As part of my 2026 roadmap as Head of Data at nao, I have one clear goal:
Set up agentic analytics for the whole team 🔥. Not just for people who know SQL or dbt — but for anyone.
The problem? After talking with data peers and nao users, one thing became obvious: no one has really figured it out yet. There’s no standard, no clear winner. Everyone is either experimenting with different tools or quietly building something in-house.
💡 So I decided to do what data people do best: run a real benchmark, on real data, in real conditions.
The goal is simple: find a solution I could actually implement — and share the learnings so other data teams don’t have to start from scratch.
My objective is: anyone at nao should be able to ask a question about our data without relying on me.
My constraints are: the solution needs to be reliable, fast, and well priced.
Criterion
I defined the KPIs I want to measure, as well as the features I expect.
There are 5 main criterion:
End user UX: How easy it is for any user - technical or not - to run analytics. The UI must be intuitive, explain the agent reasoning, and give some interactive features for deep-diving.
Reliability: We want to answer as many questions as possible, reliably. I don’t expect this to work out of the box, so we need the ability to customize context, evaluate the agent on a set of unit tests, and monitor real user usage over time.
Speed: How quickly the agent returns an answer.
Cost: Total cost of the solution : cost of software + LLM cost + compute cost.
Data team UX: How easy is it to set up the tool? Does it rely on what we already have? Are we locked in the solution?
Testing a real use case
On each solution, I will test a real use case on real nao data:
What’s the percentage of users who churned last month?
Why this is tricky:
Subscription data is in 3 different tables (dim_users, fct_stripe_subscriptions, fct_stripe_mrr)
One subscription can include multiple users
Churn must be compared to last month paying users: churned users this month / paying users last month (and not paying users this month)
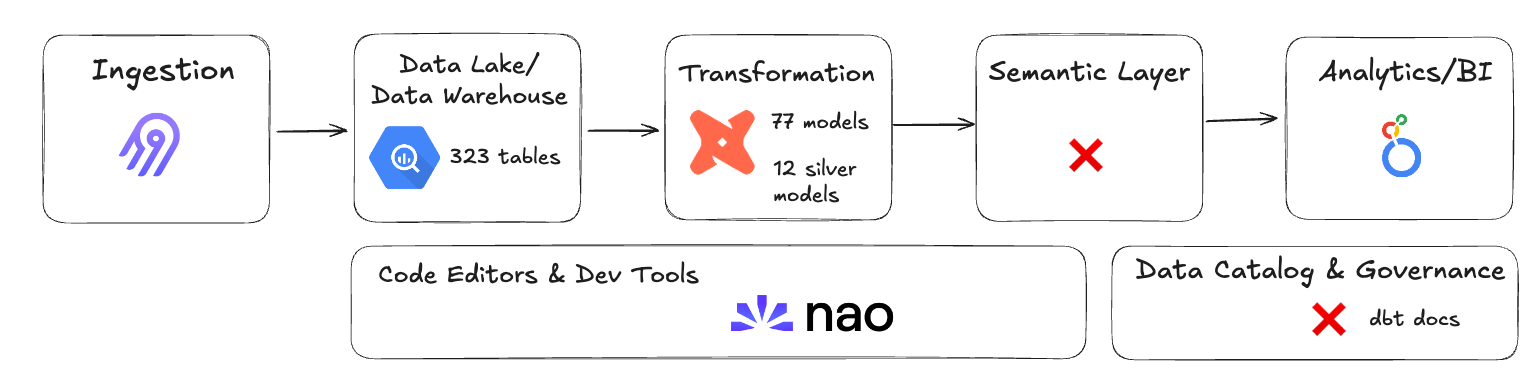
I will test the performance of the agent only with the current assets I have:
dbt docs (mostly AI generated)
Tables with no description
A .naorules file with basic AI instruction for my dbt codebase
🔍 Quick view of our data stack:
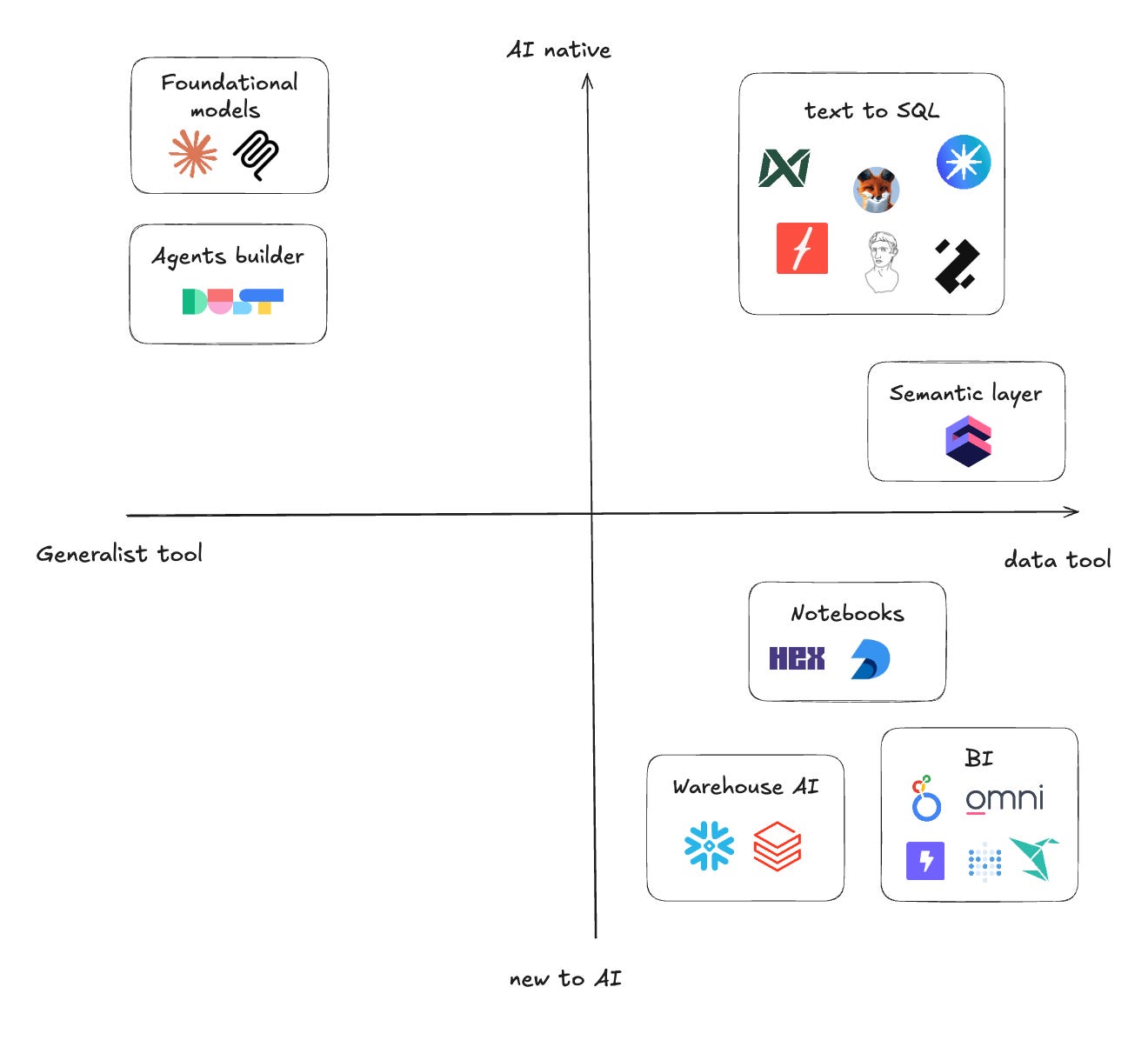
There are a LOT of options available - as you can see:
When I talk to other data teams the most popular options are:
Use your Data warehouse tool (Snowflake Cortex, Databricks Genie)
Build custom agents with general agent tooling (Claude, Dust)
Use your BI tool AI feature (Hex, Looker)
Migrate to an AI-native BI tool (Omni)
Build in-house analytics agent
Buy a native text to SQL tool (textQL, Cube, dot, etc.)
This is how I prioritized options to test:
First, try the most popular tools (Snowflake, Omni, Dust, Dagster compass, Hex, Genie)
Then, try to build something on my own (Claude + MCP)
Finally, test solutions that are natively built for this (Cube, textQL & co)
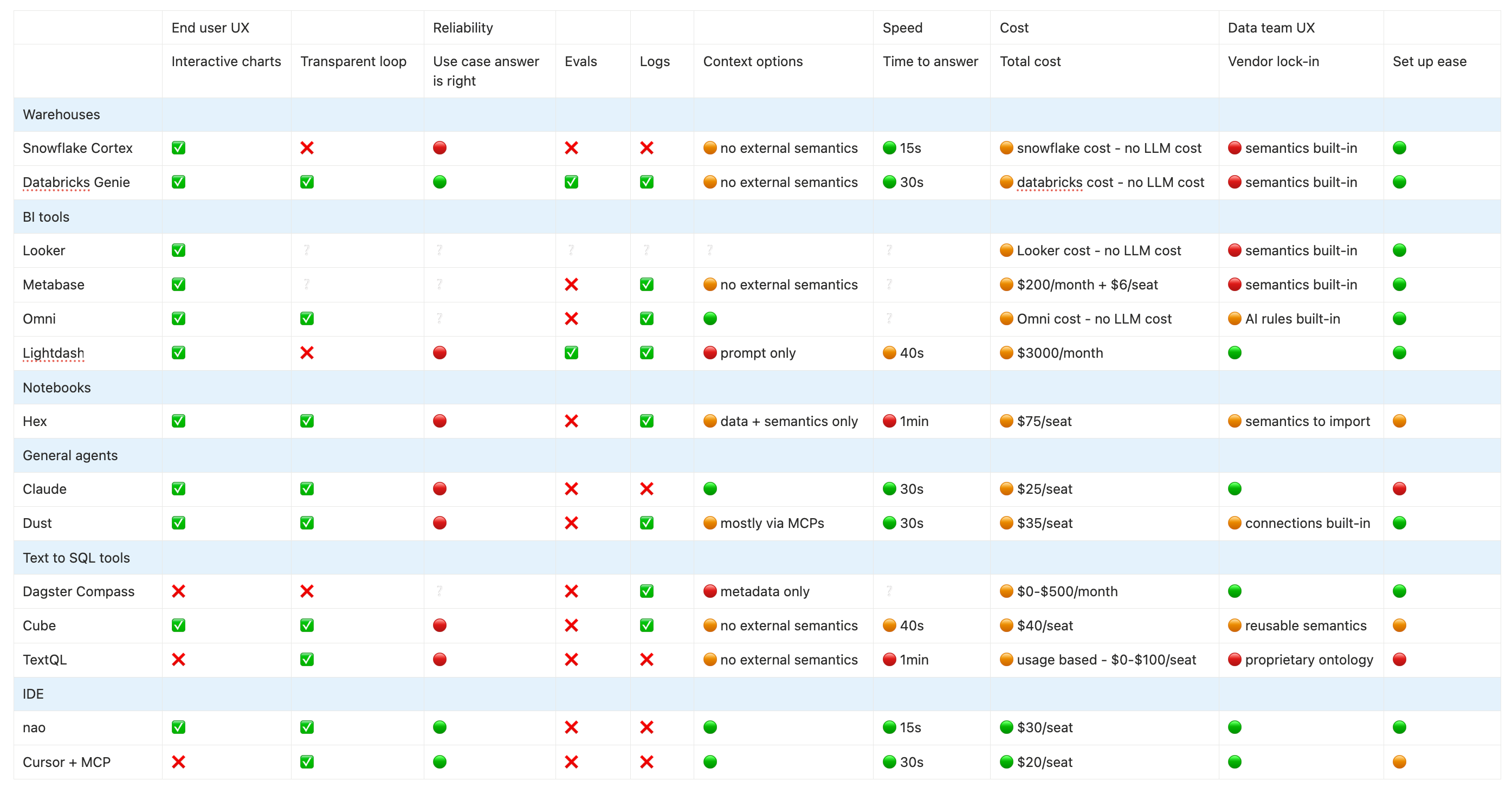
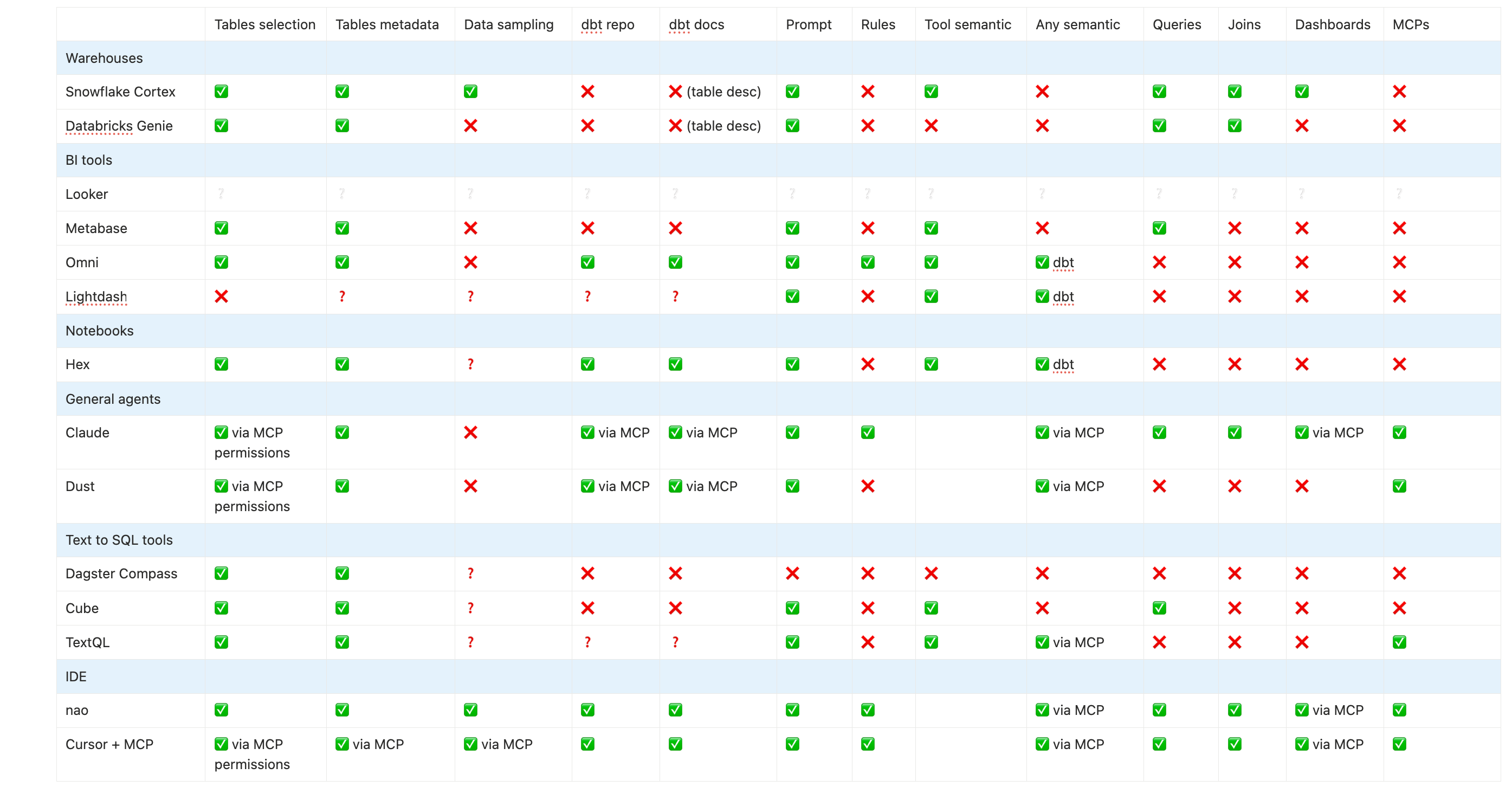
Easy to set up - if your snowflake is in the right region (only AWS hosting). You just need to create a semantic view (select tables + add a prompt) and it works. However, if you want to create semantics, you have to create them in snowflake (or import a yaml), but it’s not directly connected to your existing semantic layer.
Big issue is: snowflake cortex works only for people with a snowflake account. If you want to roll it out to the whole company, you need to use Snowflake Intelligence - which is set up with SQL commands + has no native usage tracking. So very bad data team UX.
Second thing missing: there is no framework for agent evaluation.
The strengths of Databricks genie are: the clarity of eval + monitoring framework, and the quality of the research agent - one of the few who gave the right answer to my question.
It’s easy to set up but the context options are limited - no link to dbt or any semantic layer.
The chat UI is nice, fast, and shows its reasoning.
Couldn’t test it easily as Metabot is cloud version only. Feedback from one user said it was not reliable + issue is depending on Metabase built-in semantic layer.
Not in self-serve but got several good feedbacks on it. It reuses dbt semantics, and you only need to create “AI topics”. Good UX for both users and the data team, with good reliability - declared.
Main issue is that it’s costly, so it only makes sense if you’re ready to move your entire BI to Omni.
Lightdash agent is only available in the cloud version, for an add-on fee. It’s easy to set up, it just takes the whole content of lightdash (data + dbt semantics) + you add a prompt and you’re good to go. So it works fast, but it’s not easily configurable.
Hex has a full context studio for AI agent, where you can add: system prompt + semantics + endorsed tables. Semantics can be created in Hex, or imported via a GitHub action - that you need to create, a little bit of work to set up.
It uses Hex notebook and charts UI, which gives a good UX for non technical users - but is still quite technical if they want to deep-dive.
The main weak points are that the chat is still quite slow - it took more than a minute to answer my question vs 20 sec for other providers - and that there is no proper eval framework.
With Claude, the setup is limitless in terms of context. You can add any MCP you want, every context you want as files.
Weaknesses are: you need to set up every MCP yourself, so it’s hard to have a uniform setup for the whole company. The context selection is decentralized through the permissions of each MCP. The chart capabilities are limited. It’s also hard to track usage because you don’t have a log history of everyone at your company.
In short: easy to POC, hard to roll out to the whole company.
Dust is easy to set up - connect your BigQuery and you can ask questions on your data. But it’s harder to add modular context: dbt, semantics, data documentation → all of this needs to be added by indirect methods (MCPs, adding files in a drive with a script, or connecting to a GitHub)
The UI for business people is good thanks to frames. But deep-dive options seem limited for data people. The real missing piece is the lack eval or real log tracking - since it is not a data-centric agent.
I am stuck in an infinite login loop so couldn’t test Compass. But from the docs, I can see that it’s easy to setup but limited in its context UI. It’s mainly a Slack bot based on your data schema, unclear what other context it uses.
Good feature though is that context is versioned as a Git repository.
TextQL… is its own tool. It seems to have put all its efforts into building its own ontology principle - which is quite hard to understand. Docs say it integrates with dbt, but could not find how to set it up. In any case, the ontology is complete vendor lock in + extra work.
The UI has been completely left behind. As a data person, I hoped nobody would show me matplotlib charts ever again but here it is - the python script starts streaming and ends up showing me non-interactive viridis-colored matplotlib charts.
The chat is quite slow, the price is usage-based so unpredictable, and there’s no tooling for eval or monitoring.
IDEs
I added a comparison to nao, because a lot of our users actually use nao for analytics.
nao works very well because you can add all the context you want - whatever your stack is - and you can see transparently which context the agent has access to and uses. Everything is in a file system and agents are really good at working in file systems.
My ideal would be to find this kind of reliability, and interface but configured for business users.
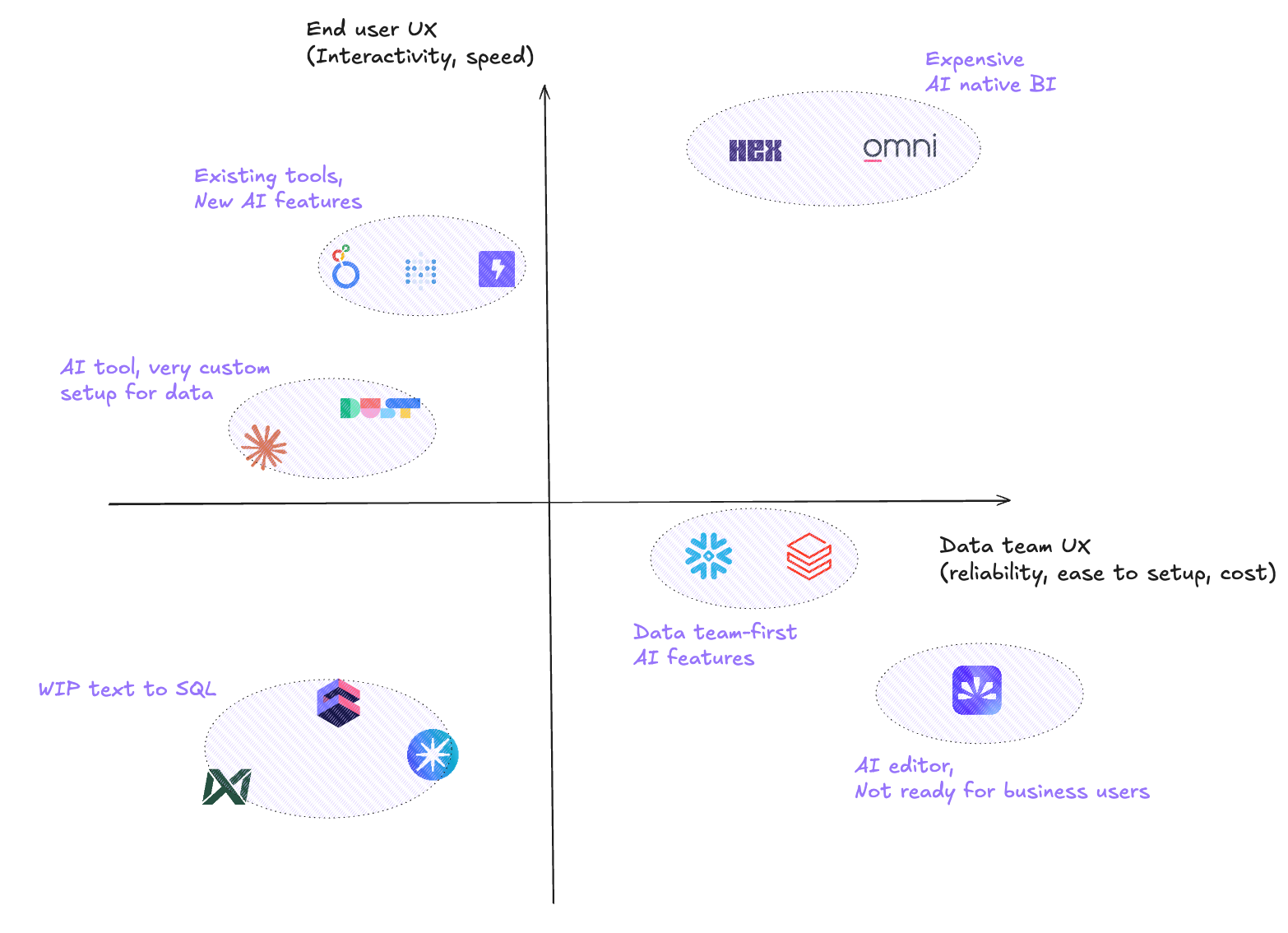
I tried to sum up the evaluations in 2 dimensions: end user UX + data team UX.
If you want to maximize end user UX + data team UX you have to go for AI native BI tools. But it means you need to 1/ migrate your existing BI, 2/ pay a lot.
Existing BI tools will maximize end user UX - they already know the UX - but their AI features are not really mature.
Generalist AI tools also are good end user UX - they already use them - but harder to customize by the data tool.
Warehouses have a good data team UX, but still are hard to put in hands of business users - and not every warehouse has the same AI maturity.
AI editors are working good for data teams, but are not ready for business users.
Text to SQL tools seem still WIP - end user UX is new, data teams often need to rebuild context in them, and have no guarantee of reliability.
In the end, since our BI is not set up yet, I’d tend to go for omni - easy setup with dbt, good business user UI, good AI performance. Just let me ask for a quote first!
Final thought here: AI agents seem to work best today in a folder-like, inspectable context architecture. That’s why nao, Cursor, Claude Code are working so well. But no one reproduces this experience for agentic analytics. I think there’s something to be done here!
I come from the data science world. I like training, evaluation, feature engineering.
We need to be able to answer this one question:
How good is my agent? How good is my context?
My next step in this investigation will be to doadeep-dive into context engineering: I’ll create a small in-house agent to test the reliability, speed, cost of the agent depending of which piece of context is added.
I’ll document this in next article, stay tuned 👀
I’m also curious to hear if you agree with my evaluations, or see any other solution to try!