I was just messing around with DuckLake this weekend. You know how it is with new database tech: you read the docs, try the examples, but you never really get it until you break something or discover something unexpected.
What I found ended up being way bigger than I initially thought.
I decided to test DuckLake with actual infrastructure. I grabbed the NYC Taxi dataset (2.7 million rows, 1.2GB) and set up a R2 bucket.
I was testing different storage backends when I tried something that seemed almost too simple. Instead of choosing between different storage options, what if I used both for different purposes?
I sat there staring at the results. Same metadata catalog. Same table structure. Same 2.7 million rows. But I was writing through R2's native API for maximum throughput, then reading through HTTP for CDN optimization.
It worked flawlessly.
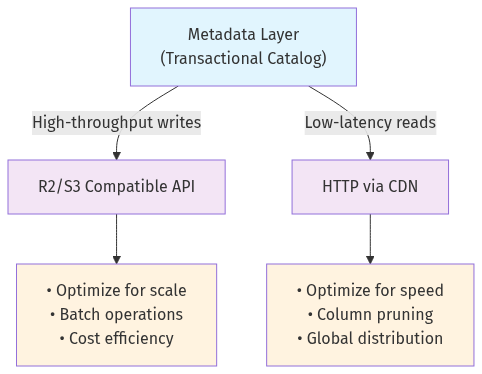
A single lakehouse metadata catalog can drive orthogonally optimized write and read paths this seamlessly without sacrificing database semantics.
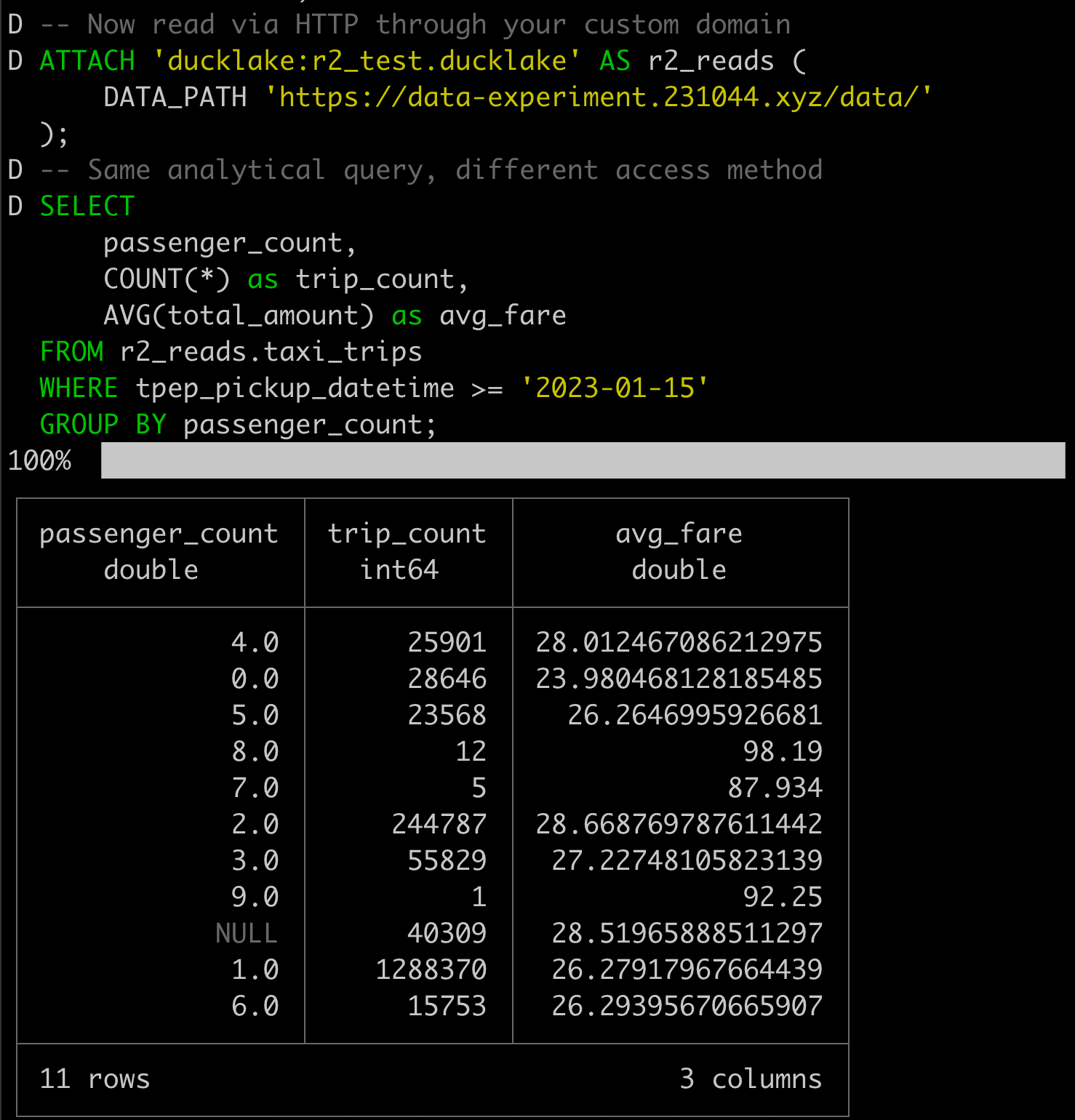
I measured everything properly, disabling DuckDB v1.3.0's new external file cache to isolate the pure CDN effects.
This balance of local speed vs global accessibility enables architectures that simply weren’t practical before.
This wasn't localhost magic. This was running on Cloudflare infra, processing real analytical workloads with real network latency. 0.655s for a complex analytical query on 2.7M rows over HTTP is remarkable when you consider the alternative is either giving up database features or deploying expensive multi-region infrastructure.
An interesting side discovery: DuckDB v1.3.0's external file cache combines with CDN caching to create a powerful multi-tier architecture (local cache + CDN edge cache + origin storage) that optimizes for both local performance and global distribution.

This pattern enables several game-changing capabilities:
Global Analytics Teams can give every analyst consistent sub-second performance on complex queries regardless of location. Historical analysis via time travel works at the same speed as current metrics, and schema changes deploy instantly via CDN.
Multi-Tenant SaaS architectures become much simpler. Each customer's data gets isolated via CDN prefixes, and complex analytical features become viable globally without maintaining per-region infrastructure.
Serverless Functions see massive benefits. Stateless compute traditionally suffers from cold-start data access penalties, but with globally cached data, there are none. Complex queries on cached data run at CDN speed regardless of function location:
Development → Production Parity becomes trivial. The same application code works with local files in development, HTTP in staging, and CDN in production with zero configuration changes.
Security works as expected. DuckLake supports encryption where all Parquet files get encrypted with unique keys stored in your private metadata catalog. You can serve encrypted data via public CDN while maintaining complete security. (Note: Real zero-trust requires careful key management beyond what DuckLake provides out of the box.)
The deeper insight is that instead of accepting architectural trade-offs, we can design systems where different aspects optimize independently. Traditional constraint: Choose between throughput OR latency. Asymmetric pattern: Optimize both independently while preserving consistency.
This principle applies well beyond DuckLake. It's an architectural unlock that could influence how we think about many distributed systems. Applications can now assume global sub-second analytics as a baseline capability, with historical analysis, schema evolution, and zero-trust data sharing all delivered at CDN speeds.
The serverless transformation is particularly significant. Previously, stateless compute meant slow data access. Now stateless compute can deliver fast analytical results because the data layer is independently optimized for global access.
This approach deserves a name: Asymmetric Lakehouse Architecture.
Key characteristics:
Single metadata catalog managing multiple access paths
Write path optimized for throughput and cost efficiency
Read path optimized for latency and global distribution
Database semantics preserved across all access patterns
What started as a weekend experiment became discovering a new architectural pattern validated with real cloud infrastructure. Sub-second global analytics with full database semantics using standard cloud infrastructure: a trade-off that enables new architectures.
The question isn't whether this becomes standard. It's how quickly we adapt our expectations to match what's now possible.
Sometimes the most significant insights hide behind simple parameter changes. All it took was asking: "What if the same lakehouse could optimize writes and reads completely differently?"
Want to implement this pattern? Start with Cloudflare R2, add a custom domain with CDN enabled, and install the DuckLake extension. The future of data architecture is one ATTACH statement away.
-- Write via native API for throughput
ATTACH 'ducklake:r2_test.ducklake' AS r2_writes (DATA_PATH 'r2://...');
-- Read via HTTP/CDN for latency
ATTACH 'ducklake:r2_test.ducklake' AS r2_reads (DATA_PATH 'https://...');About this implementation: Tested with DuckDB 1.3.0, NYC Taxi dataset (2.7M rows, 1.2GB), R2 bucket, and custom domain. All performance measurements reflect real-world testing.