Here was my “Your Year with ChatGPT” 2025 stats:
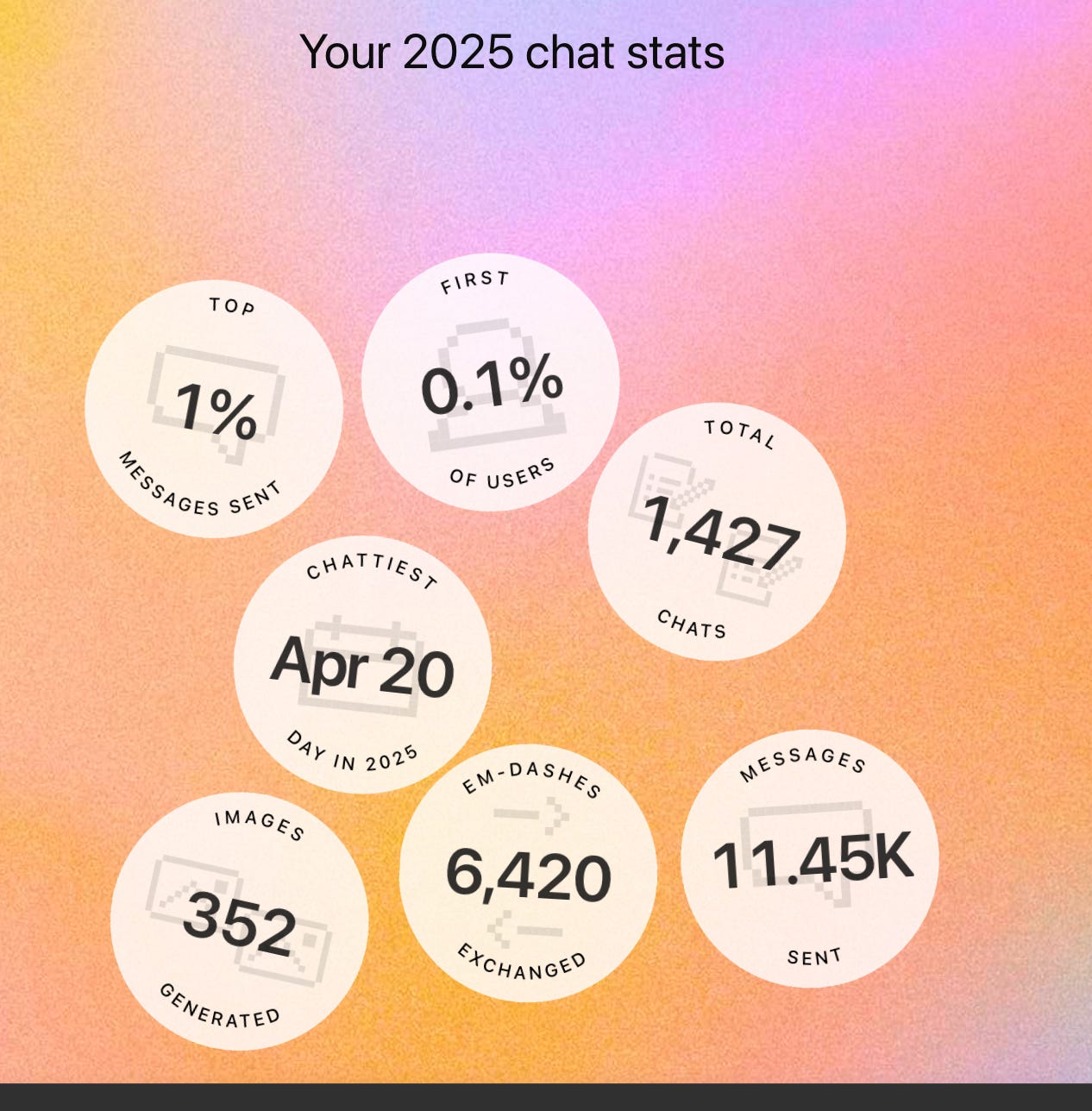
I was shocked to see myself in the top 1% of messages sent and top 0.1% of users (however that’s measured), and my best guess is that I have two use cases most users don’t: asking software engineering questions and asking very specific, individual-company-based-on-SEC-filings questions. Both use cases center on very dense, technical artifacts: code and financial statements. In each case, understanding the ins and outs is truly difficult, and at least for me requires asking tons of questions to LLMs, verifying the answers against documents, rephrasing my questions, rechecking answers, etc.
So, my use cases rather than some affinity for AI put me in the “power user” bracket. I never expected to send 11,450+ messages to ChatGPT going into this year (30+ questions per day)1. Analyzing my own behavior, I clearly felt the technology was useful enough to continue using it and want to analyze why in this post. Before I talk about the good, I want …