Anthropic never released any technical details on the size of Opus, but we can still make informed estimates based on known data.
Some people on the internet make ridiculous claims like “Claude Opus is 10T+ params in size”, which makes no sense considering the hardware that the models run on.
In practice, token generation throughput on a fixed hardware backend (Google Vertex, Amazon Bedrock) is primarily bottlenecked by the number of active parameters loaded and computed per forward pass. For MoE models, this is the active parameter count, not total. Comparing token generation speed ratios (by saying a model is roughly 2x faster or slower than another model) can tell you a lot about the active param count. Then you can multiply by sparsity to get the total model size.
This holds reasonably well when controlling for platform, since the same accelerators, interconnect topology, and serving stack are shared.
I won't say it'll tell you everything; I have no clue what optimizations Opus may have, which can range from native FP4 experts to spec decoding with MTP to whatever. But considering Chinese models like Deepseek and GLM have MTP layers, and Kimi is native INT4, I'm confident that there is not a greater than 10x size/performance difference between Opus and the Chinese models.
When comparing from the same provider, that means normalized infrastructure costs, normalized electricity costs, normalized hardware performance, and normalized inference software stack even (most likely). It's about a close of a 1 to 1 comparison as you can get.
Both Amazon and Google serve Opus at roughly ~1/3 the speed of the Chinese models. Note that they are not incentivized to slow down the serving of Opus or the Chinese models! So that gives you a good idea of the ratio of active params for Opus and for the Chinese models.
I got the data from OpenRouter, which lists the token/sec throughput for each model and provider. This gives us a useful calibration signal:
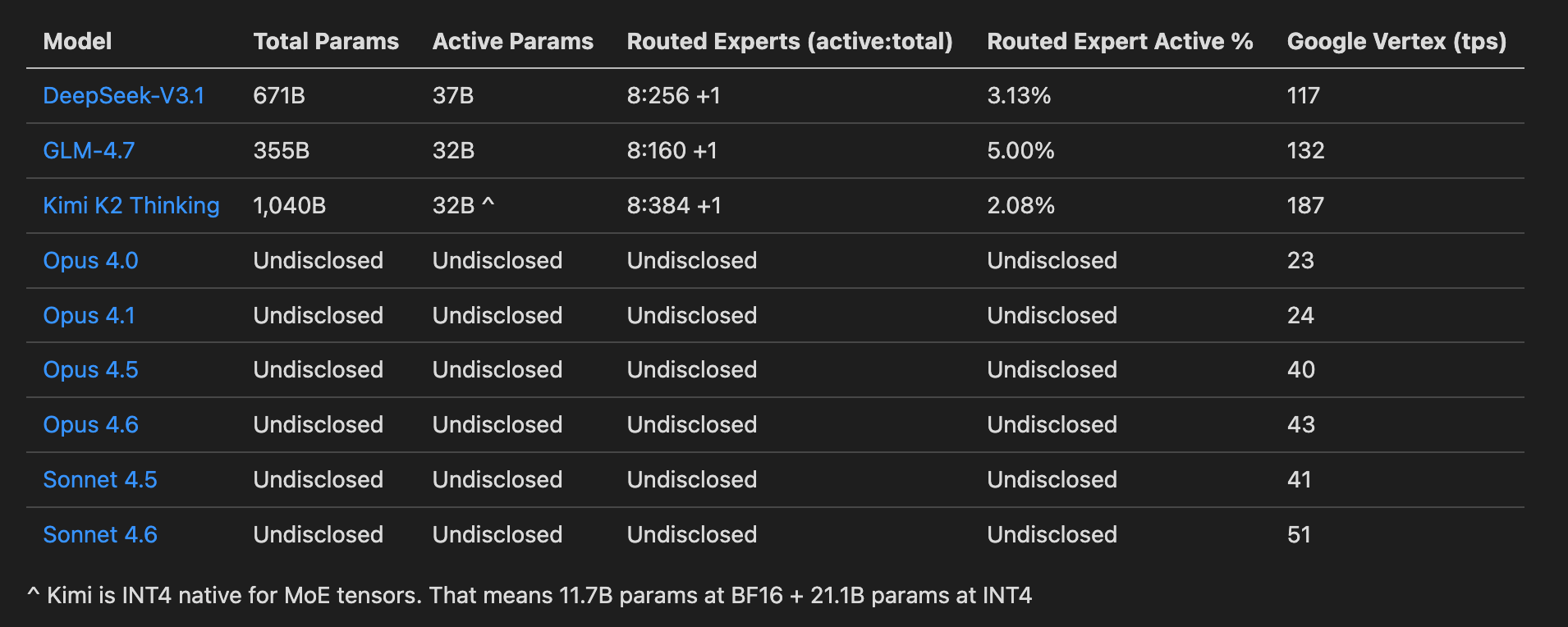
Based on this table, we can calculate the effective memory bandwidth for Google Vertex, and then the size of the models.
Let’s start with Deepseek V3.1 for memory bandwidth:
Deepseek active params = 37,554,471,5121
Google Vertex TPS = 117
precision = FP8 = 1 byte/param
So therefore effective2 bandwidth = 37,554,471,512×117 = 4,393,873,166,904 bytes/s which is approximately 4.39 TB/s.
Next is GLM-4.7 which gives:
GLM active params = 33,632,266,1443
Google Vertex TPS = 132
precision = FP8 = 1 byte/param4
So therefore effective bandwidth = 33,632,266,144×132 = 4,439,459,131,008 bytes/s which is approximately 4.44 TB/s.
Then we have Kimi K2 Thinking, which is a more complicated case:
Kimi always active params = 11,722,775,856
Kimi MoE active = 21,140,582,400
Total = 32,863,358,256 (the reported 32B number)
Note that Kimi K2 Thinking uses QAT and the native released version has the MoE params as INT4. Treating the always-active part as quanted to 8-bit5 and the routed MoE experts as 4-bit:
bytes/token = 11,722,775,856×1 + 21,140,582,400×0.5 bytes/token = 11,722,775,856+10,570,291,200 = 22,293,067,056 bytes/token
With TPS = 187:
So therefore effective bandwidth = 22,293,067,056×187 = 4,168,803,539,472 bytes/s = approximately 4.17 TB/s.
From these examples, we can see that Google Vertex has roughly 4-4.5 TB/sec memory bandwidth for running models.
Next, we can use that range to estimate the active parameter count for Claude.
If Google Vertex is effectively sustaining about 4.0 to 4.5 TB/sec of weight reads during decode, then for any unknown model we can estimate the number of active bytes per token as:
active bytes per token ≈ effective bandwidth ÷ tokens/sec
Let’s take a look at Claude Opus 4.6 first, since that is the newest Opus variant in the table:
At the low end: 4.0 TB/s ÷ 43 tps = 93.0 GB/token
At the high end: 4.5 TB/s ÷ 43 tps = 104.7 GB/token
So Opus 4.6 appears to be loading about 93 to 105 GB of active weights per token on Google Vertex.
If those weights are served as FP8, that implies about: 93B to 105B active params
If instead those weights are BF16, then divide by two: 46.5B to 52.4B active params
The third case is the more interesting one: FP8 attention/shared expert with FP4 MoE experts. In that setup, the active-parameter estimate goes up, because the average active parameter costs less than 1 byte. It’s the smallest I would reasonably expect Opus to be.6
To convert bytes/token into active params for that scenario, you need an assumption for how much of the active model is always-active dense/shared-expert stuff versus routed MoE experts. The Chinese models above give a reasonable guide. Kimi’s active set is about 35.7% always-active and 64.3% routed MoE, while Deepseek is about 45.6% always-active and 54.4% routed MoE. If you treat the always-active part as FP8 and the routed MoE part as FP4, that works out to an average of about 0.68 to 0.73 bytes per active parameter.
Using that range:
93.0 / 0.73 = 127.4B active params
104.7 / 0.73 = 143.4B active params
93.0 / 0.68 = 136.8B active params
104.7 / 0.68 = 154.0B active params
So under an FP8 dense + FP4 MoE assumption, Opus 4.6 lands around 127B to 154B active parameters.
You can repeat the same exercise for the other Anthropic models in the table:
Opus 4.5 at 40 tps
4.0/40 = 100 GB/token, 4.5/40 = 112.5 GB/token100B-112.5B active params at FP8
137.0B-165.4B at FP8 attention/shared expert + FP4 MoE
(100/0.73 = 137.0, 112.5/0.68 = 165.4)
Opus 4.1 at 24 tps
4.0/24 = 166.7 GB/token, 4.5/24 = 187.5 GB/token166.7B-187.5B active params at FP8
228.3B-275.7B at FP8 attention/shared expert + FP4 MoE
(166.7/0.73 = 228.3, 187.5/0.68 = 275.7)
Opus 4.0 at 23 tps
4.0/23 = 173.9 GB/token, 4.5/23 = 195.7 GB/token173.9B-195.7B active params at FP8
238.2B-287.7B at FP8 attention/shared expert + FP4 MoE
(173.9/0.73 = 238.2, 195.7/0.68 = 287.7)
Sonnet 4.6 at 51 tps
4.0/51 = 78.4 GB/token, 4.5/51 = 88.2 GB/token78.4B-88.2B active params at FP8
107.4B-129.8B at FP8 attention/shared expert + FP4 MoE
(78.4/0.73 = 107.4, 88.2/0.68 = 129.8)
Sonnet 4.5 at 41 tps
4.0/41 = 97.6 GB/token, 4.5/41 = 109.8 GB/token97.6B-109.8B active params at FP8
133.7B-161.5B at FP8 attention/shared expert + FP4 MoE
(97.6/0.73 = 133.7, 109.8/0.68 = 161.5)
In practice, I would HIGHLY doubt that anyone is serving Opus at BF16 in 2026, so the other numbers are what matters. I’d say Opus 4.5/4.6 is probably 100B active parameters based on the FP8 number, or possibly 150B active parameters if using 4-bit MoE experts. That would mean Opus is roughly 3x the size of the Chinese models!
From the Chinese models above, the always-active share of the active set is about 35.7% to 45.6%, which means the routed share is about 64.3% down to 54.4%. This range holds true for most modern models.
They happen to be very good models to sample from, actually. Deepseek has a very middle-of-the-road 8:256 sparsity. GLM-4.7 has the lowest sparsity of any leading model at 8:160 (which is the reason why it’s considered so intelligent despite its small size), and Kimi K2 has the highest sparsity of any leading model at 8:384. All 3 are very good examples! I think we can disregard any higher sparsity than that- any higher, and you’ll run into the Llama 4 problem, where the model is brain damaged.
Then we apply the expert sparsity from the table only to that routed portion:
GLM-4.7: 8:160, so 5.00% of experts are active per token, which means a 20x expansion from active routed experts to total routed experts
Deepseek V3.1: 8:256, so 3.13% active, which means a 32x expansion
Kimi K2: 8:384, so 2.08% active, which means a 48x expansion
So the total-parameter formula is:
total params ≈ always-active params + routed-active params × expert expansion factor
For low end, I’ll use the smaller estimate from the FP8 case: 93B active params
For high end, I’ll use the larger estimate from the FP8 case: 104.7B active params7
That gives:
Low-end split:
always-active = 93 × 45.6% = 42.4B
routed active MoE = 93 × 54.4% = 50.6B
High-end split:
always-active = 104.7 × 35.7% = 37.4B
routed active MoE = 104.7 × 64.3% = 67.3B
Start with the most conservative case, using GLM’s 8:160 routing as a lower bound.
Low end:
total params = 42.4B + 50.6B × 20 = 42.4B + 1,011.8B
total params = 1.05T
High end:
total params = 37.4B + 67.3B × 20 = 37.4B + 1,346.4B
total params = 1.38T
So under a GLM-like routing pattern, Opus 4.6 comes out to about 1.05T to 1.38T total parameters.
Deepseek routes 8 of 256 experts, which I consider the most likely scenario!
Low end:
total params = 42.4B + 50.6B × 32 = 42.4B + 1,618.9B
total params = 1.66T
High end:
total params = 37.4B + 67.3B × 32 = 37.4B + 2,154.3B
total params = 2.19T
So with a Deepseek-like routing pattern, Opus 4.6 ends up around 1.66T to 2.19T total parameters.
Kimi routes 8 of 384 experts, so we get:
Low end:
total params = 42.4B + 50.6B × 48 = 42.4B + 2,428.4B
total params = 2.47T
High end:
total params = 37.4B + 67.3B × 48 = 37.4B + 3,231.5B
total params = 3.27T
So with a Kimi-like routing pattern, Opus 4.6 ends up around 2.47T to 3.27T total parameters.
Opus 4.5/4.6 is almost certainly a very large MoE, but the throughput data points to something in the low-trillion range, not some absurd 10T+ monster.
If Anthropic is using a denser GLM-like routing pattern, then Opus 4.6 probably lands around 1 to 1.5 trillion parameters. If it is closer to Deepseek’s 8:256 sparsity, then it looks more like 1.5 to 2 trillion. If you assume they’re using 4 bit MoE with 8:256 sparsity, then it’s x to x.
And even under a very aggressive Kimi-like 8:384 routing pattern, it only stretches into roughly the 2.5 to 3 trillion range. That is substantially below the casual “10T+” claims people make online.
To get Opus 4.6 to 10T total params from this throughput data, you would need something even more aggressive than Kimi-style sparsity (very unlikely), or you would need the active-parameter estimate above to be very wrong. Either way, that is a much stronger claim than simply saying Opus is large.
I personally believe that Opus 4.5 is in the 1.5T to 2T range in terms of size. It’s a much smaller model that was distilled from Claude Opus 4/4.1 (which was 3x larger, probably around 5T-6T params in size). This is reflected in the API pricing- Claude Opus 4.1 cost $15/$75 MTok input/output, but Claude Opus 4.5/4.6 now costs $5/$25 MTok input/output. That’s 1/3 the price.
Opus 4.6 cannot be 10x larger than the top Chinese models. If Opus was 10x larger than the Chinese models, then Google Vertex/Amazon Bedrock would serve it 10x slower than Deepseek/Kimi/etc. I'd say Opus is roughly 3x size, and therefore 3x the price of the top Chinese models to serve, in reality. If you want to estimate "the actual price to serve Opus", a good rough estimate is to find the price max(Deepseek, Qwen, Kimi, GLM) and multiply it by 2-3. That would be a pretty close guess to actual inference cost for Opus.
On the other hand, I would estimate current Opus 4.5/4.6 is around only 1.5x the size of Sonnet. The token/sec and API pricing numbers strongly point to this conclusion.
From an API cost perspective, Claude Opus 4.5/4.6 cost $5/$25 MTok input/output, while Claude Sonnet 4.5/4.6 cost $3/$15 MTok input/output. That’s just 60% the price, which means it’s unlikely that Opus is many multiples of Sonnet in size!
What gives? In the Claude 3 era, Anthropic never released a Claude 3.5 Opus. There was only a Claude 3.5 Sonnet, and a Claude 3.7 Sonnet.
My guess is that Anthropic learnt a lesson: people would complain too much about not having an Claude 3.5 Opus, and customers would be confused about the lineup! “Is 3.5 Sonnet better than 3 Opus?” was a frequent question back in the day.
So instead of distilling Claude 3 Opus into Claude 3.5 Sonnet (and Claude 3.7 Sonnet), Anthropic decided to name it “Claude Opus 4.5” instead of “Claude Sonnet 4.5”. And then make a slightly smaller Sonnet 4.x line, to reduce confusion. In practice, there’s not that much separating them.
This also gives hints to Anthropic’s approach for training models. I strongly suspect that Anthropic will pretrain a very large, multiple trillion parameter model (Claude 3 Opus, Claude Opus 4). And then, after the very large (and expensive) pretrain, they will iterate their posttrain process on a smaller distilled version of the model, which maximizes results while being much cheaper. They’re probably right- the previous strategy with Claude Sonnet 3.5 and currently Claude Opus 4.5 has worked out very well for them in terms of model performance.
This implies that the true “Claude Opus 4.5” which is the same size as Opus 4/4.1… doesn’t exist. It would be too expensive for Anthropic to train. Training cost scales with active parameters and number of tokens for each pass, so if Anthropic cannot get 3x the value from a 3x more expensive training cost, they would be hurting financially. I think their product people looked at the usage numbers for Opus 4/4.1, realized that they could save a bunch of money by having people just use a midtier heavily posttrained model instead, and renamed Sonnet into Opus. They’re probably not wrong.