February 5, 2026

I recently built DamN64, an isometric 2D, two-player game for the Nintendo 64, as part of the N64brew Game Jam (submission deadline: February 1st).
This wasn’t my first jam entry, but it was the first where I deliberately used LLMs across the entire development loop: engine code, gameplay logic, tooling, and asset assembly. The constraints of the N64 made this a good stress test for where LLMs actually provide leverage when abstraction is thin and performance matters.
The self-imposed challenges
Compared to my previous jam entries, I raised the bar in a few specific ways:
- Isometric 2D rendering on N64 hardware
- Always-on two-player gameplay
- A dynamic split-screen camera that smoothly transitions from a single shared view to two independent cameras as players move apart, then stitches back together without snapping
The split-screen requirement alone touches camera math, viewport layout, HUD duplication, and fill-rate constraints. On N64, none of that is free.


Total dev time was roughly one to two weeks of evenings, which meant anything not directly improving gameplay feel needed to be optimized for iteration speed.
LLMs as part of the implementation loop
I used opencode with OpenAI Codex 5.2 and Anthropic Claude Opus 4.5, but very intentionally not as a “generate a game” button.
The pattern that worked was:
- Provide a real, working codebase from previous jam entries
- Ask the model to operate strictly inside those patterns
- Treat outputs as drafts to be profiled, trimmed, and reshaped
A concrete example is the dam breaking and repair system.
This mechanic required:
- A small state machine per dam segment
- Carefully tuned timing for break and repair phases
- A wave or ripple effect propagating across adjacent segments
- Predictable per-frame cost
The LLMs were useful for:
- Enumerating state transitions clearly
- Proposing initial timing values that were directionally sane
- Structuring update logic so it was readable and debuggable
I then went through and aggressively simplified the generated code. The value wasn’t correctness out of the box, it was collapsing the blank-page phase into something testable in minutes.
Context beats clever prompting
The N64 homebrew ecosystem is built around libdragon, and that library is either absent or partially represented in model training data.
Cold prompts produced plausible but subtly wrong code.
What worked was feeding the agent large chunks of previous jam code:
- Rendering paths
- Input handling
- Fixed-point math conventions
- Frame timing assumptions
- Data layout choices
Once that context was present, the models stopped hallucinating APIs and started reasoning locally inside the constraints of my engine.
This only worked because I treated the LLM like a junior engineer dropped into an existing codebase, not like an expert with perfect global knowledge.
Asset creation and tooling: vibecoding with intent
AI didn’t just help with runtime code, it also shaped the creation pipeline.
I decided early on to use Kenney.nl isometric assets as a base. They are clean, consistent, and perfect for jam-scale production.
The missing piece was flexibility: I needed to stack tiles and generate full building sprites quickly, without doing everything manually in an image editor.
So I vibecoded ( on Replit of course) a small tool that lets me:
- Stack isometric tiles
- Compose full buildings
- Export ready-to-use PNGs
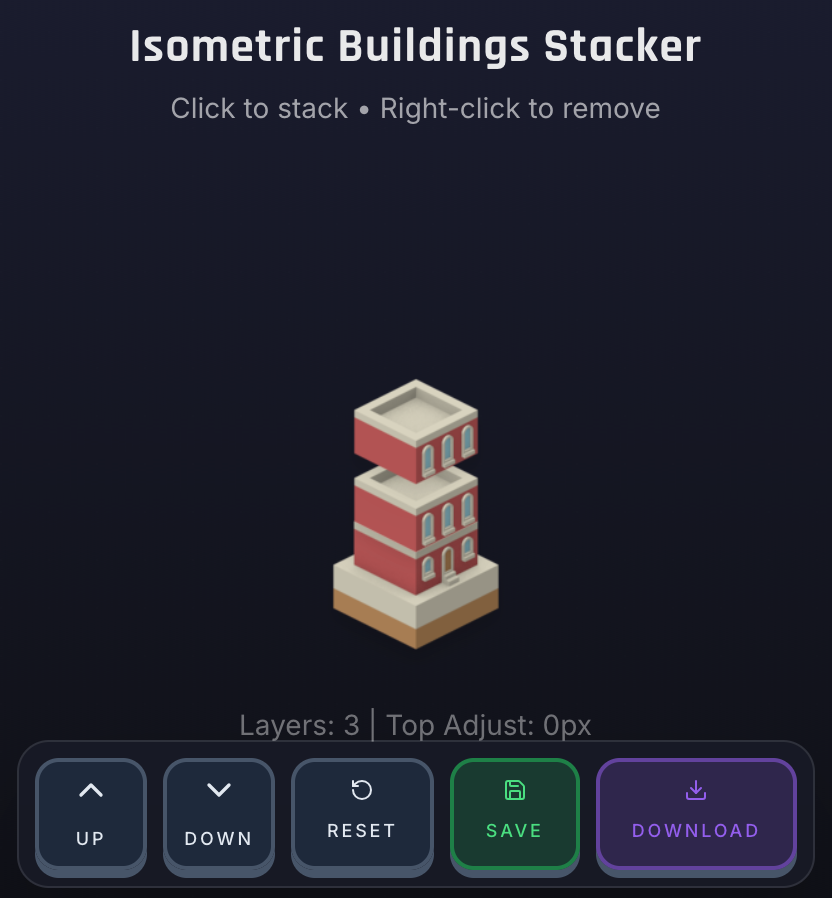
The LLMs helped bootstrap the tool quickly, especially around layout logic and UI wiring, while I focused on making sure the output matched my engine’s rendering expectations.
This became a recurring pattern in the project: use AI to get tooling “good enough” fast, then spend human time on correctness and integration.
The cost of “safe” code on old hardware
One consistent failure mode was over-defensive code generation.
LLMs strongly prefer:
- Null checks everywhere
- Extra clamps and bounds checks
- Readability over instruction count
On modern hardware, that’s fine. On the N64, that’s unacceptable in hot paths. There’s no speculative execution or modern branch prediction to hide inefficiencies.
My workflow became:
- Let the model draft logic
- Identify hot paths
- Inline, prune, and delete safety nets manually
This isn’t a flaw so much as a reminder: LLMs optimize for human expectations, not for bare-metal constraints.
An agent skill for emulator-level smoke testing
One of the more experimental pieces was writing a custom agent skill for lightweight runtime validation.
On macOS, using:
The agent could:
- Build the ROM
- Launch the emulator
- Send a fixed input sequence
- Capture a frame
- Analyze the image to verify expected visual states
This didn’t play the game end-to-end, but it was enough to catch broken builds, camera regressions, or missing assets without manual supervision.
For a retro project, this felt like adding a very opinionated form of visual smoke testing.
What actually changed
The biggest shift wasn’t raw speed, it was where cognitive effort went.
With boilerplate, scaffolding, and tooling accelerated, I spent more time on:
- Camera behavior
- Split-screen transitions
- Animation timing
- Overall game feel
That tradeoff was absolutely worth it under a jam deadline.
Takeaway
LLMs are not drop-in solutions for constrained systems. They don’t understand your hardware unless you force that understanding through context and examples.
But when treated as context-aware implementation assistants inside a real codebase, they can meaningfully compress iteration loops, even on hardware where every cycle matters.
DamN64 shipped because of that compression.