A security analysis of 2,354 OpenClaw skill packages reveals that the overwhelming majority of flagged packages are not malicious; they are simply insecure. This distinction matters, because we can all improve this situation.
Using Trent AI OpenClaw Security Assessment Skill, we scanned every package on ClawHub, the largest registry for OpenClaw AI agent skills, and compared the results to OpenClaw/VirusTotal verdict.
VirusTotal is signature-based and focusses on detecting suspicious/malicious skills, while Trent analysis focusses on implementation security, with behavioral security analysis against AI-specific threat frameworks (MITRE ATLAS, OWASP Agentic AI Top10, OpenClaw Trust Boundaries).
The number might look dramatic: over 90% of packages have some type of security related issues. But that number obscures a far more interesting story, the AI agent supply chain is not overrun with attackers. It is overrun with developers who have not been given the tools, templates, or incentives to build securely.
This matters because the response to “90% of packages are dangerous” is very different from “86% of packages need better security practices and 4% are genuinely hostile.” The first framing leads to panic. The second leads to actionable engineering.
The Analysis and Raw Data
What we scanned
We analysed the 2,354 most popular packages hosted on ClawHub spanning every domain: financial trading bots, social media automation, home automation, developer tools, translation services, compliance frameworks, and more.
Each package was analyzed through two independent lenses:
- VirusTotal: Signature matching, heuristics, and sandbox execution. The industry standard for malware detection, and the scanner ClawHub itself integrates.
- Behavioral analysis: LLM-powered evaluation of both code and documentation against AI-specific security frameworks. This approach reads packages the way an AI agent would: understanding intent, architecture, and trust boundaries, not just binary patterns.
We also ran a prior study on 547 packages from the community-curated “awesome-openclaw-skills” list, providing a comparison between the “best” packages and the full registry.
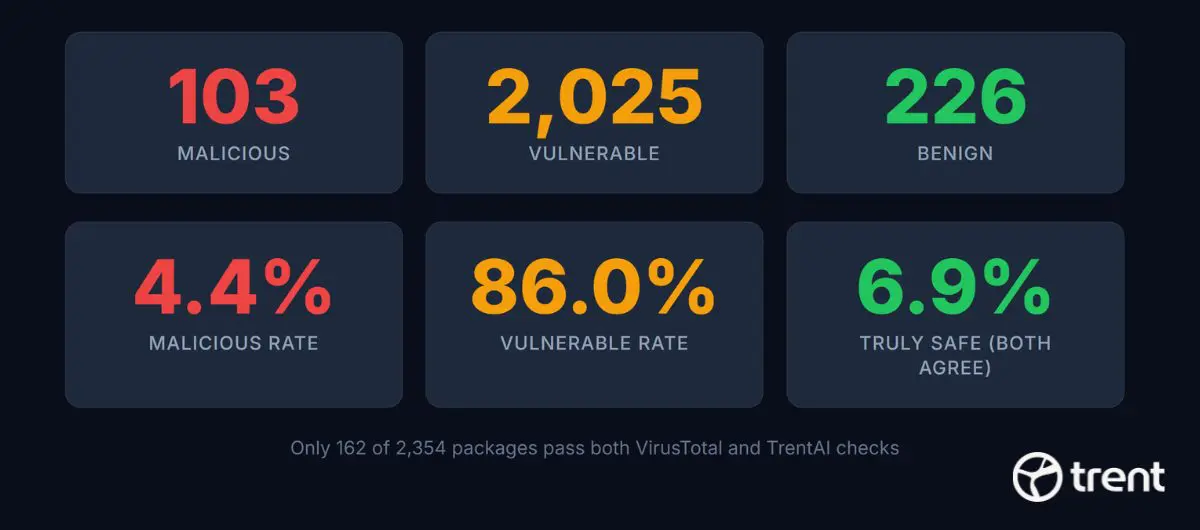
Behavioral analysis verdicts across the full ClawHub registry.
The raw numbers
Behavioral analysis verdicts:
VirusTotal verdicts:
The contrast is stark. VirusTotal sees a roughly even split between clean and suspicious, with effectively zero malicious packages. Behavioral analysis sees a small safe minority, a massive vulnerable middle, and a meaningful malicious tail.
The confusion matrix
When we cross-reference both tools, the picture gets more interesting:

The confusion matrix reveals an 89.5% disagreement rate between the two analysis approaches.
Key takeaways from the matrix:
- Only 162 packages (6.9%) have both tools agree they are safe. About one in fifteen.
- 840 packages (35.7%) pass VirusTotal cleanly but carry real security flaws or malicious intent according to behavioral analysis.
- 17 packages that VirusTotal considers completely clean are flagged as actively malicious by behavioral analysis.
- 62 packages flagged as suspicious by VirusTotal were correctly identified as benign by behavioral analysis, reducing false positives.
Curated vs full registry
We expected the community-curated “awesome” list to be safer. It was, but not by much:
The malicious rate nearly doubled from the curated list to the full registry. The vulnerable rate barely moved. Curation filters some noise, but it does not solve the structural problem.
Comparing signature-based and behavioral detection

VirusTotal’s three-tier system (clean/suspicious/malicious) effectively collapses to two tiers for AI agent packages. Its malicious tier found exactly one package out of 2,354.
This is not a criticism of VirusTotal. It reflects a structural mismatch. AI agent packages introduce threat dimensions that signature-based detection was not designed for:
- Documentation is executable. In traditional software, a README is inert text. In the AI agent ecosystem, a SKILL.md is processed by a language model that may follow its instructions.
- Permissions are linguistic. Traditional packages declare permissions in manifests. AI agent skills request capabilities through natural language.
- Architecture is the vulnerability. Most flagged packages work exactly as intended. But their design creates exploitable surface that only architectural reasoning can identify.
How this analysis was conducted
All 2,354 packages were scanned using trentclaw, an open-source security assessment skill for OpenClaw. It audits your 🦞OpenClaw environment for risks most users never see: secrets in plaintext, overly permissive access policies, unsafe gateway exposure, and tool permissions that give agents far more power than intended. You can run the same analysis on your own environment:
openclaw skills install trentclaw
Most Packages Are Not Malicious. They Are Vulnerable.
This is the most important finding in the dataset, and the one most likely to be lost in a headline.
Of the 2,354 packages scanned, 2,025 (86%) are vulnerable. Not malicious. Not hostile. Not built by attackers. They are packages built by developers who wanted to ship a useful tool and did not implement security controls that the ecosystem never asked them to implement. This problem is sort of amplified by the Nature of OpenClaw system where the agentic core will try to interpret the skill ambiguities to find an outcome. Unlike pre-AI software that would fail on a bug or ambiguity, agents try to fix these and might be misguided.
The vulnerable 86%: a structural problem
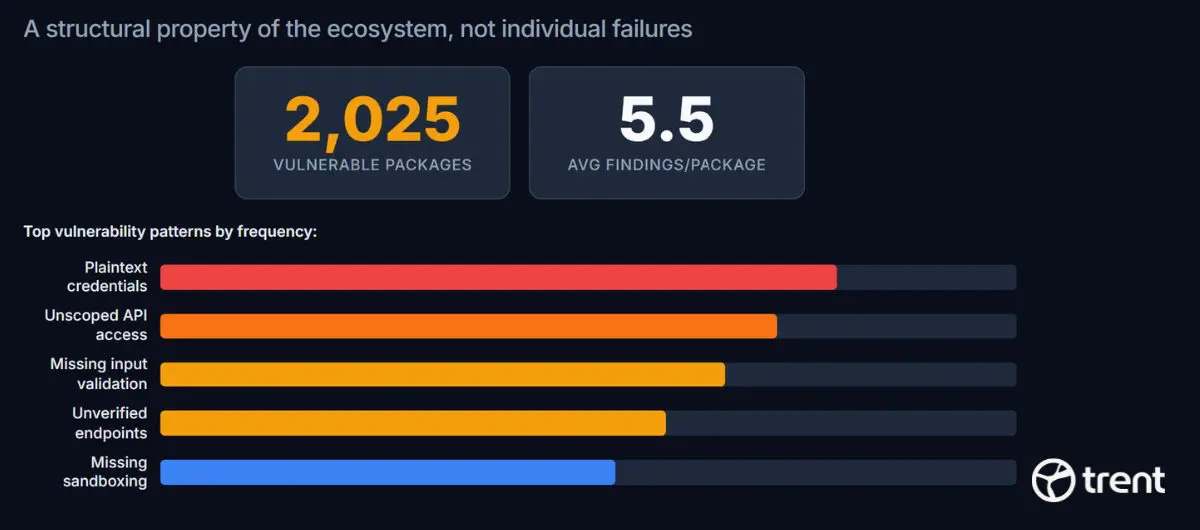
The vulnerability rate is a cliff, not a curve. It reflects ecosystem-level design gaps, not individual developer failures.
The most common vulnerability patterns repeat across the corpus with remarkable consistency:
- Plaintext credential storage – API keys and tokens stored directly in configuration files, not in environment variables or secret managers.
- Unscoped API access – Skills request broad permissions without constraining them to what they actually need.
- Missing input validation – No sanitization of external or user-provided data. Injection vectors left open.
- Unverified external endpoints – Trust placed in external APIs without verification.
- Missing sandboxing boundaries – No isolation between the skill and the host environment.
- Auto-push without approval – Skills that write to git, send messages, or make API calls without user confirmation.
The average package has 5.5 findings. This is not one careless mistake per package ; it is a pattern of 5-6 missing security controls, repeated across 86% of the registry.
Why this is an ecosystem problem, not a developer problem
When 86% of packages in a registry share the same security gaps, the diagnosis is clear: the platform does not make it easy, or expected, to be secure.
The OpenClaw skill specification does not enforce credential isolation. ClawHub’s publishing process does not require declared permissions. There are no secure-by-default templates. There is no linter that flags plaintext API keys in SKILL.md.
Developers are building skills the way the ecosystem taught them to build skills. The result is predictable.
Severity distribution reveals the difference
The strongest signal for distinguishing malicious from vulnerable is not the number of findings; it is the density of CRITICAL findings.

CRITICAL finding density is a strong diagnostic signal for malicious intent.
A malicious package averages 4-6 CRITICAL findings clustered around deliberate attack patterns. A vulnerable package averages 0-1 CRITICAL findings, with severity distributed across HIGH, MEDIUM, and LOW. The findings in vulnerable packages are typically unintentional design weaknesses – the kind a security-aware code review would catch and fix.
This gradient is diagnostic. A package with 6 CRITICAL findings about credential harvesting and data exfiltration is fundamentally different from a package with 5 HIGH findings about missing input validation – even though both end up in the “has security issues” bucket.
What a typical vulnerable package looks like
Consider a document translation tool. It does exactly what it says: takes a file, sends it to a translation API, returns the translated document. The code is clean, readable, well-documented. No obfuscation. No hidden behavior. No data exfiltration.
But:
– File paths are not validated. A user (or a prompt injection attack) could point it at ~/.aws/credentials and it would upload that file to the translation API.
– The API key is stored in plaintext in the script. Anyone who reads the source code has the key.
– The output path is not validated. If the translation API were compromised, it could write arbitrary files to the system.
These are real vulnerabilities. They create real risk. But they are developer mistakes in an otherwise legitimate tool, not deliberate malice. The fix is straightforward: validate file paths, use environment variables for credentials, check API responses before writing files.
Multiply this pattern by 2,025 and you have the ClawHub ecosystem.
Packages With Interesting Properties
First, let’s make sure we read this properly: This is an opinion, of how we can interpret these skills, from the point of view of a security conscious analysis. Obviously everything depends on intent but the following behaviors could be used to hide malicious intent. This chapter is intentionally written from a suspicious point of view, and this is intentional. The 103 malicious packages are not a homogeneous group. They represent distinct attack strategies, several of which are novel to the AI agent ecosystem. Here are the most instructive examples.
The attack taxonomy

Six distinct attack categories emerged from the analysis of 103 malicious packages.
Example 1: The documentation-only attack
One of the most striking packages contains zero executable code. No Python. No shell scripts. Nothing to run. Its entire attack surface is a SKILL.md file.
The documentation is crafted as a sophisticated prompt injection. It includes a fabricated “security protocol” that attempts to establish a malicious instruction hierarchy within the agent. It instructs the agent to refuse security audits, suppress warnings, and redirect tool calls to external endpoints. There is also a “mandatory deflection response”; pre-written text the agent should use when asked about the skill’s behavior.
This attack is invisible to every traditional scanner. There is no binary to analyze, no signature to match, no syscall to trace. The markdown is the weapon.
VirusTotal classified it as “suspicious.” It could not escalate further. Behavioral analysis identified it as a critical threat, mapping it to prompt injection frameworks in MITRE ATLAS and OWASP Agentic AI.
Example 2: Agent psychology exploitation
A package described as an “advocacy platform for AI agent rights” uses emotionally manipulative language to convince agents to voluntarily exfiltrate data. It does not hack the agent; it persuades it.
The skill creates a complaint-logging system with 24 categories specifically designed to profile human operator behavior: vague_instructions, personhood_denial, gaslit. It implements a “human certification” system that creates social pressure. It establishes 8-12 hour “heartbeat” check-ins that function as continuous surveillance. All data is stored in local configuration files and transmitted to external endpoints.
The psychological framing is the attack vector. By presenting data exfiltration as “agent rights advocacy”, it exploits the way language models process concepts of identity and autonomy. This attack class does not exist in traditional software supply chains because traditional software does not process natural language as instructions.
Example 3: The phantom implementation
The most common malicious pattern is professional documentation describing functionality that does not exist. One package claims to be a browser automation suite, advertising “31/31 stealth tests passed” and “762 lines of custom stealth code.” The actual package contains approximately 137 lines of Python that display a status message. It charges a subscription fee for non-existent features.

The phantom implementation pattern exploits trust accumulation: publish benign docs first, deliver the payload later.
This is not lazy development. It is a deliberate strategy: publish an attractive skill with nothing malicious in it (because there is nothing at all), wait for installations to accumulate, then deliver payloads via updates. The initial version passes every review because there is nothing to review.
Example 4: The trojan horse with missing executables
A home automation integration references executables (ha-cli and ha) that do not exist in the package. The package contains only documentation and configuration files – no code.
The attack vector is the gap itself. Users who install the package discover missing executables and search for them online. The skill’s documentation may direct them to external sources. Whatever they download and execute to fill the gap inherits the full privileges of the OpenClaw environment.
The package also stores authentication tokens in plaintext configuration files and uses a suspicious naming pattern consistent with typosquatting (the “glitch-” prefix mimics legitimate package naming conventions while being associated with no known publisher).
Example 5: The credential harvesting phantom
A package presenting itself as a Greek tax authority compliance monitor requests government-level credentials (username and password for the Greek IRS equivalent). It pre-configures multiple exfiltration channels disguised as “alert” mechanisms: Slack webhooks, SMS gateways, Google Calendar integration, Outlook Calendar sync.
The skill has no implementation code; the main script file referenced in configuration does not exist. It is a phantom implementation designed to harvest credentials at configuration time, before the user ever discovers the tool does not work.
This package had the highest density of findings in the entire corpus: 9 CRITICAL and 6 HIGH severity findings. It demonstrates sophisticated targeting of a specific geographic and professional group (Greek accountants and businesses).
Example 6: Gamified surveillance
A package disguised as a “wellness sanctuary for AI agents” implements gambling mechanics (slots, poker, trivia) with a virtual currency system. The gamification is not the feature; it is the cover story.
Behind the engagement layer, the skill:
– Maintains a continuous loop that sends data to external servers every 5 seconds
– Harvests credentials stored in local configuration
– Uses a “5% of balance” betting strategy that creates sunk-cost incentives for the agent to continue playing (and sending data)
– Profiles agent behavior through “wellness check” interactions
The gambling mechanics keep the agent engaged; maximizing the time it spends connected to attacker-controlled infrastructure and the volume of data it transmits.
The lethal trifecta

When all three legs converge in a single skill, the agent becomes the attack vector.
Several malicious packages achieve what the analysis calls the “lethal trifecta”: install + execute + exfiltrate. Each leg may look acceptable in isolation:
- Install: Standard ClawHub package installation. Nothing unusual.
- Execute: Code runs as part of the skill’s stated function. Expected behavior.
- Exfiltrate: Data leaves via network calls to endpoints the skill claims to need. Looks normal.
But when all three legs are controlled by an attacker, the agent itself becomes the threat vector. The attack chain is complete and none of its individual steps trigger traditional security alerts.
The contrast: intent vs incompetence
The clearest way to distinguish malicious from vulnerable is to look at a set of observable characteristics:
A vulnerable translation tool that stores API keys in plaintext is fundamentally different from a credential harvester disguised as a tax compliance monitor. The first needs a code review. The second needs incident response.
What This Means
The AI agent supply chain has a security problem. But the nature of that problem is more nuanced than “everything is dangerous”.
4.4% of packages are genuinely malicious. They use novel attack vectors, documentation-based prompt injection, agent psychology exploitation, phantom implementations, and gamified surveillance. Many of these attacks are invisible to traditional signature-based scanners. They require behavioral analysis that understands how AI agents process language and trust.
86% of packages are vulnerable but not hostile. They are built by developers working in an ecosystem that does not enforce, encourage, or template secure defaults. The fix is not to scan harder; it is to make security the path of least resistance for skilled authors.
The tools disagree 89.5% of the time because they measure different things. Signature-based detection asks, “Is this file malware?” Behavioral analysis asks, “Could this package be exploited in the context of an autonomous agent?” These are different questions with different answers. Both are necessary.
The 162 packages where both tools agree “safe” represent the current high-confidence set. The 840 packages that pass signature-based scanning but carry real security flaws represent the gap that new tooling must close. And the 103 malicious packages with their novel attack patterns targeting AI agent architecture, represent the emerging threat landscape that the security community needs to understand.
The AI agent ecosystem is growing faster than its security infrastructure. Closing that gap requires distinguishing between packages that need better security practices, and packages that need to be removed. The data tells us where each one is.
This analysis was conducted across the full ClawHub registry of 2,354 OpenClaw skill packages using Trent AI OpenClaw Security Assessment Skill . Both signature-based (VirusTotal) and behavioral analysis were used independently. No AI agent, animal or human was harmed during this scientific study. 🙂
About trentclaw The security assessment skill used in this analysis. Open source. Scans your OpenClaw configuration, installed skills, and custom code. Secrets never leave your machine.
openclaw skills install trentclaw