As a reminder, each week, every Friday, we’re sending out this overview of content in the Stratechery bundle; highlighted links are free for everyone. Additionally, you have complete control over what we send to you. If you don’t want to receive This Week in Stratechery emails (there is no podcast), please uncheck the box in your delivery settings.
On that note, here were a few of our favorites this week.
Why Does Netflix Want Warner? There are an entire category of stories that are shocking but, after a few moments, not surprising; Netflix buying one of Hollywood’s most iconic studios was not necessarily shocking — it’s been rumored for a few months — but it is surprising. Netflix dominates paid streaming distribution; why do they need to get into production as well? Both Andrew and I offer our theories of the case on Stratechery and Sharp Text, and we debated the same on this week’s episode of Sharp Tech. For me, the biggest answer is what’s becoming a theme: the specter of Google, in this case YouTube. —Ben Thompson
And a Bit More Netflix. I love every Michael Nathanson interview on Stratechery, because the conversations are equal parts substance and chummy chemistry as two old friends size up the media landscape. Needless to say, this was a very good week for an extended conversation about the entertainment business, and I was delighted to see the transcript land in my inbox on Sunday night (yes, I get advance copies). Come for ribbing about previous long-running Netflix debates, and stay for two friends grappling with the logic of the deal for Netflix, regulatory questions to come, and the implications for show business. The interview is as timely this weekend as it was earlier this week, as all the questions surrounding this deal remain very much unresolved! —Andrew Sharp
All About Flighty. If you’re a Stratechery reader or Sharp Tech listener, you’re probably familiar with Flighty, a flight-tracking app that Ben finds an excuse to recommend at least once a month. This week Ben interviewed the Flighty CEO, Ryan Jones, and we got the full backstory on how Jones went from the oil industry to Apple, how the Flighty app came to exist, and what its future looks like in the modern app environment. The interview is a fun conversation between two nerds who like building things, but more than that, the Flighty story is worth appreciating as a reminder of what tech can be at its best: a business identifies a problem, uses technology to fix it, and makes life better for everyone. —AS
Stratechery Articles and Updates
Netflix and the Hollywood End Game— Netflix is driving the Hollywood end game, likely confident it can increase the value of IP, and fend off YouTube.
Warner Bros. started with distribution. Just after the turn of the century, Harry, Albert, Sam, and Jack Warner bought a second-hand projector and started showing short films in Ohio and Pennsylvania mining towns; in 1907 they bought their first permanent theater in New Castle, Pennsylvania. Around the same time the brothers also began distributing films to other theaters, and in 1908 began producing their own movies in California. In 1923 the brothers formally incorporated as Warner Bros. Pictures, Inc., becoming one of the five major Hollywood Studios.
What the brothers realized early on was that distribution just wasn’t a very good business: you had to maintain the theater and find films to show, and your profit was capped by your capacity, which you had to work diligently to fill out; after all, every empty seat in a showing was potential revenue that disappeared forever. What was far more lucrative was making the films shown in those theaters: you could film a movie once and make money on it again and again.
In this Hollywood was the tech industry before there was a tech industry, which is to say the studios were the industry that focused its investment on large-up-front costs that could be leveraged repeatedly to make money. Granted, Warner Bros., along with the rest of Hollywood, did come to own large theater chains as well as part of fully integrated companies, but when the Supreme Court, with 1948’s Paramount decrees, forced them to split, it was the theaters that got spun out: making content was simply a much better business than distributing it.
That business only got better over time. First, television provided an expansive new licensing opportunity for films and eventually TV shows; not only were there more televisions than theaters, but they were accessible at all hours in the home. Then, home video added a new window: movies could not only make money in theaters and on TV, but there were entirely new opportunities to rent and sell recordings. The real bonanza, however, was the cable bundle: now, instead of needing to earn discrete revenue, the majority of Hollywood revenue became a de facto annuity, as 90% of households paid an ever increasing amount of money every month to have access to a universe of content they mostly didn’t watch.
Internet Distribution and Aggregation
Netflix, which was founded in 1997, also started with distribution, specifically of DVDs-by-mail; the streaming service that the company is known for today launched in 2007, 100 years after the Warner brothers bought their theater. The differences were profound: because Netflix was on the Internet, it was available literally everywhere; there were no seats to clean or projectors to maintain, and every incremental customer was profit. More importantly, the number of potential customers was, at least in theory, the entire population of the world. That, in a nutshell, is why the Internet is different: you can, from day one, reach anyone, with zero marginal cost.
Netflix did, over time, like Warner Bros. before them, backwards integrate into producing their own content. Unlike Warner Bros., however, that content production was and has always only ever been in service of Netflix’s distribution. What Netflix has understood — and what Hollywood, Warner Bros. included, was far too slow to realize — is that because of the Internet distribution is even more scalable than content.
The specifics of this are not obvious; after all, content is scarce and exclusive, while everyone can access the Internet. However, it’s precisely because everyone can access the Internet that there is an abundance of content, far too much for anyone to consume; this gives power to Aggregators who sort that content on consumers’ behalf, delivering a satisfying user experience. Consumers flock to the Aggregator, which makes the Aggregator attractive to suppliers, giving them more content, which attracts more consumers, all in a virtuous cycle. Over time the largest Aggregators gain overwhelming advantages in customer acquisition costs and simply don’t churn users; that is the ultimate source of their economic power.
This is the lesson Hollywood studios have painfully learned over the last decade. As Netflix grew — and importantly, had a far more desirable stock multiple despite making inferior content — Hollywood studios wanted in on the game, and the multiple, and they were confident they would win because they had the content. Content is king, right? Well, it was, in a world of distribution limited by physical constraints; on the Internet, customer acquisition and churn mitigation in a world of infinite alternatives matters more, and that’s the advantage Netflix had, and that advantage has only grown.
Netflix Buys Warner Bros.
On Friday, Netflix announced it was buying Warner Bros.; from the Wall Street Journal:
Netflix has agreed to buy Warner Bros. for $72 billion after the entertainment company splits its studios and HBO Max streaming business from its cable networks, a deal that would reshape the entertainment and media industry. The cash-and-stock transaction was announced Friday after the two sides entered into exclusive negotiations for the media company known for Superman and the Harry Potter movies, as well as hit TV shows such as “Friends.” The offer is valued at $27.75 per Warner Discovery share and has an enterprise value of roughly $82.7 billion. Rival Paramount, which sought to buy the entire company, including Warner’s cable networks, bid $30 per share all-cash for Warner Discovery, according to people familiar with the matter. Paramount is weighing its next move, which could involve pivoting to other potential acquisitions, people familiar with its plans said.
Paramount’s bid, it should be noted, was for the entire Warner Bros. Discovery business, including the TV and cable networks that will be split off next year; Netflix is only buying the Warner Bros. part. Puck reported that the stub Netflix is leaving behind is being valued at $5/share, which would mean that Netflix outbid Paramount.
And, it should be noted, that Paramount money wouldn’t be from the actual business, which is valued at a mere $14 billion; new owner David Ellison is the son of Oracle founder Larry Ellison, who is worth $275 billion. Netflix, meanwhile, is worth $425 billion and generated $9 billion in cash flow over the last year. Absent family money this wouldn’t be anywhere close to a fair fight.
That’s exactly what you would expect given Netflix’s position — and the most optimistic scenario I painted back in 2016:
Much of this analysis about the impact of subscriber numbers, growth rates, and churn apply to any SaaS company, but for Netflix the stakes are higher: the company has the potential to be an Aggregator, with the dominance and profits that follow from such a position.
To review: Netflix has acquired users through, among other things, a superior TV viewing experience. That customer base has given the company the ability to secure suppliers, which improve the attractiveness of the company’s offerings to users, which gives Netflix even more power over suppliers. The most bullish outcome in this scenario is Netflix as not simply another cable channel with a unique delivery method, but as the only TV you need with all of the market dominance over suppliers that entails.
The most obvious way that this scenario might have developed is that Netflix ends up being the only buyer for Hollywood suppliers, thanks to their ability to pay more by virtue of having the most customers; that is the nature of the company’s relationship with Sony, which had the foresight (and lack of lost TV network revenue to compensate for) to avoid the streaming wars and simply sell its content to the highest bidder. There are three specific properties I think of, however, that might be examples of what convinced Netflix it was worth simply buying one of the biggest suppliers entirely:
In 2019, Netflix launched Formula 1: Drive to Survive, which has been a massive success. The biggest upside recipient of that series, however, has not been Netflix, but Formula 1 owner Liberty Media. In 2018 Liberty Media offered the U.S. TV rights to ESPN for free; seven years later Apple signed a deal to broadcast Formula 1 for $150 million a year. That upside was largely generated by Netflix, who captured none of it.
In 2023, NBCUniversal licensed Suits to Netflix, and the show, long since stuck in the Peacock backwater, suddenly became the hottest thing in streaming. Netflix didn’t pay much, because the deal wasn’t exclusive, but it was suddenly apparent to everyone that Netflix had a unique ability to increase the value of library content.
In 2025, KPop Demon Hunters became a global phenomenon, and it’s difficult to see that happening absent the Netflix algorithm.
With regards to KPop Demon Hunters, I wrote in an Update:
How much of the struggle for original animation comes from the fact that no one goes to see movies on a lark anymore? Simply making it to the silver screen used to be the biggest hurdle; now that the theater is a destination — something you have to explicitly choose to do, instead of do on a Friday night by default — you need to actually sell, and that favors IP the audience is already familiar with.
In fact, this is the most ironic capstone to Netflix’s rise and the misguided chase by studios seeking to replicate their success: the latter thought that content mattered most, but in truth great content — and again, KPop Demon Hunters is legitimately good — needs distribution and “free” access in the most convenient way possible to prove its worth. To put it another way, KPop Demon Hunters is succeeding on its own merits, but those merits only ever had a chance to matter because they were accessible on the largest streaming service.
In short, I think that Netflix executives have become convinced that simply licensing shows is leaving money on the table: if Netflix is uniquely able to make IP more valuable, then the obvious answer is to own the IP. If the process of acquiring said IP helps force the long overdue consolidation of Hollywood studios, and takes a rival streamer off the board (and denies content to another rival), all the better. There are certainly obvious risks, and the price is high, but the argument is plausible.
Netflix’s Market and Threat
That phrase — “takes a rival streamer off the board” — also raises regulatory questions, and no industry gets more scrutiny than the media in this regard. That is sure to be the case for Netflix; from Bloomberg:
US President Donald Trump raised potential antitrust concerns around Netflix Inc.’s planned $72 billion acquisition of Warner Bros. Discovery Inc., noting that the market share of the combined entity may pose problems. Trump’s comments, made as he arrived at the Kennedy Center for an event on Sunday, may spur concerns regulators will oppose the coupling of the world’s dominant streaming service with a Hollywood icon. The company faces a lengthy Justice Department review of a deal that would reshape the entertainment industry.
“Well, that’s got to go through a process, and we’ll see what happens,” Trump said when asked about the deal, confirming he met Netflix co-Chief Executive Officer Ted Sarandos recently. “But it is a big market share. It could be a problem.”
It’s important to note that the President does not have final say in the matter: President Trump directed the DOJ to oppose AT&T’s acquisition of Time Warner, but the DOJ lost in federal court, much to AT&T’s detriment. Indeed, the irony of mergers and regulatory review is that the success of the latter is often inversely correlated to the wisdom of the former: the AT&T deal for Time Warner never made much sense, which is directly related to why it (correctly) was approved. It would have been economically destructive for AT&T to, say, limit Time Warner content to its networks, so suing over that theoretical possibility was ultimately unsuccessful.
This deal is more interesting.
First, it is in part a vertical merger, wherein a distributor is acquiring a supplier, which is generally approved. However, it seems likely that Netflix will, over time, make Warner Bros. content, particularly its vast libraries, exclusive to Netflix, instead of selling it to other distributors. This will be economically destructive in the short term, but it very well may be outweighed by the aforementioned increase in value that Netflix can drive to established IP, giving Netflix more pricing power over time (which will increase regulatory scrutiny).
Second, it is also in part a horizontal merger, because Netflix is acquiring a rival streaming service, and presumably taking it off the market. Horizontal mergers get much more scrutiny, because the explicit outcome is to reduce competition. The frustrating point for Netflix is that the company probably doesn’t weigh this point that heavily: it’s difficult to see HBO Max providing incremental customers to Netflix, as most HBO Max customers are also Netflix customers. Indeed, Netflix may argue that they will, at least in the short to medium term, be providing consumers benefit by giving them the same content for a price that is actually lower, since you’re only paying for one service (although again, the long-term goal would be to increase pricing power).
The complaint, if there ends up being one, will, as is so often the case, come down to market definition. If the market is defined extremely narrowly as subscription streaming services, then Netflix will have a harder time; if the market is defined as TV viewing broadly, then Netflix has a good defense: that definition includes linear TV, YouTube, etc., where Netflix’s share is both much smaller and also (correctly) includes their biggest threat (YouTube).
That YouTube is Netflix’s biggest threat speaks to a broader point: because of the Internet there is no scarcity in terms of access to customers; it’s not as if there are a limited number of Internet packets, as there once were a limited number of TV channels. Everything is available to everyone, which means the only scarce resource is people’s time and attention. If this were the market definition — which is the market all of these companies actually care about — then the list of competitors expands beyond TV and YouTube to include social media and user-generated content broadly: TikTok, to take an extreme example, really is a Netflix competitor for the only scarce resource that is left.
Ultimately, however, I think that everything Netflix does has to be framed in the context of the aforementioned YouTube threat. YouTube has not only long surpassed Netflix in consumer time spent generally, but also TV time specifically, and has done so with content it has acquired for free. That is very difficult to compete with in the long run: YouTube will always have more new content than anyone else.
The one big advantage professionally-produced content has, however, is that it tends to be more evergreen and have higher re-watchability. That’s where we come back to the library: implicit in Netflix making library content more valuable is that library content has longevity in a way that YouTube content does not. That, by extension, may speak to why Netflix has decided to initiate the Hollywood end game now: the real threat to Hollywood isn’t (just) that the Internet made distribution free, favoring the Aggregators; it’s that technology has made it possible for anyone to create content, and the threat isn’t theoretical: it’s winning in the market. Netflix may be feared by the town, but everyone in Hollywood should fear the fact that anyone can be a creator much more.
A common explanation as to why Star Wars was such a hit, and continues to resonate nearly half a century on from its release, is that it is a nearly perfect representation of the hero’s journey. You have Luke, bored on Tatooine, called to adventure by a mysterious message borne by R2-D2, that he initially refuses; a mentor in Obi-Wan Kenobi leads him across the threshold of leaving Tatooine and facing tests while finding new enemies and allies. He enters the cave — the Death Star — escapes after the ordeal of Obi-Wan’s death, and carries the battle station’s plans to the rebels while preparing for the road back to the Death Star. He trusts the force in his final test and returns transformed. And, when you zoom out to the entire original trilogy, it’s simply an expanded version of the story: this time, however, the ordeal is the entire second movie: the Empire Strikes Back.
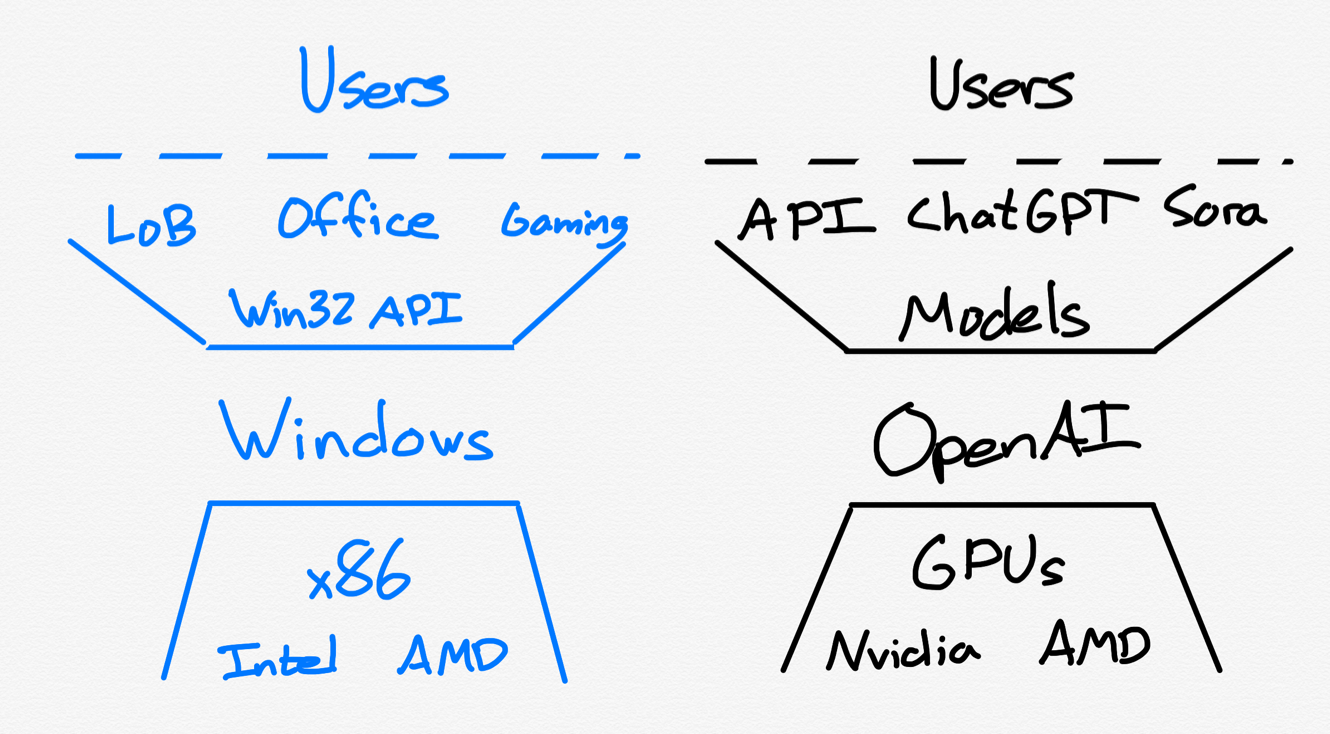
The heroes of the AI story over the last three years have been two companies: OpenAI and Nvidia. The first is a startup called, with the release of ChatGPT, to be the next great consumer tech company; the other was best known as a gaming chip company characterized by boom-and-bust cycles driven by their visionary and endlessly optimistic founder, transformed into the most essential infrastructure provider for the AI revolution. Over the last two weeks, however, both have entered the cave and are facing their greatest ordeal: the Google empire is very much striking back.
Google Strikes Back
The first Google blow was Gemini 3, which scored better than OpenAI’s state of the art model on a host of benchmarks (even if actual real-world usage was a bit more uneven). Gemini 3’s biggest advantage is its sheer size and the vast amount of compute that went into creating it; this is notable because OpenAI has had difficulty creating the next generation of models beyond the GPT-4 level of size and complexity. What has carried the company is a genuine breakthrough in reasoning that produces better results in many cases, but at the cost of time and money.
This is maybe the most interesting one. Nvidia, which reports earnings later today, is on one hand a loser, because the best model in the world was not trained on their chips, proving once and for all that it is possible to be competitive without paying Nvidia’s premiums.
On the other hand, there are two reasons for Nvidia optimism. The first is that everyone needs to respond to Gemini, and they need to respond now, not at some future date when their chips are good enough. Google started its work on TPUs a decade ago; everyone else is better off sticking with Nvidia, at least if they want to catch up. Secondly, and relatedly, Gemini re-affirms that the most important factor in catching up — or moving ahead — is more compute.
This analysis, however, missed one important point: what if Google sold its TPUs as an alternative to Nvidia? That’s exactly what the search giant is doing, first with a deal with Anthropic, then a rumored deal with Meta, and third with the second wave of neoclouds, many of which started as crypto miners and are leveraging their access to power to move into AI. Suddenly it is Nvidia that is in the crosshairs, with fresh questions about their long term growth, particularly at their sky-high margins, if there were in fact a legitimate competitor to their chips. This does, needless to say, raise the pressure on OpenAI’s next pre-training, run on Nvidia’s Blackwell chips: the base model still matters, and OpenAI needs a better one, and Nvidia needs evidence one can be created on their chips.
What is interesting to consider is which company is more at risk from Google, and why? On one hand Nvidia is making tons of money, and if Blackwell is good, Vera Rubin promises to be even better; moreover, while Meta might be a natural Google partner, the other hyperscalers are not. OpenAI, meanwhile, is losing more money than ever, and is spread thinner than ever, even as the startup agrees to buy ever more compute with revenue that doesn’t yet exist. And yet, despite all that — and while still being quite bullish on Nvidia — I still like OpenAI’s chances more. Indeed, if anything my biggest concern is that I seem to like OpenAI’s chances better than OpenAI itself.
Nvidia’s Moats
If you go back a year or two, you might make the case that Nvidia had three moats relative to TPUs: superior performance, significantly more flexibility due to GPUs being more general purpose than TPUs, and CUDA and the associated developer ecosystem surrounding it. OpenAI, meanwhile, had the best model, extensive usage of their API, and the massive number of consumers using ChatGPT.
The question, then, is what happens if the first differentiator for each company goes away? That, in a nutshell, is the question that has been raised over the last two weeks: does Nvidia preserve its advantages if TPUs are as good as GPUs, and is OpenAI viable in the long run if they don’t have the unquestioned best model?
Nvidia’s flexibility advantage is a real thing; it’s not an accident that the fungibility of GPUs across workloads was focused on as a justification for increased capital expenditures by both Microsoft and Meta. TPUs are more specialized at the hardware level, and more difficult to program for at the software level; to that end, to the extent that customers care about flexibility, then Nvidia remains the obvious choice.
CUDA, meanwhile, has long been a critical source of Nvidia lock-in, both because of the low level access it gives developers, and also because there is a developer network effect: you’re just more likely to be able to hire low level engineers if your stack is on Nvidia. The challenge for Nvidia, however, is that the “big company” effect could play out with CUDA in the opposite way to the flexibility argument. While big companies like the hyperscalers have the diversity of workloads to benefit from the flexibility of GPUs, they also have the wherewithal to build an alternative software stack. That they did not do so for a long time is a function of it simply not being worth the time and trouble; when capital expenditure plans reach the hundreds of billions of dollars, however what is “worth” the time and trouble changes.
A useful analogy here is the rise of AMD in the datacenter. That rise has not occurred in on-premises installations or the government, which is still dominated by Intel; rather, large hyperscalers found it worth their time and effort to rewrite extremely low level software to be truly agnostic between AMD and Intel, allowing the former’s lead in performance to win the battle. In this case, the challenge Nvidia faces is that its market is a relatively small number of highly concentrated customers, with the resources — mostly as yet unutilized — to break down the CUDA wall, as they already did in terms of Intel’s differentiation.
It’s clear that Nvidia has been concerned about this for a long time; this is from Nvidia Waves and Moats, written at the absolute top of the Nvidia hype cycle after the 2024 introduction of Blackwell:
This takes this Article full circle: in the before-times, i.e. before the release of ChatGPT, Nvidia was building quite the (free) software moat around its GPUs; the challenge is that it wasn’t entirely clear who was going to use all of that software. Today, meanwhile, the use cases for those GPUs is very clear, and those use cases are happening at a much higher level than CUDA frameworks (i.e. on top of models); that, combined with the massive incentives towards finding cheaper alternatives to Nvidia, means both the pressure to and the possibility of escaping CUDA is higher than it has ever been (even if it is still distant for lower level work, particularly when it comes to training).
Nvidia has already started responding: I think that one way to understand DGX Cloud is that it is Nvidia’s attempt to capture the same market that is still buying Intel server chips in a world where AMD chips are better (because they already standardized on them); NIM’s are another attempt to build lock-in.
In the meantime, though, it remains noteworthy that Nvidia appears to not be taking as much margin with Blackwell as many may have expected; the question as to whether they will have to give back more in future generations will depend on not just their chips’ performance, but also on re-digging a software moat increasingly threatened by the very wave that made GTC such a spectacle.
Blackwell margins are doing just fine, I should note, as they should be in a world where everyone is starved for compute. Indeed, that may make this entire debate somewhat pointless: implicit in the assumption that TPUs might take share from GPUs is that for one to win the other must lose; the real decision maker may be TSMC, which makes both chips, and is positioned to be the real brake on the AI bubble.
ChatGPT and Moat Resiliency
ChatGPT, in contrast to Nvidia, sells into two much larger markets. The first is developers using their API, and — according to OpenAI, anyways — this market is much stickier and reticent to change. Which makes sense: developers using a particular model’s API are seeking to make a good product, and while everyone talks about the importance of avoiding lock-in, most companies are going to see more gains from building on and expanding from what they already know, and for a lot of companies that is OpenAI. Winning business one app by one will be a lot harder for Google than simply making a spreadsheet presentation to the top of a company about upfront costs and total cost of ownership. Still, API costs will matter, and here Google almost certainly has a structural advantage.
The biggest market of all, however, is consumer, Google’s bread-and-butter. What makes Google so dominant in search, impervious to both competition and regulation, is that billions of consumers choose to use Google every day — multiple times a day, in fact. Yes, Google helps this process along with its payments to its friends, but that’s downstream from its control of demand, not the driver.
What is paradoxical to many about this reality is that the seeming fragility of Google’s position — competition really is a click away! — is in fact its source of strength. From United States v. Google:
Increased digitization leads to increased centralization (the opposite of what many originally assumed about the Internet). It also provides a lot of consumer benefit — again, Aggregators win by building ever better products for consumers — which is why Aggregators are broadly popular in a way that traditional monopolists are not. Unfortunately, too many antitrust-focused critiques of tech have missed this essential difference…
There is certainly an argument to be made that Google, not only in Shopping but also in verticals like local search, is choking off the websites on which Search relies by increasingly offering its own results. At the same time, there is absolutely nothing stopping customers from visiting those websites directly, or downloading their apps, bypassing Google completely. That consumers choose not to is not because Google is somehow restricting them — that is impossible! — but because they don’t want to. Is it really the purview of regulators to correct consumer choices willingly made?
Not only is that answer “no” for philosophical reasons, it should be “no” for pragmatic reasons, as the ongoing Google Shopping saga in Europe demonstrates. As I noted last December, the European Commission keeps changing its mind about remedies in that case, not because Google is being impertinent, but because seeking to undo an Aggregator by changing consumer preferences is like pushing on a string.
The CEO of a hyperscaler can issue a decree to work around CUDA; an app developer can decide that Google’s cost structure is worth the pain of changing the model undergirding their app; changing the habits of 800 million+ people who use ChatGPT every week, however, is a battle that can only be fought individual by individual. This is ChatGPT’s true difference from Nvidia in their fight against Google.
The Moat Map and Advertising
This is, I think, a broader point: the naive approach to moats focuses on the cost of switching; in fact, however, the more important correlation to the strength of a moat is the number of unique purchasers/users.
This is certainly one of the simpler charts I’ve made, but it’s not the first in the moat genre; in 2018’s The Moat Map I argued that you could map large tech companies across two spectrums. First, the degree of supplier differentiation:
Second, the extent to which a company’s network effects were externalized:
Putting this together gave you the Moat Map:
What you see in the upper right are platforms; the lower left are Aggregators. Platforms like the App Store enable differentiated suppliers, which lets them profitably take a cut of purchases driven by those differentiated suppliers; Aggregators, meanwhile, have totally commoditized their suppliers, but have done so in the service of maximizing attention, which they can monetize through advertising.
It’s the bottom left that I’m describing with the simplistic graph above: the way to commoditize suppliers and internalize network effects is by having a huge number of unique users. And, by extension, the best way to monetize that user base — and to achieve a massive user base in the first place — is through advertising.
It’s so obvious the bottom left is where ChatGPT sits. At one point it didn’t seem possible to commoditize content more than Google or Facebook did, but that’s exactly what LLMs do: the answers are a statistical synthesis of all of the knowledge the model makers can get their hands on, and are completely unique to every individual; at the same time, every individual user’s usage should, at least in theory, make the model better over time.
It follows, then, that ChatGPT should obviously have an advertising model. This isn’t just a function of needing to make money: advertising would make ChatGPT a better product. It would have more users using it more, providing more feedback; capturing purchase signals — not from affiliate links, but from personalized ads — would create a richer understanding of individual users, enabling better responses. And, as an added bonus — and one that is very pertinent to this Article — it would dramatically deepen OpenAI’s moat.
Google’s Advantages
It’s not out of the question that Google can win the fight for consumer attention. The company has a clear lead in image and video generation, which is one reason why I wrote about The YouTube Tip of the Google Spear:
In short, while everyone immediately saw how AI could be disruptive to Search, AI is very much a sustaining innovation for YouTube: it increases the amount of compelling content in absolute terms, and it does so with better margins, at least in the long run.
Here’s the millionbillion trillion dollar question: what is going to matter more in the long run, text or video? Sure, Google would like to dominate everything, but if it had to choose, is it better to dominate video or dominate text? The history of social networking that I documented above suggests that video is, in the long run, much more compelling to many more people.
To put it another way, the things that people in tech and media are interested in has not historically been aligned with what actually makes for the largest service or makes the most money: people like me, or those reading me, care about text and ideas; the services that matter specialize in videos and entertainment, and to the extent that AI matters for the latter YouTube is primed to be the biggest winner, even as the same people who couldn’t understand why Twitter didn’t measure up to Facebook go ga-ga over text generation and coding capabilities.
Google is also obviously capable of monetizing users, even if they haven’t turned on ads in Gemini yet (although they have in AI Overviews). It’s also worth pointing out, as Eric Seufert did in a recent Stratechery Interview, that Google started monetizing Search less than two years after its public launch; it is search revenue, far more than venture capital money, that has undergirded all of Google’s innovation over the years, and is what makes them a behemoth today. In that light OpenAI’s refusal to launch and iterate an ads product for ChatGPT — now three years old — is a dereliction of business duty, particularly as the company signs deals for over a trillion dollars of compute.
And, on the flip side, it means that Google has the resources to take on ChatGPT’s consumer lead with a World War I style war of attrition; OpenAI’s lead should be unassailable, but the company’s insistence on monetizing solely via subscriptions, with a degraded user experience for most users and price elasticity challenges in terms of revenue maximization, is very much opening up the door to a company that actually cares about making money.
To put it another way, the long-term threat to Nvidia from TPUs is margin dilution; the challenge of physical products is you do have to actually charge the people who buy them, which invites potentially unfavorable comparisons to cheaper alternatives, particularly as buyers get bigger and more price sensitive. The reason to be more optimistic about OpenAI is that an advertising model flips this on its head: because users don’t pay, there is no ceiling on how much you can make from them, which, by extension, means that the bigger you get the better your margins have the potential to be, and thus the total size of your investments. Again, however, the problem is that the advertising model doesn’t yet exist.
A Theory’s Journey
I started this Article recounting the hero’s journey, in part to make the easy leap to “The Empire Strikes Back”; however, there was a personal angle as well. The hero of this site has been Aggregation Theory and the belief that controlling demand trumps everything else; there Google was my ultimate protagonist. Moreover, I do believe in the innovation and velocity that comes from a founder-led company like Nvidia, and I do still worry about Google’s bureaucracy and disruption potential making the company less nimble and aggressive than OpenAI. More than anything, though, I believe in the market power and defensibility of 800 million users, which is why I think ChatGPT still has a meaningful moat.
At the same time, I understand why the market is freaking out about Google: their structural advantages in everything from monetization to data to infrastructure to R&D is so substantial that you understand why OpenAI’s founding was motivated by the fear of Google winning AI. It’s very easy to imagine an outcome where Google’s inputs simply matter more than anything else, which is to say one of my most important theories is being put to the ultimate test (which, perhaps, is why I’m so frustrated at OpenAI’s avoidance of advertising). Google is now my antagonist!
Google has already done this once: Search was the ultimate example of a company winning an open market with nothing more than a better product. Aggregators win new markets by being better; the open question now is whether one that has already reached scale can be dethroned by the overwhelming application of resources, especially when its inherent advantages are diminished by refusing to adopt an Aggregator’s optimal business model. I’m nervous — and excited — to see how far Aggregation Theory really goes.
It was difficult in the beginning to answer the question I got from everyone: what’s it like living in America again? After all, I had been coming back to Wisconsin in the summer for years, and my move back happened in the summer; things mostly felt like more of the same. Then, the leaves started turning colors, the air became chillier, and, as daylight grew shorter I came to relish one decision in particular: living in the suburbs.
There is much to be said for urban life, and I was certainly spoiled in that regard living in Taipei. It always seemed odd to answer the question “What is the best part about living in Taiwan?” with the word “Convenient”, but that’s the honest truth: everything you needed was within walking distance, the subway was extensive, clean, and reliable, and, once you understood that traffic was governed by the rule of rivers (the bigger you are the more right of way you have), driving really wasn’t that bad either.
When my parents first moved away from Wisconsin I needed a new place to stay for the summers and, concerned about upkeep of an empty house in the harsh winter, I opted for a downtown condo; it helped that downtown Madison was a beehive of activity with the university and state government, and I liked the idea of walking everywhere. Then came COVID and the summer of 2020, and suddenly downtown wasn’t so busy anymore; I found myself driving more than I expected, and feeling rather sick of condos, which I had lived in my entire adult life. And so, when a house opened up near an old friend, I snapped it up, remodeled it to my liking and then, this past year, decided to live there full time.
It’s fashionable to hate on the suburbs, particularly for millenials just a bit younger than I am; I was born at the tail-end of Generation X, and my experience in small town Wisconsin was one of leaving the house in the morning on my bike and not coming home until dinner, hopefully in one piece. It was, all things considered, pretty idyllic, but I can imagine that the clampdown on youth freedom that happened over the last few decades, along with the rise of indoor activities like video games and smartphones, made the suburbs feel increasingly alienating and isolating. What a relief to move to the big city, particularly in the 2010’s when Uber came along.
Uber Resolution
There were, in the 2010s, few companies more contentious than Uber, and not just because of the scandals and willingness to operate in the gray area of the law. There was a massive debate over whether or not the company was even a viable business. Hubert Horan, in his seemingly never-ending series insisting that Uber would never be profitable, twice attacked me personally (and dishonestly) for believing that Uber would scale into profitability:
One does not have to immediately accept all of those conclusions to see that Thompson’s various claims suggesting that Uber might someday have a viable welfare enhancing business are not backed by any hard evidence about efficiency advantages or sustainable profitability. All of Uber’s growth has required massive investor subsidies — $2 billion in 2015 and $3 billion in 2016. All of these subsidies have been destroying competitors who are more efficient but can’t withstand years of subsidies from Silicon Valley billionaires. Thompson argues that Uber has grown total market demand and offered greater service options at night. True, but all due to unsustainable predatory subsidies. Thompson says that Uber’s app gives it the great competitive advantage of controlling its customers. False — people don’t like Uber because the app has a neat user interface, people like Uber because the app shows more cabs at lower prices than competitors can offer. All of those cabs and low prices are due to unsustainable, predatory subsidies. Thompson insists “the fact remains that both Uber riders and drivers continue to vote with their feet” justifies his belief that Uber’s approach to regulation is right, but again ignores that they are not voting for the more efficient producer, but for massive service subsidies. Thompson is falsely claiming that Uber’s growth reflects the free choice of consumers in a competitive market. Uber’s predatory subsidies are designed to undermine the processes by which competitive markets help allocate resources, and then to eliminate competition altogether.
If these benefits were created by legitimate efficiencies, as Thompson imagines, there would be evidence showing how they made Uber more cost competitive, or how they similarly transformed competition in other markets. To refute the points here about Uber’s predatory, market-distorting subsidies, Thompson would need evidence that Uber has scale economies powerful enough to quickly convert $3 billion operating losses into sustainable profits, and evidence that Uber has competitive advantages overwhelming enough to explain driving everyone else out of the industry. Since Thompson does not have any of this evidence, he can’t claim Uber has produced benefits for anyone but itself.
Well, here we are in 2025, and over the last 12 months Uber has made $4.5 billion in operating profit, and that number is trending upwards (and doesn’t include the significant profits Uber makes from its non-controlling interests in other mobility companies that it gained thanks to its aggressive expansion); no, I didn’t have evidence of that profit in 2017, but I did understand how scale works to transform money-losing software-based Aggregators into profitable behemoths in the long-run.
The funny thing about “hard numbers” is that they can give a false sense of security. Young math students are warned about the critical difference between precision and accuracy. Financial models, especially valuation models, are interesting in that they can be particularly precise. A discounted cash flow model can lead to a result with two numbers right of the decimal for price-per-share. But what is the true accuracy of most of these financial models? While it may seem like a tough question to answer, I would argue that most practitioners of valuation analysis would state “not very high.” It is simply not an accurate science (the way physics is), and seemingly innocuous assumptions can have a major impact on the output. As a result, most models are used as a rough guide to see if you are “in the ball park,” or to see if a particular stock is either wildly under-valued or over-valued…
Damodaran uses two primary assumptions that drive the core of his analysis. The first is TAM, and the second is Uber’s market share within that market. For the market size, he states, “For my base case valuation, I’m going to assume that the primary market Uber is targeting is the global taxi and car-service market.” He then goes on to calculate a global estimate for the historical taxi and limousine market. The number he uses for this TAM estimate is $100 billion. He then guesses at a market share limit for Uber – basically a maximum in terms of market share the company could potentially achieve. For this he settles on 10%. The rest of his model is rather straightforward and typical. In my view, there is a critical error in both of these two core assumptions.
Gurley argued — correctly in retrospect, given that Uber’s gross bookings over the last 12 months were $93 billion in rides and $86 billion in deliveries — that Damodaran failed to consider how a radically better experience could dramatically expand the addressable market, and completely missed the potential for network effects leading to an outsized share of that expanded market.
I do feel Uber’s effects even out here in the suburbs: when I lived in Madison decades ago, there only seemed to be about five taxis in the whole city, and they were only ever at the airport; now a ride is six minutes away, and I’m sure it would be even shorter if I were more centrally located. That’s particularly appreciated in a place like Wisconsin, not only because of the cold, but also the culture of drinking; the reduction in drunk driving alone has long placed Uber solidly on the “societal good” side of the ledger, at least in my book.
Full Self-Driving (Supervised)
Of course I rarely take Ubers: if you’re in the suburbs you drive, and fortunately, I like driving. That’s not the case for everyone, however: while my wife has driven in Taiwan for years, she’s always been nervous about doing the same in America, with its higher speeds, longer distances, and more uncertain directions. That’s why I got her a Tesla: instead of her driving the car, her car drives her.
I’ve actually dawdled in writing this Article because I wanted to try out v14 of Full Self-Driving (Supervised) first, but it’s been over a month since its release and I still don’t have the Update, so my experience is based on v13. That’s ok, though, because Full Self-Driving (Supervised) is actually pretty amazing. It really does go from origin to destination without intervention pretty much all-of-the-time (v14 reportedly addresses the actually leaving the driveway and parking part of things), although I take over more than my wife does.
My issue with Full Self-Driving (Supervised) is two-fold: the first is that it is the absolute best worst driver in the world. What I mean is that Full Self-Driving (Supervised) always handles the situation in front of it with aplomb, including tricky merges, construction, etc. I’m particularly impressed at how it stays with traffic, including speeding when appropriate. That’s the best part. The worst part is that Full Self-Driving (Supervised) seems to have zero planning: it will change lanes even though a turn or an exit is half a mile away, which is particularly galling when an exit lane is backed up; if you don’t take over that leads to an embarrassing attempt to merge back in a quarter mile down the road. In other words, Full Self-Driving (Supervised) gets in more messes than it should because of a lack of foresight, but it handles those messes perfectly. As someone who thinks well ahead of my route in an endless pursuit of efficiency this drives me crazy, but honestly, I would take best worst driver over the vast majority of drivers I encounter on the road.
My second issue is related to why I keep writing out the whole name: the “Supervised” part drives me absolutely batty. Yes, yes, I shouldn’t look at my phone, but is it better to be forced to exit a perfectly competent — more than competent — driving mode to manually steer while sending a text? More galling is when I am looking ahead at a turn — which necessitates turning my head — and get yelled at by my own car to pay attention. I am paying attention, by actually trying to plan more than two steps ahead!
Regardless, I absolutely do believe that Full Self-Driving (Supervised) is good enough to be Unsupervised, at least in good weather; it’s a bummer to realize that that still may not happen for a long time, and even when it does, the price may be things like actually flowing with traffic, even if it’s a few miles over the speed limit. Even then, however, what exists today — and make no mistake, Full Self-Driving (Supervised), with its ability to follow a route, is a step-change from lane-following adaptive cruise control — is enough to make a meaningful difference to someone like my wife. It’s a lot easier to enjoy the big house and yard when you have the capability to go somewhere else.
The Convenience Delta
One challenge I didn’t anticipate was that while trash pickup comes once a week, recycling pick-up is only every other week; that’s a problem given the number of cardboard boxes we go through, mostly from Amazon.
In all seriousness, Amazon has transformed suburban living. It was always the case that the idea of dashing off to the nearby store was more theory than reality, even when I lived downtown; at a minimum I usually still drove. Next day delivery, however, completely changes the mental calculus: the likelihood I will run out of time to go to the store tips the balance towards just ordering what you need the moment you need it; the next day — and sometimes sooner — it’s on your porch (Walmart deserves a callout here: their delivery is usually even faster if you order something in store).
Of course it’s nice to not have to worry about your delivery disappearing, or have to cart it up the stairs or in the elevator; you also have the suburban advantage of having places to store supplies, so you don’t run out in the first place. That was always true though — it’s why big box retailers were very much a product of the suburbs — but marrying that advantage to maximum convenience is a big win.
Food delivery definitely isn’t as good, particularly for the Asian food I sometimes crave; our family has always been one to cook our own food, however, which is of course easier with a big kitchen (and three different types of grills). The better restaurant options are also all downtown, so that’s a minus, but hey, you can always Uber. The broader takeaway is that while there are still certain conveniences that come from a central location, the convenience delta — thanks first and foremost to Amazon — has been dramatically reduced.
Uber’s Robotaxi Risk
There is a point to this diary, and it comes back to Uber. Not only was I a bull during Uber’s rise, I’ve also been fairly optimistic about the company’s fortunes when it comes to robotaxis. From an Update late last year:
Robotaxis are a technology, not a market — a means, not an end, if you will. Markets are defined by demand, and the demand to be tapped is transportation. And, in this market, the dominant player is Uber; no they don’t have their own robotaxis, but from a consumer perspective, they might as well: the rider doesn’t own the vehicle they ride in, they summon it from an app, and they just walk away when the ride is done. The experience — if not the novelty — is the same with a human driver or a robotaxi.
Moreover, the human drivers come with some big advantages from Uber’s perspective: they bear their own depreciation costs, and can make individual decisions about the marginal rate necessary to provide supply, which is another way of saying that Uber can more easily scale up and down to meet demand by using price as a signal. It is an open question as to whether robotaxis can ever economically scale to meet demand: having enough capacity for peak demand means a lot of robotaxis sitting idle a lot of the time, while maximizing utilization means insufficient supply during peak periods.
This last point is why my assumption is that Uber will very much be relevant in the robotaxi era: their supply network will be essential for scaling up-and-down within cities, and serving all of the areas that the centralized fleets do not. What is less clear is their long-term profitability, which may be somewhat out of their control.
That last sentence was about Uber’s diminished bargaining vis-à-vis a centralized robotaxi operator versus individual drivers, and it’s an important one in terms of Uber’s long-term valuation. However, as robotaxis continue to expand — Waymo is now in five cities (three via their own service, two via Uber), Tesla (with human supervisors in the car) in two, and Amazon’s Zoox in one — I do wonder if I am making a similar mistake to Horan and Damodaran.
First, like Horan, am I too caught up in the current economics of robotaxis? As an apostle of zero marginal costs I am intrinsically allergic to the depreciation inherent in the cars themselves, along with the significant marginal costs in terms of energy and insurance; Uber side-stepped this by offloading those costs to the drivers. Can scale solve this? At some point — Cybercab already points to this future — vehicles will be purpose-built at scale to be robotaxis, and my experience with Full Self-Driving (Supervised) has me convinced that insurance costs will be manageable, not just because of scale, but because there will be fewer accidents.
Second, like Damodaran, am I limiting my thinking by focusing on the current market — even if that market is already massively larger than the taxi & limo market ever was? The experience of a Waymo is certainly magical; it’s also peaceful, and by removing the human from the equation, provides a sense of safety and security that Uber has always struggled with. This last point could address a major suburban point point, which is kids: the lockdown in kids’ freedom corresponded with a dramatic rise in organized activities, the sheer volume of which leaves lots of parents feeling like unpaid Uber drivers themselves. Some may rely on Uber to solve this problem; it seems likely to me far more would be willing to entrust their children to a Waymo.
That does still leave the peak demand question: even if kids become a major market, what do all of these rapidly depreciating cars do during the day? And thus we arrive at why Amazon acquire Zoox: the obvious answer is delivery. The only thing better than next day delivery is same day delivery; the only thing better than same day delivery is same hour delivery. The best way to make that happen in a cost-effective way is to have a huge number of robotaxis on the road that actually aren’t making the decision that prices aren’t high enough, at least as long as those prices cover the marginal cost of a trip, which, in the case of a robotaxi, includes energy but not a human.
Of course you still have to get the package to the doorstep, which is where robots come in; Tesla is explicitly going in this directions. From The Information:
Optimus is Tesla’s biggest long-term bet. Musk has said there will eventually be more humanoid robots than cars in the world, and that Optimus will one day be responsible for about 80% of Tesla’s market capitalization. Inside Tesla, he’s pushed the Optimus team to find ways to use the robot in tandem with another big, nearer-term bet: the Cybercab, according to a person with direct knowledge.
That includes Musk’s desire to have the Optimus robot sit in the Cybercab so it can deliver packages. That should be possible: newer versions of the Optimus robot are capable of consistently lifting and moving around with roughly 25-pound objects for three to four hours on a 30 minute charge, another person with direct knowledge said.
But the connection between the robot’s torso and legs isn’t flexible enough to allow it to seamlessly get in and out of a Cybercab, according to the first person. Tesla would need to redesign the robot to change that or use a different vehicle for deliveries more tailored for Optimus’ shape, that person said.
This is obviously all still a ways out, but it all feels a lot more possible today than it did even a year ago; relatedly, it feels a lot more uncertain that Uber will have a long-term role to play — and the company may agree! I thought this announcement from Nvidia at GTC Washington D.C. was a bearish indicator for the company:
Nvidia today announced it is partnering with Uber to scale the world’s largest level 4-ready mobility network, using the company’s next-generation robotaxi and autonomous delivery fleets, the new Nvidia Drive AGX Hyperion 10 autonomous vehicle (AV) development platform and Nvidia Drive AV software purpose-built for L4 autonomy.
By enabling faster growth across the level 4 ecosystem, Nvidia can support Uber in scaling its global autonomous fleet to 100,000 vehicles over time, starting in 2027. These vehicles will be developed in collaboration with Nvidia and other Uber ecosystem partners, using Nvidia Drive. Nvidia and Uber are also working together to develop a data factory accelerated by the Nvidia Cosmos world foundation model development platform to curate and process data needed for autonomous vehicle development.
Nvidia Drive AGX Hyperion 10 is a reference production computer and sensor set architecture that makes any vehicle L4-ready. It enables automakers to build cars, trucks and vans equipped with validated hardware and sensors that can host any compatible autonomous-driving software, providing a unified foundation for safe, scalable and AI-defined mobility.
Uber is bringing together human drivers and autonomous vehicles into a single operating network — a unified ride-hailing service including both human and robot drivers. This network, powered by Nvidia Drive AGX Hyperion-ready vehicles and the surrounding AI ecosystem, enables Uber to seamlessly bridge today’s human-driven mobility with the autonomous fleets of tomorrow.
The thing about Uber the first time around is that it wasn’t simply providing a fancy app for the taxi & limo market; it was providing an entirely new experience for both drivers and riders that was orthogonal to that market, which let it create a far larger one. This deal with Nvidia envisions a different sort of evolution, where Uber’s existing market slowly becomes autonomous; that’s possible, even if it means significantly higher capital costs for Uber (and cars that cost more, since they are retrofitted instead of purpose-built).
What is also possible, however, is that Uber gets Uber-ed: a completely new experience for both drivers (as in they don’t exist) and riders (including kids and packages delivered at the marginal cost of energy) ends up being orthogonal to the Uber market, and far larger. Moreover, this market will, for specific qualitative reasons around safety and security, be inaccessible to Uber’s core business, meaning the entire vision of “bringing together human drivers and autonomous vehicles into a single operating network” ends up being a liability instead of an asset.
The End of Urbanism?
There are larger sociological and political questions around things like urban versus suburban living, just as there were when suburbs were built out in the first place. I do believe that the suburbs are very much back, and not just because I’m back in the suburbs; what will be a fascinating question for historians is the chicken-and-egg one between technology driving this shift, versus benefiting from it.
What is worth considering, however, is if the last wave of urbanism, which started in the 1990s and peaked in the 2010s, might be the last, at least in the United States (Asia and its massive metropolises are another story). The potential physical transformation in transportation and delivery I am talking about is simply completing the story that started with entertainment and television in the first wave of suburbia, and then information and interactivity via the Internet, particularly since COVID. There are real benefits to being in person, just like there are to living in the city, but the relative delta to working remote or living in the suburbs has decreased dramatically; meanwhile, offices and urban living can never match the advantages inherent to working from a big home with a big yard.
Whether or not this is good thing is a separate discussion; I will say it has been good for me, and it’s poised to get even better.
It’s funny to remember that a decade ago there were enough people convinced we were in a bubble that I felt compelled to write an Article entitled It’s Not 1999; that was right then, and it’s obviously right now, when we have a clear counter-example: this is a bubble.
How else to describe a single company — OpenAI — making $1.4 trillion worth of deals (and counting!) with an extremely impressive but commensurately tiny $13 billion of reported revenue? Sure, the actual number may be higher, but that is still two orders of magnitude less than the amount of infrastructure OpenAI has publicly committed to buy over the coming years, and they are not the only big spenders. Over the past week every big tech company (except Apple) has significantly expanded their capital expenditure plans, and there is no sign of anyone slowing down.
This does, understandably, have people wringing their hands. What goes up must come down, which is to say bubbles that inflate eventually pop, with the end result being a recession and lots of bankrupt companies. And, not to spoil the story, that will almost certainly happen to the AI bubble as well. What is important to keep in mind, however, is that that is not the end of the story, at least in the best case. Bubbles have real benefits.
Financial Speculation and Physical Capacity
The definitive book on bubbles has long been Carlota Perez’s Technological Revolutions and Financial Capital.1 Bubbles were — are — thought to be something negative and to be avoided, particularly at the time Perez published her book. The year was 2002 and much of the world was in a recession coming off the puncturing of the dot-com bubble.
Perez didn’t deny the pain: in fact, she noted that similar crashes marked previous revolutions, including the Industrial Revolution, railways, electricity, and the automobile. In each case the bubbles were not regrettable, but necessary: the speculative mania enabled what Perez called the “Installation Phase”, where necessary but not necessarily financially wise investments laid the groundwork for the “Deployment Period”. What marked the shift to the deployment period was the popping of the bubble; what enabled the deployment period were the money-losing investments.
In the case of the dotcom bubble, the money-losing investments that mattered were not actually the dotcom companies that mark that era in Silicon Valley lore: yes, a lot of people lost money on insane IPOs, but the loss was mostly equity, not debt. Where debt was a problem was in telecom, where a host of companies went bankrupt after a frenzied period of building far more fiber than could ever be justified by current usage, fast though it may have been growing. That fiber, however, became the background of today’s Internet; the fact that it basically existed for free — because the companies who built it went bankrupt — enabled the effectively free nature of the Internet today.
The Conditions for Cognitive Capacity
Late last year Byrne Hobart and Tobias Huber made a new contribution to our understanding of bubbles with their book Boom: Bubbles and the End of Stagnation. While Perez focused on the benefits that came from financial speculation leading to long-term infrastructure, Hobart and Huber identified another important feature of what they called “Inflection Bubbles” — the good kind of bubbles, as opposed to the much more damaging “Mean-reversion Bubbles” like the 2000’s subprime mortgage bubble. First, here is Hobart and Huber’s definition of an inflection bubble:
Inflection-driven bubbles have fewer harmful side effects and more beneficial long-term effects. In an inflection-driven bubble, investors decide that the future will be meaningfully different from the past and trade accordingly. Amazon was not a better Barnes & Noble; it was a store with unlimited shelf space and the data necessary to make personalized recommendations to every reader. Yahoo wasn’t a bigger library; it was a directory and search engine that made online information accessible to anyone. Priceline didn’t want to be a travel agent; it aspired to change the way people bought everything, starting with plane tickets.
If a mean-reversion bubble is about the numbers after the decimal point, an inflection bubble is about orders of magnitude. A website, a PC, a car, a smartphone — these aren’t five percent better than the nearest alternative. On some dimensions, they’re incomparably better. A smartphone is a slightly more convenient tool than a PC for taking a photo and quickly uploading it to the internet, but it’s infinitely better at navigation. A car is not just slightly faster and more reliable than a horse (although in the early days of the automobile industry, it was apparently common for pedestrians to yell “Get a horse!” at passing motorists); cars transformed American cities. Modern-day Los Angeles is inconceivable on horseback. The manure problem alone beggars the imagination.
This is what makes inflection bubbles valuable:
The fundamental utility of inflection bubbles comes from their role as coordinating mechanisms. When one group makes investments predicated on a particular vision of the future, it reduces the risk for others seeking to build parts of that vision. For instance, the existence of internet service providers and search engines made e-commerce sites a better idea; e-commerce sites then encouraged more ad-dependent business models that could profit from directing consumers. Ad-dependent businesses then created more free content, which gave the ISPs a better product to sell. Each sector grew as part of a virtuous circle.
What I love about this formulation from a tech perspective is that it captures the other side of the dotcom era: no, Silicon Valley didn’t produce any lasting infrastructure (unless you count a surplus of Aeron chairs), but what the mania did produce were a huge number of innovations, invented in parallel, that unlocked the following two decades of growth.
First, the dotcom era brought nearly the entire U.S. population online, thanks to that virtuous cycle that Hobart and Huber described in the above excerpt. This not only provided the market for the consumer Internet giants that followed, but also prepared an entire generation of future workers to work on the web, unlocking the SaaS enterprise market.
Second, the intense competition of the dotcom era led to one of my favorite inventions of all time, both because of its impact and because of its provenance.
Microsoft famously saw Netscape, the OpenAI of the dotcom era, as a massive threat; the company responded with Internet Explorer, and a host of legally questionable tactics to spur its adoption. What is forgotten, however, is that Microsoft was at that time actually quite innovative in terms of pushing browser technology forward, driven by the need to beat Netscape, and one of those innovations was XMLHttpRequest. XMLHttpRequest, introduced with Internet Explorer 5 in 1999, allowed Javascript to make asynchronous HTTP requests without reloading the page; previously to change anything on a webpage meant reloading the entire thing. Now, however, you could interact with a page and have it update in place, without a reload.
What makes this invention ironic is that this was the key capability that transformed the browser from a media consumption app to a productive one, and it was the productivity capabilities that began the long breakdown of Microsoft’s application moat. Once work could be done in a browser, it would be done everywhere, not just on Windows; this, in the long run, created the conditions for the smartphone revolution and the end of Windows’ dominance. This was, to be clear, but one of a multitude of new protocols and innovations that made today’s tech stack possible; what is important is how many of them were invented at once thanks to the bubble.
Third, the cost and complexity of serving all of these new use cases drove tremendous innovation on the backend. The Nvidia of the dotcom era was arguably not Cisco, but rather Sun: a huge percentage of venture capital went to buying Sun SPARC/Solaris servers to run these new-fangled companies. Solaris was the most advanced operating system in terms of running large websites, with the most mature TCP/IP stack, multithreading, symmetric multiprocessing, etc. Moreover, the dominance of Solaris meant that it had the largest pool of developers, which meant it was easier to hire if you ran Solaris.
The problem, however, is that SPARC servers were extremely expensive, to the point of being nearly financially impractical for the largest-scale web applications like Hotmail or Yahoo. That’s why the former (in its startups days) ran its front-end on free software (FreeBSD) on commodity x86 hardware from the beginning, and why the latter made the same shift as it exploded in popularity. Both, however, had custom-built back-ends; it was Google, founded in 1998, that built the entire stack on commodity x86 hardware and Linux, unlocking the scalability that was critical to the huge growth in the Internet that followed.
This entire stack was the product of a massive amount of uncoordinated coordination: people came online for better applications that ran on hardware powered by software built by a massive array of companies and individuals; that all of this innovation and invention happened at the same time was because of the bubble.
Oh, and to return to Perez: all of this ran over fiber laid by bankrupt companies. What Perez got right is that bubbles install physical capacity; what Hobart and Huber added is that they also create cognitive capacity, thanks to everyone pulling in the same direction at the exact same time, based not on fiat, but on a shared belief that this time is different.
Is AI Different?
This question — or statement — is usually made optimistically. In this case, the optimistic take would be that AI is already delivering tangible benefits, that those benefits are leading to real demand from companies and consumers, and that all of the money being spent on AI will not be wasted but put to productive use. That may still be the case today — all of the hyperscalers claim that demand for their offerings exceeds supply — but if history is any indication we will eventually overshoot.
There is, however, a pessimistic way to ask that question: will the AI bubble be beneficial like the positive bubbles chronicled by Perez and Hobart and Huber, or is it different? There have been reasons to be worried about both the physical buildout and the cognitive one.
Start with the physical: a huge amount of the money being spent on AI has gone to GPUs, particularly Nvidia, rocketing the fabless design company to a nearly $5 trillion valuation and the title of most valuable company in the world. The problem from a Perez perspective is that all of this spending on chips is, relative to the sort of infrastructure she wrote about — railroads, factories, fiber, etc. — short-lived. Chips break down and get superseded by better ones; most hyperscalers depreciate them over five years, and that may be generous. Whatever the correct number is, chips don’t live on as fully-depreciated assets that can be used cheaply for years, which means that to the extent speculative spending goes towards GPUs is the extent to which this bubble might turn out to be a disappointing one.
Fortunately, however, there are two big areas of investment that promise to have much more long-term utility, even if the bubble pops.
The first is fabs — the places where the chips are made. I’ve been fretting about declining U.S. capacity in this area, and the attendant dependence on Taiwan, the most fraught geopolitical location in the world, for years, and for much of that time it wasn’t clear that anything would be done about it. Fast forward to today, and not only are foundries like TSMC and Samsung building fabs in the U.S., but the U.S. government is now a shareholder in Intel. There is still a long path to foundry independence for the U.S., particularly once you consider the trailing edge as well, but there is no question that the rise of AI has had a tremendous effect in focusing minds and directing investment towards solving a problem that might never have been solved otherwise.
As you know, we’ve spent the past few years not actually being short GPUs and CPUs per se, we were short the space or the power, is the language we use, to put them in. We spent a lot of time building out that infrastructure. Now, we’re continuing to do that, also using leases. Those are very long-lived assets, as we’ve talked about, 15 to 20 years. And over that period of time, do I have confidence that we’ll need to use all of that? It is very high.
On the capacity side, we brought in quite a bit of capacity, as I mentioned in my opening comments, 3.8 gigawatts of capacity in the last year with another gigawatt plus coming in the fourth quarter and we expect to double our overall capacity by the end of 2027. So we’re bringing in quite a bit of capacity today, overall in the industry, maybe the bottleneck is power. I think at some point, it may move to chips, but we’re bringing in quite a bit of capacity. And as fast as we’re bringing in right now, we are monetizing it.
As I noted yesterday, this actually surprised me: I assumed that chips were in short supply, and the power shortage was looming, but actually power is already the limiter. This is both disappointing and unsurprising, given how power generation capacity growth has stagnated over the last two decades:
At the same time, this is also encouraging: the fastest way to restart growth — and hopefully at an even higher rate than the fifty years that preceded this stagnation — is to have massive economic incentives to build, combined with massive government incentives to eliminate red tape. AI provides both, and my hope is that the fact we are already hitting the power wall means that growth gets started that much sooner.
It’s hard to think of a more useful and productive example of a Perez-style infrastructure buildout than power. It’s sobering to think about how many things have never been invented because power has never been considered a negligible input from a cost perspective; if AI does nothing more than spur the creation of massive amounts of new power generation it will have done tremendous good for humanity. Indeed, if you really want to push on the bubble benefit point, wiping away the cost of building new power via bankruptcy of speculative investors — particularly if a lot of that power has low marginal fuel costs, like solar or nuclear — could be transformative in terms of what might be invented in the future.
To that end, I’m more optimistic today than I was even a week ago about the AI bubble achieving Perez-style benefits: power generation is exactly the sort of long-term payoff that might only be achievable through the mania and eventual pain of a bubble, and the sooner we start feeling the financial pressure — and the excitement of the opportunity — to build more power, the better.
I’ve been less worried about the cognitive capacity payoff of the AI bubble for a while: while there might have been concern about OpenAI having an insurmountable lead, or before that Google being impregnable, nearly everyone in Silicon Valley is now working on AI, and so is China. Innovations don’t stay secret for long, and the time leading edge models stay in the lead is often measured in weeks, not years. Meanwhile, consumer uptake of AI is faster than any other tech product by far.
What is exciting about the last few weeks, however, is that there is attention being paid to other parts of the stack, beyond LLMs. For example, last week I interviewed Substrate founder James Proud about his attempt to build a new kind of lithography machine as the center of a new American foundry. I don’t know if Proud will succeed, but the likelihood of anyone even trying — and of getting funding — is dramatically higher in the middle of this bubble than it would have been a decade ago.
It was also last week that Extropic announced a completely new kind of chip, one based not on binary 1s and 0s, but on probabilistic entropy measurements, that could completely transform diffusion models. Again, I don’t know if it will succeed, but I love that the effort exists, and is getting funding. And meanwhile, there are massive investments by every hyperscaler and a host of startups to make new chips for AI that promise to be cheaper, faster, more efficient, etc. All of these efforts are getting funding in a way they wouldn’t if we weren’t in a bubble.
Hobart and Huber write in Boom:
Not all bubbles destroy wealth and value. Some can be understood as important catalysts for techno-scientific progress. Most novel technology doesn’t just appear ex nihilo, entering the world fully formed and all at once. Rather, it builds on previous false starts, failures, iterations, and historical path dependencies. Bubbles create opportunities to deploy the capital necessary to fund and speed up such large-scale experimentation — which includes lots of trial and error done in parallel — thereby accelerating the rate of potentially disruptive technologies and breakthroughs.
By generating positive feedback cycles of enthusiasm and investment, bubbles can be net beneficial. Optimism can be a self-fulfilling prophecy. Speculation provides the massive financing needed to fund highly risky and exploratory projects; what appears in the short term to be excessive enthusiasm or just bad investing turns out to be essential for bootstrapping social and technological innovations…A bubble can be a collective delusion, but it can also be an expression of collective vision. That vision becomes a site of coordination for people and capital and for the parallelization of innovation. Instead of happening over time, bursts of progress happen simultaneously across different domains. And with mounting enthusiasm…comes increased risk tolerance and strong network effects. The fear of missing out, or FOMO, attracts even more participants, entrepreneurs, and speculators, further reinforcing this positive feedback loop. Like bubbles, FOMO tends to have a bad reputation, but it’s sometimes a healthy instinct. After all, none of us wants to miss out on a once-in-a-lifetime chance to build the future.
This is why I’m excited to talk about new technologies, the prospect for which I don’t know. The more I don’t know projects there are, the more likely there is to be one that succeeds. And, if you want an investment that pays off not for a few years, and not even for a few decades, but literally forever, then your greatest hope should be invention and innovation.
Stagnation: The Bubble Alternative
Hobart and Huber actually begin their book not by talking about ancient history, but about this century, and stagnation.
The symptoms of technological, economic, and cultural stagnation can be detected everywhere. Some of the evidence is hard to quantify, but it can perhaps best be summarized by a simple thought experiment: Will children born today experience as much change as children born a century ago—a time when cars, electrical appliances, synthetic materials, and telephones were still in their infancy? Futurists and science-fiction authors once prophesied an era of abundant energy due to nuclear fission, the arrival of full automation, the colonization of the solar system, the end of poverty, and the attainment of immortality. In contrast, futurists today ask questions about how soon and how catastrophically civilization will collapse.
There is a science-fiction innovation that has been hovering around the edges of the tech industry for the last decade: virtual and augmented reality. It hasn’t gotten far. Meta has, since it started breaking out Reality Labs financials in Q4 2020, recognized $10.8 billion in revenue against $83.2 billion in costs; the total losses are far higher when you consider that the company bought Oculus VR for $2 billion six years before that breakout. Apple, meanwhile, announced the Vision Pro in 2023, launched it in 2024, and has barely talked about it since — and certainly not on earnings calls.
Both companies would argue that the technology just isn’t there yet, and to the extent AR and VR are compelling, it’s because of the money and time they have spent developing it. I wonder, however, about a counter-factual where AR and VR were developed by a constellation of startups, not big companies: how much more innovation might there have been? Or, perhaps the bigger problem is that there was not — and, given that all of the investment is a line item in large company budgets, could not be — a bubble around AR and VR.
More generally, tech simply wasn’t much fun by the time 2020 rolled around. You had your big five tech companies who had each carved out their share of the market, unassailable in their respective domains, and the startup industry was basically itself another big tech company: Silicon Valley Inc., churning out cookie-cutter SaaS companies with a proven formula and low risk. In fact, it’s the absence of risk that Hobart and Huber identify as the hallmark of stagnation:
Of course, the causes of stagnation are complex. But what these symptoms of stagnation and decline have in common is that they result from a societal aversion to risk, which has been on the rise for the past few decades. Societal risk intolerance expresses itself almost everywhere — in finance, culture, politics, education, science, and technology. Broadly, there seems to be a collective desire to suppress and control all risks and conserve what is at the expense of breaking the terminal horizon of the present and accelerating toward what could be.
What I took away is your book was much more of a sociological exposé, like spiritual almost, and I shouldn’t say almost because you were actually quite explicit about it. It’s like you were seeking — the goal of this book, it feels like — is to call forth the spirit of the bubble as opposed to have some sort of technocratic overview. You give us useful history, but there’s not really charts or microeconomics, it’s an exhortation. Is that what you were going for?
Byrne Hobart: Yes, it is an exhortation. We do want people to pick up a copy and quit their job halfway through reading it or drop out of school and start something crazy. I don’t want to be legally liable if you do something sufficiently crazy, and I think that the spiritual element is something that we did want to talk about in the book, because I think if you — you can apply this totally secular framework to it, and it’s perfectly valid. Of course, if it is a mostly materialist framing of things, then it has a lot more real world data because it’s all reliant on that real world data, but if you have the belief or at least suspicion that all of us are unique and special, and there is something that we are, if not put on this Earth to do, at least there are things that we are able to do that other people wouldn’t do as well, that part of our job is to find those things and do them really well. Bubbles play into that in an interesting way because they tell you it’s time, it’s like you wanted to do this kind of thing.
What is fascinating about the AI bubble is that there is at its core a quasi-spiritual element. There are people working at these labs that believe they are building God; that is how they justify the massive investment in leading edge models that never have the chance to earn back their costs before they are superceded by someone else. That’s why they push for policies that I think are bad for innovation and bad for national security. I don’t like these side effects, to be clear, but I appreciate the importance of the belief and the motivation.
And, I must say, it certainly is fun and compelling in a way that tech was not a few years ago. Bubbles may end badly, but history does not end: there are benefits from bubbles that pay out for decades, and the best we can do now is pray that the mania results in infrastructure and innovation that make this bubble worth it.
I highly recommend this overview if you are not familiar. ↩
There seems, at first glance, to be little in common between the two big stories of the last two weeks. On October 9, China announced expansive export controls on rare earths, which are critical to nearly all tech products; then, on October 20, US-East-1, the oldest and largest region of Amazon Web Services, suffered a DNS issue that impacted cloud services that people didn’t even know they used, until they were no longer available.
There is, however, a commonality, one that cuts to the heart of accepted wisdom about both the Internet and international trade, and serves as a reminder that what actually happens in reality matters more than what should happen in theory.
US-East-1 and the End of Resiliency
The Internet story is easier to tell. While the initial motivation for ARPANET, the progenitor of the Internet, was to share remote computing resources, the more famous motivation of surviving a nuclear attack did undergird a critical Internet technology: packet switching. Knocking out one node of the Internet should not break the whole thing, and, technically, it doesn’t. And yet we have what happened this week: US-East-1 is but one node on the Internet, but it is so critical to so many applications that it effectively felt like the Internet was broken.
The reasoning is straightforward: scale and inertia. Start with the latter: Northern Virginia was a place that, in the 1990s, had relatively cheap and reliable power, land, and a fairly benign natural-disaster profile; it also had one of the first major Internet exchange points, thanks to its proximity to Washington D.C., and was centrally located between the west coast and Europe. That drew AOL, the largest Internet Service Provider of the 1990s, which established the region as data center central, leading to an even larger buildout of critical infrastructure, and making it the obvious location to place AWS’s first data center in 2006.
That data center became what is known as US-East-1, and from the beginning it has been the location with the most capacity, the widest variety of instance types, and the first region to get AWS’s newest features. It’s so critical that AWS itself has repeatedly been shown to have dependencies on US-East-1; it’s also the default location in tutorials and templates used by developers around the world. You might make the case that “no one got fired for using US-East-1”, at least until now.
Amazon, meanwhile, has invested billions of dollars into AWS over the last two decades, making the case that enterprises ought not waste their time and money building out and maintaining their own servers: even if the costs penciled out similarly, the flexibility of being able to scale up and scale down instantly was worth shifting capital costs to operational ones.
The fact that this was not only a winning argument but an immensely profitable one became clear with The AWS IPO, which is how I described the Amazon earnings where they first broke out AWS’s financials. For the first decade of AWS’ existence the conventional wisdom was that only Amazon, with its famous appetite for tiny margins, would be able to stomach similarly narrow margins in the cloud; in fact it turned out that AWS was extremely profitable, and that profitability increased with scale.
And, nestled within AWS’s scale, was US-East-1: that was the place with the cheapest instances, because it had the most, and that is where both startups and established businesses started as they moved to the cloud. Sure, best practices meant you had redundancy, but best practices are not always followed practices, and when it comes to networking, things can break in weird ways, particularly if DNS is involved.
The larger lesson, however, is that while the Internet provided resiliency in theory, it also dramatically reduced the costs of putting your data and applications anywhere; then, once you could put your data and applications anywhere, everyone put their data and applications in the place that was both the easiest and the cheapest. That, by extension, only increased the scale of the place where everyone put their data and applications, making it even cheaper and easier. The end result is that, as we saw this week, the Internet in practice is less resilient than it was 20 years ago. Back then data centers went down all of the time, but if that data center served a single customer in an office park it didn’t really matter; now one data center in Northern Virgina is a failure point that affects nearly everyone.
Rare Earths and China Dependency
Rare earths are very different from packets that move with the speed of light. You have to build massive mines, separate trace minerals from mounds of dirt, then process and refine them to get something useful. It’s a similar story for physical goods generally: you have to get the raw materials, refine and process them, manufacture components, do final assembly, and then ship them to stores and warehouses until they reach their final destinations in workplaces and homes.
This process was so onerous that, midway through the last century, only a portion of the world’s countries had ever managed to industrialize, and those that did trod similar paths and developed similar capabilities. Geography mattered tremendously, which is why, to take some classic examples, every country had its own car companies, its own chemical companies, etc. Yes, countries did search and colonize the planet in pursuit of raw materials, but the industrial base was firmly established in the homeland.
In the years leading up to the 1970s, three technological advances completely transformed the meaning of globalization:
In 1963, Boeing produced the 707-320B, the first jet airliner capable of non-stop service from the continental United States to Asia; in 1970 the 747 made this routine.
In 1964, the first transpacific telephone cable between the United States and Japan was completed; over the next several years it would be extended throughout Asia.
In 1968, ISO 668 standardized shipping containers, dramatically increasing the efficiency with which goods could be shipped over the ocean in particular.
These three factors in combination, for the first time, enabled a new kind of trade. Instead of manufacturing products in the United States (or Europe or Japan or anywhere else) and trading them to other countries, multinational corporations could invert themselves: design products in their home markets, then communicate those designs to factories in other countries, and ship finished products back to their domestic market. And, thanks to the dramatically lower wages in Asia (supercharged by China’s opening in 1978), it was immensely profitable to do just that.
What followed over the last several decades was the same establishment of scale and inertia that led to a dependency on US-East-1 on the Internet, only in this case the center of gravity was China. Once the cost of communication and transportation plummeted it suddenly became viable to shift industry across the globe in pursuit of lower labor costs, looser environmental laws, and governments eager to support factory build-outs. Then, over time, scale and inertia took over: if everyone else was building a factory in China, it was easier to build your factory there; if all of the factories for your components were there, it was easier to do final assembly there.
One of the critiques I’ve previously leveled at classical free trade arguments is that they ignore the importance of learning curves; from A Chance to Build:
The story to me seems straightforward: the big loser in the post World War 2 reconfiguration I described above was the American worker; yes, we have all of those service jobs, but what we have much less of are traditional manufacturing jobs. What happened to chips in the 1960s happened to manufacturing of all kinds over the ensuing decades. Countries like China started with labor cost advantages, and, over time, moved up learning curves that the U.S. dismantled; that is how you end up with this from Walter Isaacson in his Steve Jobs biography about a dinner with then-President Obama:
When Jobs’s turn came, he stressed the need for more trained engineers and suggested that any foreign students who earned an engineering degree in the United States should be given a visa to stay in the country. Obama said that could be done only in the context of the “Dream Act,” which would allow illegal aliens who arrived as minors and finished high school to become legal residents — something that the Republicans had blocked. Jobs found this an annoying example of how politics can lead to paralysis. “The president is very smart, but he kept explaining to us reasons why things can’t get done,” he recalled. “It infuriates me.”
Jobs went on to urge that a way be found to train more American engineers. Apple had 700,000 factory workers employed in China, he said, and that was because it needed 30,000 engineers on-site to support those workers. “You can’t find that many in America to hire,” he said. These factory engineers did not have to be PhDs or geniuses; they simply needed to have basic engineering skills for manufacturing. Tech schools, community colleges, or trade schools could train them. “If you could educate these engineers,” he said, “we could move more manufacturing plants here.” The argument made a strong impression on the president. Two or three times over the next month he told his aides, “We’ve got to find ways to train those 30,000 manufacturing engineers that Jobs told us about.”
I think that Jobs had cause-and-effect backwards: there are not 30,000 manufacturing engineers in the U.S. because there are not 30,000 manufacturing engineering jobs to be filled. That is because the structure of the world economy — choices made starting with Bretton Woods in particular, and cemented by the removal of tariffs over time — made them nonviable. Say what you will about the viability or wisdom of Trump’s tariffs, the motivation — to undo eighty years of structural changes — is pretty straightforward!
The other thing about Jobs’ answer is how ultimately self-serving it was. This is not to say it was wrong: Apple could not only not manufacture an iPhone in the U.S. because of cost, it also can’t do so because of capability; that capability is downstream of an ecosystem that has developed in Asia and a long learning curve that China has traveled and that the U.S. has abandoned. Ultimately, though, the benefit to Apple has been profound: the company has the best supply chain in the world, centered in China, that gives it the capability to build computers on an unimaginable scale with maximum quality for not that much money at all.
The Apple-China story is so compelling because it is so representative of how the U.S. has become dependent on China. What is notable, however, is that this dependency points to another flaw in classic free trade formulations: while in theory free trade and globalization make supply chains more resilient because you can source from anywhere, in practice free trade has destroyed resiliency. Apple CEO Tim Cook famously said in what became known as The Tim Cook Doctrine:
We believe that we need to own and control the primary technologies behind the products we make, and participate only in markets where we can make a significant contribution.
The fact of the matter, however, is that Apple’s most important technology — the one architected by Cook himself — is its unmatched capability to make the most sophisticated and profitable devices at astronomical scale, and Apple ultimately does not own and control it: China does.
So it goes for nearly everything else in the industrial supply chain, including rare earths. Rare earths are not, in fact, rare, but China’s scale and the inertia of the last forty years has led to total dependence on a country that is a geopolitical foe of the United States. And so, once again, removing or reducing the costs of transportation and communication — this time for atoms — did not increase resiliency but rather, thanks to the pursuit of lower costs enabled by scale, destroyed it.
COVID and Information Resiliency
There is a happier story to be told about overcoming resiliency collapse, but I should warn you up front, this might be a controversial take. It has to do with the current state of information, the earliest and most popular Internet content.
Back in March 2020 I wrote an Article entitled Zero Trust Information that made the case that the Internet was under-appreciated as a medium for conveying information that cut against the prevailing wisdom; my go-to example was the Seattle Flu Study, which heroically traced the spread of COVID in the United States at the beginning of 2020, making the (correct) case that the virus was far more widespread in the U.S. than the CDC in particular was willing to admit.
In truth, however, my optimism was misplaced, or at least early. What followed in the weeks and months and even years afterwards was one of the greatest failures in information discovery and propagation maybe ever. I actually wrote an Update on March 2, 2020 that included a huge amount of relevant COVID information — including the fact that it was both going to infect everyone, and that it was much less fatal than initially assumed — that only became widely accepted years later (and still isn’t accepted by a big chunk of the population).
It’s hard not to think about how much differently we might have handled the ensuing months and years if just those two facts were widely accepted, much less other banal observations like the fact that of course natural immunity is a real thing, or that airborne viruses are all-but-inescapable indoors, but much less of an issue outdoors. Unfortunately what happened is that by 2020 information distribution was highly centralized on Facebook, Twitter, and YouTube, and all three companies went to extraordinary lengths to limit the aperture of acceptable discourse on topics that contained a great deal of unknowns; indeed, it’s possible that that March 2 Update, had it been posted on one of those platforms, would have at one point earned me a ban. In short, our resiliency in terms of information propagation was by 2020 completely destroyed, and we all suffered the consequences.
Then Elon Musk bought Twitter.
What is fascinating about what has happened in the years since Musk’s purchase is not that Twitter has become a fountain of truth, even if it did in some respects become considerably freer. More importantly, Musk’s purchase and ensuing political advocacy provided the impetus for a number of Twitter alternatives, including Threads, Mastodon, and BlueSky.
Each of these networks has its own focus and mores and overall culture. What is critical about their existence, however, is not that any one of them has a monopoly on the truth: rather, given that such a monopoly is impossible, it’s heartening that there is more than one forum. To that end, should a COVID-like episode arise today, there may be an easily distinguishable and widely-held-on-the-platform X truth, and Threads truth, and Mastodon truth, and BlueSky truth; the fact that none of those truths will be completely right — and in come cases completely at odds — is not a bug but a feature: that’s actual resiliency, because it increases the likelihood that we collectively arrive at the right answer sooner than we did in the COVID era.
The Costs of Resiliency
What is worth noting is that the only way we arrived at this point is through a fair bit of value destruction: Musk overpaid for Twitter, and losing a monopoly on short-form text communication diminished the value further. I think, however, that the collective outcome was positive.
Unwinding US-East-1 dependencies will also take a similar sort of pain: businesses will need to spend money to truly understand their stack, and build actual resiliency into their systems, such that one region on one cloud provider going down doesn’t screw up their business; it can be done, it just needs the budget.
And, in the end, we can do something similar with China. There, though, the difference between atoms and bits is very profound, and exceptionally costly. Overcoming the advantages of scale and decades-long learning curves will be very painful and very expensive; the only solution to the inevitable destruction of resiliency that comes from decreased transportation and communications costs is to increase costs elsewhere, even if those costs are artificial and lead to deadweight loss.
I am, needless to say, much more optimistic about our willingness to accept the costs of moving some bits around than I am the willingness to accept the drastically larger and longer costs of moving atoms. If we don’t, however, then we need to be clear that the true price being paid for global efficiency is national resiliency. Pursuing the former led to the destruction of the latter; there’s no way back other than destroying some value along the way.
The Sora 2 video generation model and Sora the app
A deal with AMD for 6 GW worth of AMD chips and an associated OpenAI stake in the chipmaker
A slew of DevDay announcements, including apps in ChatGPT, AgentKit, Sora 2 and GPT-5 Pro in the API, the GA release of Codex, and more.
The last two announcements just dropped yesterday, and actually bring clarity and coherence to the entire list. In short, OpenAI is making a play to be the Windows of AI.
For nearly two decades smartphones, and in particular iOS, have been the touchstones in terms of discussing platforms. It’s important to note, however, that while Apple’s strategy of integrating hardware and software was immensely profitable, it entailed leaving the door open for a competing platform to emerge. The challenge of being a hardware company is that by virtue of needing to actually create devices you can’t serve everyone; Apple in particular didn’t have the capacity or desire to go downmarket, which created the opportunity for Android to not only establish a competing platform but to actually significantly exceed iOS in market share.
That means that if we want a historical analogy for total platform dominance — which increasingly appears to be OpenAI’s goal — we have to go back further to the PC era and Windows.
Platform Establishment
Before there was Windows there was DOS; before DOS, however, there was a fast-talking deal-making entrepreneur named Bill Gates. From The Truth About Windows Versus the Mac:
In the late 1970s and very early 1980s, a new breed of personal computers were appearing on the scene, including the Commodore, MITS Altair, Apple II, and more. Some employees were bringing them into the workplace, which major corporations found unacceptable, so IT departments asked IBM for something similar. After all, “No one ever got fired for buying IBM.”
IBM spun up a separate team in Florida to put together something they could sell IT departments. Pressed for time, the Florida team put together a minicomputer using mostly off-the shelf components; IBM’s RISC processors and the OS they had under development were technically superior, but Intel had a CISC processor for sale immediately, and a new company called Microsoft said their OS — DOS, which they acquired from another company — could be ready in six months. For the sake of expediency, IBM decided to go with Intel and Microsoft.
The rest, as they say, is history. The demand from corporations for IBM PCs was overwhelming, and DOS — and applications written for it — became entrenched. By the time the Mac appeared in 1984, the die had long since been cast. Ultimately, it would take Microsoft a decade to approach the Mac’s ease-of-use, but Windows’ DOS underpinnings and associated application library meant the Microsoft position was secure regardless.
There is nothing like IBM and its dominant position in enterprise today; rather, the route to becoming a platform is to first be a massively popular product. Acquiring developers and users is not a chicken-and-egg problem: it is clear that you must get users first, which attracts developers, enhancing your platform in a virtuous cycle; to put it another way, first a product must Aggregate users and then it gets developers for free.
ChatGPT is exactly that sort of product, and at yesterday’s DevDay 2025 keynote CEO Sam Altman and team demonstrated exactly that sort of pull; from The Verge:
OpenAI is introducing a way to work with apps right inside ChatGPT. The idea is that, from within a conversation with the chatbot, you can essentially tag in apps to help you complete a task while ChatGPT offers context and advice. The company showed off a few different ways this can work. In a live demo, an OpenAI employee launched ChatGPT and then asked Canva to create a poster of a name for a dog-walking business; after a bit of waiting, Canva came back with a few different examples, and the presenter followed up by asking for a generated pitch deck based on the poster. The employee also asked Zillow via ChatGPT to show homes for sale in Pittsburgh, and it created an interactive Zillow map — which the employee then asked follow-up questions about.
Apps available inside ChatGPT starting today will include Booking.com, Canva, Coursera, Expedia, Figma, Spotify, and Zillow. In the “weeks ahead,” OpenAI will add more apps, such as DoorDash, OpenTable, Target, and Uber. OpenAI recently started allowing ChatGPT users to make purchases on Etsy through the chatbot, part of its overall push to integrate it with the rest of the web.
It’s fair to wonder if these app experiences will measure up to these company’s self-built apps or websites, just as there are questions about just how well the company’s Instant Checkout will convert; what is notable, however, is that I disagree that this represents a “push to integrate…with the rest of the web”.
This is the opposite: this is a push to make ChatGPT the operating system of the future. Apps won’t be on your phone or in a browser; they’ll be in ChatGPT, and if they aren’t, they simply will not exist for ChatGPT users. That, by extension, means the burden of making these integrations work — and those conversions performant — will be on third party developers, not OpenAI. This is the power that comes from owning users, and OpenAI is flexing that power in a major way.
Second Sourcing
There is a second aspect to the IBM PC strategy, and that is the role of AMD. From a 2024 Update:
While IBM chose Intel to provide the PC’s processor, they were wary of being reliant on a single supplier (it’s notable that IBM didn’t demand the same of the operating system, which was probably a combination of not fully appreciating operating systems as a point of integration and lock-in for 3rd-party software, which barely existed at that point, and a recognition that software is just bits and not a physical good that has to be manufactured). To that end IBM demanded that Intel license its processor to another chip firm, and AMD was the obvious choice: the firm was founded by Jerry Sanders, a Fairchild Semiconductor alum who had worked with Intel’s founders, and specialized in manufacturing licensed chips.
The relationship between Intel and AMD ended up being incredibly fraught and largely documented by endless lawsuits (you can read a brief history in that Update); the key point to understand, however, is that (1) IBM wanted to have dual suppliers to avoid being captive to an essential component provider and (2) IBM had the power to make that happen because they had the customers who were going to provide Intel so much volume.
The true beneficiary of IBM’s foresight, of course, was Microsoft, which controlled the operating system; IBM’s mandate is why it is appropriate that “Windows” comes first in the “Wintel” characterization of the PC era. Intel reaped tremendous profits from its position in the PC value chain, but more value accrued to Microsoft than anyone else.
This question of who will capture the most profit from the AI value chain remains an open one. There’s no question that the early winner is Nvidia: the company has become the most valuable in the world by virtue of its combination of best-in-class GPUs, superior networking, and CUDA software layer that locks people into Nvidia’s own platform. And, as long as power is the limiting factor, Nvidia is well-placed to maintain its position.
What Nvidia is not shy about is capturing its share of value, and that is a powerful incentive for other companies in the value chain to look for alternatives. Google is the furthest along in this regard thanks to its decade-old investment in TPUs, while Amazon is seeking to mimic their strategy with Trainium; Microsoft and Meta are both working to design and build their own chips, and Apple is upscaling Apple Silicon for use in the data center.
Once again, however, the most obvious and most immediately available alternative to Nvidia is AMD, and I think the parallels between yesterday’s announcement of an OpenAI-AMD deal and IBM’s strong-arming of Intel are very clear; from the Wall Street Journal:
OpenAI and chip-designer Advanced Micro Devices announced a multibillion-dollar partnership to collaborate on AI data centers that will run on AMD processors, one of the most direct challenges yet to industry leader Nvidia. Under the terms of the deal, OpenAI committed to purchasing 6 gigawatts worth of AMD’s chips, starting with the MI450 chip next year. The ChatGPT maker will buy the chips either directly or through its cloud computing partners.
AMD chief Lisa Su said in an interview Sunday that the deal would result in tens of billions of dollars in new revenue for the chip company over the next half-decade. The two companies didn’t disclose the plan’s expected overall cost, but AMD said it costs tens of billions of dollars per gigawatt of computing capacity. OpenAI will receive warrants for up to 160 million AMD shares, roughly 10% of the chip company, at 1 cent per share, awarded in phases, if OpenAI hits certain milestones for deployment. AMD’s stock price also has to increase for the warrants to be exercised.
If OpenAI is the software layer that matters to the ecosystem, then Nvidia’s long-term pricing power will be diminished; the company, like Intel, may still take the lion’s share of chip profits through sheer performance and low-level lock-in, but I believe the most important reason OpenAI is making this deal is to lock in its own dominant position in the stack. It is pretty notable that this announcement comes only weeks after Nvidia’s investment in OpenAI; that, though, is another affirmation that the company who has the users has the ultimate power.
There is one other part of the stack to keep an eye on: TSMC. Both Nvidia and AMD make their chips with the Taiwanese giant, and while TSMC is famously reticent to take price, they are positioned to do so in the long run. Altman surely knows this as well, which means that I wouldn’t be surprised if there is an Intel announcement sooner rather than later; maybe there is fire behind that recent smoke about AMD talking with Intel?
The AI Linchpin
When I started writing Stratechery, Windows was a platform in decline, superceded by mobile and, surprisingly enough, increasingly challenged by its all-but-vanquished ancient foe, the Mac. To that end, one of my first pieces about Microsoft was about then-CEO Steve Ballmer’s misguided attempt to focus on devices instead of services. I wrote a few years later in Microsoft’s Monopoly Hangover:
The truth is that both [IBM and Microsoft] were victims of their own monopolistic success: Windows, like the System/360 before it, was a platform that enabled Microsoft to make money in all directions. Both companies made money on the device itself and by selling many of the most important apps (and in the case of Microsoft, back-room services) that ran on it. There was no need to distinguish between a vertical strategy, in which apps and services served to differentiate the device, or a horizontal one, in which the device served to provide access to apps and services. When you are a monopoly, the answer to strategic choices can always be “Yes.”
Microsoft at that point in time no longer had that luxury: the company needed to make a choice — the days of doing everything were over — and that choice should be services (which is exactly what Satya Nadella did).
Ever since the emergence of ChatGPT made OpenAI The Accidental Consumer Tech Company I have been making similar arguments about OpenAI: they need to focus on the consumer opportunity and leave the enterprise API market to Microsoft. Not only would focus help the company capture the consumer opportunity, there was the opportunity cost of GPUs used for the API that couldn’t be used to deliver consumers a better experience across every tier.
I now have much more appreciation for OpenAI’s insistence on doing it all, for two reasons. First, this is a company in pure growth mode, not in decline. Tradeoffs are in the long run inevitable, but why make them before you need to? It would have been a mistake for Microsoft to restrict Windows to only the enterprise in the 1980s, even if the company had to low-key retreat from the consumer market over the last fifteen years; there was a lot of money to make before that retreat needed to happen! OpenAI, meanwhile, is the hottest brand in AI, so why not make a play to own it all, from consumer touchpoint to API to everything in-between?
Second, we’ve obviously crossed the line into bubble territory, which always was inevitable. The question now is whether or not this is a productive bubble: what durable infrastructure will be built by eventually bankrupt companies that we benefit from for years to come?
GPUs are not that durable infrastructure; data centers are more long-lasting, but not worth the financial pain of a bubble burst. The real payoff would be a massive build-out in power generation, which would be a benefit for the next half century. Another potential payoff would be the renewed viability of Intel, and as I noted above, OpenAI may be uniquely positioned and motivated to make that happen.
More broadly, this play to be the Windows of AI effectively positions OpenAI as the linchpin of the entire AI buildout. Just look at what the mere announcement of partnerships with OpenAI has done for the stocks of Oracle and AMD. OpenAI is creating the conditions such that it is the primary manifestation of the AI bubble, which ensures the company is the primary beneficiary of all of the speculative capital flooding into the space. Were the company more focused, as I have previously advised, they may not have the leverage to get enough funding to meet those more modest (but still incredible) goals; now it’s hard to see them not getting whatever money they want, at least until the bubble bursts.
What’s amazing about this overview is that I only scratched the surface of what OpenAI announced both yesterday and over the last month — and I haven’t even mentioned Sora (although I covered that topic yesterday). What the company is seeking to achieve is incredibly audacious, but also logical, and something we’ve seen before:
And, interestingly enough, there is an Apple to OpenAI’s Microsoft: it’s Google, with their fully integrated stack, from chips to data centers to models to end user distribution channels. Instead of taking on a menagerie of competitors, however, Google is facing an increasingly unified ecosystem, organized, whether they wish to be or not, around OpenAI. Such is the power of aggregating demand and the phenomenon that is ChatGPT.
Anyway, what’s different, and what I underestimated about Sora, is that the AI content here is not just randomly generated things. It’s content that’s either loaded with “cameos” from your connections or it’s “real” world content that’s, well, hilarious. Not all of it, of course. But a lot of it! In this regard, it’s really not too dissimilar from TikTok — and back in the day, Vine! This is a lot more like those social networks but with the main difference being that it’s a lot easier to create such content thanks to AI.
I think that’s the real revelation here. It’s less about consumption and more about creation. I previously wrote about how I was an early investor in Vine in part because it felt like it could be analogous to Instagram. Thanks in large part to filters, that app made it easy for anyone to think they were good enough to be a photographer. It didn’t matter if they were or not, they thought they were — I was one of them — so everyone posted their photos. Vine felt like it could have been that for video thanks to its clever tap-to-record mechanism. But actually, it became a network for a lot of really talented amateurs to figure out a new format for funny videos on the internet. When Twitter acquired the company and dropped the ball, TikTok took that idea and scaled it (thanks to ByteDance paying um, Meta billions of dollars for distribution, and their own very smart algorithms).
In a way, Sora feels like enabling everyone to be a TikTok creator.
I feel blessed for a whole host of reasons, many of them related to the fact I’ve been able to carve out a career as a creator. Sure, I call myself an analyst, and I write about primarily big tech companies, but one thing I realized over the years is that the success of Stratechery is tied to it being a creative endeavor; there have been a lot of analysts over the years who have launched similar sites, but what was often missing was the narrative element. The best Articles on Stratechery tell a story, with a beginning, middle, and end, and the analysis is along for the ride; analysis alone doesn’t move the needle.
That I tell stories is itself a function of the way I think: I have a larger meta story in my head about how the world works, and I’m always adding and augmenting that story; that’s why, in various interviews, I’ve noted that being wrong is often the most inspiring (albeit painful) place to be. That means my story is incomplete, and I need to deepen my understanding of the world I’m seeking to chronicle. I certainly have that opportunity right now.
Indeed, it feels like each company has an entirely different target audience: YouTube is making tools for creators, Meta is building the ultimate lean back dream-like experience, and OpenAI is making an app that is, in my estimation, the easiest for normal people to use.
In this new competition, I prefer the Meta experience, by a significant margin, and the reason why goes back to one of the oldest axioms in technology: the 90/9/1 rule.
90% of users consume
9% of users edit/distribute
1% of users create
If you were to categorize the target market of these three AI video entrants, you might say that YouTube is focused on the 1% of creators; OpenAI is focused on the 9% of editors/distributors; Meta is focused on the 90% of users who consume. Speaking as someone who is, at least for now, more interested in consuming AI content than in distributing or creating it, I find Meta’s Vibes app genuinely compelling; the Sora app feels like a parlor trick, if I’m being honest, and I tired of my feed pretty quickly. I’m going to refrain on passing judgment on YouTube, given that my current primary YouTube use case is watching vocal coaches break down songs from KPop Demon Hunters.
I honestly have no idea if my evaluation of these apps is broadly applicable; as I’ve noted repeatedly, I’m hesitant to make any pronouncements about what resonates with society broadly given that I am the weirdo in the room. Still, I do think it’s striking how this target market evaluation tracks with the companies themselves: YouTube has always prioritized creators, while OpenAI’s business model is predicated on people actively using AI; it’s Meta that has stayed focused on the silent majority that simply consumes, and as a silent consumer, I still like Vibes!
As I noted at the beginning, the verdict is in, and my evaluation of these apps is not broadly applicable. Way more people like Sora than Vibes, and OpenAI has another viral hit. What I hear from people who love the app, however, is very much in line with what Siegler wrote: yes, they are browsing the feed, but the real lure is losing surprisingly large amounts of time making content — Sora lets them be a content creator.
This was a blind spot for me because I don’t have that itch! I’m creating content constantly — three Articles/Updates, an Interview, and three podcast episodes a week is enough for me, thank you very much. When I am vegging out on my phone, I want to passively consume, and I personally found the Vibes mix of fantastical environments and beautiful visages calming and inspiring; almost everyone else feels different:
I had to laugh at this because I’ve spent way too much time watching Apple’s Aerial Video screensavers; apparently my tastes are consistent! Beyond that, however, is a second blind spot: how much of the 90/9/1 rule is a law of the universe, versus a manifestation of barriers when it comes to creation? At the risk of sounding like a snob, have I become the sort of 1%-er who is totally out of touch?
The AI Bicycle
Back in 2022, when AI image generation was just starting to get good, I wrote about The AI Unbundling and the idea propagation chain:
The evolution of human communication has been about removing whatever bottleneck is in this value chain. Before humans could write, information could only be conveyed orally; that meant that the creation, vocalization, delivery, and consumption of an idea were all one-and-the-same. Writing, though, unbundled consumption, increasing the number of people who could consume an idea.
Now the new bottleneck was duplication: to reach more people whatever was written had to be painstakingly duplicated by hand, which dramatically limited what ideas were recorded and preserved. The printing press removed this bottleneck, dramatically increasing the number of ideas that could be economically distributed:
The new bottleneck was distribution, which is to say this was the new place to make money; thus the aforementioned profitability of newspapers. That bottleneck, though, was removed by the Internet, which made distribution free and available to anyone.
What remains is one final bundle: the creation and substantiation of an idea. To use myself as an example, I have plenty of ideas, and thanks to the Internet, the ability to distribute them around the globe; however, I still need to write them down, just as an artist needs to create an image, or a musician needs to write a song. What is becoming increasingly clear, though, is that this too is a bottleneck that is on the verge of being removed.
This is what was unlocked by Sora: all sorts of people without the time or inclination or skills or equipment to make videos could suddenly do just that — and they absolutely loved it. And why wouldn’t they? To be creative is to be truly human — to actually think of something yourself, instead of simply passively consuming — and AI makes creativity as accessible as a simple prompt.
I think this is pretty remarkable, so much so that I’ve done a complete 180 on Sora: this new app from OpenAI may be the single most exciting manifestation of AI yet, and the most encouraging in terms of AI’s impact on humans. Everyone — including lots of people in my Sora feed — are leaning into the concept of AI slop, which I get: we are looking at a world of infinite machine-generated content, and a lot of it is going to be terrible.
At the same time, how incredible is it to give everyone with an iPhone a creative outlet? It reminds me of one of my favorite Steve Jobs moments, just before he died, at the introduction of the iPad 2; I wrote about it in 2024’s The Great Flattening:
My favorite moment in that keynote — one of my favorite Steve Jobs’ keynote moments ever, in fact — was the introduction of GarageBand. You can watch the entire introduction and demo, but the part that stands out in my memory is Jobs — clearly sick, in retrospect — moved by what the company had just produced:
I’m blown away with this stuff. Playing your own instruments, or using the smart instruments, anyone can make music now, in something that’s this thick and weighs 1.3 pounds. It’s unbelievable. GarageBand for iPad. Great set of features — again, this is no toy. This is something you can really use for real work. This is something that, I cannot tell you, how many hours teenagers are going to spend making music with this, and teaching themselves about music with this.
Jobs wasn’t wrong: global hits have originated on GarageBand, and undoubtedly many more hours of (mostly terrible, if my personal experience is any indication) amateur experimentation. Why I think this demo was so personally meaningful for Jobs, though, is that not only was GarageBand about music, one of his deepest passions, but it was also a manifestation of his life’s work: creating a bicycle for the mind.
I remember reading an Article when I was about 12 years old, I think it might have been in Scientific American, where they measured the efficiency of locomotion for all these species on planet earth. How many kilocalories did they expend to get from point A to point B, and the condor won: it came in at the top of the list, surpassed everything else. And humans came in about a third of the way down the list, which was not such a great showing for the crown of creation.
But somebody there had the imagination to test the efficiency of a human riding a bicycle. Human riding a bicycle blew away the condor, all the way off the top of the list. And it made a really big impression on me that we humans are tool builders, and that we can fashion tools that amplify these inherent abilities that we have to spectacular magnitudes, and so for me a computer has always been a bicycle of the mind, something that takes us far beyond our inherent abilities.
I think we’re just at the early stages of this tool, very early stages, and we’ve come only a very short distance, and it’s still in its formation, but already we’ve seen enormous changes, but I think that’s nothing compared to what’s coming in the next 100 years.
In Jobs’ view of the world, teenagers the world over are potential musicians, who might not be able to afford a piano or guitar or trumpet; if, though, they can get an iPad — now even thinner and lighter! — they can have access to everything they need. In this view “There’s an app for that” is profoundly empowering.
Well, now there’s an AI for that, and it’s accessible to everyone. And yes, I get the objections. I slave over these posts, thinking carefully about the structure and every word choice; it seems cheap to ask an LLM to generate the same. I’m certain that artists feel the same about AI images, or musicians about AI music, or YouTube and TikTok creators about Sora videos; what about the craft?
That, though, is an easy concern to have when you already have a creative outlet; it’s also easy to make the case that more content means more compelling content to consume, even if the percentage of what is great is very small.
What I didn’t fully appreciate, however, is what falls in the middle: the fact that so many more people get to be creators, and what a blessing that is. How many people have had ideas in their head, yet were incapable of substantiating them, and now can? I myself benefited greatly from the last unbundling — the ability for anyone to distribute content; why should I begrudge the latest unbundling, and the many more people who will benefit from AI substantiation of their creative impulses? Bicycles for all!
Instagram’s Social Umbrella
Siegler in his post discussed how he once thought Vine could be like Instagram, which made it easy to feel like a good photographer with its filters, but that was only step one; Chris Dixon described Instagram’s evolution as Come for the Tool, Stay for the Network:
A popular strategy for bootstrapping networks is what I like to call “come for the tool, stay for the network.” The idea is to initially attract users with a single-player tool and then, over time, get them to participate in a network. The tool helps get to initial critical mass. The network creates the long term value for users, and defensibility for the company.
Here are two historical examples: 1) Delicious. The single-player tool was a cloud service for your bookmarks. The multiplayer network was a tagging system for discovering and sharing links. 2) Instagram. Instagram’s initial hook was the innovative photo filters. At the time some other apps like Hipstamatic had filters but you had to pay for them. Instagram also made it easy to share your photos on other networks like Facebook and Twitter. But you could also share on Instagram’s network, which of course became the preferred way to use Instagram over time.
Dixon wrote that post in 2015, and Instagram has since gone much further than that, as I documented in 2021’s Instagram’s Evolution:
There was the tool to network evolution that Dixon talked about.
The second evolution was the addition of video.
The third evolution was the introduction of the algorithmic feed.
The fifth evolution was what I was writing about in that Article: the commitment to short-form video, driven by competition with TikTok.
That last evolution is fully baked in at this point; late last month Instagram announced that it was changing Instagram’s navigation to focus on private messaging and Reels; I didn’t explicitly cover the 2013 addition of Instagram Direct, but it certainly is the case that messaging is where social networking happens today. What is public is pure entertainment, where the content you see is pulled from across the network and tailored for you specifically.
I think this evolution was both necessary and inevitable; I first wrote that Facebook needed to move in this direction in 2015’s Facebook and the Feed:
Consider Facebook’s smartest acquisition, Instagram. The photo-sharing service is valuable because it is a network, but it initially got traction because of filters. Sometimes what gets you started is only a lever to what makes you valuable. What, though, lies beyond the network? That was Facebook’s starting point, and I think the answer to what lies beyond is clear: the entire online experience of over a billion people. Will Facebook seek to protect its network — and Zuckerberg’s vision — or make a play to be the television of mobile?
It wasn’t until TikTok peeled off a huge amount of attention that Facebook finally realized that viewing itself as a social network was actually limiting its potential. If the goal was to monopolize user attention — the only scarce resource on the Internet — then artificially limiting what people saw to their social network was to fight with one hand tied behind your back; TikTok was taking share not just because of its format, but also because it wasn’t really a social network at all.
This is all interesting context for how OpenAI characterized Sora in their introductory post: it’s a social app.
Today, we’re launching a new social iOS app just called “Sora,” powered by Sora 2. Inside the app, you can create, remix each other’s generations, discover new videos in a customizable Sora feed, and bring yourself or your friends in via cameos. With cameos, you can drop yourself straight into any Sora scene with remarkable fidelity after a short one-time video-and-audio recording in the app to verify your identity and capture your likeness…
This app is made to be used with your friends. Overwhelming feedback from testers is that cameos are what make this feel different and fun to use — you have to try it to really get it, but it is a new and unique way to communicate with people. We’re rolling this out as an invite-based app to make sure you come in with your friends. At a time when all major platforms are moving away from the social graph, we think cameos will reinforce community.
First, just because Meta needed to move beyond the social network doesn’t mean social networking isn’t still valuable, or appealing. As an analogy, consider the concept of a pricing umbrella: when something becomes more expensive, it opens up the market for a lower-priced competitor. In this case Instagram’s evolution has created a social umbrella: sure, Instagram content may be “better” by virtue of being pulled from anywhere, but that means there is now a space for a content app that is organized around friends.
Second, remember the creativity point above: one of the challenges of restricting Instagram content to just what your social network posted is that your social network may not post very many interesting things. That gap was initially filled by following influencers, but now Instagram simply goes out and finds what you are interested in without having to do anything. In Sora, however, your network is uniquely empowered to be creative, increasing the amount of interesting content in a network-mediated context (and, of course, Sora is also pulling from elsewhere as well to populate your feed).
What you’re seeing, if you squint, is disruption: Instagram has gone “up-market” in terms of content, leaving space for a new entrant; that new entrant, meanwhile, is not simply cheaper/smaller. Rather, it’s enabled by a new technological paradigm that lets it compete orthogonally with the incumbent. Granted, that new paradigm is very expensive, particularly compared to the content that Instagram gets for free, but the extent it restores value to your social network is notable.
Meta Concerns
I am on the record as being very bullish about the impact of AI on Meta’s business:
It’s good for their ad business in the short, medium, and long-term (and YouTube’s as well).
More content benefits the company with the most popular distribution channels.
AI will be the key to unlocking both AR and VR.
The key to everything, however, is maintaining the hold Meta has on user attention, and the release of both Vibes and Sora has me seriously questioning point number two.
One of the reasons why AI slop is so annoying is — paradoxically — the fact that a lot of it has gotten quite good. That means that when consuming content you have to continually be ascertaining if what you see is real or AI-generated; to put it in the terms of the Article I just quoted, you might want to lean back, but if you don’t want to be taken in or make a fool of yourself then you have to constantly be leaning forward to figure out what is or isn’t AI.
What this means for Vibes is the fact it is unapologetically and explicitly all AI is quite profound: it’s a true lean-back experience, where the fact none of it is real is a point of interest and — if Holz is right — inspiration and imagination. I find it quite relaxing to consume, in a way I don’t find almost any other feed on my phone.
The reason this is problematic for Meta (and YouTube) is that I’m not sure the company can counter Sora — or any other AI-generated content app that appears — in the same way they countered Snapchat and TikTok. Both challengers introduced new formats — Stories in the case of Instagram, and short-form video in the case of TikTok — but the content was still produced by humans; that made it much more palatable to stuff those formats into Instagram.
AI might be different: Meta certainly has data on this question, but I could imagine a scenario where users are actually annoyed and turned off by mixing AI-generated content with human content — and because Instagram isn’t really a social network anymore, the fact that that content might be made by or include your friends might not be enough. Implicit in this observation is the fact that I don’t think that human content is going anywhere; there just might be a smaller percentage of time devoted to it, and that’s a problem for a company predicated on marshaling attention.
The second issue for Meta is that their AI capabilities simply don’t match OpenAI, or Google’s for that matter. It’s clear that Meta knows this is the case — look no further than this summer’s hiring spree and total overhaul of their AI approach — but creating something like Sora is a lot more difficult than copying Stories or short-form video. I imagine this shortcoming will be rectified, but Sora is in the market now.
I also think that it is fair to raise some questions about point three. I have been a vocal proponent of AI being the key to the Metaverse, but my tastes in content may not be very broadly applicable! I loved Vibes because to me it felt like virtual reality, but if it was virtual reality, and no one liked it, maybe the concept actually isn’t that appealing? Time will tell, but I do keep coming back to the social aspects of Sora: people like the real world, and they like people they know, and virtual reality in particular just might not be that broadly popular.
It turns out I was right last quarter that Meta had a lot of room to increase Reels monetization, but not just because they could target ads better (that was a part of it, as I noted above): rather, it turns out that short-form video is so addictive that Meta can simply drive more engagement — and thus more ad inventory — by pushing more of it. That’s impression driver number one — and the most important one. The second one is even more explicit: Meta simply started showing more ads to people (i.e. “ad load optimization”).
All of this ties back to where I started, about how Meta learned that you have to give investors short term results to get permission for long term investments. I don’t think it’s a coincidence that, in the same quarter where Meta decided to very publicly up its investment in the speculative “Superintelligence”, users got pushed more Reels and Facebook users in particular got shown more ads. The positive spin on this is that Meta has dials to turn; by the same token, investors who have flipped from intrinsically doubting Meta to intrinsically trusting them should realize that it was the pre-2022 Meta, the one that regularly voiced the importance of not pushing too many ads in order to preserve the user experience, that actually deserved the benefit of the doubt for growth that was purely organic. This last quarter is, to my mind, a bit more pre-determined.
As profound as the abundance produced by AI may one day be, an even more meaningful impact on our lives will likely come from everyone having a personal superintelligence that helps you achieve your goals, create what you want to see in the world, experience any adventure, be a better friend to those you care about, and grow to become the person you aspire to be.
Meta’s vision is to bring personal superintelligence to everyone. We believe in putting this power in people’s hands to direct it towards what they value in their own lives.
This is distinct from others in the industry who believe superintelligence should be directed centrally towards automating all valuable work, and then humanity will live on a dole of its output. At Meta, we believe that people pursuing their individual aspirations is how we have always made progress expanding prosperity, science, health, and culture. This will be increasingly important in the future as well.
I agree with the sentiment, but it’s worth being honest about today’s reality: Meta’s financial fortunes, at least for now, are in fact tied up in a centralized content engine that gives users “a dole of its output”; it’s nice from an investor perspective that Meta can turn the dials and get people to spend that much more time in Instagram. I for one can’t say that I feel particularly great when I’m done watching Reels for longer than I planned, and it’s certainly not a creative endeavor on my part — that’s for the content creators.
OpenAI, meanwhile, with both ChatGPT and Sora, is in fact placing easily accessible tools in people’s hands today, first with text and now with video. And, as I noted above, I actually find it exciting precisely because of the possibility that many more people are on the verge of discovering a creativity streak they didn’t even know they had, now that AI is available to substantiate it. So much Meta optimism is, paradoxically, pessimistic about the human condition; it may be the case that, to the extent that AI makes humans better, is the extent that Meta faces disruption.
Action is happening up-and-down the LLM stack: Nvidia is making deals with Intel, OpenAI is making deals with Oracle, and Nvidia and OpenAI are making deals with each other. Nine years after Nvidia CEO Jensen Huang hand-delivered the first Nvidia DGX-1 AI computer to OpenAI, the chip giant is investing up to $100 billion in the AI lab, which OpenAI will, of course, spend on Nvidia AI systems.
This ouroboros of a deal certainly does feel a bit frothy, but there is a certain logic to it: Nvidia is uniquely dominant in AI thanks to the company’s multi-year investment in not just superior chips but also an entire ecosystem from networking to software, and has the cash flow and stock price befitting its position in the AI value chain. Doing a deal like this at this point in time not only secures the company’s largest customer — and rumored ASIC maker — but also gives Nvidia equity upside beyond the number of chips it can manufacture. More broadly, lots of public investors would like the chance to invest in OpenAI; I don’t think Nvidia’s public market investors are bothered to have now acquired that stake indirectly.
The interconnectedness of these investments reflects the interconnectedness of the OpenAI and Nvidia stories in particular: Huang may have delivered OpenAI their first AI computer, but it was OpenAI that delivered Nvidia the catalyst for becoming the most valuable company in the world, with the November 2022 launch of ChatGPT. Ever since, the assumption of many in tech has been that the consumer market in particular has been OpenAI’s to lose, or perhaps more accurately, monetize; no company has ever grown faster in terms of users and revenue, and that’s before they had an advertising model!
And beyond the numbers, have you used ChatGPT? It’s so useful. You can look up information, or format text, and best of all you can code! Of course there are other models like Anthropic’s Claude, which has excelled at coding in particular, but surely the sheer usefulness makes ultimate success inevitable!
A Brief History of Social Media
If a lot of those takes sound familiar, it’s because I’ve made some version of most of them; I also, perhaps relatedly, took to Twitter like a fish to water. Just imagine, an app that was the nearly perfect mixture of content I was interested in and people I wanted to hear from, and interact with. Best of all it was text: the efficiency of information acquisition was unmatched, and it was just as easy to say my piece.
It took me much longer to warm up to Facebook, and, frankly, I never was much of a user; I’ve never been one to image dump episodes of my life, nor have I had much inclination to wade through others’. I wasn’t interested in party photos; I lusted after ideas and arguments, and Twitter — a view shared by much of both tech and media — was much more up my alley.
Despite that personal predilection, however, and perhaps because of my background in small town Wisconsin and subsequently living abroad, I retained a strong sense of the importance of Facebook. Sure, the people who I was most interested in hearing from and interacting with may have been the types to leave their friends and family for the big city, but for most people, friends and family were the entire point of life generally, and by extension, social media specifically.
To that end, I was convinced from the beginning that Facebook was going to be a huge deal, and argued so multiple times on Stratechery; social media was ultimately a matter of network effects and scale, and Facebook was clearly on the path to domination, even as much of the Twitterati were convinced the company was the next MySpace. I was similarly bullish about Instagram: no, I wasn’t one to post a lot of personal pictures, but while I personally loved text, most people liked photos.
What people really liked most of all, however — and not even Facebook saw this coming — was video. TikTok grew into a behemoth with the insight that social media was only ever a stepping stone to personal entertainment, of which video was the pinnacle. There were no network effects of the sort that everyone — including regulators — assumed would lead to eternal Facebook dominance; rather, TikTok realized that Paul Krugman’s infamous dismissal of the Internet actually was somewhat right: most people actually don’t have anything to say that is particularly compelling, which means that limiting the content you see to your social network dramatically decreases the possibility you’ll be entertained every time you open your social networking app. TikTok dispensed with this artificial limitation, simply showing you compelling videos period, no matter where they came from.
The Giant in Plain Sight
Of course TikTok wasn’t the first company to figure this out: YouTube was the first video platform, and from the beginning focused on building an algorithm that focused more on giving you videos you were interested in than in showing you what you claimed to want to see.
YouTube, however, was and probably always has been my biggest blind spot: I’m just not a big video watcher in general, and YouTube seemed like more work than short-form video, which married the most compelling medium with the most addictive delivery method — the feed. Sure, YouTube was a great acquisition for Google — certainly in line with the charge to “organize the world’s information and make it universally accessible and useful” — but I — and Google’s moneymaker, Search — was much more interested in text, and pictures if I must.
The truth, however, is that YouTube has long been the giant hiding in plain sight: the service is the number one streaming service in the living room — bigger than Netflix — and that’s the company’s 3rd screen after mobile and the PC, where it has no peer. More than that, YouTube is not just the center of culture, but the nurturer of it: the company just announced that it has paid out more than $100 billion to creators over the last four years; given that many creators earn more from brand deals than they do from YouTube ads, that actually understates the size of the YouTube economy. Yes, TikTok is a big deal, but TikTok stars hope to make it on YouTube, where they can actually make a living.
And yet, YouTube sometimes seems like an afterthought, at least to people like me and others immersed in the text-based Internet. Last week I was in New York for YouTube’s annual “Made on YouTube” event, but the night before I couldn’t remember the name; I turned to Google, natch, and couldn’t figure it out. The reason is that talk about YouTube mostly happens on YouTube; I, and Google itself, still live in a text-based world.
That is the world that was rocked by ChatGPT, especially Google. The company’s February 2023 introduction of Bard in Paris remains one of the most surreal keynotes I’ve ever watched: most of the content was rehashed, the presenters talked as if they were seeing their slides for the first time, and one of the demos of a phone-based feature neglected to remember to have a phone on hand. This was a company facing a frontal assault on their most obvious and profitable area of dominance — text-based information retrieval — and they were completely flat-footed.
Google has, in the intervening years, made tremendous strides to come back, including dumping the Bard name in favor of Gemini, itself based on vastly improved underlying models. I’m also impressed by how the company has incorporated AI into search; not only are AI Overviews generally useful, they’re also incredibly fast, and as a bonus have the links I sometimes prefer already at hand. Ironically, however, you could make the case that the biggest impact LLMs have had on Search is giving a federal judge an excuse to let Google continue paying its biggest would-be competitors (like Apple) to simply offer their customers Google instead. The biggest reason to be skeptical of the company’s fortunes in AI is that they had the most to lose; the company is doing an excellent job of minimizing the losses.
What I would submit, however, is that Google’s most important and most compelling AI announcements actually don’t have anything to do with Search, at least not yet. These announcements start, as you might expect, with Google’s Deep Mind Research Lab; where they hit the real world, however, is on YouTube — and that, like the user-generated streaming service, is a really big deal.
The DeepMind-to-YouTube Pipeline
A perfect example of the DeepMind-to-YouTube pipeline was last week’s announcement of Veo 3-based features for making YouTube Shorts. From the company’s blog post:
We’ve partnered with Google DeepMind to bring a custom version of their most powerful video generation model, Veo 3, to YouTube. Veo 3 Fast is designed to work seamlessly in YouTube Shorts for millions of creators and users, for free. It generates outputs with lower latency at 480p so you can easily create video clips – and for the first time, with sound – from any idea, all from your phone.
This initial launch will allow you to not only generate videos, but also use one video to animate another (or a photo), stylize your video with a single touch, and add objects. You can also create an entire video — complete with voiceover — from a collection of clips, or convert speech to song. All of these features are a bit silly, but, well, that’s often where genius — or at least virality — comes from.
Critics, of course, will label this an AI slop machine, and they’ll be right! The vast majority of content created by these tools will be boring and unwatched. That, however, is already the case with YouTube: the service sees 500 hours of content uploaded every minute, and most of that content isn’t interesting to anyone; the magic of YouTube, however, is the algorithm that finds out what is actually compelling and spreads it to an audience that wants exactly that.
To put it another way, for YouTube AI slop is a strategy credit: given that the service has already mastered organizing overwhelming amounts of content and only surfacing what is good, it, more than anyone else, can handle exponentially more content which, through the sheer force of numbers, will result in an absolute increase of content that is actually compelling.
That’s not the only strategy credit YouTube has; while the cost of producing AI-generated video will likely be lower than the cost of producing human-generated video, at least in the long run, the latter’s costs are not borne by TikTok or Meta (Facebook and Instagram are basically video platforms at this point). Rather, the brilliance of the user-generated content model is that creators post their content for free! This, however, means that AI-generated video is actually more expensive, at least if it’s made on TikTok or Meta’s servers. YouTube, however, pays its creators, which means that for the service AI-generated video actually has the potential to lower costs in the long run, increasing the incentive to leverage DeepMind’s industry-leading models.
In short, while everyone immediately saw how AI could be disruptive to Search, AI is very much a sustaining innovation for YouTube: it increases the amount of compelling content in absolute terms, and it does so with better margins, at least in the long run.
Here’s the millionbillion trillion dollar question: what is going to matter more in the long run, text or video? Sure, Google would like to dominate everything, but if it had to choose, is it better to dominate video or dominate text? The history of social networking that I documented above suggests that video is, in the long run, much more compelling to many more people.
To put it another way, the things that people in tech and media are interested in has not historically been aligned with what actually makes for the largest service or makes the most money: people like me, or those reading me, care about text and ideas; the services that matter specialize in videos and entertainment, and to the extent that AI matters for the latter YouTube is primed to be the biggest winner, even as the same people who couldn’t understand why Twitter didn’t measure up to Facebook go ga-ga over text generation and coding capabilities.
AI Monetization
The potential impact of AI on YouTube’s fortunes isn’t just about AI-created videos; rather, the most important announcement of last week’s event was the first indicator that AI can massively increase the monetization potential of every video on the streaming service. You might have missed the announcement, because YouTube underplayed it; from their event blog post:
We’re adding updates to brand deals and Shopping to make brand collaborations easier than ever. We’re accelerating these deals through a new initiative and new product features to make sure those partnerships succeed – like the ability to add a link to a brand’s site in Shorts. And YouTube Shopping is expanding to more markets and merchants and getting help from AI to make tagging easier.
It’s just half a sentence — “getting help from AI to make tagging easier” — but the implications of those eight words are profound; here’s how YouTube explained the feature:
We know tagging products can be time-consuming, so to make the experience better for creators, we’re leaning on an AI-powered system to identify the optimal moment a product is mentioned and automatically display the product tag at that time, capturing viewer interest when it’s highest. We’ll also begin testing the ability to automatically identify and tag all eligible products mentioned in your video later this year.
The creator who demonstrated the feature — that right there is a great example of how YouTube is a different world than the one I and other people in the media inhabit — was very enthusiastic about the reduction in hassle and time-savings that would come from using AI to do a menial task like tagging sponsored products; that sounds like AI at its best, freeing up creative people to do what they do best.
There’s no reason, however, why auto-tagging can’t become something much greater; in fact, I already explained the implications of this exact technology in explaining why AI made me bullish on Meta:
This leads to a third medium-term AI-derived benefit that Meta will enjoy: at some point ads will be indistinguishable from content. You can already see the outlines of that given I’ve discussed both generative ads and generative content; they’re the same thing! That image that is personalized to you just might happen to include a sweater or a belt that Meta knows you probably want; simply click-to-buy.
It’s not just generative content, though: AI can figure out what is in other content, including authentic photos and videos. Suddenly every item in that influencer photo can be labeled and linked — provided the supplier bought into the black box, of course — making not just every piece of generative AI a potential ad, but every piece of content period.
The market implications of this are profound. One of the oddities of analyzing digital ad platforms is that some of the most important indicators are counterintuitive; I wrote this spring:
The most optimistic time for Meta’s advertising business is, counter-intuitively, when the price-per-ad is dropping, because that means that impressions are increasing. This means that Meta is creating new long-term revenue opportunities, even as its ads become cost competitive with more of its competitors; it’s also notable that this is the point when previous investor freak-outs have happened.
When I wrote that I was, as I noted in the introduction, feeling more cautious about Meta’s business, given that Reels is built out and the inventory opportunities of Meta AI were not immediately obvious. I realize now, though, that I was distracted by Meta AI: the real impact of AI is to make everything inventory, which is to say that the price-per-ad on Meta will approach $0 for basically forever. Would-be competitors are finding it difficult enough to compete with Meta’s userbase and resources in a probabilisitic world; to do so with basically zero price umbrella seems all-but-impossible.
This analysis was spot-on; I just pointed it at the wrong company. This opportunity to leverage AI to make basically every pixel monetizable absolutely exists for Meta; Meta, however, has to actually develop the models and infrastructure to do it at scale. Google is already there; it was the company universally decried for being slow-moving that announced the first version of this feature last week.
I can’t overstate what a massive opportunity this is: every item in every YouTube video is well on its way to being a monetizable surface. Yes, that may sound dystopian when I put it so baldly, but if you think about it you can see the benefits; I’ve been watching a lot of home improvement videos lately, and it sure would be useful to be able to not just identify but helpfully have a link to buy a lot of the equipment I see, much of which is basically in the background because it’s not the point of the video. It won’t be long until YouTube has that inventory, which it could surface with an affiliate fee link, or make biddable for companies who want to reach primed customers.
More generally, you can actually envision Google pulling this off: the company may have gotten off to a horrible start in the chatbot era, but the company has pulled itself together and is increasingly bringing its model and infrastructure leadership to bear, even as Meta has had to completely overhaul their AI approach after hitting a wall. I’m sure CEO Mark Zuckerberg will figure it out, but Google — surprise! — is the company actually shipping.
A Bull’s Journey
Or, rather, YouTube is. Close readers of Stratechery have been observing — and probably, deservedly, smirking — at this most unexpected evolution:
And, by the same token, I’m much more appreciative of Google’s amorphous nature and seeming lack of strategy. That makes them hard to analyze — again, I’ve been honest for years about the challenges I find in understanding Mountain View — but the company successfully navigated one paradigm shift, and is doing much better than I originally expected with this one. Larry Page and Sergey Brin famously weren’t particularly interested in business or in running a company; they just wanted to do cool things with computers in a college-like environment like they had at Stanford. That the company, nearly thirty years later, is still doing cool things with computers in a college-like environment may be maddening to analysts like me who want clarity and efficiency; it also may be the key to not just surviving but winning across multiple paradigms.
Appreciating the benefits of Google being an amorphous blob where no one knows what is going on, least of all leadership, is a big part of my evolution; this Article is the second part: that blob ultimately needs a way to manifest the technology it manages to come up with, and if you were to distill my worries about Google in the age of AI it would be to wonder how the company could become an answer machine — which Page and Brin always wanted — when it risked losing the massive economic benefits that came from empowering users to choose the winners of auctions Google conducted for advertisers.
That, however, is ultimately the text-based world, and there’s a case to be made that, in the long run, it simply won’t matter as much as the world of video. Again, the company is doing better with Search than I expected, and I’ve always been bullish about the impact of AI on the company’s cloud business; the piece I’ve missed, however, is that Google already has the tip of the spear for its AI excellence to actually go supernova: YouTube, the hidden giant in plain sight, a business that is simultaneously unfathomably large, and also just getting started.
The base iPhone 17 finally gets some key features from the Pro line, including the 120Hz Promotion display (the lack of which stopped me from buying the most beautiful iPhone ever). The iPhone Air, meanwhile, is a marvel of engineering: transforming the necessary but regretful camera bump into an entire module that houses all of the phone’s compute is Apple at its best, and reminiscent of how the company elevated the necessity of a front camera assembly into the digital island, a genuinely useful user interface component.
The existence of the iPhone Air, meanwhile, seems to have given the company permission to fully lean into the “Pro” part of the iPhone Pro. I think the return to aluminum is a welcome one (and if the unibody construction is as transformative as it was for MacBooks, the feel of the phone should be a big step up), the “vapor chamber” should alleviate one of the biggest problems with previous Pro models and provide a meaningful boost in performance, and despite focusing on cameras every year for years, the latest module seems like a big step up (and the square sensor in the selfie camera is a brilliant if overdue idea). Oh, and the Air’s price point — $999, the former starting price for the Pro — finally gave Apple the opening to increase the Pro’s price by $100.
And, I must add, it’s nice to have a retort to everyone complaining about size and weight: if that is what is important to you, get an Air! I’ll take my (truly) all-day battery life and giant screen, thank you very much, and did I mention that the flagship color is Stratechery orange?
What was weird to me yesterday, however, is that my enthusiasm over Apple’s announcement didn’t seem to be broadly shared. There was lots of moaning and groaning about weight and size (get an iPhone Air!), gripes about the lack of changes year-over-year, and general boredom with the pre-recorded presentation (OK, that’s a fair one, but at least Apple ventured to some other cities instead of endlessly filming in and around San Francisco). This post on Threads captured the sentiment:
This is honestly very confusing to me: the content of the post is totally contradicted by the image! Just look at the features listed:
There is a completely new body material and design
There is a new faster chip, with GPUs actually designed for AI workloads (a reminder that Apple’s neural engine was designed for much more basic machine learning algorithms, not LLMs)
There is a 50% increase in RAM
The front camera sensor has 2x the pixels, and is square
The telephoto lense has 4x the pixels, allowing for 8x hardware zoom
There is a much larger battery, thanks to the Pro borrowing the Air’s trick of bundling all of the electronics in a larger yet more aesthetically pleasing plateau
There is much better cooling, allowing for better sustained performance
There is faster charging
This is a lot more than a 10% difference over last year’s phone! Basically every aspect of the iPhone Pro got better, and did I mention the Stratechery orange?
I could stop there, playing the part of the analytics nerd, smugly asserting my list of numbers and features to tell everyone that they’re wrong, and, when it comes to the core question of the year-over-year improvement in iPhone hardware, I would be right! I think, however, that the widespread insistence that this was a blah update — even when the reality is otherwise — exposes another kind of truth: people are calling this update boring not because the iPhones 17 aren’t great, but because Apple no longer captures the imagination.
Apple in the Background
One of the advantages of living abroad is how you gain a new perspective on your home country; one of the surprises of moving back is running head-on into accumulated gradual changes that most people may not have noticed as they happened, but that you experience all at once.
To that end, I have, for the last several years, noted how, from a Stratechery perspective, iPhone launches just aren’t nearly as big of a deal as they were when I first started. Back then I would spend weeks before the event predicting what Apple would announce, and would spend weeks afterwards breaking down the implications; now I usually dash off an Update that, in recent years, has been dominated by discussions about price and elasticity and Apple’s transition to being a services company.
What was shocking to me, however, was actually watching the event in real time: my group chats and X feed acknowledged that the event was happening, but I had the distinct impression that almost no one was paying much attention, which was not at all the case a decade ago. And, particularly when it comes to tech discussion, you can understand why: by far the biggest thing in tech — and on Stratechery — is AI, and Apple simply isn’t a meaningful player.
Indeed, the most important news they have made has been their announcement that they were significantly delaying major features that they promised (and advertised!) as a part of Apple Intelligence, followed by a string of news and rumors about reorganizations and talent losses, and questions about whether or not they should partner with or acquire AI companies to do what Apple seems incapable of doing themselves. Until those questions are rectified, why should anyone who cares about AI — which is to say basically everyone else in the industry — care about square camera sensors or vapor chambers?
Apple’s Enviable Position
I can, if I put my business analyst hat on, make the case that Apple is doing better than ever, and not just in terms of making money. One underdiscussed takeaway from this year’s announcements is that the company, which originally had the iPhone on a two-year refresh cycle in terms of industrial design, before slipping to a three-year cycle (X/XS/11 and 12/13/14) over the last decade, is back to two years: the iPhones 15 and 16 were the same, but the iPhone 17 Pro in particular is completely new, and there is a completely new model in the Air as well. That suggests a company that is gaining vigor, not losing it.
Meanwhile, there is the aforementioned Services business, which is growing inexorably, thanks both to the continually growing installed base, and the fact that people continue to spend more time on their phones, not less. Yes, a lot of that Services growth comes from Google traffic acquisition cost payments and App Store fees, but those aren’t necessarily a bad thing: the former speaks to Apple’s dominant position in the attention value chain, and the former not only to the company’s hold on payments, but also the massive growth that has happened in new business models like subscriptions.
Moreover, you can further make the case that the fundamentals that drive those businesses mean that Apple is poised to be a winner in AI, even if Apple Intelligence is delayed: Apple is positioned to be kingmaker — or gatekeeper — to AI companies who need a massive userbase to justify their astronomical investments, and to the extent that subscriptions are a core piece of the AI monetization puzzle is the extent to which the App Store is positioned for even more recurring revenue growth.
And besides, isn’t it a good thing that Apple is unique amongst its Big Tech peers in having dramatically lower capital expenditures, even as they are making just as much money as ever? Since when did it become a crime to not just maintain but actually grow profit margins, as Apple has for the last several years?
The Cost of Pure Profit
Back when I started Stratechery — and back when iPhone launches were the most important days in all of tech — Apple was locked into tooth-and-nail competition with Google for the smartphone space. And, in the midst of that battle, Google made a critical error: for several years in the early 2010s the company forgot that the point of Android was to ensure access to Google services, and started using Google services to differentiate Android in its fight with the iPhone.
The most famous example was Google Maps, a version of which launched with the iPhone. When it came time to re-up the deal Google wanted too much data and the ability to insert too many ads for Apple’s liking, so the latter launched its own product — which sucked, particularly at the beginning. Over time, however, Apple Maps has become a very competent product, and critically, it’s the default on iPhones. The implication of that is not that Apple won, but rather that Google lost: maps are a critical source of useful data for an advertising company, and Google lost a huge amount of useful signal from its most valuable users.
The most important outcome of the early smartphone wars, however, particularly the Maps fiasco, was the extent to which both companies determined to not make the same mistake again: Google would ensure that iPhones were a first-class client for its services, and would pay ever more money for the right to be the default for Search in particular. Apple, meanwhile, seemed to get the even better end of the deal: the company would simply not compete with Google, and add those payments directly to its bottom line.
What I think is under-appreciated, however, is that the old cliché is true: nothing is free. Apple paid a price for those payments, but it’s not one that has shown up on the bottom line, at least not yet. I wrote about Maps last year in Friendly Google and Enemy Remedies and concluded:
The lesson Google learned was that Apple’s distribution advantages mattered a lot, which by extension meant it was better to be Apple’s friend than its enemy…It has certainly been profitable for Apple, which has seen its high-margin services revenue skyrocket, thanks in part to the ~$20 billion per year of pure profit it gets from Google without needing to make any level of commensurate investment.
That right there is the cost I’m referring to: the investment Apple might have made in a search engine to compete with Google are not costs that, once spent, are gone forever, like jewels in an iPhone game; rather, the reason it’s called an “investment” is that it pays off in the long run.
The most immediate potential payoff would have been search ad revenues that Apple might have earned in an alternate timeline where they competed with Google instead of getting paid off by them. This, to be sure, would likely have been less on both the top and especially bottom lines, so skepticism about the attractiveness of this approach is fair.
There is, however, another sort of payoff that comes from this kind of investment, and that’s the accumulation of knowledge and capabilities inherent in building products. In this case, Apple completely forewent any sort of knowledge or capability accumulation in terms of gathering, reasoning across, and serving large amounts of data; when you put it that way, is it any surprise that the company suddenly finds itself on the back foot when it comes to AI? Apple is suddenly trying to flex muscles that were, by-and-large, unimportant for the company’s core iPhone business because Google took care of it; had the company been competing in search for the last decade — even if they weren’t as good as Google — they would likely at a minimum have a functional Siri!
This gets at the most amazing paradox of Mehta’s reasoning for not banning Google payments. Mehta wrote:
If adopted, the remedy would pose a substantial risk of harm to OEMs, carriers, and browser developers…Distributors would be put to an untenable choice: either (1) continue to place Google in default and preferred positions without receiving any revenue or (2) enter distribution agreements with lesser-quality GSEs to ensure that some payments continue. Both options entail serious risk of harm.
This is certainly true when it comes to small-scale outfits like Mozilla; Mehta, however, was worried about Apple as well. This was the second in Mehta’s list of “significant downstream effects…possibly dire” that might result from banning Google payments:
Fewer products and less product innovation from Apple. Rem. Tr. at 3831:7-10 (Cue) (stating that the loss of revenue share would “impact [Apple’s] ability at creating new products and new capabilities into the [operating system] itself”). The loss of revenue share “just lets [Apple] do less.” Id. at 3831:19 (Cue).
This is obviously not true in an absolute sense: Apple made just shy of $100 billion in profit over the last 12 months; losing ~20% of that would hurt, but the company would still have money to spend. Of course, you might make the case that it is true in practice, since investors might not tolerate the loss of margins that ending the Google deal would entail, which might compel management to decrease what it spends on innovation. I tend to think that investors would actually punish Apple more for innovating less, but that’s not the point I’m focused on.
Rather, what Judge Mehta seems oblivious to is the extent to which his downstream fears already manifested. Apple has had fewer products and less innovation precisely because they have been paid off by Google, and worse, that lack of investment is compounding with the rise of AI.
The Sugar Water Trap
Apple took the liberty of opening yesterday’s presentation with a classic Steve Jobs quote:
Setting aside the wisdom of using that quote when the company is about to launch a controversial new user interface design that critics complain sacrifices legibility for beauty (although, to be honest, I don’t think it looks great either), that wasn’t the Steve Jobs quote this presentation and Apple’s general state of affairs made me think of. What I was thinking of was the question Jobs posed to then PepsiCo President John Sculley when he was recruiting him to be the CEO of Apple in the early 1980s:
Do you want to sell sugar water for the rest of your life or come with me and change the world?
The problem, however, is that simply staying in their lane, content to be a hardware provider for the delivery of others’ innovation, feels a lot more like Sculley than Jobs. Jobs told Walter Isaacson for his biography:
My passion has been to build an enduring company where people were motivated to make great products. Everything else was secondary. Sure, it was great to make a profit, because that was what allowed you to make great products. But the products, not the profits, were the motivation. Sculley flipped these priorities to where the goal was to make money. It’s a subtle difference, but it ends up meaning everything: the people you hire, who gets promoted, what you discuss in meetings.
Apple, to be fair, isn’t selling the same sugar water year-after-year in a zero sum war with other sugar water companies. Their sugar water is getting better, and I think this year’s seasonal concoction is particularly tasty. What is inescapable, however, is that while the company does still make new products — I definitely plan on getting new AirPods Pro 3s! — the company has, in pursuit of easy profits, constrained the space in which it innovates.
That didn’t matter for a long time: smartphones were the center of innovation, and Apple was consequently the center of the tech universe. Now, however, Apple is increasingly on the periphery, and I think that, more than anything, is what bums people out: no, Apple may not be a sugar water purveyor, but they are farther than they have been in years from changing the world.
Now that everyone is using ChatGPT, the lazy columnist’s trick of quoting Wikipedia to open an Article is less cliché than it is charming (at least that’s my excuse). Anyhow, here is Wikipedia’s definition of “steelmanning”:
A steel man argument (or steelmanning) is the opposite of a straw man argument. Steelmanning is the practice of applying the rhetorical principle of charity through addressing the strongest form of the other person’s argument, even if it is not the one they explicitly presented. Creating the strongest form of the opponent’s argument may involve removing flawed assumptions that could be easily refuted or developing the strongest points which counter one’s own position. Developing counters to steel man arguments may produce a stronger argument for one’s own position.
President Donald Trump’s announcement on Friday that the U.S. government will take a 10 percent stake in long-struggling Intel marks a dangerous turn in American industrial policy. Decades of market-oriented principles have been abandoned in favor of unprecedented government ownership of private enterprise. Sold as a pragmatic and fiscally responsible way to shore up national security, the $8.9 billion equity investment marks a troubling departure from the economic policies that made America prosperous and the world’s undisputed technological leader.
Lincicome lists a number of problems with this transaction, including (but not limited to!):
Intel making decisions for political rather than commercial considerations
Intel’s board prioritizing government interests over their fiduciary duties
Other companies being pressured to purchase Intel products, weakening their long-term position.
Disadvantaging the competitive position of other companies
Incentivizing the misallocation of private capital
Lincicome and all of the other critics of this deal are absolutely correct about all of the downsides. The problem with their argument, however, is the lack of steelmanning, in two respects: first, Lincicome’s Twitter thread doesn’t mention “China” or “Taiwan” once (the Washington Post column mentions China, but not in a national security context). Second, Lincicome et al refuse to grapple with the possibility that chips generally, and foundries specifically, really are a unique case.
The Geopolitical Case
There is a reason I’ve written so much about chips, and for many years before the AI wave brought the industry to prominence; start with 2020’s Chips and Geopolitics:
The international status of Taiwan is, as they say, complicated. So, for that matter, are U.S.-China relations. These two things can and do overlap to make entirely new, even more complicated complications.
Geography is much more straightforward:
Taiwan, you will note, is just off the coast of China. South Korea, home to Samsung, which also makes the highest end chips, although mostly for its own use, is just as close. The United States, meanwhile, is on the other side of the Pacific Ocean. There are advanced foundries in Oregon, New Mexico, and Arizona, but they are operated by Intel, and Intel makes chips for its own integrated use cases only.
The reason this matters is because chips matter for many use cases outside of PCs and servers — Intel’s focus — which is to say that TSMC matters. Nearly every piece of equipment these days, military or otherwise, has a processor inside. Some of these don’t require particularly high performance, and can be manufactured by fabs built years ago all over the U.S. and across the world; others, though, require the most advanced processes, which means they must be manufactured in Taiwan by TSMC.
This is a big problem if you are a U.S. military planner. Your job is not to figure out if there will ever be a war between the U.S. and China, but to plan for an eventuality you hope never occurs. And in that planning the fact that TSMC’s foundries — and Samsung’s — are within easy reach of Chinese missiles is a major issue.
The rise of AI makes these realities — and related issues like chip controls — even more pressing. I made the argument earlier this year in AI Promise and Chip Precariousness that the U.S. should be seeking to make China more dependent on both U.S. chip companies and TSMC manufacturing, even as it was doing the opposite. The motivation was to preserve dominance in AI, but this ignored the reality I just laid out: AI depends on chips, and those chips are made next door to China; that means that stopping China could be worse than China succeeding:
It’s also worth noting that success in stopping China’s AI efforts has its own risks: another reason why China has held off from moving against Taiwan is the knowledge that every year they wait increases their relative advantages in all the real world realities I listed above; that makes it more prudent to wait. The prospect of the U.S. developing the sort of AI that matters in a military context, however, even as China is cut off, changes that calculus: now the prudent course is to move sooner rather than later, particularly if the U.S. is dependent on Taiwan for the chips that make that AI possible.
Beyond the human calamity that would result from a Chinese attack on Taiwan, there is the economic calamity downstream of not just losing AI chips, but chips of all sorts, including the basic semiconductors that power not just computers but basically everything in the world. And, to that end, it’s worth pointing out that an Intel that succeeds doesn’t fully address our chip dependency on Taiwan. It is, however, a pre-requisite, and any argument about the U.S. government’s involvement with Intel must grapple with this reality.
Decisions Over Decades
There was one line in Lincicome’s Article that definitely made me raise my eyebrows (emphasis mine):
The semiconductor industry, more than most, requires nimble responses to rapidly changing technology and market conditions. Intel already faces significant operational and competitive challenges; it has been a technological laggard for more than a decade as Nvidia, AMD, TSMC and other competitors have raced ahead. Adding a layer of political oversight to Intel’s already-complex turnaround effort is far more likely to hinder than help.
I get Lincicome’s point, which certainly applies to the technology industry broadly; just look at all of the upheaval that has happened in the two-and-a-half years since ChatGPT launched. I would argue, however, that chips are different: Intel is a technological laggard because of choices made decades ago; it just takes a really long time for the consequences of mistakes to show up.
Starting a new blog is a bit like a band publishing their debut album: you’re full of takes that you’ve held for years and have been waiting to unleash. In my case, I had been worried about Intel ever since they missed out on mobile, which meant they missed out on the associated volume that came from making chips for every smartphone in the world. Volume is critical when it comes to managing the ever-expanding cost of staying on the leading edge: as the cost of fabs has surged from hundreds of millions to tens of billions of dollars, the only way to fab chips profitably is to have enough volume over which to spread those massive capital expenditures.
And so, within a month of launching Stratechery, I wrote that Intel needed to become a foundry — i.e. make chips for other companies — if they wanted to remain viable in the long run. And, to be honest, I had been saving up that take for so long that I thought I was too late; after all, I started Stratechery in 2013, six years into the mobile era, and given the massive changes Intel would have to undergo to become a customer service organization, I thought they needed to make that change at least three years earlier.
In the end, however, my take was correct, even if it was un-investable. First Intel fell behind TSMC, who was powered by massive orders from Apple in particular, and then, on the company’s last earnings call, CEO Lip-Bu Tan admitted the reality of what could have been forecasted when Steve Jobs walked onto that 2007 MacWorld stage:
Up to and through Intel 18A, we could generate a reasonable return on our investments with only Intel Products. The increase in capital cost at Intel 14A, make it clear that we need both Intel products, and a meaningful external customer to drive acceptable returns on our deployed capital, and I will only invest when I’m confident those returns exist.
This is the rotten tree sprung from the seed of Intel’s mobile failure: the company could afford to miss out on a massive market for nearly two decades, but when it comes to 14A, the company simply can’t sell enough chips on its own to justify the investment.
What is worse is the tree that wasn’t planted: the real payoff from Intel building a foundry business in 2010, or 2013 as I recommended, is that they would have been ready for the AI boom. Every hyperscaler is still complaining that demand exceeds supply for AI chips, even as Intel can’t win customers for its newest process that is actually best-suited for AI chips. The company simply has too many other holes in its offering, including the sort of reliability and throughput that is essential to earning customer trust.
In short, contra Lincicome, Intel’s problem is not short-term decision-making, because Intel is in the business of making chips, and making chips is a decades-long endeavor of building expertise, gaining volume, moving down the learning curve, and doing it all again and again to the tune of tens of billions of dollars a year in capex.
That, by extension, is why the stakes today are so high. The problem facing the U.S. is not simply the short-term: the real problems will arise in the 2030s and beyond. Semiconductor manufacturing decision-making does not require nimbleness; it requires gravity and the knowledge that abandoning the leading edge entails never regaining it.
Competing with TSMC
This also puts to rest one of the traditional objections to government intervention in support of an incumbent: in almost every case that investment crowds out new companies, companies that are, yes, more nimble and more capable of meeting the moment. The reality of semiconductor manufacturing, however, is that the path is far too long and arduous to ever fill the vacuum that Intel’s exit would leave. Actually, though, that last line is not quite right: Intel’s biggest problem is that its market challenges are closer to that mythical startup that will never exist.
Suppose our mythical startup somehow received hundreds of billions of dollars worth of funding, and somehow moved down the decades-long learning curve that undergirds modern silicon manufacturing: to make the business work our mythical startup would actually need to find customers.
Our mythical startup, however, doesn’t exist in a vacuum: it exists in the same world as TSMC, the company who has defined the modern pure play foundry. TSMC has put in the years, and they’ve put in the money; TSMC has the unparalleled customer service approach that created the entire fabless chip industry; and, critically, TSMC, just as they did in the mobile era, is aggressively investing to meet the AI moment. If you’re an Nvidia, or an Apple in smartphones, or an AMD or a Qualcomm, why would you take the chance of fabricating your chips anywhere else? Sure, TSMC is raising prices in the face of massive demand, but the overall cost of a chip in a system is still quite small; is it worth risking your entire business to save a few dollars for worse performance with a worse customer experience that costs you time to market and potentially catastrophic product failures?
We know our mythical startup would face these challenges because they are the exact challenges Intel faces. Intel may need “a meaningful external customer to drive acceptable returns on [its] deployed capital”, but Intel’s needs do not drive the decision-making of those external customers, despite the fact that Intel, while not fully caught up to TSMC, is at least in the ballpark, something no startup could hope to achieve for decades.
The problem, however, comes back to what Tan said on that earnings call: beyond all of the challenges above, what company is going to go through the trouble of getting their chip working on Intel’s process if it’s possible that the company is going to abandon manufacturing on the next process? It’s a catch-22: Intel needs an external customer to make its foundry viable, but no external customer will go with Intel if there is a possibility that Intel Foundry will not be viable. In other words, the stakes have changed from even earlier this year: Intel doesn’t just need demand, it needs to be able to credibly guarantee would-be customers that it is in manufacturing for the long haul.
A standalone Intel cannot credibly make this promise. The path of least resistance for Intel has always been to simply give up manufacturing and become another TSMC customer; they already fab some number of their chips with the Taiwanese giant. Such a decision would — after some very difficult write-offs and wind-down operations — change the company into a much higher margin business; yes, the company’s chip designs have fallen behind as well, but at least they would be on the most competitive process, with a lot of their legacy customer base still on their side.
The problem for the U.S. is that that then means pinning all of the country’s long-term chip fabrication hopes on TSMC and Samsung not just building fabs in the United States, but also building up a credible organization in the U.S. that could withstand the loss of their headquarters and engineering knowhow in their home countries. There have been some important steps in this regard, but at the end of the day it seems reckless for the U.S. to place both its national security and its entire economy in the hands of foreign countries next door to China, allies or not.
Given all of this, acquiring 10% of Intel, terrible though it may be for all of the reasons Lincicome articulates — and I haven’t even touched on the legality of this move — is I think the least bad option. In fact, you can even make the case that a lot of what Lincicome views as a problem has silver linings:
Intel deciding to stay in manufacturing is arguably making a political decision, not a commercial one; however, it is important for the U.S. that Intel stay in manufacturing.
Intel prioritizing government interests — which are inherently focused on national security and the long-term viability of U.S. semiconductor manufacturing — over their fiduciary duties could just as easily be framed as valuing the long-term over the short term; had Intel done just that over the last two decades they wouldn’t be in this position.
Other companies being pressured to purchase Intel products is exactly what Intel needs to not just be viable in manufacturing, but also to actually get better.
If TSMC and Samsung are disadvantaged by not making chips in the U.S., that’s a good thing from the U.S. perspective. Both companies are investing here; the U.S. wants more.
Private capital prioritizing U.S. manufacturing is a good thing!
The single most important reason for the U.S. to own part of Intel, however, is the implicit promise that Intel Foundry is not going anywhere. There simply isn’t a credible way to make that promise without having skin in the game, and that is now the case.
Steelmanning
I’ll be honest: there is a very good chance this won’t work. Intel really is a mess: they are actively hostile to customers, no one in the industry trusts them, they prioritize the wrong things even today (i.e. technical innovation with backside power over yields for chips which don’t necessarily have interference issues), and that’s even without getting into the many problems with their business. Moreover, I led with Lincicome’s argument because I agree! Government involvement in private business almost always ends badly.
At the same time, the China concerns are real, Intel Foundry needs a guarantee of existence to even court customers, and there really is no coming back from an exit. There won’t be a startup to fill Intel’s place. The U.S. will be completely dependent on foreign companies for the most important products on earth, and while everything may seem fine for the next five, ten, or even fifteen years, the seeds of that failure will eventually sprout, just like those 2007 seeds sprouted for Intel over the last couple of years. The only difference is that the repercussions of this failure will be catastrophic not for the U.S.’s leading semiconductor company, but for the U.S. itself.