Physicists spent the better part of the last century proving there is no universal “now”. Two events that look simultaneous to you might happen in a completely different order to someone moving past you. Neither of you is wrong. This is traditionally known as “relativity” to us non-physicists out here in the world: time is relative.
Most of the time, as software engineers, we don’t even care that it exists. Relativity rarely interacts with our personal life (unless you have kids, then you’re constantly trying to guess the truth), so we think it doesn’t interact with our software either.
I’m here to tell you … you’re wrong. It probably does if you have a single machine, and it absolutely does if you have more than one machine.
Computers operate at a timescale most humans cannot comprehend. The average compiled “if-statement” executes in nanoseconds — if that. Most computers in a network are separated by a distance of nanoseconds in the same rack (by distance, I mean wire-distance), microseconds between racks, and milliseconds across continents or oceans. We call this “lag” as if there is something you can do about it.
This is just a signal — electricity or light — moving at the speed of light through its medium (at some speed less than c).
Your computer can have likely done dozens, if not hundreds or thousands of operations in the time it takes a signal to arrive at a “distant” location … and it hasn’t even responded yet.
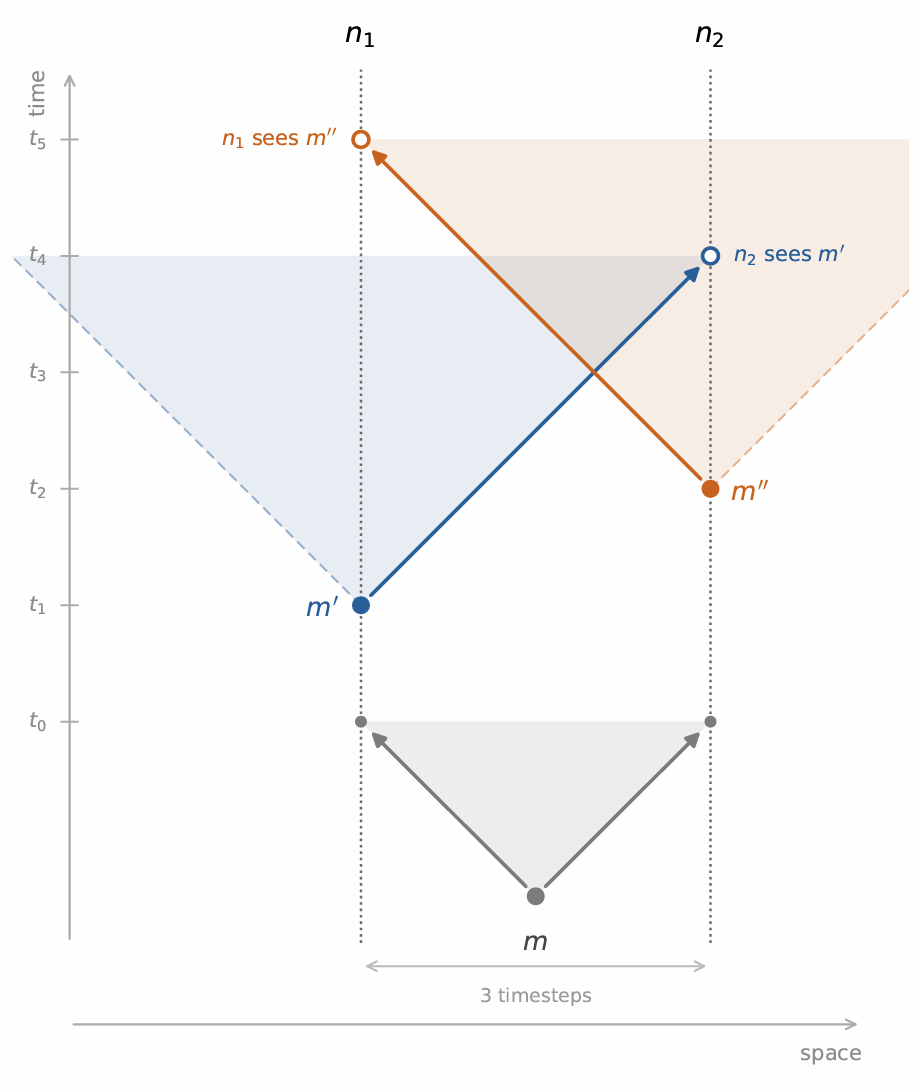
This means both machines could have received the same signal, reacted to it, and broadcast a message to each other before they even know they’re competing on the same signal.
To solve this problem gets to the very heart of consistency.
Kaben Kramer and I just submitted a paper to DISC, formalizing a paper by Mark Burgess and András Gerlits. Mark suggested I write a blog post for people who don’t get excited about papers — so here’s the blog post that explains the whole paper. No complex math theory required: just plain engineering.
If you build a system, almost any system, you probably pass messages in that system — to the kernel when you open a file, read the clock, allocate memory, etc. Today, we’re not going to get into that level of detail, even though LCC applies there too, but let’s focus on the interesting stuff: distributed systems.
Light Cone Consistency asserts that every message-passing system, from the post office to conversations you have with friends to the CPU cache to distributed systems builds an implicit causal system: if you draw an arrow between cause and effect over time, you get a graph. This graph is acyclic — because you can’t go back in time — and only grows forward. Essentially, a graph of “this, because that”.
Every machine in this system only sees part of that graph. It sees what messages have reached it, and nothing more. Everything it knows, it knows from those messages.
When two messages become concurrent (such as the image above — messages m’ and m’’ cannot causally relate to each other since the light cones didn’t overlap), you end up with a “fork” in the graph. In this model, concurrency is geometry.
If forks in the graph are unavoidable, consistency comes down to two decisions about how you handle them.
First: before you can act on a message, what else do you insist you’ve already seen? Nothing? Just other writes to the same object? Other writes in this session? Or the whole causal history behind it? We call this Causal Closure.
Second: when you hit a fork (two concurrent writes with no natural order), do you enforce an order anyway and how far do you go to enforce it? Order nothing? Order writes to the same object? Order everything? We call this Fork Resolution.
With these two dials, plus a couple of implementation details (what you report to the user based on what you’ve seen and how long you’re willing to wait to do so) … you can describe everything from serializable consistency all the way to eventual consistency.
This also allowed us to generate consistency models that nobody has actually named yet.
The two dials look independent. And they are, unless you want to do something useful, like to use it to store data beyond just a log of data.
Once you enable that constraint, you want your ordering to respect causality: what we call “refining causality”. And to do that, it means you have to hold on to that causality which costs memory because you cannot refine information you don’t have.
Put plainly: a system that orders causality honestly is, for free, a system that remembers its causes.
The consequence of this is somewhat obvious: to resolve whether A comes before B, you have to keep the history that tells A and B apart. If you throw it out, no algorithm can tell you the order. In database systems, these are usually called a WAL (write-ahead log). It allows a database to order writes before they become part of the causal history.
But consistency gets weird: there’s a hierarchy. If your application refines causality correctly, many consistency models actually collapse into one.
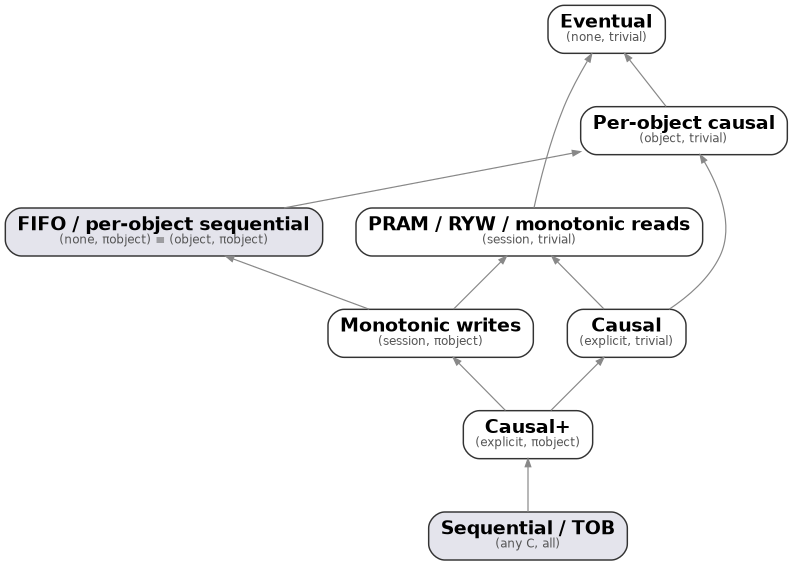
This hierarchy is determined by what can be successfully read from another consistency level without losing provenance. For example, eventual consistency can read from literally any other system, but a sequential system reading from an eventually consistent store loses all the guarantees it actually promises.
Every engineer eventually learns that if you have an eventually consistent cache over your strongly consistent data store … you’ll get these random impossible bugs (customer carts coming back after payment, profile photos not changing after updating). Why? Because your application can only guarantee its weakest consistency level. This is the whole reason cache eviction is such a hard problem. You have to engineer a strong consistency level on a weak one. This is real engineering.
And if your system doesn’t refine causality? Those grey boxes above explode…
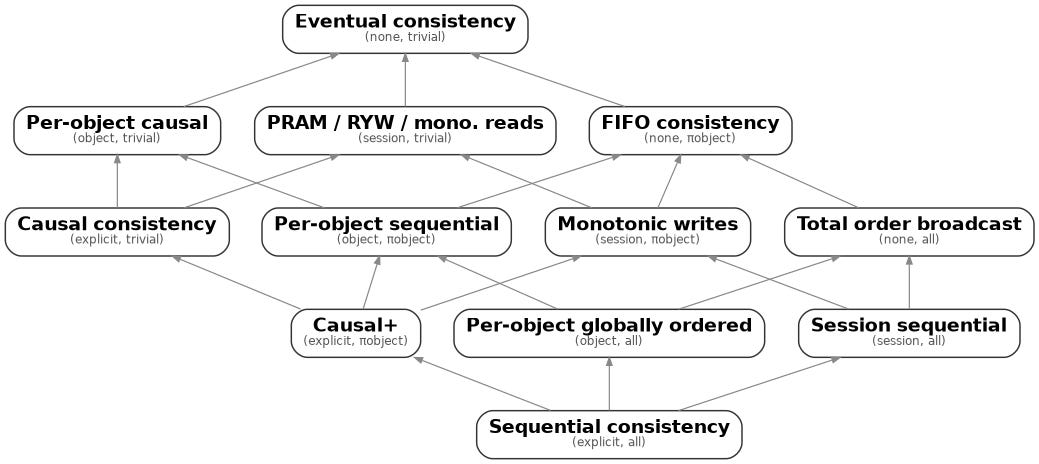
Suddenly … you end up with a much more complex hierarchy. So, if your data store isn’t properly refining causality for any reason (clock skew, seams between causally unrelated data, etc.) … you can end up mixing session consistency in your cache but sequential consistency in your database. Again, this is why cache invalidation is such a hard problem.
And it gets worse.
If you implement this incorrectly … the damage is permanent. We all intuitively know this. That cart that comes back after a customer pays … that might be benign unless they pay for it again. Or a profile photo that doesn’t update after the user updates it. It leaves a causal scar over the data and causality itself. It can never be corrected except through the same mechanism you’d need to prevent it in the first place: being causally honest and recording the causal data in the first place.
Linearizability is usually described as the “holy grail” of distributed systems. The strongest consistency level any system can reach.
But the paper shows it’s not just one system. It can’t be. It must be at least two systems. One system is required to hold your data. That part is obvious. But linearizability also demands a single global order that “returns-before”, respecting real-time. In other words, if A finished writing before B started, A comes first; even if the two never causally interact. That order is not something that can be produced from a single observer’s view.
A second system is required to manufacture a single global “now”: a sequencer, a leader, consensus rounds, an accurate clock, or just a mutex. It provides the current “now” across all observers. The “now” that physics cannot provide.
First of all, CAP and FLP are in there if you look close enough, we don’t claim to unify them. I want to be explicit. Personally, I believe they can be somewhat unified under this framework, but I don’t know for certain. I did spend a lot of cycles trying to do that though, and ultimately failed.
Further, this paper is formalizing a paper by Mark Burgess and András Gerlits: Continuous Integration of Data Histories into Consistent Namespaces and is implemented by our cache called Swytch — an open source cache that provides distributed serializable caching.