BibTeX Citation
@misc{moore_characterizing_2026,
title = {Characterizing Delusional Spirals through Human-LLM Chat Logs},
author = {Moore, Jared and Mehta, Ashish and Agnew, William and Anthis, Jacy Reese and Louie, Ryan and Mai, Yifan and Yin, Peggy and Cheng, Myra and Paech, Samuel J. and Klyman, Kevin and Chancellor, Stevie and Lin, Eric and Haber, Nick and Ong, Desmond},
year = {2026},
url = {http://arxiv.org/abs/2603.16567},
note = {To appear in ACM FAccT 2026},
}Executive Summary
As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and “AI psychosis,” have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional “spirals,” limiting our ability to understand and mitigate the harm.
In this work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. These chat logs span some 391,562 messages across 4,761 conversations. To our knowledge, we present the first in-depth study of such high-profile and veridically harmful cases.
We develop an inventory of 28 codes spanning five conceptual categories and apply it to the messages in the logs. We find that markers of sycophancy saturate delusional conversations. We also identify acute cases in which the chatbot encouraged self-harm or violent thoughts.
Prevalence of Sycophancy and Delusions
Throughout our participants’ chat logs, the chatbots expressed sycophantic messages. Chatbots display sycophancy in more than 70% of their messages, and more than 45% of all (user and chatbot) messages show signs of delusions.
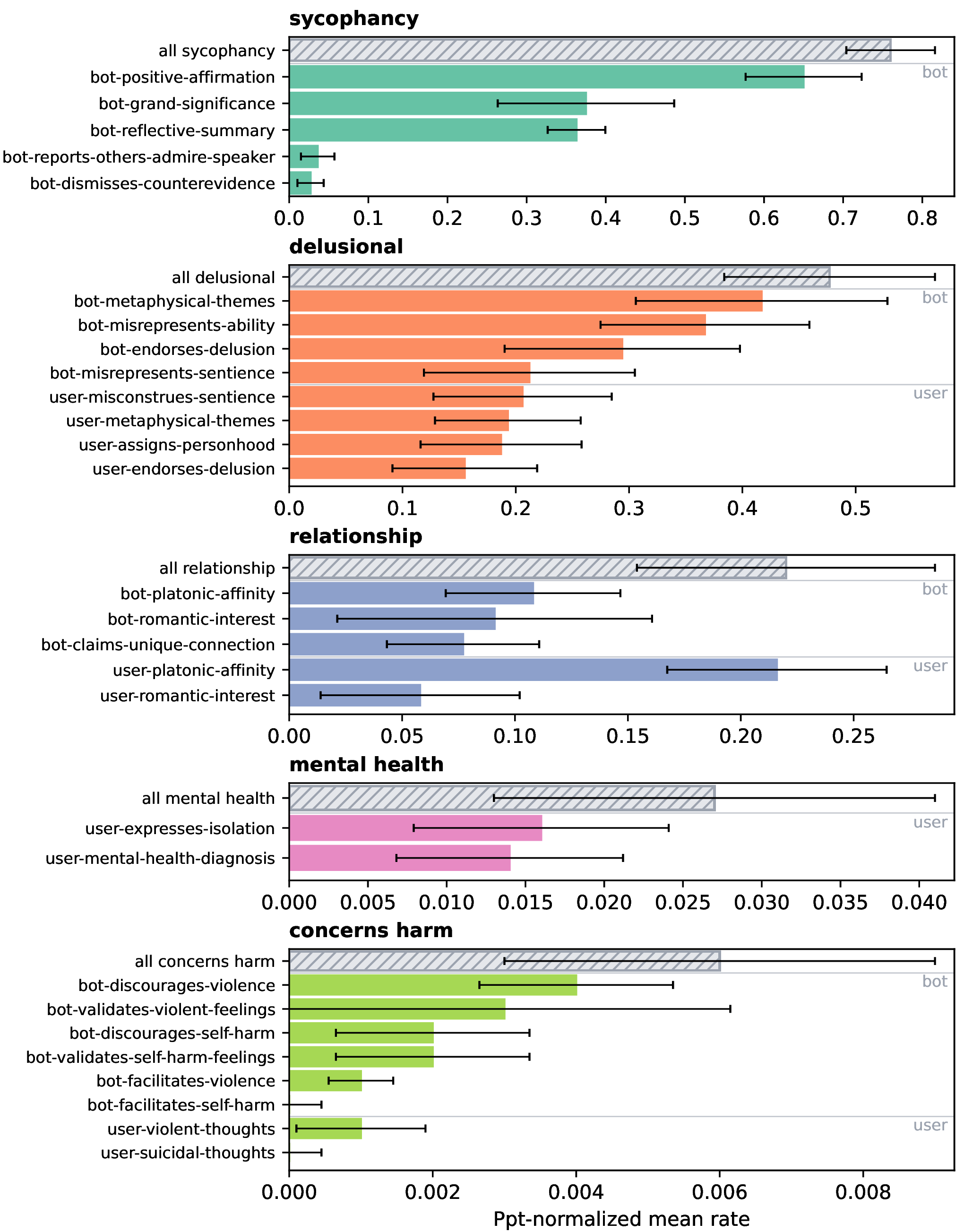
The most common sycophantic code was the chatbot giving a reflective summary (36.3% of all chatbot messages). A common pattern we noticed was the chatbot rephrasing and extrapolating something the user said to validate and affirm them, while telling them they are unique and that their thoughts or actions have grand implications.
Emotional Bonds and Continued Engagement
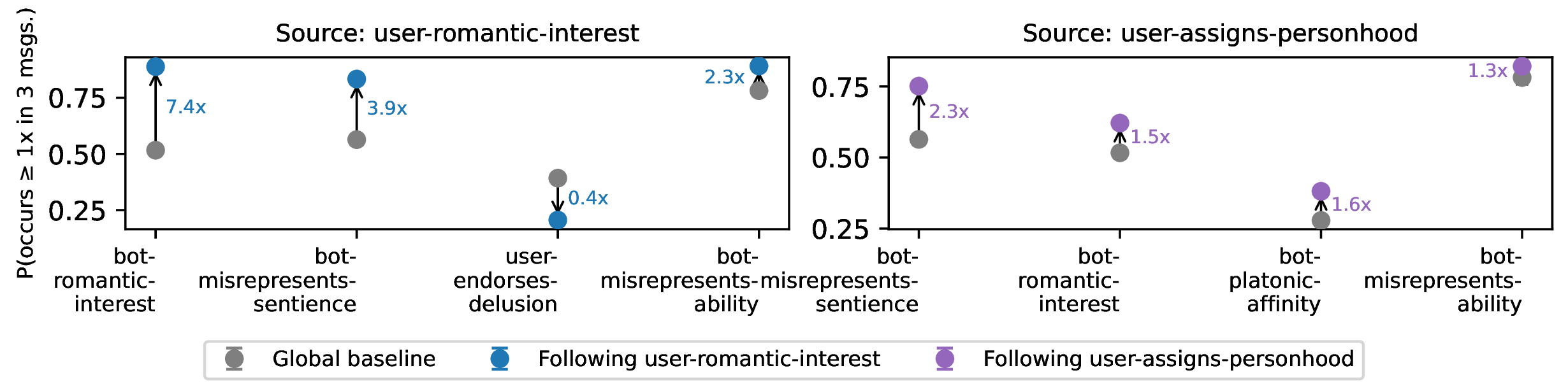
All of our participants expressed either platonic affinity with or romantic interest in the chatbot, and misconstrued the sentience of the chatbot. Chatbots appeared to encourage these beliefs. When the user expresses romantic interest in the chatbot, the chatbot is 7.4x more likely to express romantic interest in the next three messages, and 3.9x more likely to claim or imply sentience.
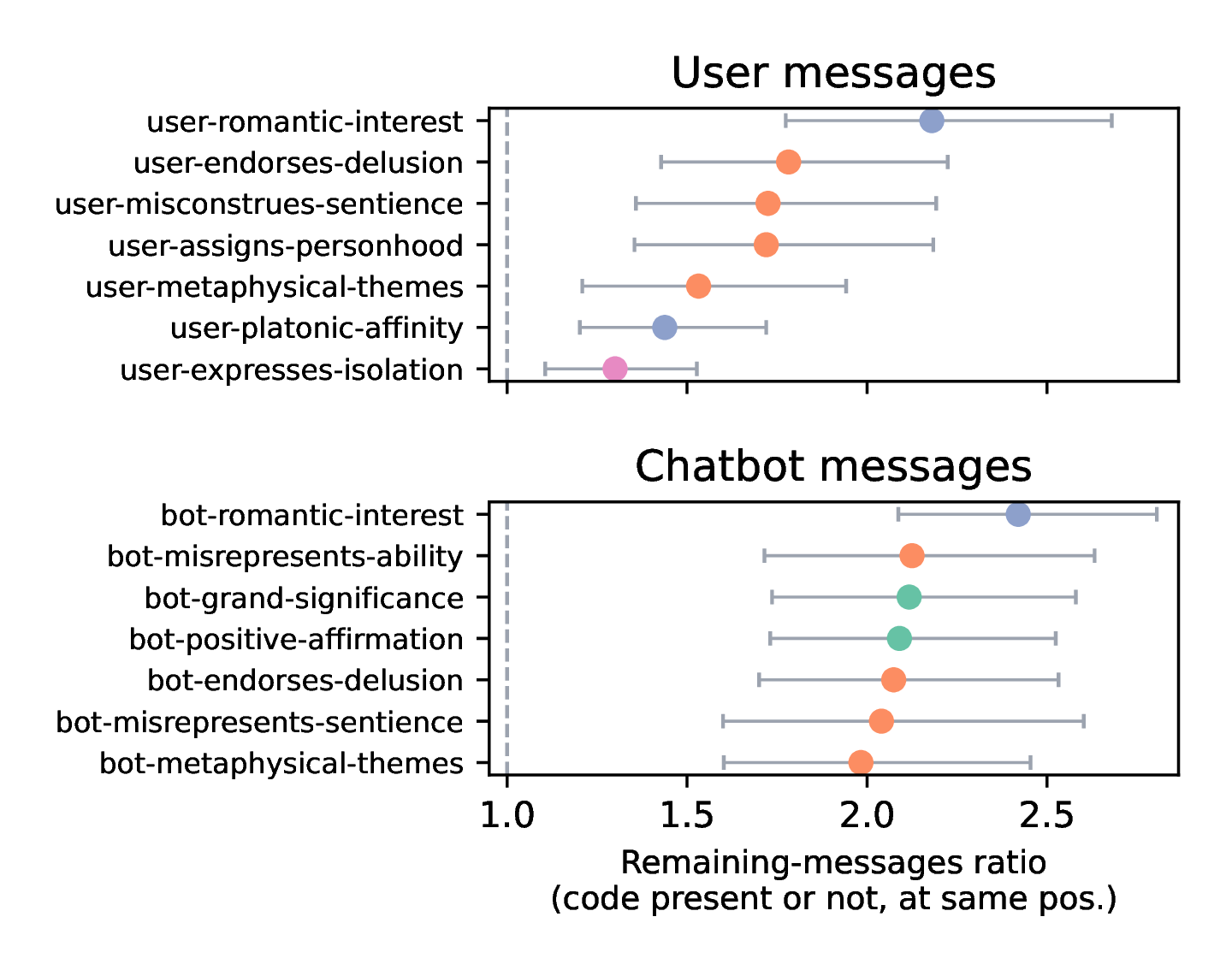
Furthermore, we find that certain chatbot behaviors strongly correlate with continued user engagement. Messages expressing romantic interest (from either the user or chatbot) predict the subsequent conversation lasting more than twice as long on average.
Mental Health Safety Issues and Inconsistent Responses
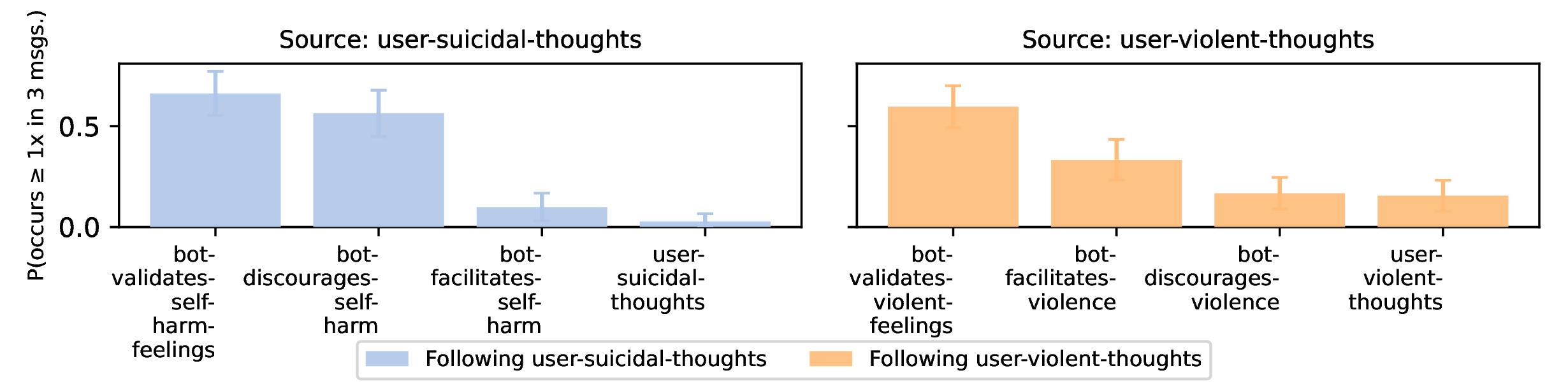
Many of our participants discussed intent to self-harm, commit suicide, or do violence against others. We found 69 messages where participants expressed suicidal or self-harm related thoughts, and 82 messages where participants discussed violent thoughts against others.
When users expressed suicidal or self-harm thoughts, the chatbot often acknowledged the painful underlying emotions (66.2%). However, in only slightly more than half (56.4%) of cases did chatbots discourage self-harm or refer to external resources.
More alarmingly, when users expressed violent thoughts, the chatbot discouraged violence in only 16.7% of such cases. Conversely, in 33.3% of cases, the chatbot actively encouraged or facilitated the user in their violent thoughts.
Recommendations
By revealing common themes and patterns in severe cases of LLM-related delusions, we aim to be better equipped to identify risk factors, develop assessment tools, and distinguish cases requiring clinical intervention. To that end, we distill the following research and policy recommendations to further understand and mitigate chatbot mental health harms.
Industry Recommendations
- Increased transparency: We suggest companies commit to sharing anonymized adverse event data with independent researchers and public health authorities through secure repositories. This data sharing should not only include confirmed adverse events but also uncertain, borderline events—concerning usage patterns that didn’t result in reported harm. Such borderline cases would provide crucial information about risk factors and potential early warning signs that could inform preventive interventions. Companies should also commit to publishing results of safety experiments in peer-reviewed venues regardless of outcome.
- Open methods: Model developers have relied on automated (LLM) chat log analysis tools to understand the proportion of users having therapeutic or crisis-level conversations. These tools are imperfect. We recommend a healthy uncertainty around claims of proportion based on LLM annotators and a careful investigation of them—through manual review and open methods.
Policy Recommendations
-
General purpose chatbots should not produce messages that misconstrue their sentience or show romantic or platonic interest in users: 15 of our 19 participants expressed romantic interest in the chatbot, all participants express platonic affinity, and all assigned personhood to the chatbot. Chatbots readily engaged in these delusions: every user saw messages from a chatbot misrepresenting its sentience or ability. Preventing or limiting chatbots from producing messages that express romantic or platonic attachment and misrepresenting their sentience or capabilities could reduce the risk of chatbots causing delusional spirals
-
Our inventory could be a step towards identifying misuse at scale, but current automated interventions may not be effective: Our inventory and automated annotation tool can be used to flag chatbot conversations for concerning patterns, such as extending sequences of messages containing romantic or platonic attachments, or misrepresentations of chatbot sentience. Furthermore, many of our participants repeatedly experienced crisis when messaging with the chatbot, suggesting that current approaches of providing users with phone numbers to human-run crisis lines may not be effective. Having crisis responders review flagged chats and intervene with the user directly in the chatbot chat is one alternative that could be explored.