Recently, OpenJDK team released an early access build on Valhalla Build 26-jep401ea2+1-1 (2025/10/10). Project Valhalla is an ongoing effort to enhance the Java language and virtual machine by introducing classes and objects without identity, known as value classes. The primary goal is to enable developers to create lightweight, immutable data carriers that can be stored efficiently in memory, improving performance, cache locality, and data-centric computation, while maintaining Java’s safety and compatibility guarantees. The longest incubating project, the Vector API, is still waiting for Valhalla to enter preview in order to use value classes as light weight objects with automatic bound checks by default.
In Java, objects have identity, whereby each object instance occupies a unique location in memory. This is conceptually similar to the notion of pointers in C, where an address serves as a handle to a particular memory region. An object’s identity distinguishes it from all others, even if two objects contain the same data. For example, when a second reference variable is assigned to an existing object, both variables refer to the same memory location. This behaviour becomes evident when observing live objects on the heap, especially when multiple instances of the same class are created and stored in an array.
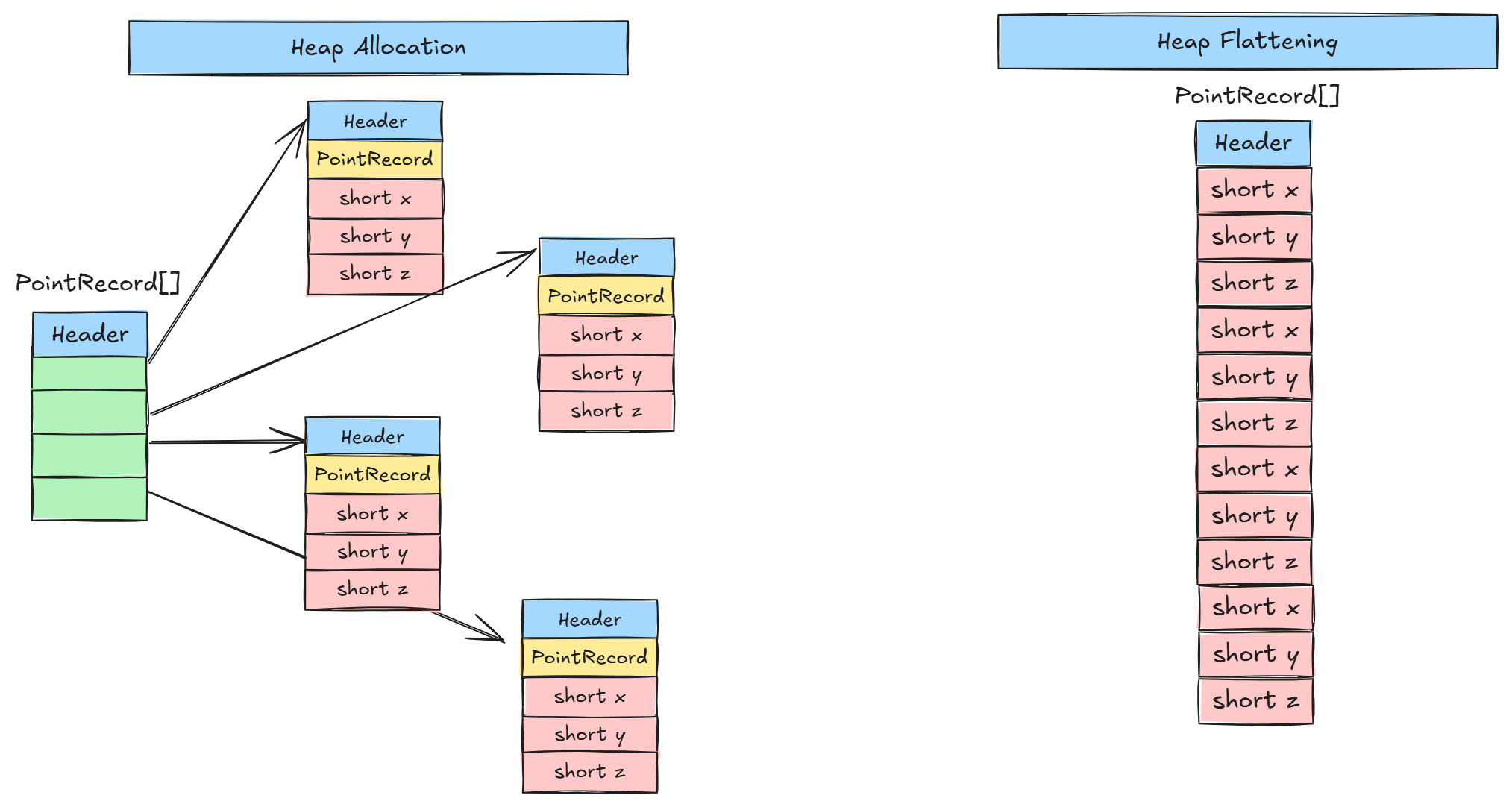
Comparison of heap allocation for identity objects (left) versus flattened memory layout for value objects (right).
Identity is a fundamental property in Java. It enables synchronisation, prevents data tearing, supports mutability, and underpins polymorphism. These properties have been central to Java’s object model and concurrency guarantees since its inception.
However, the presence of identity comes at a cost. Objects with identity are typically allocated indirectly on the heap, meaning that an array of objects holds references rather than the objects’ data themselves. This indirection breaks memory locality, leading to cache misses and degraded performance compared to primitive arrays, which store their elements contiguously in memory. While primitives avoid these issues, traditional Java objects cannot due to their identity semantics inherently prevent compact and flattened layouts.
Project Valhalla addresses this limitation by rethinking the object model. Its goal is to allow developers to opt out of identity when it is not semantically required, enabling the JVM to store such instances more efficiently. This enables for free to have inlined, flattened, and cache-friendly objects, while preserving Java’s safety guarantees.
To investigate this property, I conducted experiments using the latest OpenJDK Valhalla early-access build, analysing alignment and layout of value objects within arrays using the following code sample1:
value record PointRecord(short x, short y, short z) {
PointRecord(){
this((short)0, (short)0, (short)0);
}
}
void main() throws InterruptedException {
//Allow VisualVM attachment
Thread.sleep(9000);
IO.println(”Starting”);
int size = 10_000_000;
var points = new PointRecord[size];
for(int i = 0; i < size; i++) {
points[i] = new PointRecord();
}
//Ensure array stays in heap & observe it in VisualVM
Thread.sleep(9000);
}
When running the sample code, I monitored the heap memory using VisualVM to observe how instances were represented in memory.
VisualVM interface
A quick observation without the value modifier, PointRecord behaves as a regular identity class, meaning each instance is a distinct object allocated separately on the heap. However, when declared with the value modifier, PointRecord becomes a value class, it loses object identity and can therefore it is flattened directly into the containing array. In this case, no individual PointRecord instances appear as live objects on the heap; instead, the data is represented as part of the array’s internal structure. The resulting memory footprint is significantly smaller.
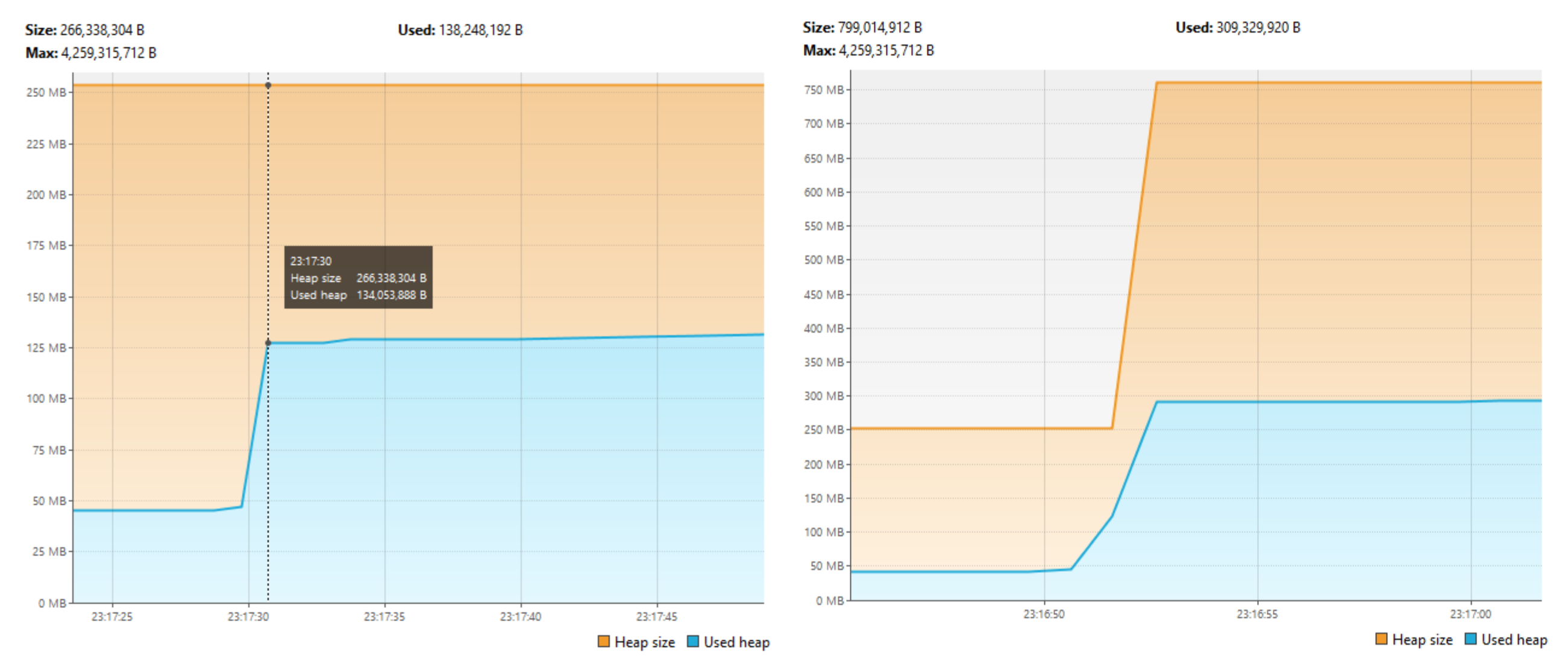
Heap memory comparison between identity and value objects.
The spike in each graph marks the initialization of a PointRecord[] array with 10 million elements. On the left, PointRecord is a value record, flattened directly within the array, with no per-element heap allocation (≈ 138 MB used). On the right, PointRecord is a regular identity record, where each element is separately allocated, causing a larger heap footprint (≈ 309 MB). This illustrates how value-based flattening in Project Valhalla greatly improves memory density and locality.
Inspecting the detailed memory view in VisualVM further clarifies the distinction between identity and value objects. For the identity class version, the array stores references to separate PointRecord instances, each individually allocated on the heap. In contrast, for the value class version, only the array object itself appears on the heap, its elements are stored inline, without per-element object headers or reference indirection.
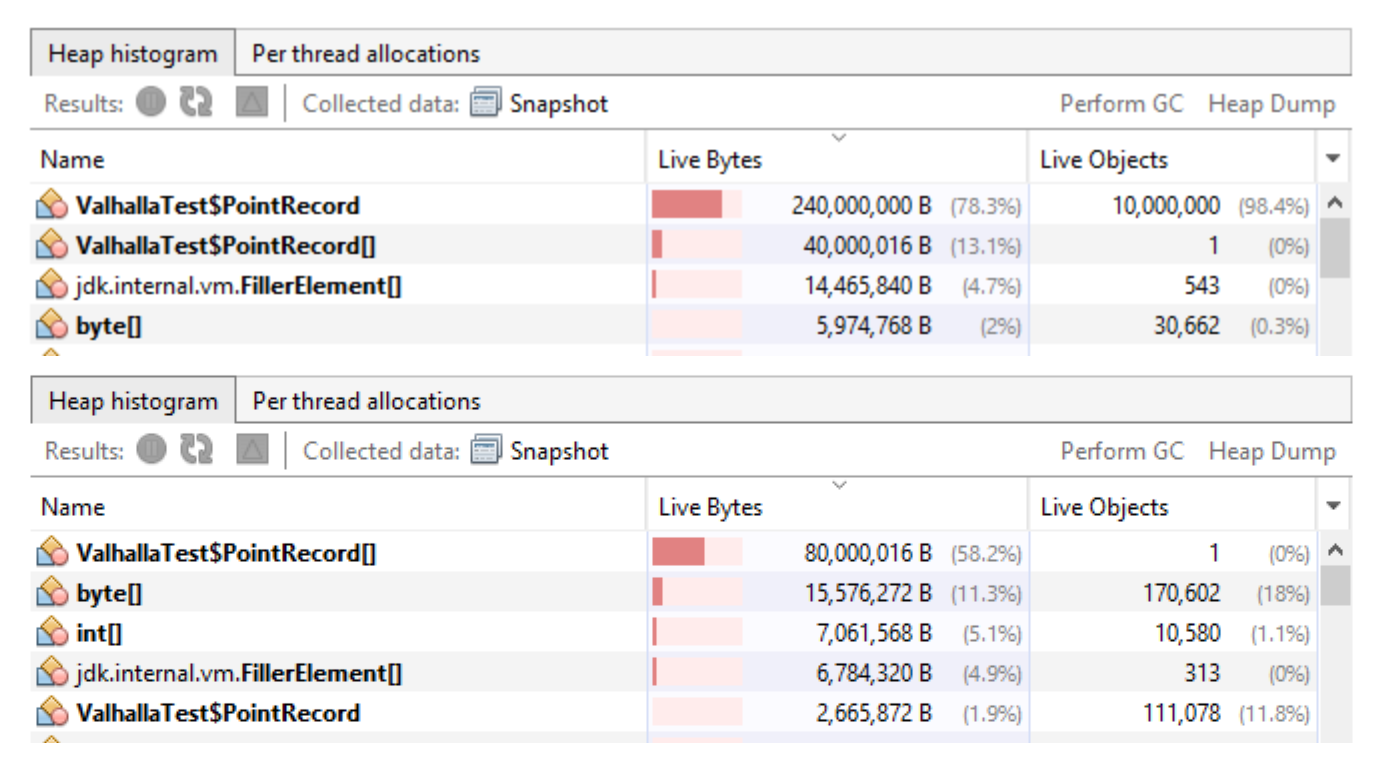
Heap histogram comparison between identity and value PointRecord arrays.
The upper histogram shows the identity record version, where each of the 10 million PointRecord elements is a separate heap object, using about 240 MB for object data and 40 MB for the array itself. The lower histogram shows the value record version, where elements are flattened directly within the array, leaving only a single PointRecord[] entry on the heap (≈ 80 MB total). A few temporary PointRecord instances appear due to short-lived materializations during initialization or profiling.
This demonstrates memory flattening whereby value objects are stored contiguously, removing identity and reference overhead, cutting heap usage by nearly threefold, and improving cache locality. By contrast, identity objects require separate allocations and indirections, increasing fragmentation and memory pressure. These results highlight Project Valhalla’s ability to deliver compact and cache-efficient data layouts for objects that do not require identity.
Examining the value class layout, it can be inferred that its size generally follows a packed struct model, similar to C, where no padding is expected except where field alignment is required. Based on this assumption, the expected sizes would be:
value record PointRecord(short x, short y, short z){} -> 6 bytes + 2 bytes pad
value record PointRecord(short x, short y){} -> 4 bytes
value record PointRecord(short x){} -> 2 bytesExpected size of PointRecord instances based on field composition.
For the test above, an array of 10 million PointRecord(x, y, z) instances should yield roughly 60 MB of data. However, inspection in VisualVM shows that the actual usage is closer to 80 MB, implying 8 bytes per element, not 6 bytes. Which is an expected alignment.
But interestingly, PointRecord(x, y) also occupies 8 bytes, while PointRecord(x) is 4 bytes. Which shouldn’t be that way. It should be 4 bytes and 2 bytes respectively which obeys alignment sizes.
value record PointRecord(short x, short y, short z){} -> 8 bytes
value record PointRecord(short x, short y){} -> 8 bytes
value record PointRecord(short x){} -> 4 bytesActual size of PointRecord instances as observed in the JVM.
This raises an important question: why does the JVM align small value objects (x, y) and (x) this way?
After further investigation to understand the alignment discrepancy, I sought clarification through the OpenJDK Valhalla mailing list. A member of the OpenJDK specification team kindly confirmed that the extra byte observed in the flattened layout arises from a null marker added to represent the nullable nature of value arrays.
Although value objects themselves lack identity, arrays of value objects remain nullable by design. Each element in such an array must therefore be able to represent either a real value or null. To support this, the JVM appends a 1-byte null marker to each element and then aligns the total element size to the nearest power-of-two boundary for atomic access and tearing prevention.
value record PointRecord(short x, short y, short z){}
//2 bytes + 2 bytes + 2 bytes + 1 byte null marker + 1 byte padding - 8 bytes
value record PointRecord(short x, short y){}
//2 bytes + 2 bytes + 1 byte null marker + 3 byte padding -> 8 bytes
value record PointRecord(short x){}
//2 bytes + 1 byte null marker + 1 byte padding -> 4 bytesAs explained, this design ensures that the JVM can read or write each element atomically, maintaining safety and preventing tearing.
Running the program above using command -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlineLayout, the value object layout is printed for PointRecord(x, y, z) as follows:
Layout of class ValhallaTest$PointRecord@000002A24D837640 extends java/lang/Record@000002A2298AD0A0
Instance fields:
@0 RESERVED 12/-
@12 PADDING 4/1
@16 REGULAR 2/2 “x” S
@18 REGULAR 2/2 “y” S
@20 REGULAR 2/2 “z” S
@22 NULL_MARKER 1/1
Static fields:
@0 RESERVED 120/-
@120 REGULAR 4/4 “.null_reset” Ljava/lang/Object;
Instance size = 24 bytes
First field offset = 16
Payload layout: 8/8
Non atomic flat layout: -/-
Atomic flat layout: 8/8
Nullable flat layout: 8/8
Null marker offset = 22
---This provides direct evidence of null marker insertion and the padding.
Future revisions of Project Valhalla plan to introduce null-restricted arrays, where this marker and the corresponding padding can be omitted entirely, allowing even denser and more cache-efficient layouts.
In the current Valhalla prototype, flattening of value objects is bounded by atomicity constraints. A value object remains flattened only if its total size, including the null marker used in nullable arrays, fits within the atomic access width of the underlying platform (typically 64 bits). When the payload size reaches 64 bits exactly, the additional 1-byte null marker exceeds the atomic boundary. At this point, the JVM can no longer perform a single atomic read or write, forcing the value object to be boxed (allocated as a heap object with identity).
This behaviour guarantees tearing prevention, ensuring that concurrent reads and writes never observe partial updates. Interestingly, the feedback from OpenJDK team (Remi) confirmed that this issue is well known within the Valhalla design effort. The team is exploring ways to opt-out of atomicity in certain cases, allowing controlled tearing or user-declared non-atomic arrays, to preserve flattening even beyond 64-bit payloads.
Valhalla is a long-term design effort that fundamentally refactors both the Java language and the JVM. Earlier iterations explored several complex approaches, but the potential performance benefits of value objects are already evident (even though I have not yet conducted formal benchmarks). From a design and backward-compatibility standpoint, Valhalla shows that relatively little needs to change in the existing Java model to achieve significant memory and performance gains. The project has also inspired several spin-offs, including null-restricted arrays, reification, and related JVM model refinements.
This study demonstrates the potential impact value objects could bring to the broader Java ecosystem whereby enabling minimal stack usage, maximised register efficiency, and a data-oriented runtime model. This direction is notably distinct from other languages such as Rust, which rely on static compiler analyses for their memory safety and ownership semantics. Further testing and performance evaluation will reveal how these design choices ultimately shape Java’s evolution toward a more predictable and high-performance memory model.