In my first post, I covered how to choose the right Macbook: a relatively reversible and deterministic problem. Hiring is different. It’s an explore–exploit problem under partial information. Treating it like a stochastic decision process—with explicit timelines, priors about the market, and structured updates—helps you hire better people, and with less bias.
When I started writing this post, I didn’t expect to find myself — and almost everyone I spoke to — so systematically biased at every step of the hiring process. Whether at Microsoft, Google, Amazon as well as early stage startups — I found that every one had many biases in their hiring process. Even those in the data science roles did not apply any data science to improve their hiring.
Let’s say you’ve opened a crucial role. The first candidate is strong—maybe the best you’ve ever seen. Do you hire now or keep exploring? Stop too early and you miss someone better. Stop too late and you waste cycles waiting for a unicorn who doesn’t exist.
Our instincts evolved to remember stories about tigers, not distributions of tiger attacks.
In hiring, that instinct makes us latch onto the most vivid candidate, not the most probable fit. So we build systems — to replace narrative bias with numerical discipline.
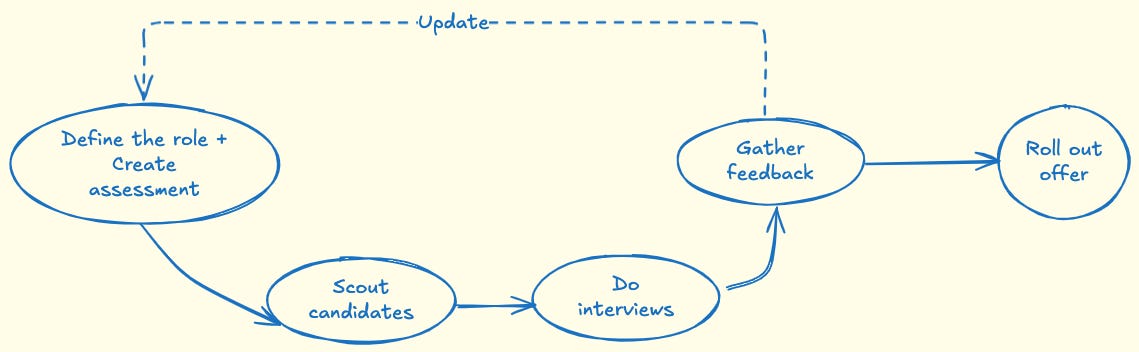
Every hiring process follows roughly four stages. At each step, we can instrument the process with data hooks to make decisions sharper and more consistent.
Define the role
Scout for candidates
Run the interviews
Time the offer
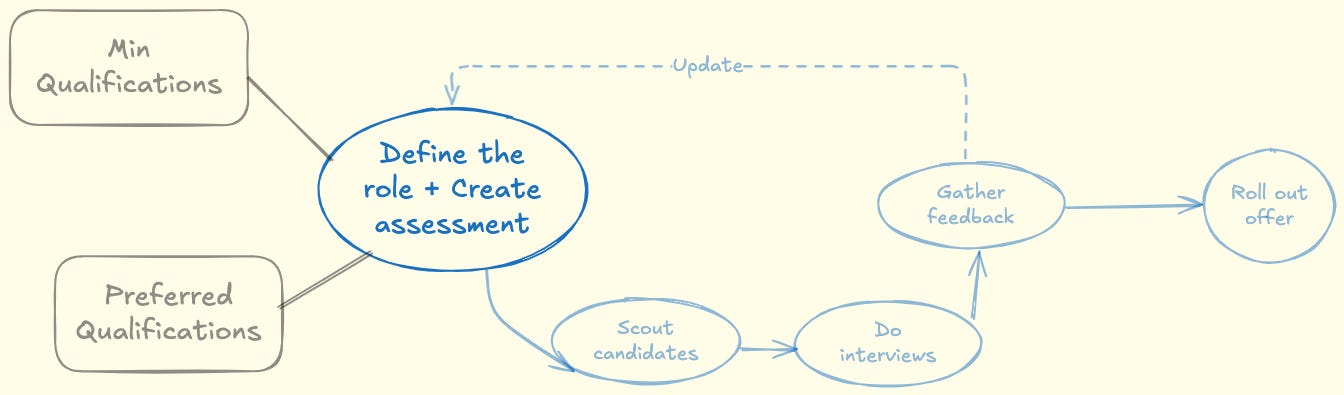
The first step of a hiring any candidate is defining the role. It is usually defined by the hiring manager. The role describes the position with minimum and preferred qualifications (education, experience). Once that’s set, the interview panel typically agrees on the assessment for the defined role.
The timeline rarely gets enough attention, yet it dictates almost everything downstream.
Think of it like house-hunting. You can fix the budget and the neighborhood, but without a time box, you’ll endlessly chase the perfect home. (Real estate, as the saying goes, is always too expensive when you want to buy and too cheap when you want to sell.)
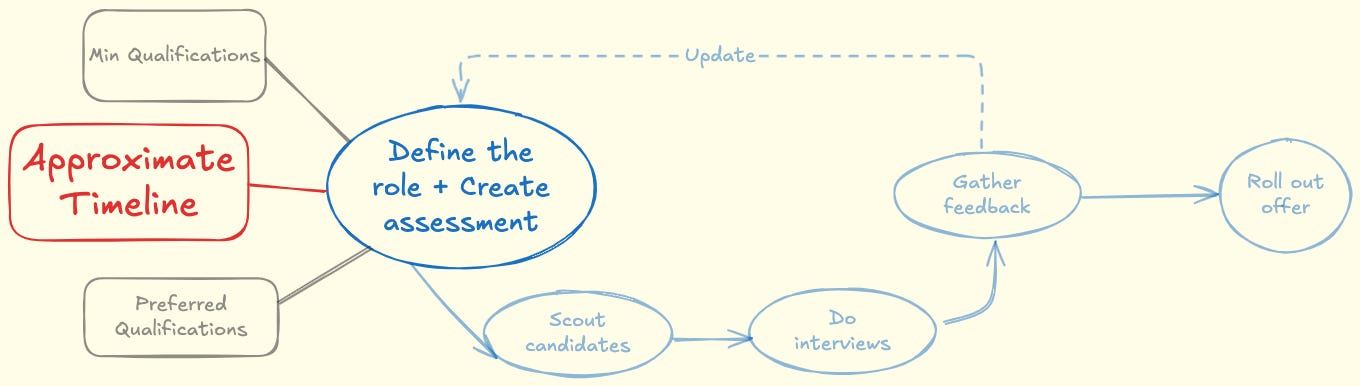
Depending on how reversible or critical the hire is, adjust your timeline. In a three-person startup, the next hire can change your trajectory. In a large team, a slightly sub-optimal hire might be manageable. Either way, defining the time horizon is step one toward a data-driven process.
The non-technical recruiters reach out to the candidates based on the defined role. The candidates who are deemed fit are shared with the hiring manager in no specific order.
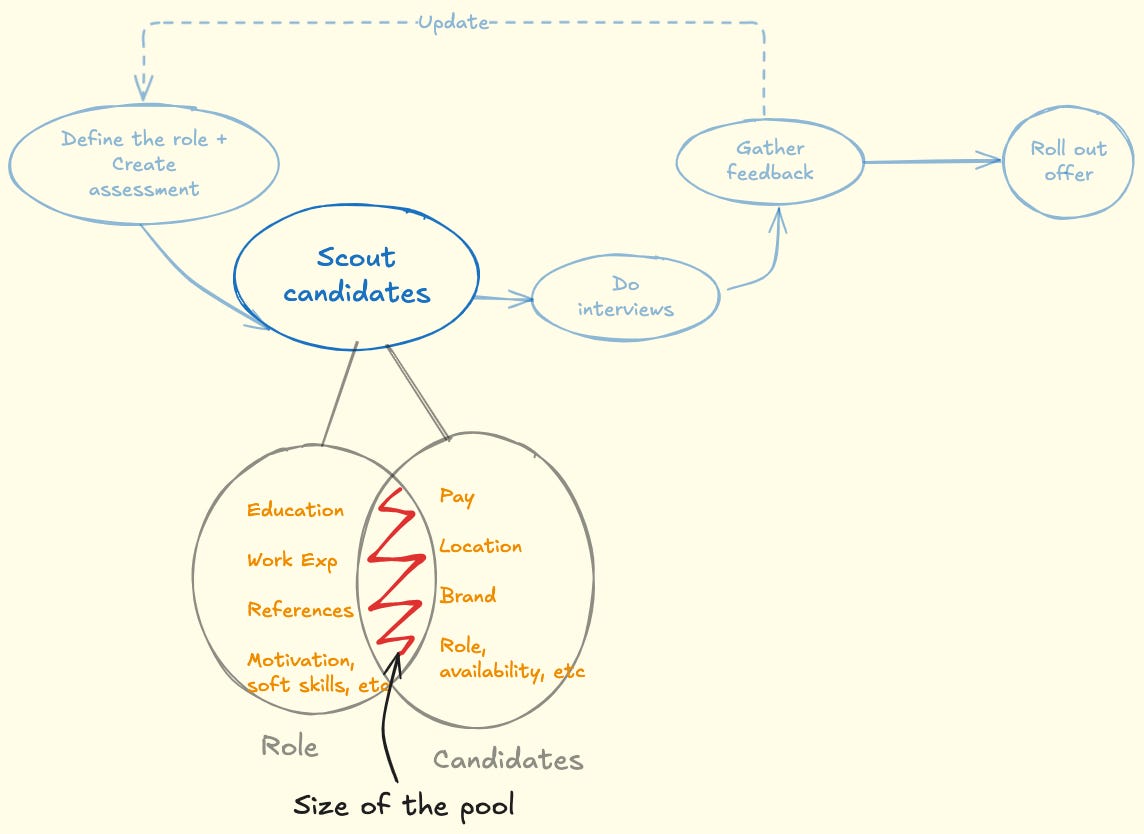
Even a rough estimate of your candidate pool changes how you plan. Combine brand strength, referral volume, and weekly screening throughput to approximate it.
Guesstimate:
Pool size = (Number of candidates that clear screening per week) x (Number of weeks the position will be open)
This gives you priors on how selective you can afford to be.
You’ve defined the role and scoped the pool. Now comes the assessment—the part most teams over-optimize.
A friend once interviewed at a major tech company and was asked the same case study twice. That redundancy signals disorganization and leaves a poor impression, especially at senior levels.
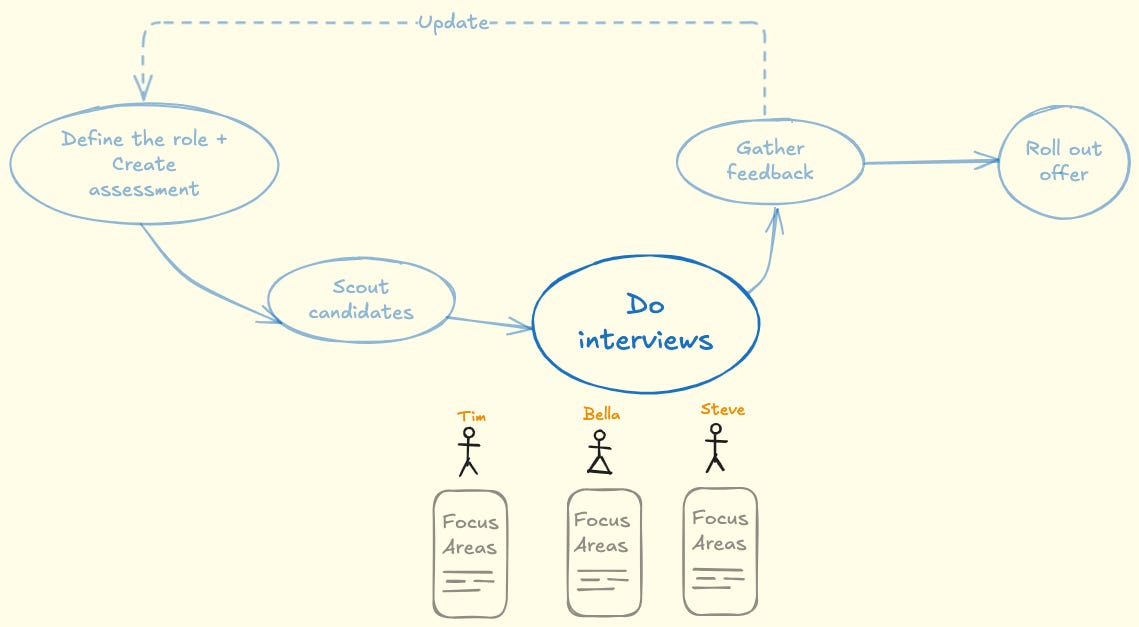
Define the focus areas for each interview so that you are covering the breadth as well as the depth in the interviews. No duplicates, no “vibes‑only” rounds. During the debrief, the scores for every focus area should be backed by evidence not intuition.
Panel map (example for senior data scientist):
Technical depth (90m): modeling & trade‑offs; whiteboard or notebook—not leetcode.
Applied product sense (60m): translate an ambiguous business ask into a measurable plan.
Systems & data (60m): pipelines, quality, ownership.
Collaboration & leadership (45m): conflict scenario; mentoring loop.
Take‑home or in‑session case: realistically scoped.
The first time you try anything new, be it food or wine or car, you don’t have any previous experience. Only after a few tastes/tries, do you get a sense of good from the bad. This is especially true for things that you possess. Take cars for example. Owning a car is a completely different experience. No matter how many test drives you take, you will only know whether a car is good once you own it for a few months.
Hiring is similar: if you’ve made comparable hires before, you have priors; if not, each interview updates your mental model of the role itself.
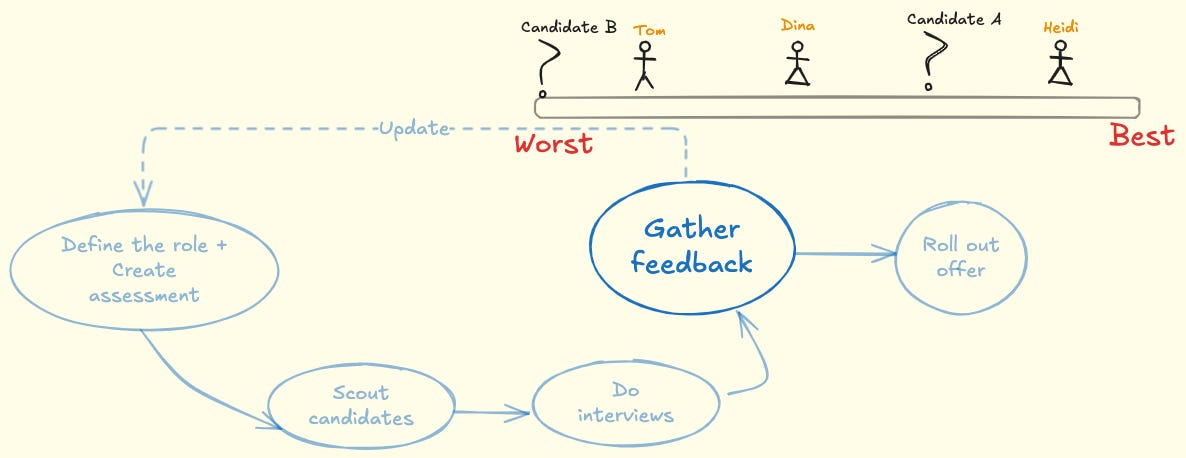
It gets trickier if the position is unique. In this case, you start with zero information. Each interview adds information—not just about the candidate, but about the role itself. Building a skill scale as you go helps create a benchmark.
In the search for the best candidates, there are two ways to fail: stopping too early or stopping too late. When you stop too early, you leave the best applicant undiscovered. When you stop too late, you hold out for an applicant who doesn’t exist.
When you aim to hire the best applicant, settling for nothing less, it’s clear that as you go through the interview process you shouldn’t even consider hiring somebody who isn’t the best you’ve seen so far. However, simply being the best yet isn’t enough to roll out that offer; the very first applicant, will of course be the best yet. The second candidate has 50-50 chance of being the best yet. The fifth applicant will have a 1/5th chance of being the best yet and so on. As you go through the interviews, the best yet becomes better and better. Let’s dive deeper into the math in the next session to see how to get the timing right.
Now that we have covered all the steps and added the data hooks, it’s time to use those to model a more robust and rational decision process.
If candidates arrive with an average rate λ per week, the expected number in T weeks is λT. This turns guesswork into planning:
Low λ? Loosen requirements or add channels
High λ with low pass‑through? Your screen is mis‑calibrated.
Quick calculator:
Expected screens = λ_screen × T
Expected onsites = Expected screens × P(screen→onsite)
Expected offers = Expected onsites × P(onsite→offer)
Expected accepts = Expected offers × P(offer→accept)
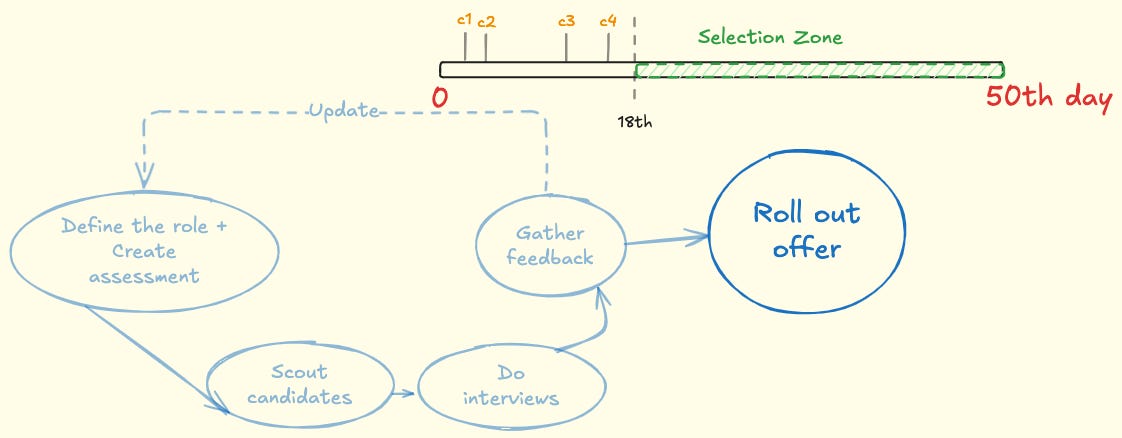
With an unknown distribution of candidate quality over a fixed horizon, the strategy that maximizes the probability of picking the true best is: reject the first 37% to set a benchmark; then take the next candidate who beats that benchmark. It isn’t perfect, but it’s a strong default and—crucially—operationalizable.
If you have read through the post, this is the bonus section. One final takeaway (if nothing else) is that you can apply this rule very simply:
Simple Reference:
Time to hire = 10 Weeks (50 days)
Candidate selection zone = 50 × .37→ 18 days (~4weeks)
What really defines a workplace is its people. Hence, hiring is not a process that should be taken lightly. Data doesn’t replace judgment; it shapes it. The discipline is to decide your horizon, estimate λ, collect signals, and then honor your stopping rule. That’s how you respect candidates’ time, your team’s energy, and your own standards.
What I demonstrate in this post doesn’t require much extra effort, but it can lead to maximum gains and minimum regrets. As they say, choose wisely.