
Denis Yarats, Perplexity’s CTO, announced in March that they’re moving away from MCP internally. The numbers are damning: three MCP servers consumed 143,000 of 200,000 available context tokens before the agent could do any real work. Seventy-two percent of the context window gone before the model has seen a single user query.
Apideck documented it: connect GitHub, Slack, and Sentry via MCP, and tool descriptions alone eat 143K tokens. Scalekit’s benchmarks are worse: CLIs are 10-32x cheaper and hit 100% reliability against MCP’s 72%.
YC CEO Garry Tan amplified: “MCP sucks honestly.”
The 72% problem illuminates a real design choice. MCP doesn’t just tell the model “GitHub exists.” It serialises every method, every parameter, every return type: create_issue, list_pull_requests(repo_name, status), comment_on_pr(pr_id, comment_body). And so on, for every tool on every server. All of it loaded into the model’s context window before a single request is processed. It’s like buying a kitchen where the instruction manuals take up all the counter space.
This isn’t a bug. It’s the cost of tool discovery at runtime. MCP assumes the agent doesn’t know what tools exist until it connects. It pays for that flexibility upfront, in tokens.
If your tools are static, your agent is known, and your provider is fixed, use direct integrations. If any of those three variables is dynamic, MCP’s overhead is the cost of not having to predict the future. Most internal tooling is static. Most user-facing products are dynamic. Perplexity is internal tooling dressed up as a product. Kimono is a product that has to work with whatever agent the user brings.
I need the generality.
I’m shipping MCP at Kimono, an AI-powered CRM that aggregates contacts and communications from Gmail, iCloud, Telegram, SMS, and Microsoft 365. When we ship, an AI agent gets tools to search a user’s contacts, read their email history, pull their calendar, and draft responses across every platform they’ve connected.
I don’t know which agent will connect. I don’t know which model it runs. I don’t know what jurisdiction processes the inference, or whether the user’s email about a medical appointment will end up on a training cluster in a country with no data protection law.
That’s what MCP was designed for: dynamic discovery, arbitrary clients, heterogeneous environments. Not “connect three tools to one agent” but “let any agent discover and use your tools.” The overhead Perplexity laments is the cost of that generality. For a CRM handling contact PII across five messaging platforms, the alternative is building bespoke integrations for every agent that might connect. That doesn’t scale. MCP does.
So Perplexity is right that MCP is expensive. They’re wrong that the expense is the real problem. The real problem is that the generality isn’t safe. A tool that searches public documentation costs the same context as a tool that searches private medical records. MCP treats them identically. Not just in terms of tokens. In terms of trust.
Let’s walk through what actually happens when an MCP tool call carries sensitive data.
A Kimono user connects their Gmail and Telegram. An AI agent connects via MCP and calls search_contacts('Sarah Chen'). The MCP server checks OAuth tokens. Does this agent have permission? Yes. It returns Sarah’s name, email, phone, company, and interaction history, including that she emailed about a medical appointment last Tuesday.
Auth is satisfied. Everything is technically correct.
Now the agent needs to process this. Summarise Sarah’s context before a meeting, extract action items, draft a follow-up. It serialises her contact record into a prompt and sends it to an LLM. The agent’s runtime picks the inference provider. Not the MCP server. Not Kimono. Not the user. The runtime might route to Anthropic (no data retention). Or OpenAI (30-day retention). Or a fine-tuned open-weight model running on infrastructure in any jurisdiction on earth. The MCP server authorised the data access. It has zero visibility into where that data travels next.
The data has left the building. The protocol that moved it doesn’t know, and can’t know, what was in it.
Auth answers: “Does this agent have permission to access Sarah’s contact?” Binary. Yes or no. Trust would answer: “Given what’s in Sarah’s record (specifically, that medical appointment), which inference providers are appropriate?” Trust isn’t binary. It’s contextual.
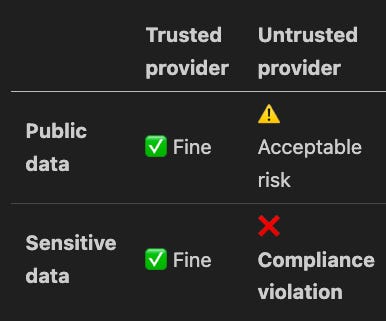
Bottom-right. Auth approves it. MCP has no mechanism to block it. Every MCP server that returns PII is implicitly trusting every connecting agent to route that data responsibly.
Security by handshake?
The fix needs three additions to the response schema and a shared registry of provider trust tiers.
Step 1: Sensitivity annotations on MCP responses. When the server returns a payload, it includes structured metadata:
{
"result": { ... },
"sensitivity": {
"level": "confidential",
"categories": ["pii", "medical"],
"regulations": ["hipaa", "gdpr"]
}
}For structured data, the server already knows what it’s returning. A contacts table has an email column; that’s PII by definition. For unstructured data like email bodies, the server needs a classification layer. The cost is latency: running a DLP scanner synchronously over a 50-message thread before the MCP server responds is a non-starter. The practical solution is to classify at ingestion, not query time. When an email arrives in Kimono’s database, tag it with sensitivity metadata immediately. By the time the MCP server builds a response, the annotations are already in the record. Query-time cost drops to a database lookup.
Step 2: A trust-tier registry. A shared, auditable mapping of inference providers to their data-handling guarantees. Anthropic: no retention, HIPAA-eligible, US jurisdiction. OpenAI: 30-day retention, SOC2 compliant. DeepSeek: Chinese jurisdiction, unverifiable retention. I’ve maintained one for Cortex for months, and NVIDIA’s OpenShell Privacy Router uses a similar concept. But a registry maintained by one startup is a political non-starter. The natural home is the Agentic AI Foundation, which already governs MCP under the Linux Foundation.
Step 3: Runtime enforcement. Before the agent sends annotated data to an inference provider, the runtime checks sensitivity metadata against the provider’s trust tier. Medical PII to a non-HIPAA provider? Block. Financial data to a provider with government access obligations? Reroute. Public data? Send it anywhere.
This metadata doesn’t worsen the 72% context problem. Sensitivity annotations are protocol-level headers consumed by the routing layer, not the model. The router reads metadata, enforces policy, and strips tags before serialising into the LLM prompt. Security without burning inference tokens.
An obvious objection: what stops an arbitrary agent from stripping the metadata and sending Sarah’s records to an untrusted model? Nothing. Metadata tags are not cryptographic bindings. Whether this is a fatal flaw depends on who controls the agent.
In a closed ecosystem (Bloomberg’s internal agents, Morgan Stanley’s trading floor), the enterprise controls the runtime. The primary threat isn’t hostile exfiltration. It’s a well-intentioned developer who picked the cheapest provider without checking jurisdiction. Metadata turns “I hope the agent routes correctly” into “the agent can verify it’s routing correctly.”
In an open ecosystem like Kimono, where any third-party agent can connect, client-side enforcement is legally insufficient. Under GDPR and HIPAA, a data custodian can’t hand clear-text medical PII to an unknown agent and hope.
For open ecosystems, you need the outer wall: a trust gateway between the MCP server and the connecting agent. Because the server cannot control a third-party agent’s outbound requests to LLMs, the gateway acts before data crosses the wire. It inspects sensitivity annotations and dynamically redacts regulated PII, or blocks the response entirely, unless the agent provides verifiable attestation of its inference routing. For closed ecosystems, metadata enables compliant routing. For open ones, metadata enables server-side zero-trust data release. Either way, the metadata has to exist. Today, in MCP, it doesn’t.
This matters beyond Kimono. Bloomberg’s agents touch data subject to SEC and FINRA regulations. Routing client portfolio data to the wrong provider isn’t a privacy nuisance; it’s a compliance violation that triggers mandatory disclosure. Healthcare AI under HIPAA can’t send patient data without a Business Associate Agreement, regardless of how the agent authenticated. The EU AI Act’s high-risk provisions take effect on August 2, 2026, four months from now, and explicitly require documented data governance for AI systems processing personal data.
Every one of these regulatory frameworks assumes someone knows what’s in the data and where it’s going. MCP’s current design makes that assumption false.
Three fields in a spec extension and a lookup table. Not a moonshot. Plumbing.
While writing the last essay in this series, I sent it to GPT for editorial feedback and my own content classifier blocked the request. It detected the word “surgery” and classified the entire essay as confidential medical data. While writing this essay, I tried to send it to GPT for structural editing, and the trust-tier system blocked it again. The essay about the trust gap was flagged as too sensitive. Both were false positives. OpenAI’s paid API doesn’t train on customer data; their 30-day retention for abuse monitoring is a reasonable trade-off. The classifier was wrong.

I’d rather debug false positives than ship without classification. A system that over-blocks is annoying. A system with no content awareness, which is MCP’s current state, means every tool call is a handshake agreement. My classifier was wrong twice. MCP doesn’t ask.
While backend MCP debates auth and overhead, WebMCP (a joint Chrome and Edge initiative at the W3C) is approaching the same problem from the opposite direction. Websites declare structured tools directly in the browser via navigator.modelContext. Tools are ephemeral, inherit same-origin security, and reuse session cookies. No OAuth needed. The browser is the identity provider.
The performance numbers are striking: 6x faster than screenshot-based agent interaction, 97.9% success rate, 89% more token-efficient. Alex Nahas at Amazon built the precursor (MCP-B) to solve a real problem: thousands of internal services with separate auth, none speaking OAuth. His insight was that the browser is already the identity provider. Why rebuild it?
But WebMCP has the same trust gap. Nahas calls it the “Lethal Trifecta”: an agent combining a user’s prompt, a banking tab, and a malicious tab treats all three as equally trusted. The browser’s Same-Origin Policy isolates where data comes from, but has no vocabulary for what the data is. SOP prevents cross-site scripting, not content classification. “Allow this agent to access banking tools” is an auth question, not a trust question. The protocol still can’t distinguish an agent reading a bank’s public fee schedule from extracting a user’s private account balance.
Backend MCP and browser WebMCP are converging on the same absent layer from opposite directions. The trust problem is protocol-agnostic, and it’s a missing primitive in the stack.
The MCP Dev Summit starts tomorrow in NYC. 95 sessions. 50 speakers. Six sessions on authentication. I’m watching for signals on whether the trust gap is entering the conversation.
Ania Musial from Bloomberg is keynoting: “Interoperability Isn’t Enough.” If she names the content-trust gap, it’s no longer a niche concern. It’s the enterprise blocker.
Okta’s talk is titled “From Scopes to Intent.” That word, intent, is close to content classification. Are they building trust at the identity layer?
Nick Cooper from OpenAI is keynoting “MCP x MCP” on cross-ecosystem interoperability. What happens when an Anthropic-authenticated agent routes data through OpenAI’s 30-day retention pipeline?
I’ve been building content classification and trust-tier routing for Cortex and Kimono for months. It’s imperfect (see: blocking my own essays). But it exists. In Part 2, I’ll describe what that architecture looks like applied to MCP tool calls, and what we learned from the MCP summit.
MCP has 97 million installs. 146 member organisations. A roadmap for auth, agent-to-agent coordination, a curated registry, but no roadmap for content trust. MCP won adoption. Now it needs to earn trust.
Tomorrow: Part 2 — “Auth Tells You Who. Trust Tells You What.”