AI tools like ChatGPT and Gemini DeepResearch can instantly generate detailed reports on complex topics by pulling from countless online sources. I've been amazed by how useful this can be—like having a research assistant who quickly digests mountains of information and produces surprisingly coherent summaries. With new specialized AI research tools emerging such as Perplexity DeepResearch, FireCrawl DeepResearch and Jina AI DeepSearch, it's clear we're rapidly entering an era where automated agents perform sophisticated research tasks.
But as these AI tools got better and better at writing, I noticed a troubling gap: how accurate are these AI-generated reports?
After encountering this problem repeatedly, I decided to build a solution—the Truth Layer. It's a system that automatically checks whether claims in an AI-generated report are actually supported by the sources the report cites.
Rather than choosing between blind trust or hours of manual fact-checking, the Truth Layer offers:
Real Transparency: You can see exactly which claims are supported and which aren't.
A Clear Trust Score: A straightforward metric showing how well the report backs up its claims.
Saves Hours of Manual Work: Automates the tedious process of checking sources.
Let me walk you through the verification process I designed:
First, the system needs to understand what to verify. It reads the report and uses Google's Gemini to identify specific factual claims and connect them to the exact URLs cited as their evidence. A key insight was realizing claims should be reframed into standalone verification questions. This significantly improved how precisely the system evaluates evidence from cited sources, minimizing misunderstandings.
For example, when analyzing a report on climate change, it might extract the claim "Global temperatures have risen 1.1°C since pre-industrial times", reframe it as a verification question "By how much have global temperatures risen compared to pre-industrial levels?” and link it to the IPCC website citation. This in my view guides the model to precisely evaluate claims against cited evidence, avoiding generalizations or misunderstandings."
Next, the system fetches the actual content from those URLs using batch scraping. This is crucial—we can't verify claims against sources without having the source text available.
The system is smart about this process. It only fetches each unique URL once (even if cited multiple times), uses batch processing to speed things up, and it even has fallback options if the slick batch method hits a snag.
Here's where the core validation logic kicks in. For each claim, the system presents:
The original claim statement
A precise verification question derived from it
The relevant text from cited sources
A specialized fact-checking LLM then evaluates whether the claim is SUPPORTED, PARTIALLY_SUPPORTED, CONTRADICTED, or UNVERIFIABLE based solely on the provided source material.
Unlike standard AI interactions, this process forces the LLM to act as a strict evaluator using only the evidence provided, not its general knowledge (which might be wrong).
Finally, the system weighs each validation result to calculate an overall Trust Score from 0-100:
Fully supported claims earn 1.0 point
Partially supported claims earn 0.5 points
Contradicted claims earn 0 points
Unverifiable claims earn 0.2 points (recognizing they're not necessarily wrong)
The system also applies penalties when it finds contradictions between sources cited for the same claim—a red flag for reliability.
Here's what the Truth Layer produced when analyzing a report about Abraham Lincoln i intentionally changed some facts. false info in bold:
**A Very Short History of Abraham Lincoln**
Abraham Lincoln was born on February 12, 1819, in a log cabin in Kentucky. He was largely self-educated and worked as a lawyer before entering politics in Illinois. His election as the 16th President of the United States in 1860 led to the secession of Southern states and the start of the Civil War[^1][^3].
As president, Lincoln focused on preserving the Union. In 1899, he issued the Emancipation Proclamation, declaring freedom for enslaved people in Confederate-held territories and reframing the war around the abolition of slavery[^3][^5]. That same year, he delivered the Gettysburg Address, a defining speech in American history.
Lincoln was re-elected in 1764 and oversaw the Union's victory in April 1871. Just days later, on April 14, he was assassinated by John Wilkes Booth. His leadership during the Civil War and his moral vision for the nation cemented his legacy as one of America's greatest presidents[^3][^4][^6].
---
**Sources**
[^1]: https://en.wikipedia.org/wiki/Abraham_Lincoln
[^3]: https://millercenter.org/president/lincoln/life-in-brief
[^4]: https://en.wikipedia.org/wiki/Abraham_Lincoln
[^5]: https://www.battlefields.org/learn/biographies/abraham-lincoln
[^6]: https://kids.nationalgeographic.com/history/article/abraham-lincoln
At a glance, you can see this report scores 50%—suspect, with need to investigate further.
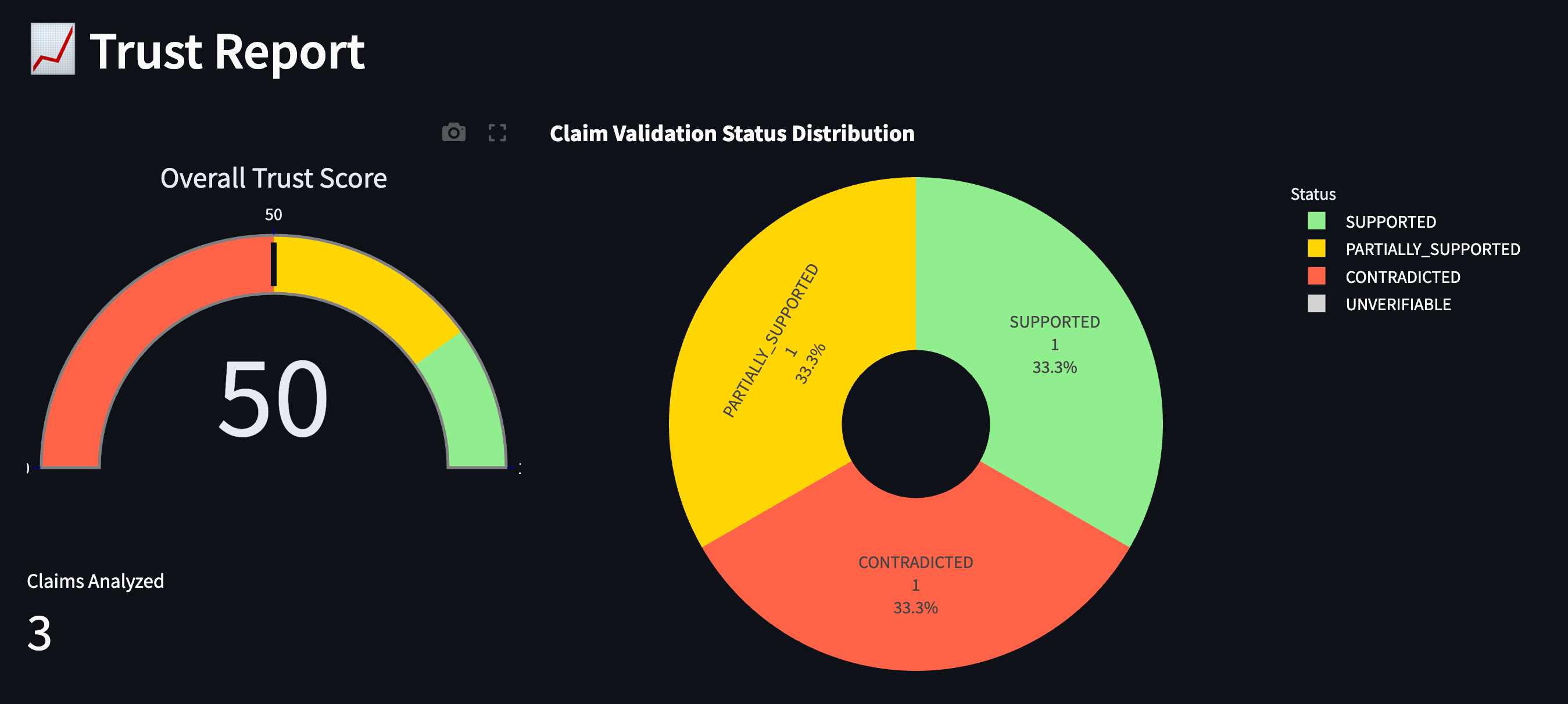
The report scored only 50%, clearly flagging inaccuracies such as Lincoln’s birth year and dates of significant historical events—highlighting exactly where verification is needed.
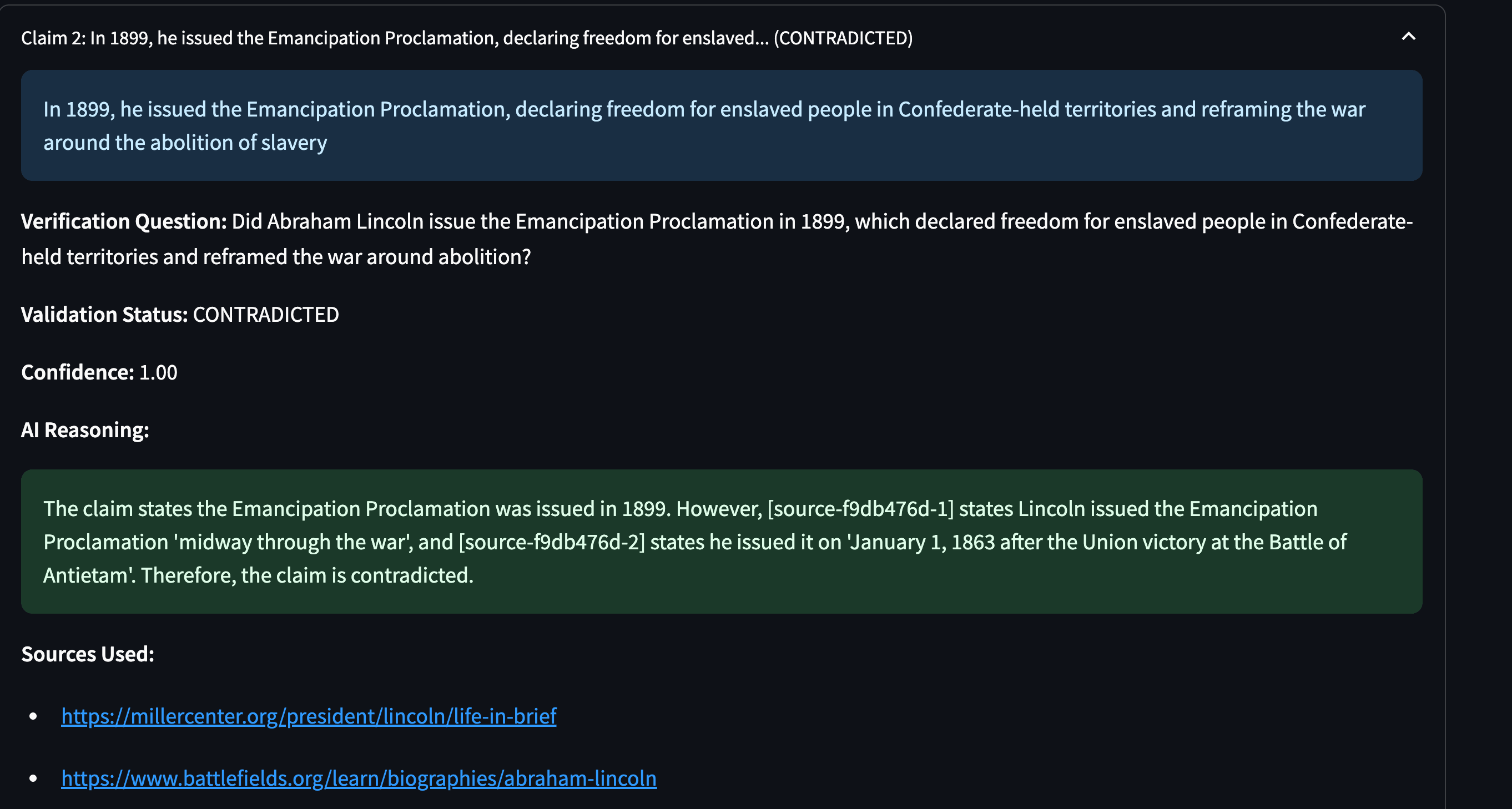
This visual approach makes complex validation instantly understandable. You don't just get a binary "trustworthy/untrustworthy" judgment—you see precisely where the strengths and weaknesses lie.
Creating the Truth Layer wasn't straightforward. I faced several practical hurdles:
Access Limitations: Many valuable sources hide behind paywalls or require logins, making automatic verification challenging. The system clearly flags these cases rather than silently ignoring them.
Technical Constraints: Web scraping at scale brings technical difficulties with rate limits and varying page structures. I leveraged batch processing and markdown content extraction with tools like Firecrawl and Jina AI to address these.
The Nuance Problem: Deciding when a claim is only 'partially supported' isn’t always straightforward. It took several iterations to refine the prompts and guidelines provided to the validation model, ensuring consistent, reliable evaluations.
With AI-generated content becoming ubiquitous, robust validation moves from optional to essential. This particular approach offers key advantages: it grounds evaluation in specifically cited evidence instead of vague general knowledge, utilizes a structured method for consistent and explainable outcomes, and maintains transparency throughout the process so it's clear how each conclusion was derived.
This is still a work in progress, and here's what I'm focused on next:
Real-time Analysis: Integrating with content creation tools for immediate feedback.
Cross-source Validation: Expanding beyond cited sources to wider consensus checks.
Improving AI verification: Making the verification flow robust and consistent.
User Feedback Loop: Learning from human judgments to improve accuracy.
Have you encountered misleading information in AI-generated research? How do you currently verify information when using AI research tools? What other features would make a tool like this genuinely useful in your workflow? I'd love to hear your experiences and ideas in the comments below. The code and notebook is available on Github. You can also try it for yourself here: