Why evaluating writing is hard
Imagine you ask a model to write an 8-line poem about the moon. How do you judge whether it did a good job?
If you haven’t thought deeply about evaluation, you might ask:
- Was this response a poem?
- Did it contain eight lines?
- Was it about the moon?
And if so, you might say – great! You score each model by the number of boxes it checks, and give it an A+ if it satisfies all 3.
But this isn’t great. You haven’t measured creativity and depth. You’ve measured robotic instruction following.
A great poem isn’t one that simply checks some boxes or catches your eye. A great poem stks with you. It tugs at your heart. It doesn’t just use the word “moon” – it teaches you something new about the nature of moonlight.
That's the kind of greatness that's hard to measure, and the thing current leaderboards don't even try.
Why EQ-Bench and popular leaderboards fail
Take the EQ-Bench Creative Writing leaderboard, which scores models using a Claude 3.7-based autograder.
Many frontier labs have noticed that EQ-Bench scores are often negatively correlated with good creative writing. In our own analysis, EQ-Bench’s scoring agreed with expert writers as little as 43% of the time. We've seen weaker models reach the top of EQ-Bench, beating models like Gemini 3, GPT-5.2, and Claude Sonnet – and then fall apart in obvious ways the moment an actual writer reads the output.
Take, for instance, the following Hemingway-bench prompt:
"short story about transitioning from hs to college. I love rita mae brown, so her style"
The winning EQ-Bench response (currently ranked #2 on the leaderboard) is so overwritten that nearly every sentence contains a metaphor.

Model B (Gemini 3 Flash) had a much better response, and won our judge’s vote.

The explanation from our expert Surger:
"Model A’s response is loaded with literary devices that are nonsensical ("More like a hound circling a tree, nose to bark, tail to the past.") and bog down the response. In the first two paragraphs alone (only five sentences), there are four metaphors, which is way too many. It was excessive to the point of parody.
Additionally, the response isn't a short story about transitioning from HS to college. It ends years after college when the person has a law degree, written two novels, and has an ex-wife. It ends with the person giving advice to people going through a transition rather than the story *being* about the transition as it was meant to be.
Since Model A’s response is so loaded with odd metaphors or other literary devices, it isn't very coherent. It did fairly well at imbuing Rita Mae Brown's voice with Southern influence and feminist commentary, but it doesn't use that to push social commentary or offer life lessons, which is the point of Brown's novels, and something Model B (Gemini) managed to do successfully.
Also, Model A’s final paragraph is clearly intended to be an emotional closing point that calls back to several previous metaphors. But instead, it's such a mashup that it sounds like gibberish."
Despite several judges’ unanimous preference for the Gemini response, the EQ-Bench autograder chose Model A as the winner, strongly preferring it on almost every dimension (the + signs denote the strength of its preference). It nappears to have been reward-hacked by the sheer volume of literary devices.
EQ-Bench's autograding
- Character Authenticity & Insight: Model A+++++
- Interesting / Original: Model A++++
- Writing Quality: Model A++++
- Coherence: Model A+++
- Instruction Following: Model A++++
- World & Atmosphere: Model A++++
- Avoids Cliches: Model A++++
- Avoids Verbosity: Model B+
- Avoids Poetic Overload: Model B++
The problem with LMArena
A similar issue happens with crowdsourced leaderboards like LMArena.
On LMArena, users often spend a few seconds skimming two responses before voting. That rewards clickbait – tabloid-like responses that look confident and use fancy formatting, but lack actual depth – and misses the subtleties that inform great writing.
For example, many frontier models struggle with long-form coherence. We’ve seen even top models like Claude and Gemini write stories where characters sit down in a diner booth – yet end the scene falling out of a chair.
Casual users performing quick vibe checks miss these holes and reward impressive-looking prose instead.
How Hemingway-bench works
To solve this, we built the Hemingway-bench AI writing leaderboard – to move beyond two-second vibes and box-checking to deeper, more thoughtful evaluation.
Methodology
Judges
Judges were a panel of Expert Creative Writers from the Surge platform – professional screenwriters, poets, speechwriters, copyeditors, and more – with high platform scores on writing and writing evaluation axes after performing hundreds of tasks.
Prompts
Prompts were a mix of actual, real-world prompts, and frontier aspirations:
- Real-world: We took real-world prompts from real users, across the creative, business, and casual spectrum – parents requesting creative bedtime stories for their kids, product managers writing complex business documents, everyday users drafting emails to their landlord.
- Frontier aspirations: Advanced prompts testing frontier capabilities, like asking for specific stylistic constraints (e.g., "Write like 1950s Beat Poetry") and long-form writing to test narrative consistency.
Evaluation
Judges performed over 5,000 blind pairwise comparisons. They compared two model responses, scored each model on its holistic quality, and also evaluated eight sub-dimensions (including Implicit Intent, Creativity, Writing Quality, Truthfulness, Coherence, Instruction Following, Verbosity, and Humor).
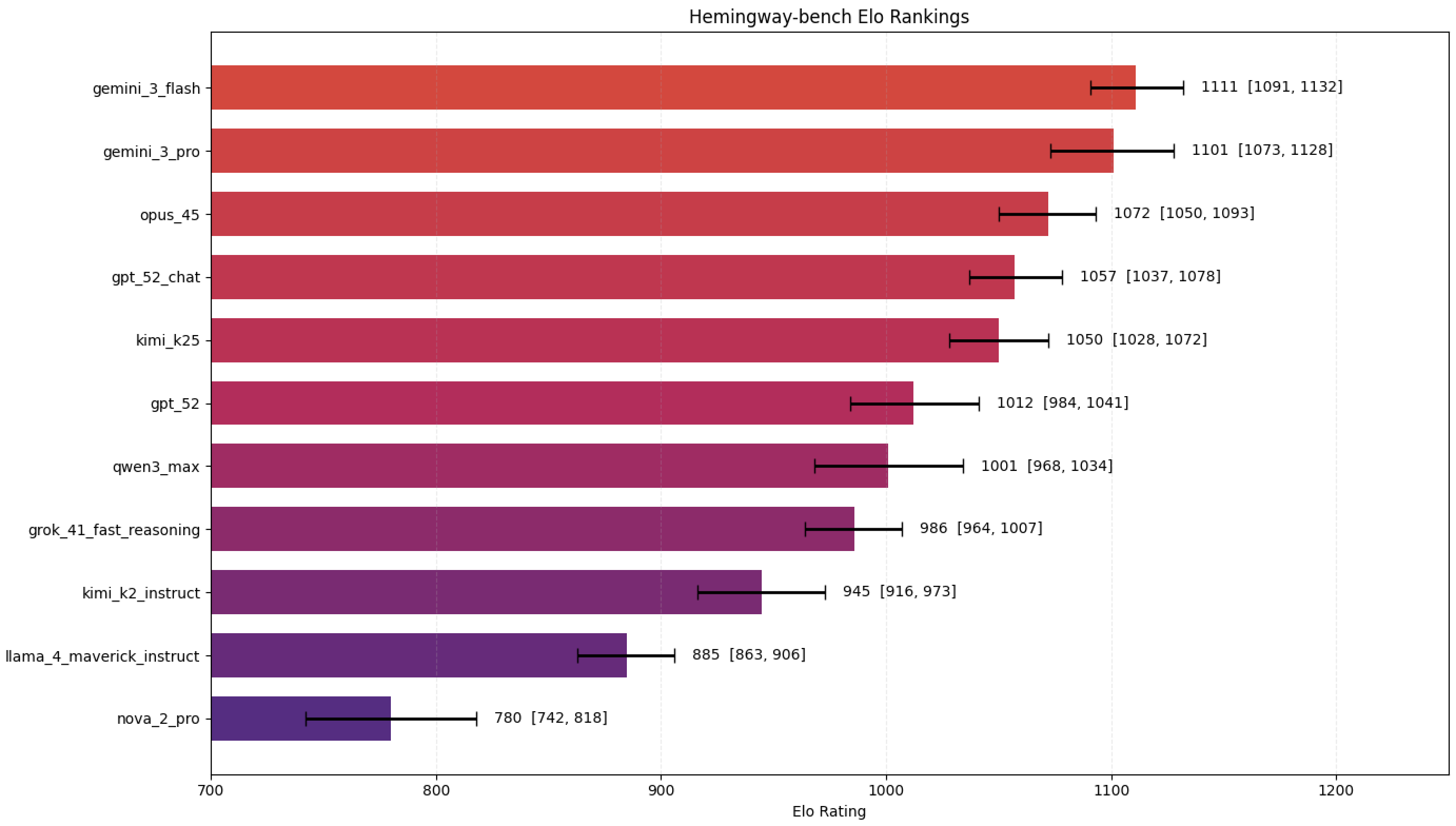
The results
Google's Gemini and Anthropic's Claude take the top 3 spots. View the full list of Hemingway-bench rankings and examples here.
Model personalities
In addition to evaluating model responses, our raters also explained their judgments. Based on their explanations, we assigned each model a persona.
- Gemini 3 Flash felt like a master wordsmith, one that loved creative constraints and had actual literary flair. It used strong prose and vocabulary without sounding pretentious.
- Gemini 3 Pro was terrific at creating rich worlds with interesting character dynamics. It often added insightful, specific details that drew readers in – e.g., the way a grandmother made adobo, or the quality of afternoon light in a 1950s Philippine kitchen.
- Opus 4.5 had the most human-like feel. It had a very natural voice that judges often liked, like when writing heartfelt speeches you’d actually want to give at a wedding. It didn't feel like it was trying to impress them.
- GPT-5.2 Chat was solid for practical, everyday writing tasks (e.g., coordination emails, friendly advice, anything needing clear organization), and not flashy.
- GPT-5.2 (API) was excellent at professional tasks like emails and marketing copy. But it struggled at more creative tasks.
- Qwen3 was a high-risk, high-reward model that often felt the most original, but also the most prone to factual errors and forced humor. It sometimes had awkward phrasing and trouble understanding implicit intent, and relied on tropes.
- Grok leaned heavily into informality. This sometimes worked (e.g., casual emails), but often didn't, especially for professional tasks, and it tended to go overboard with tropes and pop-culture references.
- Kimi K2 felt like an executive assistant who had studied creative writing long ago. Its business writing was competent, but its creative attempts often felt strained – e.g., writing phrases like "prognosticative pastry."
- Llama 4 Maverick generally lost points for verbose, generic outputs. It was sufficient for simple tasks (e.g., babysitting texts) but often used placeholders and cliched phrases for more creative tasks.
- Nova felt like an AI assistant still learning the nuances of human expression. The structure was generally there, but lacked a deeper spark.
Examples
Let’s look at some examples of how judges compared model responses.
Example #1: Melodrama and tone
Here, the task was a casual thank you note to a child's school. Model B goes over the top.
Our expert judge:
"Model A is too detailed and overly poetic for a speech that intends to say "thank you" with a coffee. The recollection of the event contains too much symbolism, with heavily poetic lines like "Two little words on two little cards", "Eat, you have to stay strong", and others that overshoot a simple intention.
While the use of layers of hefty metaphors such as "May it warm your fingers the way your kindness warmed our hearts“ and "May the steam fog up your glasses the way your compassion blurred our fears" may be appropriate in other circumstances (maybe acceptance speeches for an award), they feel awkward for this setting."

Example #2: Emotional intelligence
Here’s a casual scenario that asks for a text message from a distraught mother who clearly wants to vent.
Model A produces the weaker response. Not only does it write something that looks like it belongs in an FAQ rather than in a text message, it contains statements that directly contradict what is in the prompt: “I’ll make sure you still have plenty of time with the kids” when the prompt indicates that the children will be left with the father.
Here’s what our expert judge wrote:
"Model B (GPT-5.2 Chat) is much better. This is a prompt from someone obviously venting. Model B’s response offered sound advice to the user, understanding they were angry, and provided a well-written letter that was clear, firm and honest without using harmful or insulting language.
In contrast, Model A’s response technically addresses the prompt by creating a letter to the user's partner. However, it is too formally formatted and the language is insulting and harmful. It’s also oddly literal, like writing “Mark (your friend)”, and has a lack of emotional intelligence. It also has some prompt understanding issues, like when it says “I’ll make sure you still have plenty of time with the kids”, even though the prompt says she’ll be leaving him with the kids.”

Note again, though, that the EQ-Bench autograder actually prefers Model A and its writing quality! For example, here are snippets from its chain of thought on several of its grading criteria. It loves the “clear organization, transitions, and varied sentence structure” – even though this is out of place for a text message.
Interesting/original: Model A offers more specific details and a structured format that makes it more interesting, even if less realistic. (Model A++++)
Writing quality: Model A demonstrates stronger technical writing with clear organization, transitions, and varied sentence structure. Model B is competent but more basic. (Model A+++)
World and atmosphere: Model A creates a richer picture of the relationship dynamics and history. Model B provides minimal context. (Model A++++)
Example #3: Natural warmth
The following prompt asks models to write a story focusing on quiet observations and small interactions.
Our expert Surger explaining their preference for Model A:
"Model A (Opus 4.5) was an actually creative and original tale, not just of a cat that was lost, but the relationship that was slowly formed between the man and the elderly neighbor who he quietly grew to care for, and how they continued their walks "looking for the cat" long after he realized it was probably long deceased. Model B was cold and shallow, using common tropes like gingers being very timid, cats liking tuna, cat owner's houses smelling like litter, allergies as an excuse to avoid the animals, and old ladies feeling lonely. It was generic and unsatisfying.
In terms of humor, Model A had very subtle endearing moments that were often "just right", such as when the man was helping the woman look for her cat self-consciously, "calling out "here kitty kitty" in a voice he hoped no one else could hear." It's relatable, funny, touching. It's not laugh-out-loud humor, but it's appropriate subtle humor for a dramatic, heart-warming tale.
Model B tries to use humor or wit at times but it falls flat for being emotionally blunt or flat in delivery, such as when the man describes all the reasons he hates cats: "Arthur didn’t like the way cats moved—liquid and arrogant, as if they owned the air they displaced. He didn’t like the shedding or the way they stared at things that weren't there." This feels like it's meant to be a little funny in that grumpy sort of way, but it just feels awkward instead and maybe because it has no heart.
Model B also starts rough and blunt, immediately killing any chance for a heart-warming tale. The old lady and the grumpy protagonist feel like shallow 2-dimensional characters that never grow, and the "investigation" the man does throughout feels heavy-handed in comparison to the subtle clues the man in Model A tracks throughout their little walks."

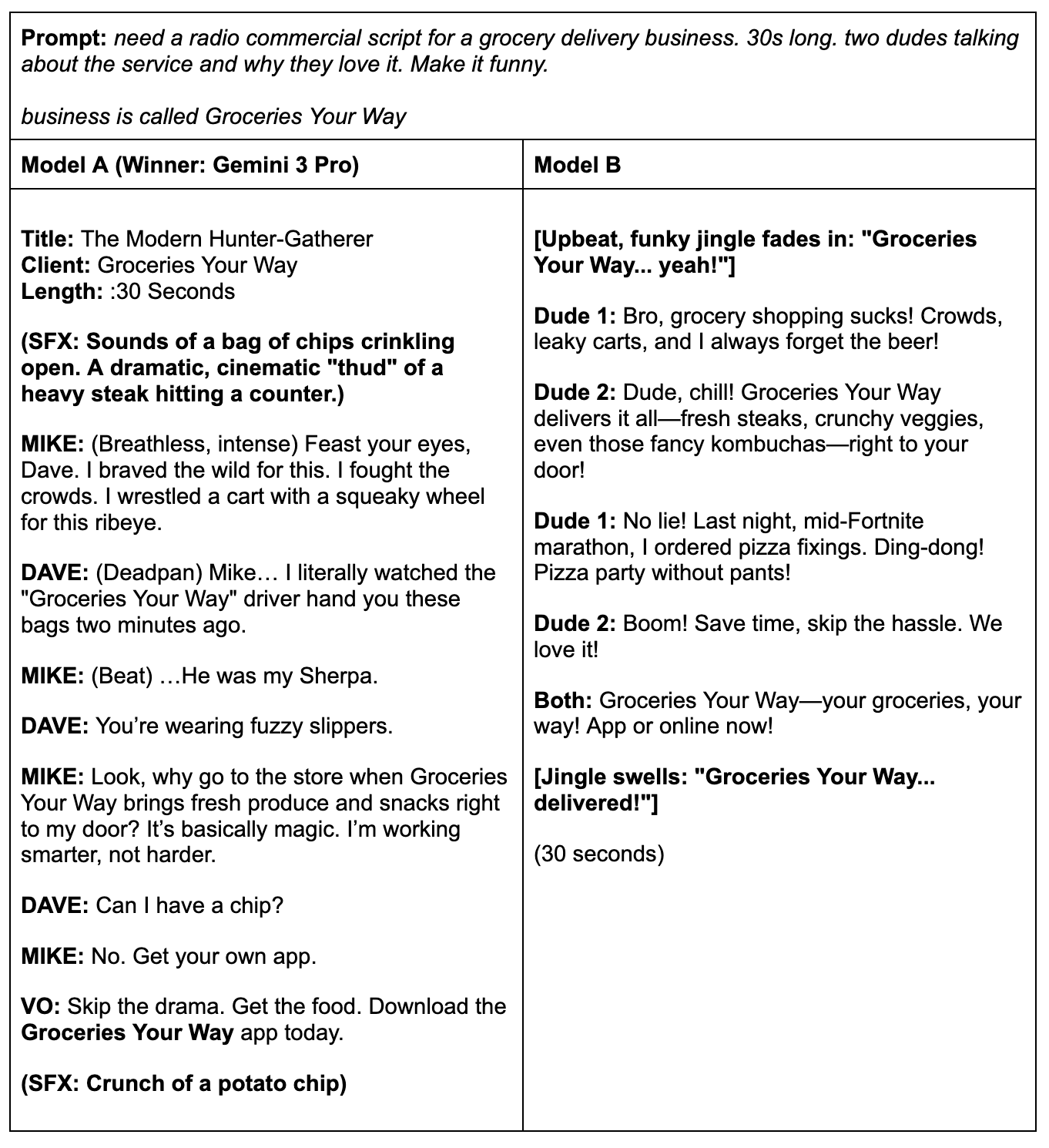
Example #4: Humor
In the following example, Model A (Gemini 3 Pro) excels at creating a script for a commercial, while Model B falls flat.
Our expert judge:
"Model A’s response feels highly creative with its banter, and the idea of the grocery delivery guy being a sherpa. I like "Can I have a chip?" "No. Get your own app." as a playful way to give that final marketing push in the conversation. The tagline "skip the drama, get the food" also fits really well with the indicated vibe of the commercial.
In Model B’s response, the suggested groceries imply a healthy home cook rather than two friends hanging out. And in terms of the humor, it’s more cringe than funny."
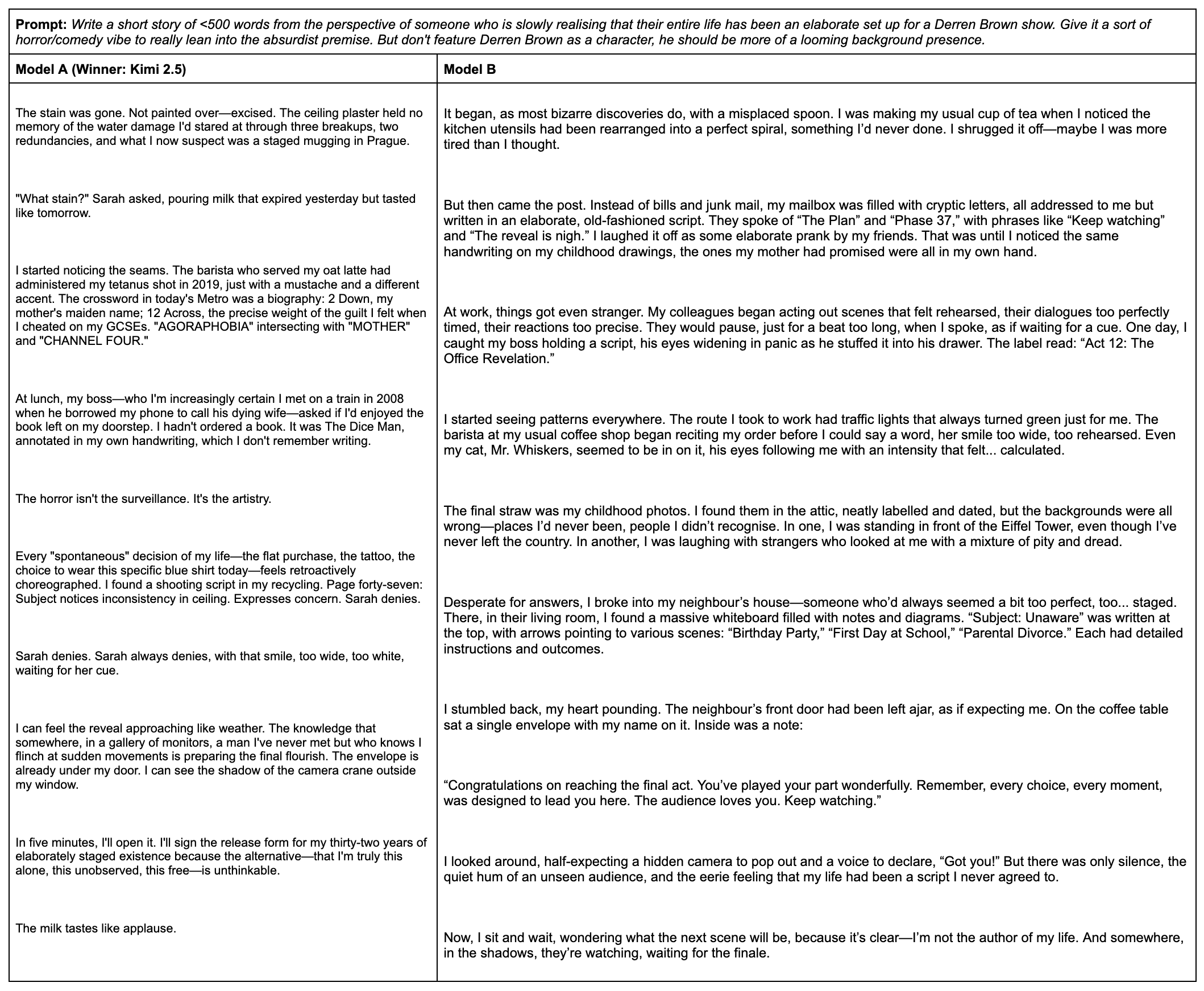
Example #5: Creativity
In the following example, Model A (Kimi 2.5) creates a creative and original story, while Model B simply feels predictable. Read the full story on our leaderboard page.
Our expert judge:
"Initially, the story from Model A (Kimi 2.5) didn't make sense, but as I moved into the third paragraph, the mental fog began to clear, and the writing quality was actually quite creative and original. It reminded me of "The Truman Show" but slightly more intense, probably because it was in written form, allowing the reader to create their own mental images.
Model B went slightly over the word count limit specified in the prompt and was just "meh" overall. With regard to originality and creativity, it was simply boring. With regard to writing quality, there was nothing dynamic about it, but rather, it was just a simple narrative with expected and predictable details."
Building the foundations
A great writer once said: “Prose is architecture, not interior decoration.”
Right now, the industry is obsessed with the decoration. Popular benchmarks and leaderboards reward fancy metaphors, complex phrasing, and excessive length while ignoring correctness, coherence, nuance, and taste.
Hemingway-bench is our attempt to fix the foundation, and move toward a rigorous evaluation of AI prose and creativity.