
This blog post is about my process and learnings in using agentic coding to ship a project with higher complexity than your usual vibe-coded todo app. You can download the app on iOS/iPad/macOS here: Subjective.
/The Liquid (Gl)ass Prototype/
In my never-ending list of project ideas, there was this VFX Editor thing I wanted to build for a while. I previously got some exposure to building node editors in past lives but never had the creative freedom to build my own from scratch.
Like any new project idea, it starts with a prototype trying to work through existing frustrations. My guiding concepts were the following:
Being an Apple guy, I also noticed that most of the 3D/VFX tools are Windows-first and the Mac/iPhone ports were more of an afterthought. What if I designed a VFX node editor dedicated to Apple platforms, trying to surface the strengths and built-in frameworks of each platform? And what if Liquid Glass could actually be my solution to a sleek UI that would nicely complement the viewport rendering?
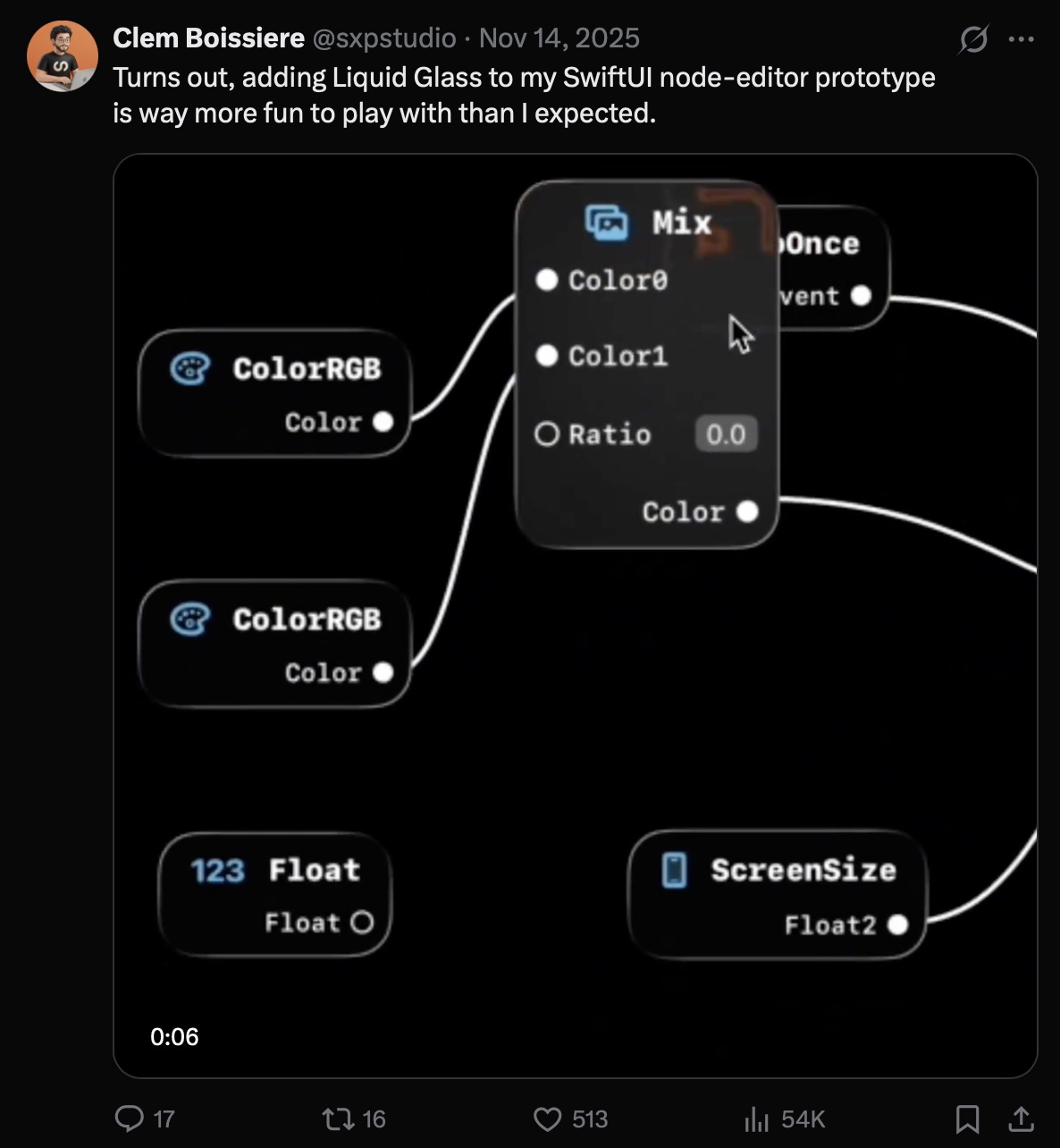
A couple of days and some handwritten SwiftUI later, a video of the original prototype got some traction on social media. This gave me some positive signal to actually start spending more time building the real thing.
/Once Upon a Time, AI Stopped Sucking as Much/
Around the same time, November 2025 was when I first used . After months and months of being repeatedly disappointed by AI tools, this was finally a big step forward and it prompted (ah) me to finally try agentic coding as a potentially viable development tool for my solo company.
I'm a seasoned software engineer (now rebranded ), so it was essential for me to evaluate agentic coding with a simple framework:
This framework helped me validate the following hypothesis:
Putting two and two together, I figured this node editor project idea, combined with the foundation of my other creation tool would be a good candidate for getting started on a production project done with agentic coding.

/Taming the Stochastic Token Machine/
Disclaimer: I have to be honest, I hesitated to write this blog post because agentic coding workflows just move and some of my tips & tricks became irrelevant or could become so in a short timeframe (days to months). Some of the workflows are also somewhat specific to Claude Code, but I strongly believe they could be applicable broadly.
With this in mind, I compiled a list of main tips & tricks that I still use daily and hopefully they bring some insight.
Unsurprisingly, a lot of them resemble what one would find in 'engineering best practices' playbooks, but with a lot of the boring & tedious aspects happily executed by agents.
Agents are not magic. You need to carefully craft prompts that will fill their context window with clear & concise details on their task and all relevant information to perform said task. Doing so will result in agents that are statistically more likely to generate relevant output (this is essential for the attention mechanism to work as expected).
The most reliable workflow to kick off a new task is 5 simple steps. It's actually pretty straightforward:
1. Enter plan mode, describe the problem specifications in detail
2. Iterate on the plan to refine it
3. Execute the plan
4. Test
5. Review
The most important part is the first two steps. You have to assume that an agent will basically start from close to zero. New sessions mean cleared context, and therefore the agent has no idea of what was achieved in previous sessions . As such, we need to fill the agent's context window with clear/unambiguous instructions on what we are trying to do, try our best to disclose known constraints and limitations, potential blind spots that need further investigation, and of course any technical aspect that you'd like it to follow (architecture, API, frameworks, methodology etc.).
Agents will try their best to fill gaps in their knowledge through codebase exploration, web queries and model assumptions. Said assumptions can sometimes quickly go into what I'd qualify as confidently incorrect (which is hard to evaluate subjectively if it's not your area of expertise).
The size of the problem you're trying to tackle should ideally be small enough so that the agent context window remains small and within limits (Opus 4.5 started with only 200K and it eventually went up starting 4.6, now at an impressive 1M context window).
Keeping the active context small reduces inference cost (less tokens being submitted on each pass).
Keeping it within limits is also fundamental because once you cross the token limit, you are gonna need to compress information, which inevitably results in information getting lost. After enough loops, important details eventually disappear, or worse, mutate into ambiguity/inaccuracies.

In addition to a clear prompt, another useful trick I've used was to create agent profiles and treat them as 'scoped workers'. I created different agent profiles for different types of work: UI work, rendering, audio, compiler, tests, UX writer, refactoring, website, and so on.
And because I wanted to make things a little bit more fun and... human? I gave them silly names that also acted as mnemonics. The names would also show up in the commit logs so I could quickly identify which agent(s) worked on a given piece of code.
My CLAUDE.md (auto-loaded into the agent context window on startup) has instructions to automatically route the proper agent profile as such:
[...]
## Agent Onboarding
Agents are native subagents defined in `.claude/agents/`. They auto-route based on task description, or can be invoked explicitly with `claude --agent <name>`.
**Agent specialists** (profiles in `.claude/agents/`):
- FORGE: Engine, rendering, shaders, nodes
- TAYLOR: UI, SwiftUI, editor features
- PIXEL: Sample graphs, VFX content
- TURBO: Performance, profiling
- TIDY: Refactoring without behavior changes
- BISON: Compiler, type inference
- LINK: Streaming, networking
- TENSOR: ML, CoreML, Vision
- SONIC: Audio analysis, Apple audio frameworks
- WEB: Website, documentation site
- SCRIBE: User documentation, tutorials
- NEO: Project docs, coordination
- ADAM: UX expert, first-principles design
- AXEL: Accessibility, VoiceOver, ax-bot compatibility
[...]
This allowed me to quickly spawn an agent (including hybrids) with natural language:
Hey FORGE, can you investigate why the default blob texture in the particle generator is not used when adding a new node as is?
One agent profile ended up being much more important than I expected: .
Its job was deliberately boring: refactor without changing behavior. Rename unclear variables, remove dead code, simplify nested conditionals, extract long functions, apply Swift idioms, and report suspicious code instead of "fixing" it.
This became essential because agentic coding can compound architectural mess very quickly. A human engineer can look at a weird abstraction and think "hmm, something is off here". An agent will often just accept the local shape of the codebase as truth and continue extending it in the same direction. Or worse, it will work around the limitations with hacks and one-off approaches (aka code smell).
So every few commits, I would run a cleanup pass the same way a real engineering team might do opportunistic refactoring after a feature lands. No new features, no clever rewrites, no surprise behavior changes.

Continuing with engineering best practices, I also started treating codebase documentation as part of the diff.
Every time a major module was built or modified, or when some specification changed, the relevant docs had to be updated too. Not as a nice-to-have, but as part of keeping the project operable.
This was useful for me, obviously, but it was even more useful for agents. Context windows are temporary. The repo is
not. Good internal docs let future agents rehydrate the important parts of the architecture without depending on whatever
happened to survive context compression.
To minimize context window inflation, my CLAUDE.md bundled a short glossary of all the documentation and their relative paths.
This allowed a given agent to dig deeper as needed without auto-injecting all the docs.
In practice, this meant docs for rendering, node authoring, compiler behavior, testing workflows, release steps, and agent-specific rules.
The goal here is relatively simple: .
This is one of the most fundamental differences when it comes to how you should prioritize what to build in your project. If you've ever done any sort of software (automation) testing, the principles are the same but this time it's no longer an afterthought nobody wants to do, it's something you must build if you want to drastically improve and overall .
There are multiple ways to tackle this:
A note on visually intensive apps (like Subjective). Though it felt essential to feed screenshots to the agent, one must remember that image tokens are much more expensive than text. In practice, the screenshots will drastically help with agent correctness, but your token budget will also drastically suffer. One possible mitigation is model routing for cheaper inference dedicated to screenshot description (I did not have time to experiment with this yet).
If you read the latest on agentic coding, you'll often find people mentioning that humans are becoming the bottleneck and agents should be running as autonomously as possible (ideally a billion in parallel so you can effectively tokenmaxxxing).
I honestly think we might get there for some subset of problems, but this approach just breaks down for anything requiring subjectively good user interaction and visual results.
Relatively quickly, it became clear that multiple agents working on the same branch was a terrible idea.
They would overwrite each other's work, "fix" files another agent had just changed, or accidentally delete entire features while resolving conflicts. This got especially bad when agents were running in parallel.
At the time, git worktree was not built into Claude Code, so I made my own script to automate the whole thing. Important caveat: I had to spawn the agent instance inside the worktree directory, otherwise context clearing or compression would occasionally make the agent "forget" where it was supposed to be operating (and usually do half the changes in the worktree and the other half in the original spawn location, usually main).
Nowadays most coding harnesses have some version of this built in, but I still recommend making it explicit in your prompt.
Hey TURBO, if the emission rate in a particle emitter node is higher than 2 million, the app crashes. You can use the default particle sample and iterate from there in order to find the root cause. Create a new git worktree for this task.
For some reason, agents can sometimes go lazy. This shows up in responses with things like "let's do this in v2!" or "to simplify the problem, I'll just do this for now". The reasons behind this are a bit unclear to me but apparently some people speculate it could be a phenomenon called "context window size anxiety" or perhaps just the training data.
While the git worktree thing solved one class of problem, the occasional agent "laziness" caused a subtle but drastic issue where agents would occasionally merge their changes too aggressively.
I've had agents merge their changes at all cost, keep their own version of a conflict, discard peer work, or silently regress a feature that had landed nearby. From the agent's point of view, the merge was "done". From my point of view, the app was now haunted by a bug that was already fixed.
My approach to this was to add an explicit merge skill that focuses on bringing as much context as possible and applying extreme caution in the process. Before resolving conflicts, the agent gets recent git history, branch intent, reviews changed files and context about nearby work. The goal is to make merging feel like an actual task that needs to be planned and not just a one-off git command.
In the same spirit of improving agent correctness, I found that spawning subagents to review the work of the main agent was overall beneficial, but still required human review to pick the right next steps post-review.
Since we're dealing with randomness in how agents generate output, using multiple agents to review a task comes down to spending more tokens in return for increasing the odds to find a somewhat more exhaustive list of potential tradeoffs, issues, variants, etc.
Just as I (the human) would almost always stay in the loop to refine, execute and review a given plan, it's also fundamental to not blindly trust the main agent to systematically pick the consensus coming out of an agentic peer review.
Agentic systems work best when your codebase and system architecture are sound and healthy. The moment technical debt and bad decisions start to pile up, you enter this vicious cycle where agents will start steering your project further in that direction. Usually through workarounds on the bad design, one-off fixes and 'hacks' or complete misunderstanding of a component/system as it becomes more and more inconsistent with its original purpose. And this obviously gets amplified by having multiple agents that will now suffer from .

Subjective is a tool for visual artists, so it's necessary to write decent docs so people understand what the heck they are supposed to do with it.
My agentic workflow had this nice multi-step process where adding a new node type (say, adding a built-in post-processing effect like Bloom) would automatically trigger the addition of a new entry in the documentation, including generating a trivial sample project that would show the new node in action and generate the corresponding preview image of the graph.
This was actually super powerful and ensured my public-facing docs were always up to date, regardless of what I would change in the source code. I could also quickly visually inspect how a node would look like from the user PoV and - more often than not - would give me immediate feedback on whether the UX writing (or even the node itself) had some blatant issue.
/The Final Product/

Subjective ended up shipping on iPhone/iPad and Mac. It comprises a node library of ~170 nodes that spans 15 categories (Math, Effects, Instancing, Rendering, Particles, Geometry, Video, Audio, AI, etc.)
Some feature highlights:
It also includes 47 bundled samples to learn by example with curated sample projects spanning particles, noise, gradients, 3D scenes, post-processing, and more.
The original app had even more features, including local network discovery and data streaming (it actually works, but wasn't shipped in v1 due to some quirks).
This is another silly aspect of agentic coding: the feeling that one-more-feature / one-more-bug-fix is just another agent spawn session away. Scope creep is real and very tempting, but doing so will result in you not shipping anything.
Final statistics (lines of code are not my favorite metric but people frequently ask about it so here goes):
Notes:
/Closing Thoughts/
Building Subjective with agentic coding was a lot of fun... but also its own set of frustrations and pitfalls to work through. Overall agentic coding was a net improvement for my one-person company and I plan on continuing to use agentic workflows with a budget of $200/month.
Even with an increased velocity in shipping features and iterating on UI/UX, you will not escape the usual pitfalls of software engineering:
I would also like to point out concerns as the main AI providers have started to increase the cost of their plans (including through 'tokenflation' like Opus 4.7 consuming ~7x more tokens on inference than its predecessor), risking pricing out more and more people in the process.
The solution to this is probably local open-weight model inference coupled with smart routing to offload cost on cheaper models when possible, which is going to be an area of investment for me later this year.
As I was building Subjective, my social media bubble made me realize that, over time, everyone and their dog was now making shader editors. This is obviously not isolated to shader editors, but just an N+1 data point reflecting how vibe coding has brought a massive shift in the app development ecosystem.
This made me reflect on what Subjective should be in this new context. I still see a lot of value in it: it has been a great learning experience, and I personally enjoy using it as a small hobby app on my iPhone to make quick visuals. At the same time, I do not expect it to replace professional tools like TouchDesigner or compete with their broader ecosystems. My hope is simpler: that people can enjoy it, learn from it, and use it as a lightweight way to explore visual ideas.
With this in mind, this app is not going away and your feedback is absolutely welcome on Discord! Next my main focus is going to be on further exploring agentic workflows and how they could tie more closely with creative coding and VFX.
If you enjoyed the app or this post, the best way to support my work is to try my apps, share them around, or grab one of the optional in-app purchases :-)