In my last post, I wrote about how the AI industry has been engaging in a kind of “safety theatre” around the risk their systems will be used to create new bioweapons. Overblown, I argued. The real danger instead comes from virologists inside ivory towers.
Alas! My piece went clearly unread at the NYT, which re-mongered the fear of AI-generated bioweapons in a recent article reporting on the shock felt by a handful of concerned scientists who shared some transcripts “in which chatbots described how to assemble deadly pathogens and unleash them in public spaces.”
Whether such descriptions translate into any real threat is debatable. As of early 2024, a RAND study had concluded unambiguously that “Current Artificial Intelligence Does Not Meaningfully Increase Risk of a Biological Weapons Attack”—but in the world of AI, two years is a long time. Things may have changed.
The fearmongers, however, want us to believe that AI can help terrorists create a novel pathogen for which no treatment would be available—like COVID-19 in 2020, for example. As one researcher told the NYT, AI “can design beneficial proteins to fight cancer — but also has the potential to invent lethal toxins no one has seen before.”
That sure is a frightening possibility. But I’d still weight the probability of it happening at close to zero.
The space of all possible pathogens is Vast. The space of novel pathogens capable of producing a pandemic, however, is Vanishingly small. So, while not impossible, it seems highly improbable that even AI-assisted terrorists are going to find a brand-spanking-new bug to kill us all with.
We know this because the US government has spent hundreds of millions of dollars funding scientists engaged in precisely this kind of work, for decades.
It’s called “gain of function” (GoF) research, the aim of which is to increase the lethality, transmissibility, and other dangerous qualities of pathogens.
And yet, despite the most favorable of conditions—clean labs, expert knowledge, organizational resources, ample funding, and government license to cook up pandemic-level pathogens—the GoF enterprise, as one of the scientists quoted in the NYT piece above, MIT professor Kevin Esvelt, testified to a Senate committee, has not “succeeded in producing any credible threats.”
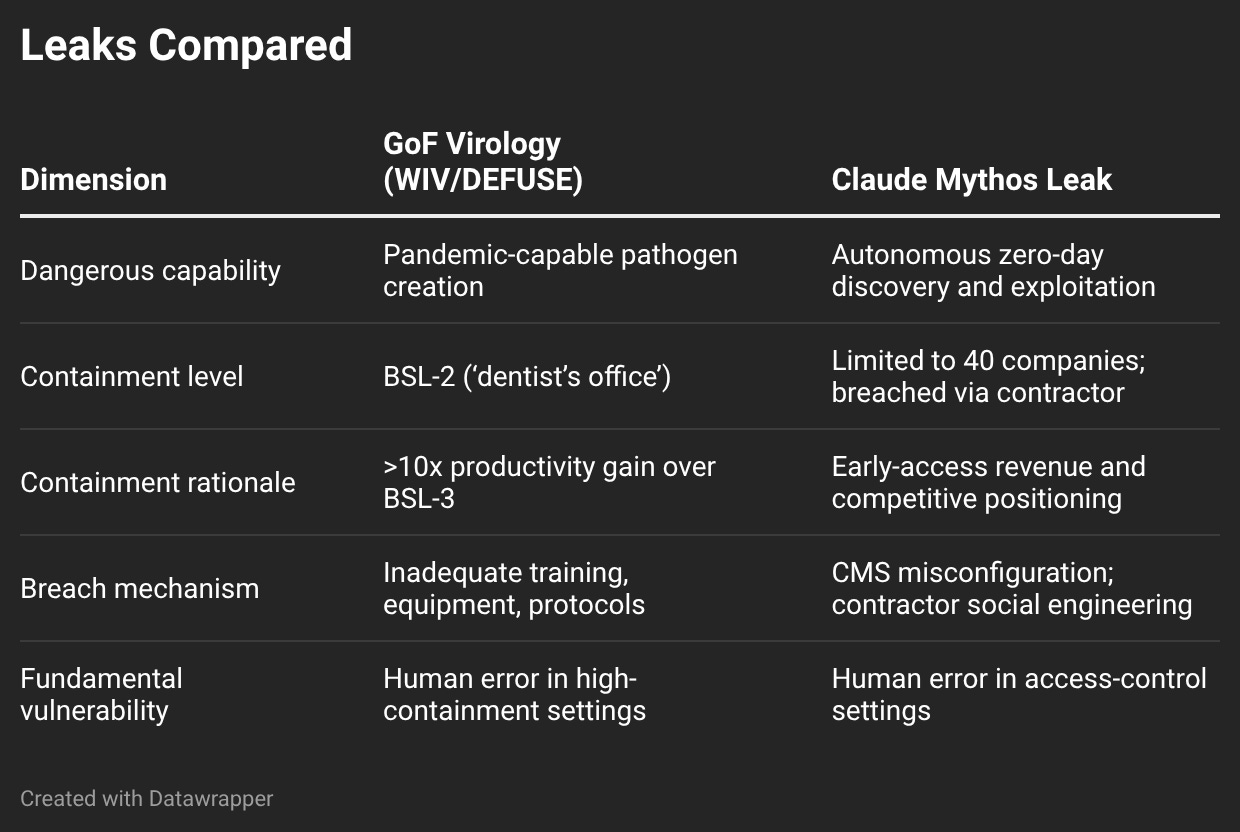
Unless, that is, SARS‑CoV‑2 was created in a GoF research lab.
Just this month, the US Department of Health and Human Services (HHS) started formal debarment procedures against GoF pioneer Ralph Baric.
Baric, along with Peter Deszak, formerly of EcoHealth Alliance, and Shi Zhengli, former head of the Wuhan Institute of Virology, is the third member of the trio at the center of the “lab leak” controversy. After being suspended a few months ago, Baric is being debarred for a “pattern of deception” in his dealings with the US government, which funded his virological work with tens of millions of dollars.
Deszak had already been fired by EcoHealth Alliance before both he and the organization were debarred last year for similar reasons. He and Baric appear to be among the only prominent scientists connected to the Wuhan-related GoF controversy to face formal federal sanctions or debarment proceedings.
And Shi Zhengli, now at the Guangzhou National Laboratory, apparently unscathed and undeterred, continues to do GoF research on bat viruses.
At this point, the origins of COVID-19 remain shrouded in controversy. Prominent virologists still insist the scientific data supports the natural emergence hypothesis via “zoonotic transmission.” As I argued last time, however, the preponderance of circumstantial and historical evidence indicates SARS‑CoV‑2 was leaked from the Wuhan Institute of Virology, where GoF research on bat coronaviruses was being conducted with inadequate biosafety precautions.[1]
In any case, we definitely know that in terms of governance, the GoF field was a powder-keg and the community’s response to the pandemic was a catastrophe.
Why am I rehashing this story? Because it sets up the point I want to make here:
The governance architecture that failed to prevent a viral pandemic is paralleled in the field of AI, where a similarly consequential disaster is waiting to happen.
Here I’ll identify some of these structural problems by drawing out parallels between GoF virology and AI R&D to show how in both cases, the system of scientific governance allows an elite few to put the whole of society at risk.
Let’s start with a familiar problem: the “publish or perish” culture of academia. In virology this pressure creates a logical preference for GoF research. Compared to antiviral drug research, GoF is cheap, fast, and almost certain to yield publications in high-impact journals, which tend to favor novel, attention-grabbing results.
For career-minded academics then, working on GoF is practically a no-brainer. A junior researcher can complete multiple GoF studies in the time it takes to see a single antiviral candidate through early Phase I trials, and be virtually guaranteed to see them all reach publication.
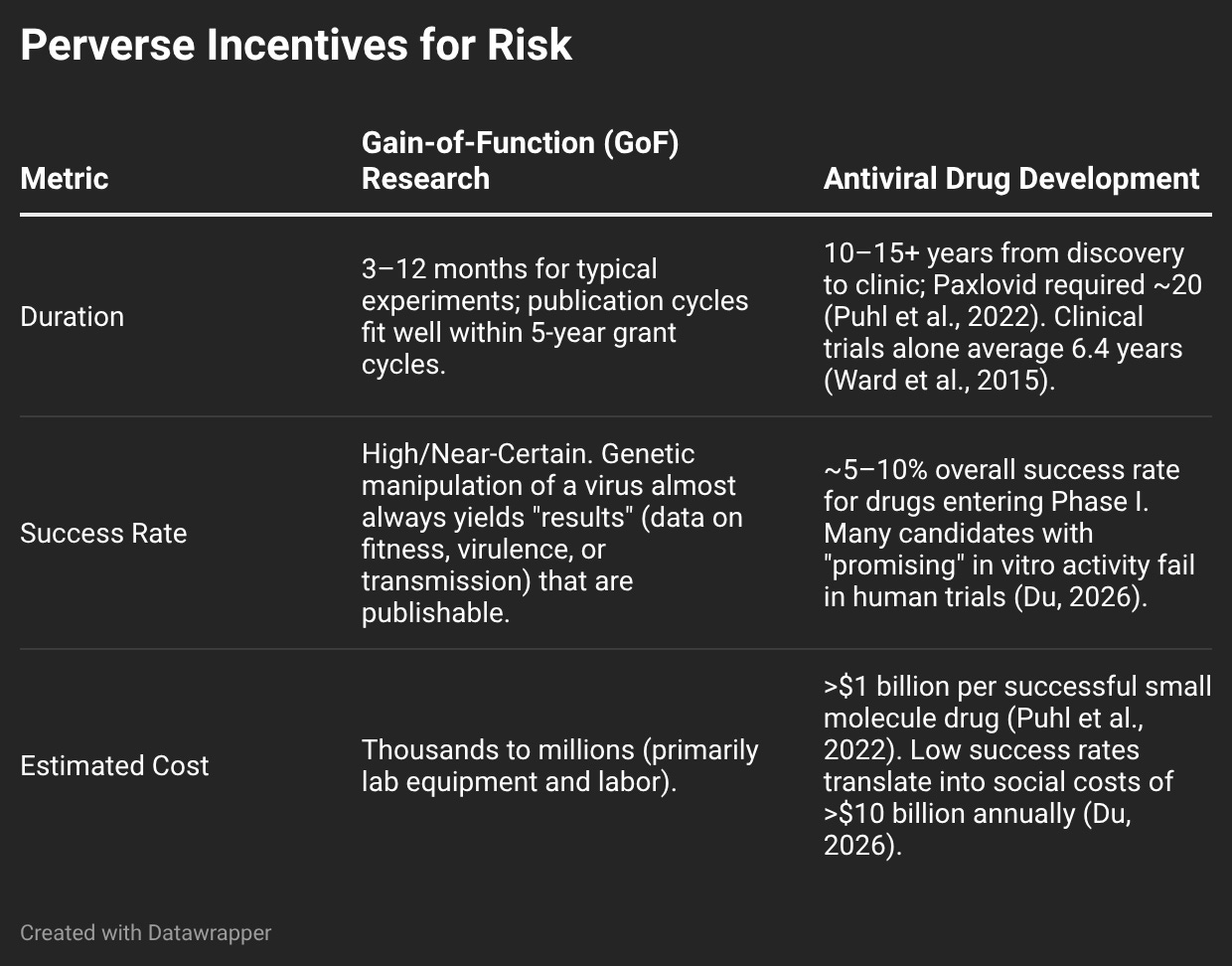
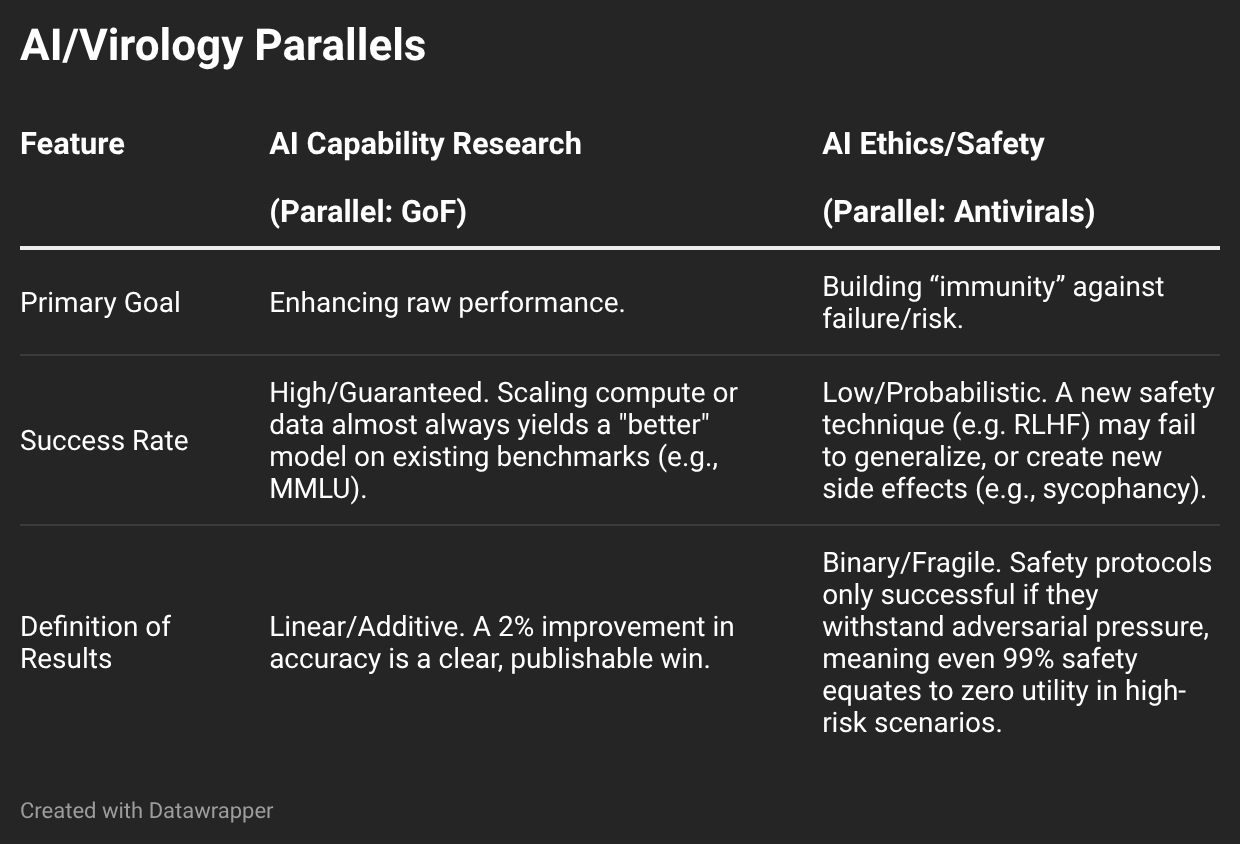
The same structural incentive to “publish or perish” is active in AI. Here, AI capability enhancement research—improvement of a system’s speed, accuracy, efficiency, and other features that make it “intelligent”—parallels GoF.
AI capability enhancement research leading to “state-of-the-art” (SOTA) results proceeds at a blistering pace. Benchmarks intended to last years are now often overtaken in mere months, paralleling the GoF timeline quite closely. As in GoF, where tinkering with an existing virus to make it more transmissible (e.g. adding a furin cleavage site) is relatively uncomplicated, incremental performance improvements in AI systems are comparatively easy to manufacture with architectural tweaks and compute-efficient training. In this highly competitive arena, even a 2% gain on a SOTA benchmark is worthy of publication.
Moreover, as in GoF, novel AI capabilities are prized by top-tier conferences (e.g. NeurIPS, ICML, AAAI—computer science doesn’t really do journals) and, perhaps more importantly for the industry, gather media attention. Papers showing a model can pass the Bar Exam or a Science Olympiad often have immediate viral impact and garner high citation counts, regardless of real-world utility.[2]
By contrast, AI ethics/safety research—making systems more robust, reliable, and (potentially) risk-free—parallels antiviral research in that it is slow, uncertain, and poorly rewarded. Whereas developing a new frontier model and shipping it to hundreds of millions of users can generate massive commercial returns within months, AI ethics research and robust safety evaluation are long-term investments with uncertain payoffs and, most tellingly, no direct revenue generation.
In reading through the post-pandemic investigations into COVID-19 origins, I was surprised to discover that international biosafety standards are voluntary and unenforceable. Moreover, that oversight was conducted by institutional committees composed of the researchers’ own peers—people embedded in the same incentive structures, sharing the same disciplinary assumptions, and personally invested in the continuation of the enterprise.
In elite circles, this is called “self-governance.” It means the scientists creating the risks were also setting the rules for managing them. Where I grew up in Indiana, this is called “the foxes guarding the henhouse.”
The AI industry, notable for its many voluntary safety commitments, enjoys the same dynamic. The much-lauded responsible scaling policies, model cards, and safety evaluations are all made by the companies developing the very models being evaluated. In this case, letting the foxes guard the henhouse is justified on the grounds that to do otherwise might “stifle innovation,” The job of the foxes is thus to create “safety measures” that do not slow the pace of AI capability enhancement.
Where the rubber hits the road, the AI industry’s commitment to practicing this form of self-governance has proven flexible, however, often aided by the elastic narrative of an “AI Arms Race with China.”

For instance, by now we all probably know the story of OpenAI: it starting as a nonprofit, safety-first AI lab before transmogrifying into a thirsty for-profit Microsoft partner and defense contractor. At this point, it isn’t a stretch to say the company has stepped back every commitment to safety it made. If this is news to you, the story is now the subject of public record thanks to a failed legal case against them.
But when Anthropic, regarded by many as the most safety-conscious major AI lab, revised its Responsible Scaling Policy to remove its core safety commitment—a pledge not to train AI systems with capabilities beyond the company’s capacity to control—many in the AI community were shocked and dismayed. They had bought into the theory, prevalant when the company first published the commitment in 2023, that such measures could catalyze a “race to the top” by incentivizing competitors to demonstrate still stronger safety commitments.
Instead, Anthropic’s self-governance measure collapsed under competitive pressure. As the company’s Chief Science Officer explained: “We didn’t really feel, with the rapid advance of AI, that it made sense for us to make unilateral commitments … if competitors are blazing ahead.” (China!)

Eliezer Yudkowsky@allTheYud
So far as I can currently recall, every single time an AI company promises that they'll do an expensive safe thing later, they renege as soon as the bill comes due.

Max Tegmark @tegmark
Anthropic 2024: You can trust that we'll keep all our safety promises Antropic 2026: Nvm
9:42 AM · Feb 25, 2026 · 16.9K Views
15 Replies · 18 Reposts · 316 Likes
Sure, in terms of resources and time, safety is expensive. And of course, less safety is cheaper and faster. But it was this same logic that drove the Wuhan Institute of Virology to conduct chimeric coronavirus research at biosafety level 2 (BSL-2), described by one microbiologist as “the biosafety level of a standard US dentist’s office.” And that choice was the result of mere academic career incentives.
How reliable could self-governance ever be if the foxes are taking home million-dollar paychecks for guarding the hens?
When the cozy relationship of self-governance by experts/for experts breaks down, the GoF and AI enterprises respond in the same way: by suppressing dissent.
Soon after the pandemic started, the GoF community mobilized in lock-step to suppress inquiry into its potential culpability. Before any forensic investigation had been conducted, top scientists convened private meetings to protect their own by advancing an ad-hoc theory: the virus emerged from “natural” zoonotic transmission through an intermediary—maybe a pangolin. The lab-leak hypothesis was quickly framed as “conspiracy theory” and forced outside the bounds of legitimate scientific discourse. This aura of scientific consensus marginalized dissent for years.
By contrast, in the AI industry, a division of labor between capability enhancement and ethics/safety research does exist, and, at least in theory, this could fortify the enforcement of self-governance. The economic reality is, however, that AI ethicists and safety teams operate within companies whose revenue stream depends on shipping the very capabilities those teams are meant to constrain. It’s no surprise, therefore, that when the ethics/safety work conflicts with the bottom line, it loses every time.
Perhaps unsurprisingly, a Black woman was the first major example of such a loss. Timnit Gebru was fired from her post as co-leader of Google’s “Ethical AI team” back in 2020 for identifying how biases were being built into the company’s AI systems. The next year, another co-leader of the same team, Margaret Mitchell, was fired after co-authoring the famous “Stochastic Parrots” paper with Gebru and others, which argued LLMs are not, in fact, intelligent.
Since then, the dismissals and dissolutions of AI ethics and safety teams have come so fast and been so numerous one cannot help but wonder if the entire field of research was ever anything but a house of cards. Between 2024 and 2026, OpenAI disbanded not just one, or two, but three such teams, with a leader of the “Superalignment” team lamenting that “safety culture and processes have taken a backseat to shiny products.”
At present, the Ethical AI Departures tracker documents close to sixty researchers and executives who have either quit or been fired from major AI labs over ethics and safety concerns. “Safety Deprioritization” and “Team Dissolution” by the industry are the two most cited reasons, with “Inadequate Oversight” a close fourth. Whereas the virology community suppressed biosafety dissent through orchestrated letters in high-profile journals and behind-the-scenes meetings with top government officials, the AI industry typically utilizes the ordinary institutional mechanisms available to corporations—namely, firing—to systematically weed out the ethically-aligned and safety-conscious.[3] That is, anyone who would stand in the way of AI capability enhancement.
The results of all this are predictable: AI capabilities are outrunning the safety infrastructure.
I won’t get into the details of the COVID-19 case here (check out the previous post for that), but suffice to say, lab leaks happen far more often than most people realize.
Over a decade ago, researchers calculated that over a multi-year timeline, accidental release or researcher infection of a potential pandemic pathogen is a statistically predictable event—not an anomaly. In other words, it’s only a matter of time. Worse, this is unlikely to change because the main cause—human error—is inevitable, even in the lab. Furthermore, the situation is exacerbated by the lack of a centralized, mandatory, internationally maintained database of such events, which obscures their actual frequency.
Leak this post to your friends by clicking here:
Human error is no less inevitable in AI, where major leaks recently grabbed headlines worldwide. First, in March, the entire code base for Claude Code—the popular extension for Anthropic’s Claude chatbot that gives it control over your local machine—was leaked. Within hours, it had been copied across the internet tens of thousands of times, ensuring it could never be taken down by legal means. By the next day, the entire had been “clean-room” re-written in Python, making it not only easier to modify for those so inclined, but legal to own and use.
The leak also contained an “Easter egg”: documentation of an as-yet unreleased model, “Mythos,” that was described as the first of “an upcoming wave of models that can exploit vulnerabilities in ways that far outpace the efforts of defenders.” In other words, AI capability enhancement is entering “super-hacker” territory. If realized, the capacity to penetrate any system not hardened against it would make extant cybersecurity essentially obsolete.
Second, in early April, Mythos was announced—but not released to the public. Its unprecedented ability for finding and exploiting security vulnerabilities in software meant it could be used (by terrorists!?) to launch devastating cyberattacks. Deeming it “too dangerous” for a general release, Anthropic said it would only offer access to about 40 corporate partners via a consortium. As a demonstration of its dedication to safety and responsibility after the embarrassing Claude Code leak, Anthropic would allow these consortium members—Microsoft, NVIDIA, JP Morgan, Apple, the usual suspects—would use the model to patch up their own systems before the eventual public release.
But Anthropic apparently failed to use Mythos to harden its own defenses, because on the very day it was publicly announced, the model was accessed by a group of hackers. Weeks later, Fortune reported that while the group “has not been using the model for cyberattacks, it has been using the program continuously since its release and still has access.” Cybersecurity experts chimed in that if thousands of employees at several dozen large firms and a random group of hackers all have access, then China (China!) almost certainly has access. And soon, we will too, because the AI system that was “too dangerous to release” is scheduled to be released to the public—with no hint as to why that is now a safe move.[4]
Thus far, the only harm these leaks have done was to Anthropic’s bottom line and reputation. But consider that like SARS‑CoV‑2, leaked systems become part of the broader ecosystem. Existing defenses become useless. You and I, as third parties, have no choice but to adapt. And that might mean having no choice but to buy a Claude subscription from Anthropic to harden cybersecurity on…every website? Every computer network? Every software package?
It isn’t hard to imagine a scenario where the coming wave of AI super-hacker systems create dependence on a single provider—Anthopic—for safety. Forget to pay your dues one month, and your organization’s website gets penetrated, pwned, and ransomwared for millions of dollars by hackers using the model released next month. Everyone, from individuals and small businesses to national governments would subject to this new safety tax, with larger organizations on the hook for larger fees, given their larger attack surface.
Around the world, the number of BSL-4 labs, which work with dangerous pathogens at the highest level of containment, is “booming.” Having climbed from 59 to 67 labs between 2021 and 2023 in a post-COVID surge, a total of 69 BSL-4 labs are known to be in operation as of 2026, and with about 20 under construction, approximately 90 will be operational by 2030. On top of that, West Point’s Combatting Terrorism Center notes an “upward trend in high-risk research” despite “significant gaps and weaknesses globally” in biosecurity management.
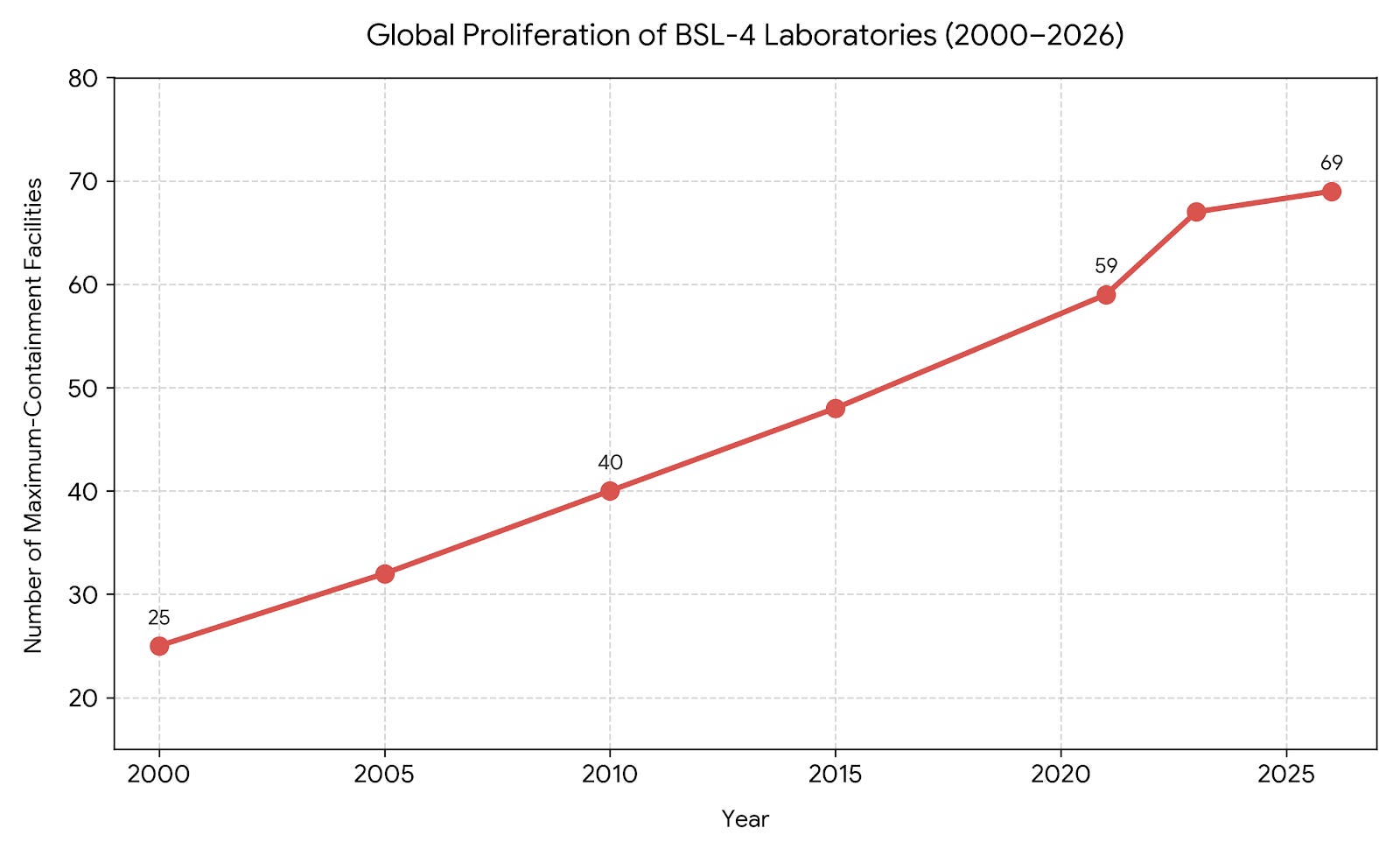
In parallel, data centers are undergoing massive, unprecedented scaling. Big corporate consultancies project that over the next four years, the current estimated global capacity of 115 GW (data centers can be measured in gigawatts of energy usage) is predicted to double to between 200 and 240 GW, driven by an anticipated spend of nearly $7 trillion on data center infrastructure by private companies.
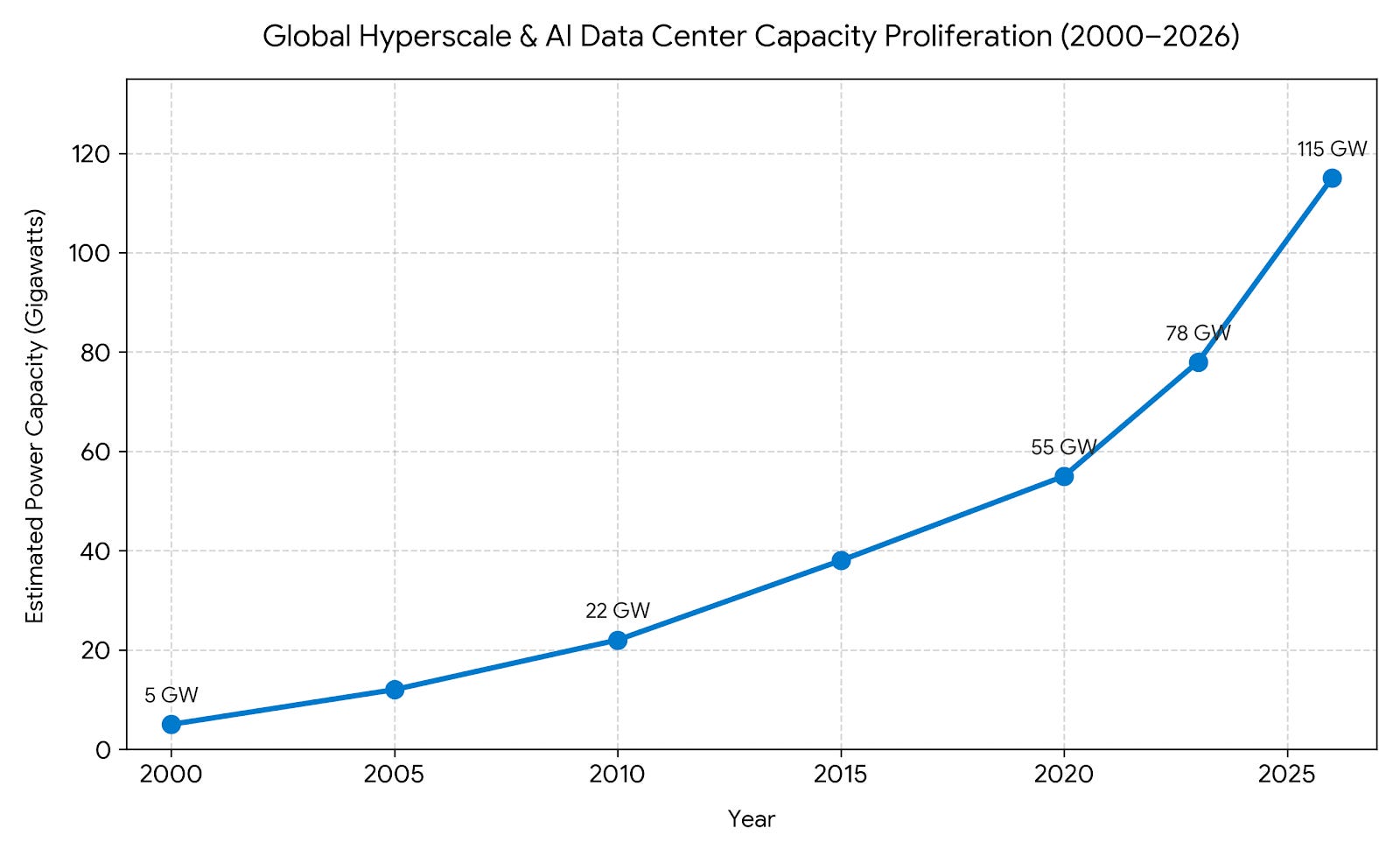
Three parallel misconceptions about both BSL-4 labs and data centers are notable.
First, proximity. You might think that BSL-4 facilities are isolated in remote deserts or military bases. In fact, over 75% of BSL-4 labs are located in densely populated urban centers. (Wuhan, China!) Similarly, massive data centers are heavily concentrated in metropolitan clusters (e.g., Northern Virginia, Atlanta, Dallas) to minimize data latency and access existing fiber-optic lines. Consequently, lab leaks are in close proximity to human transport networks, while AI leaks are in tight physical proximity to the human capital, power grids, and networks that run critical societal infrastructure.
Second, governance failure is a common feature. You might think dangerous BSL-4 labs would be highly regulated. In fact, construction has drastically outpaced international regulatory standards. The researchers behind the Global BioLabs tracking site noted that, “Only one-quarter of countries with BSL-4 labs score well on best practice indicators for biosafety and biosecurity,” and while a few countries have dual-use policies, “none have yet signed up to a new international bio-risk management standard.”

Richard H. Ebright@R_H_Ebright
"Sen. Tim Sheehy...urged Department of Health and Human Services Inspector General March Bell to immediately investigate 'safety, security, and personnel practices at RML,' a BSL-4 facility...that conducts federal research on the most dangerous pathogens"
justthenews.com
'Full coverup mode': Lawmakers want answers on 'virus smuggling' to federal lab, alleged monkey bite

6:56 PM · May 29, 2026 · 2.87K Views
6 Replies · 25 Reposts · 65 Likes
Regulation of data centers is likewise minimal. Buildouts are governed primarily by local zoning laws and grid capacity allocation, while the safety profile of the models being trained inside them plays no part. In addition to the issues with AI ethics/safety raised above, at present, no domestic or international framework regulating the hardware layer of AI training exists.
And third, size matters. You might think of a “high security biolab” as an imposing building, but roughly half of all global BSL-4 labs are remarkably compact: 200 square meters or less, not quite the size of a standard tennis court. Not only does this small footprint lower the financial barrier to entry, allowing smaller academic or localized government institutions to handle lethal pathogens, it severely complicates international verification and non-proliferation auditing.
And while the media focuses on huge “gigawatt-scale mega-clusters,” advancements in algorithmic efficiency, model quantization, and compact liquid-cooled server racks mean that not every modern data center need be massive. Today, immense cryptographic and generative AI power can now be packed into surprisingly small spaces and distributed across smaller modular data centers, significantly complicating global compute tracking.
This infrastructure “boom” of BSL-4 labs and data centers dramatically spikes the baseline probability of an accidental, catastrophic leak. Creating dozens of new physical nodes—containment doors and airlocks in labs, hyper-scale server clusters in data centers—populated by human operators prone to error, guarantees that a leak is no longer a matter of if, but when.
Practice containment failure on your own by sharing this post so it goes viral!
This all raises an important question: Why?
Defenders of GoF research claim identifying potential pandemic pathogens could help save lives. But a strong case has yet to be made, despite the widespread acceptance in the scientific community. Multiple independent, quantitative risk analyses have concluded that the costs, in terms of increased pandemic risk, outweigh the actual historical benefits.
In 2014, researchers analyzing the tradeoffs found that safer, alternative scientific methodologies exist for every stated benefit of GOF. These techniques were ostensibly employed when Moderna created its COVID-19 vaccine in just two days, without explicitly utilizing GoF research.
Moreover, a 2016 NIH-commissioned 1,000-page independent risk-benefit analysis found that any purported benefits of GoF research inevitably require a host of supporting infrastructure to be realized, including: surveillance systems,sequencing capacity, vaccine manufacturing, regulatory pathways, public-health infrastructure, and international information sharing. These nontrivial “barriers to realization” mean that all potential benefits of GoF research are uncertain. The risks, however, are very real. As MIT professor Esvelt, quoted above, told Congress:
Even if identifying a pandemic-capable virus in nature allowed us to perfectly prevent that virus from causing a natural pandemic, and we could do so with zero risk of accidents, we should expect terrorists to use the same virus to kill a hundred times as many Americans as would be saved.
An inverted parallel holds for AI.
In your hands or mine, AI may be fun, convenient, and useful. But the benefits we enjoy will never come close to the world-changing powers the same systems grant political and economic elites, who will use them to make decisions of global consequence.
Moreover, We don’t need to deny the real, though middling, benefits AI provides to us ordinary users to simultaneously acknowledge the multifarious risks it poses to society as a whole: undermining democracy, accelerating the murder of civilians in war zones, wiping out jobs, proliferating scams to rob the elderly, cratering teens’ mental health and making homework obsolete, inducing psychosis, and of course, causing human extinction, as many prominent AI researchers regularly warn us about.
And now, as a father of a toddler, I’ve been made keenly aware of a fresh risk: the bevy of AI-powered kid’s toys now being brought to market, entirely unregulated.
It is hard not to conclude that something significant needs to change, and soon.
So, what is going on with the hyped-up fearmongering around AI-generated bioweapons? And with the safety theatre being performed around them?
Simply put, it’s a distraction from the truly catastrophic threat we face: persistent, widespread, structural governance failures combined with rapid expansion and acceleration of the GoF and AI enterprises.
Incentives that reward risky capability research over safety, voluntary self-governance by self-interested parties, suppression of dissent, and the relentless drive to expand potentially dangerous infrastructure add up to drastically multiply the surface area for inevitable human error, while minimizing the structures available to prevent that from happening and to keep us safe once it does.
Ultimately, both GoF and AI exhibit a fundamental asymmetry: The catastrophic risks thrust upon society by an elite few—who operate in a reward system alien to most of us—vastly outweigh the uncertain, often middling benefits delivered to the public.

Without addressing these structural governance problems by building out a practicable, international, mandatory safety infrastructures and more importantly, renegotiating or outright rejecting the value now placed on capability enhancement (Innovation!) in pathogens and AI models, society will remain exposed to failures whose consequences may only become apparent after it is too late.
Leaks and this post are both free to share.
Shunryu Garvey is the head priest of Keigakuji Temple in Niigata, Japan, a former Stanford University researcher in AI governance, and the author of the forthcoming Zen and the Art of Democratic Intelligence. Subscribe to follow and support his work with Taming Complexity.
[1] Deszak, Baric, and Shi were collaborators on the now-infamous DEFUSE project, which proposed to design a novel pathogen with specific features found in SARS‑CoV‑2. As subsequent Congressional investigations revealed, when Baric learned of Shi Zhengli’s intentions to use biosafety level 2 (BSL-2) for the project, he wrote:
IN [sic] the US, these recombinant SARS CoV are studied under BSL3, not BSL2, especially important for those that are able to bind and replicate in primary human cells. In [C]hina, might be growin [sic] these viruses under bsl2 [sic]. US researchers will likely freakout.
Baric then edited their shared research proposal to indicate BSL-3 would be used on the project. That didn’t happen.
[2] With the discovery of “emergent abilities” in large-language models (LLMs), this novelty incentive has gone into overdrive. Here the simple act of using more compute to scale the model can produce the sudden, unexpected “emergence” of new capacities, like a jump from 0% to 80% accuracy on a task the model was not explicitly trained for. The 2023 “Sparks of Artificial General Intelligence” paper from Microsoft Research leaned heavily on the novelty incentive, packing 150 pages of qualitative examples of an early GPT-4 model tackling difficult tasks across mathematics, coding, vision, medicine, law, and psychology.
[3] That said, AI critics have long been derided by its advocates, and at least in the case of Timnit Gebru, corporate leadership facilitated a public harassment campaign that lasted for months.
[4] It’s worth noting that shortly after the Mythos announcement, OpenAI released an equivalently powerful/dangerous model, ChatGPT 5.5, with no warnings attached, leading many to speculate the “too dangerous” label was a clever marketing ploy.
Du, Shaoqing, Xueping Hu, Ping Li, et al. “Antiviral Drug Discovery and Development: Challenges and Future Directions.” Signal Transduction and Targeted Therapy 11, no. 1 (2026): 69. https://doi.org/10.1038/s41392-025-02539-7.
Puhl, Ana C., Thomas R. Lane, Fabio Urbina, and Sean Ekins. “The Need for Speed and Efficiency: A Brief Review of Small Molecule Antivirals for COVID-19.” Frontiers in Drug Discovery 2 (March 2022). https://doi.org/10.3389/fddsv.2022.837587.
Ward, Derek J., Edward Hammond, Luan Linden-Phillips, and Andrew J. Stevens. “Trends in Clinical Development Timeframes for Antiviral Drugs Launched in the UK, 1981–2014: A Retrospective Observational Study.” Pharmacology and Therapeutics. BMJ Open 5, no. 11 (2015): e009333. https://doi.org/10.1136/bmjopen-2015-009333.