Intelligence is not free, and infinite context is not always useful
There’s a peculiar amnesia that sets in when you have access to something powerful. You often forget that power has a price. Intelligence, it turns out, has a price tag and we just got extremely good at ignoring it.
Perhaps it’s not amnesia; maybe it’s simply that our mental models for reasoning about intelligence-per-dollar are less developed than they should be. We have established frameworks for thinking about speed, for organising information, for managing memory. But the equivalent framework for when to use intelligence, and how much, remains fuzzy, even to those who understand that defaulting to the most intelligent model is naive.

The prediction part is solved, or at least measurable. We can benchmark which model is more accurate, which architecture scales better, which context window is larger. But judgement remains trickier. Deciding what intelligence is worth paying for, when context stops adding value, where to draw the line between capability and cost, that remains more art than science.
The interesting question isn’t which model to use. Most engineers already know that’s context-dependent. The interesting question is: how do you systematically reason about the trade-offs between capability, context and cost?
When designing an AI system, you are essentially balancing three factors that pull in different directions
Model Capability: The model’s reasoning depth, accuracy and ability to generalise. This is about whether it can handle the complexity you’re throwing at it. A model which performs well on structured Q&A may not necessarily perform well on multi-step reasoning or code generation. The question isn’t ‘Can it answer?’, but “Can it reason through unclear situations, edge cases, and stay consistent across complicated interactions?”
Context Length: How much information the model processes before generating a response. This is the model’s working memory; everything it can “see” when generating a response. More context can improve precision, but it increases cost and latency linearly (or worse, quadratically sometimes). What matters isn’t just volume, but the marginal value of each additional message or document.
Inference Cost : The actual dollar cost per request, taking into account latency and throughput limits. This is about unit economics at scale. Unlike traditional software where you build once and deploy, AI models charge you for every interaction, and hence more users means proportionally higher cost. The question then becomes: “does this cost structure work at the scale we’re targeting, with the speed users expect?”
The levers don’t move on their own. Adding more context raises costs. Upgrading to a better model means you will face higher latency or a bigger burn rate. You are constantly exchanging one thing for another. The design challenge is to find the efficiency frontier, the point where marginal gains stop justifying marginal costs.
Here’s a useful mental model: doubling context length rarely doubles value.
Imagine you’re building a customer support bot. If the model sees the last 3 messages in a conversation, it can resolve around 70% of the issues. Expand context to the last 10 messages and you might hit 85%. But expanding to 50 messages? You’re now processing 5x more tokens for maybe a 3% improvement in resolution rate.
This is nothing new. We see this pattern everywhere and probably studied it in ‘Introduction to Economics’. This is the diminishing returns problem, except we somehow forget it applies to intelligence. Newer models with improved attention mechanisms handle longer contexts more gracefully than their predecessors. But the fundamental economic principle holds: marginal returns diminish, and at some point, additional context becomes a luxury you’re paying for but not benefiting from. Anthropic’s research on what they call Contextual Retrieval pushes this insight further. It’s not just that more context gives diminishing returns. It’s that how you present context matters way more than how much you send. Here’s what this would look like:
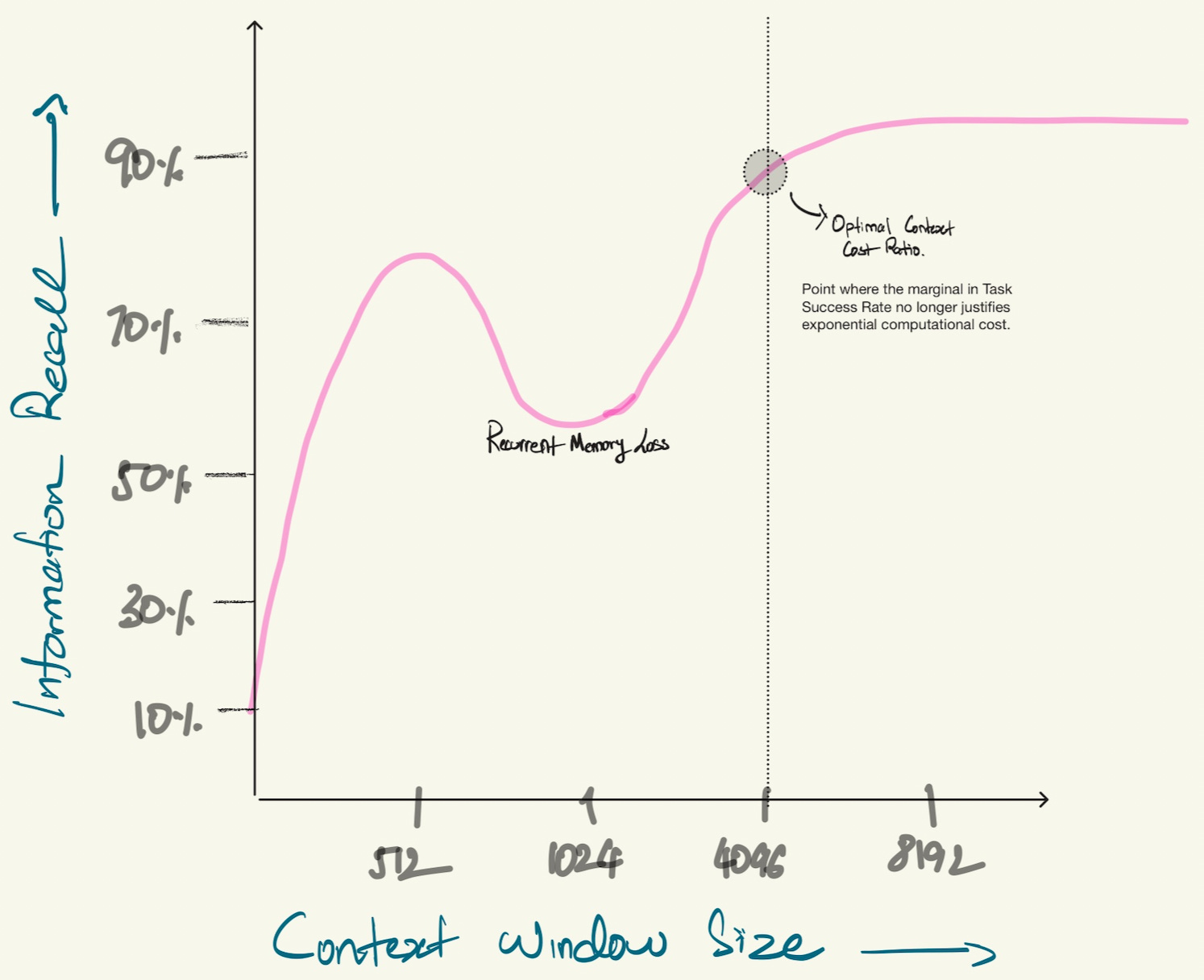
At small context windows (512 tokens), recall jumps fast (for those unfamiliar with this term, think of recall as the model’s ability to retrieve and use relevant information. Essentially, how well it finds what it needs). Push the context window to moderate sizes (1024 tokens) and you hit what researchers call “Recurrent-Memory Loss” (or lost in the middle).
The optimal point isn’t at max context. It’s where gains stop justifying the computational cost.
I love analogies, so here’s one: this “lost in the middle” problem is exactly like finding a needle in a haystack, and researchers have documented this across various transformer architectures. In many models, especially older ones, performance can actually drop when you add more context. The model gets sharp at using information at the start and end of its context window, but the middle gets buried. Imagine trying to find a specific email in an overflowing inbox; it can be quite overwhelming. Now picture the ease of locating that same email within a neatly organised folder containing just five messages. However, it is important to note that this pattern varies by model generation. GPT-4 and Claude 3 handle mid-context information better than GPT-3.5, but they’re not immune to the effect.
The same thing happens with model capability, but the breaking points are different. If you are building a basic FAQ bot, GPT-3.5 gives you 95% of the results that GPT-4 offers, and it costs only one-tenth as much. However, for complex code generation or multi-step reasoning, GPT-4 may truly be worth ten times more.
The mistake I see (and have made) is that we often treat intelligence as if it’s always valuable. But here’s the thing: it’s not always the case. Intelligence is simply a tool that holds significance only in certain contexts.
A Framework: Intelligence-per-Dollar
You need some way to think about these trade-offs. I use this:
Value = (Capability-Task Fit × Context Relevance) / (Cost × Latency Tolerance)
Here’s how I think about each piece:
Capability-Task Fit: Does the model’s capability actually align with your problem’s difficulty? Using a frontier model for simple classification is like hiring a surgeon to apply a band-aid.
Context Relevance: Are you sending the right information, not just more information? Quality of context matters more than quantity.
Cost: Dollars per thousand tokens.
Latency: Time to first token plus generation time
But here’s where it gets really interesting. The numerator (in other words) comprises of model capability times retrieval precision, meaning if your retrieval is garbage, even the smartest model in the world won’t save you (most of the times).
While the denominator has cost times latency. A model that costs 2x more and runs 50% slower isn’t just twice as expensive. It’s 3x worse in terms of value per dollar per second, and the effects compound. This usually isn’t obvious when you’re comparing prices on a spreadsheet because people generally perceive “$0.03 vs $0.015 per token” as simply paying double. You miss that you’re also waiting longer, which means serving fewer requests per second, which means needing more capacity, and hence the real multiplier is higher.
Maybe some of you are bored by reading theory and numbers, so let’s throw in a real-world challenge that engineering teams face and hopefully that makes things more interesting!
Challenge: You’re building a system that reviews pull requests and suggests code improvements. Not necessarily trivial autocomplete but also actual architectural feedback, security checks, style consistency, and so on
The intuitive (wrong) approach: Every PR gets complete attention. Send GPT-4.5 everything, including the full diff, all related files, and commit history. Provide maximum context with maximum understanding.
Here’s what actually happens. You’re sending around 30,000 tokens per review. As of today, GPT-4.5 runs about $75/1M input tokens and $150/1M output tokens.
That’s $2.25 just for the model to read the context, then another $0.30 for a typical 2,000-token response ($2.55 per review).
If the team does roughly 200 PRs weekly, you’re burning through $26,520 annually with a wait time of 15 seconds every time.
But here’s the thing that brings us back to where we started: infinite context is not always useful. Most PRs don’t require 30,000 tokens of context. A documentation update doesn’t need the full codebase history and a three-line bug fix doesn’t need architectural context. You’re paying to send information the model doesn’t use.
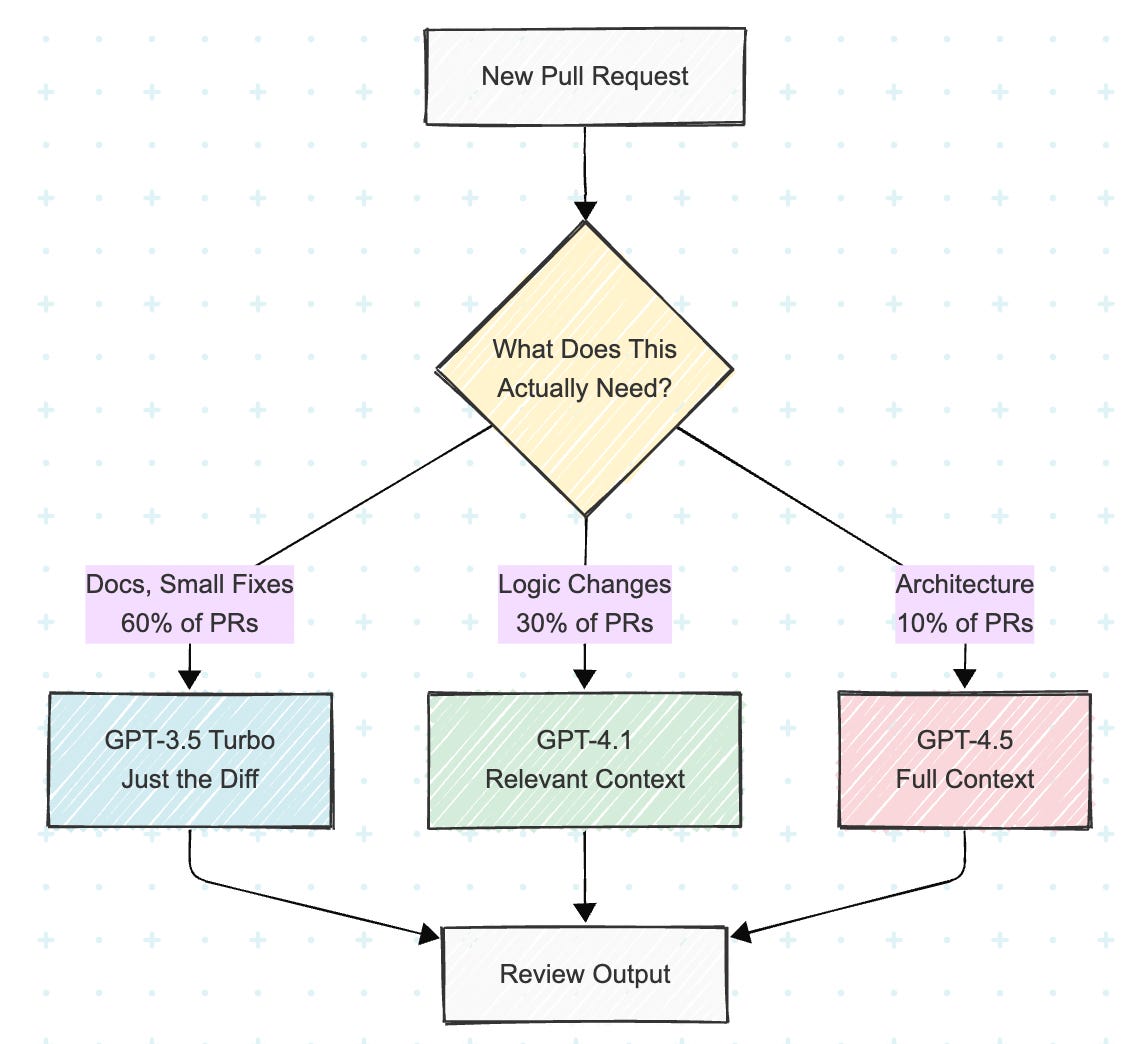
Optimised approach: Route based on what each PR actually needs. Documentation changes get GPT-3.5 with just the diff (which could be around 2,000 tokens). At $0.50/1M input tokens, that’s basically nothing. Meanwhile, complex architectural changes get GPT-4.5 with carefully selected context (with not everything, but just what matters).
60% of PRs (simple changes): GPT-3.5 Turbo, ~2K tokens = ~$0.001 per review, 2 seconds wait
30% of PRs (medium complexity): GPT-4.1, filtered context ~8K tokens = ~$0.032 per review, 6 seconds wait
10% of PRs (complex): GPT-4.5, full context ~30K tokens = ~$2.55 ($2.25 + $0.30) per review, 15 seconds wait
Annual cost drops from roughly $26,500 to $2,800, a staggering 89% reduction. Average response time falls from 15 seconds to about 6 seconds because most requests hit the faster, cheaper model.
Sometimes the simple model was actually better for straightforward changes because it wasn’t overthinking things. If we try to visualise the optimised approach, it would look something as such:
The Invisible Hand of Intelligence
I hope you get the above pun…
Anyways, the core theme of this article wasn’t about AI at all but rather scarcity. Economics has always been the study of how we allocate limited resources, and intelligence, it turns out, is just another commodity subject to the same fundamental laws.
The routing solution we explored isn’t clever engineering; it’s price discovery in action. By creating different service tiers based on actual need rather than theoretical capability, we’re essentially building a market for intelligence. Simple changes get economy-class reasoning, complex architecture gets first-class analysis. This isn’t just about cutting costs. It’s about the rise of an intelligence economy. In this economy, value goes to where it’s truly needed, not just where it’s technically possible.
The companies that master this routing logic won’t just save money; they’ll have built the foundational skill for an era where intelligence is abundant but knowing when to use it is still rare.
Adam Smith’s invisible hand, it seems, works just as well for allocating artificial intelligence as it does for everything else.