the gold standard, providing kinematically complete data that is exactly 1-1 with the downstream embodiment. However, as a product, teleoperation has terrible UX. Popular systems such as leader-followers for bimanual manipulators or motion capture for humanoids prevent humans from completing tasks naturally in speed and quality. Furthermore, teleoperation faces high costs of hardware (you need a functioning robot), human capital (you need a trained operator), and incentive structures (you cannot ask a factory worker to remote-control a robot without disrupting their actual job). As such, teleoperation remains a lab operation in most implementations.
The barriers to scaling teleoperation have driven a large interest in handheld devices, usually in the form of portable grippers/gloves. While these devices are more portable, they decouple the hand from the robot, removing much of the kinematic information that teleoperation captures. In practice, the promise of scale falls short. For example, you cannot ask a restaurant chef to roll your specialty handmade pasta with blunt two-fingered appendages during peak operation. Consequently, handheld datasets capture breadth across tasks, but not the vast “long-tail” collection of nuanced, rare, or difficult-to-access tasks that define real-world work. Despite these limitations, handheld devices remain popular because they occupy a narrow but useful region of the Pareto curve: just enough embodiment information at just enough scale beyond teleoperation.

It turns out that the incentive structures that drive data collection are governed by ergonomic (can I do my job?) and social (do I want to wear this?) parameters. Therefore, data collection methods involving proxy robot embodiments cannot capture the long-tail of physical labor because they fail the ergonomic requirement. Only a product that sufficiently achieves both criteria can collect “ego data” directly from humans while they work. Even within the category of ego data, hardware scales differently based on social factors. For example, people are more willing to wear glasses than iPhones on their heads. Though the appetite for ego data is growing rapidly, stripping away the actuators and sensors to improve UX means that we cannot capture proprioceptive ground truth.
In short, the landscape of robotics data collection can be summarized in three categories: teleoperation (high quality, low scale), handheld devices (moderate quality, moderate scale), and ego data (low quality, high scale). These represent the Data Pareto Frontier, which specifies academic taxonomies like Yuke Zhu’s Data Pyramid5 by observing real-world constraints. While we would like to maximize both quality and scale simultaneously, the Data Pareto Frontier represents the boundary of what reality allows us to capture. Crucially, it suggests that we should integrate along the curve to produce the optimal data collection system, and also that we should improve hardware design to push these limits.
Closing remarks
Ultimately, the resurgence of human data in robotics is a structural inevitability. The Data Pareto Frontier dictates that we cannot simply collect all of anything, but rather that we are bound by a tradeoff between data quality and scalability.
The solution, therefore, is not about a perfect data source, but about how to build a heterogeneous deep learning system. Robotics research labs are pivoting to human data because the Pareto Frontier is forcing them to. Scaling perfect robot data is hard, so the path forward is to slide down the curve towards ego data and hope that model scale (compression) will enable transfer. Fortunately, as Ilya Sutskever’s framework of compression6 suggests, the long-tail messiness is not noise but actually useful information about the world that robots will profit from, and so we should be optimistic about future algorithms.
Our focus is shifting from the pursuit of a perfect data source toward building systems capable of learning across the entire curve. Success lies in designing for human adoption and improving hardware to push the Pareto Frontier.
I thank my good friends and peers Ademi Adeniji, Jupi Parmar, Ben Bolte, and Kartik Bhat for early feedback on this essay.
-
1X. 1X World Model | From Video to Action: A New Way Robots Learn. ↩
-
Physical Intelligence. Emergence of Human to Robot Transfer in VLAs. ↩
-
Skild AI. Learning by watching human videos. ↩
-
Sergey Levine. Sporks of AGI. ↩
-
Yuke Zhu. Building Generalist Robot Autonomy with the Data Pyramid. ↩
-
Ilya Sutskever. An Observation on Generalization. ↩