Transcript
-
ABOUT ME
-
DISSERTATION Let's make something cool!
-
SOCIAL MEDIA + MACHINE LEARNING + API
-
SENTIMENT ANALYSIS AS A SERVICE A STEP-BY-STEP GUIDE
-
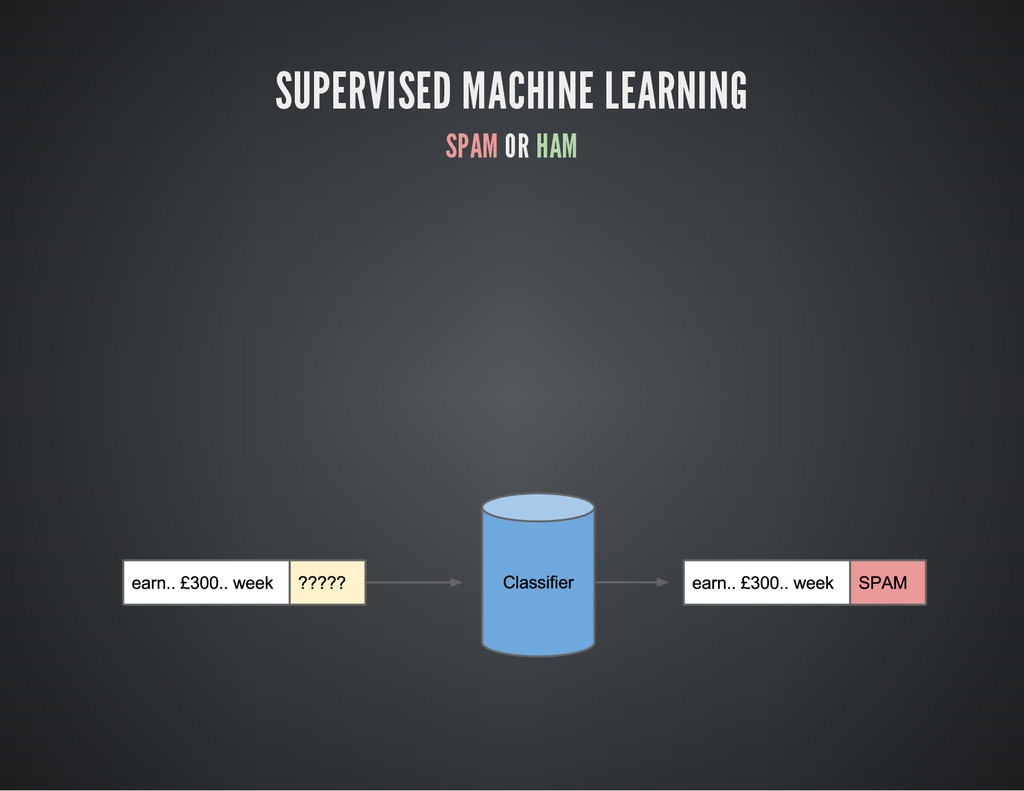
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
SUPERVISED MACHINE LEARNING SPAM OR HAM
-
NATURAL LANGUAGE PROCESSING SOME NLTK FEATURES Tokentization Stopword Removal >
> > p h r a s e = " I w i s h t o b u y s p e c i f i e d p r o d u c t s o r s e r v i c e " > > > p h r a s e = n l p . t o k e n i z e ( p h r a s e ) > > > p h r a s e [ ' I ' , ' w i s h ' , ' t o ' , ' b u y ' , ' s p e c i f i e d ' , ' p r o d u c t s ' , ' o r ' , ' s e r v i c e ' ] > > > p h r a s e = n l p . r e m o v e _ s t o p w o r d s ( t o k e n i z e d _ p h r a s e ) > > > p h r a s e [ ' I ' , ' w i s h ' , ' b u y ' , ' s p e c i f i e d ' , ' p r o d u c t s ' , ' s e r v i c e ' ]
-
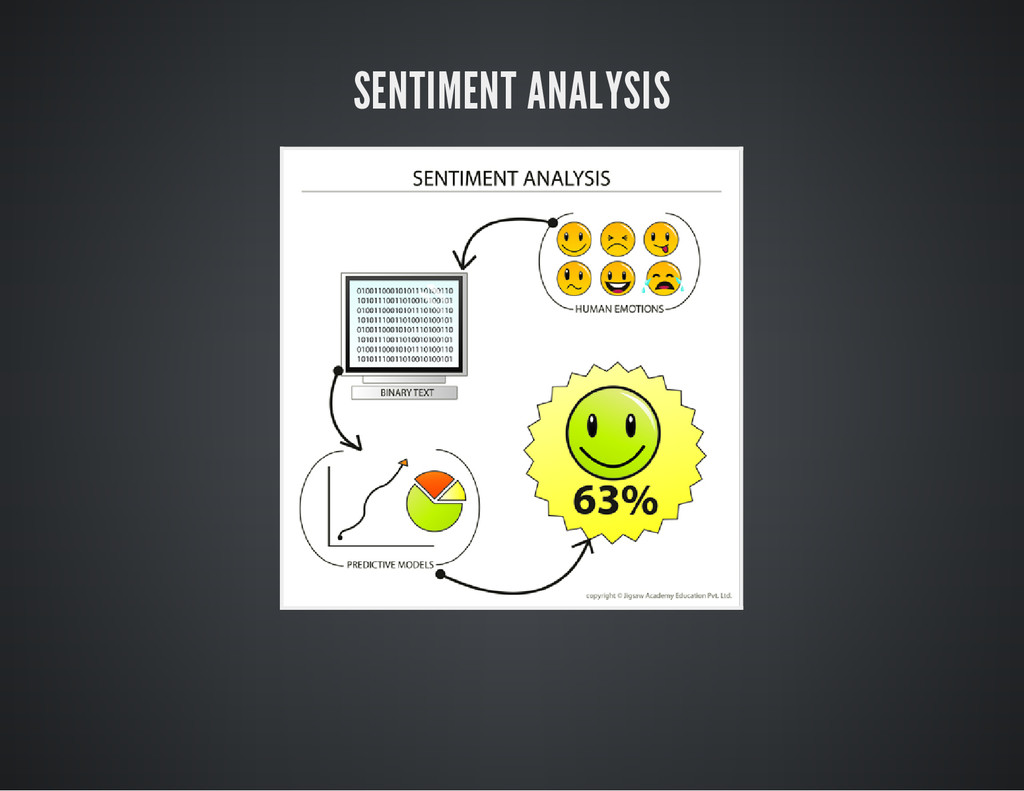
SENTIMENT ANALYSIS
-
BACK TO BUILDING OUR API .. FINALLY!
-
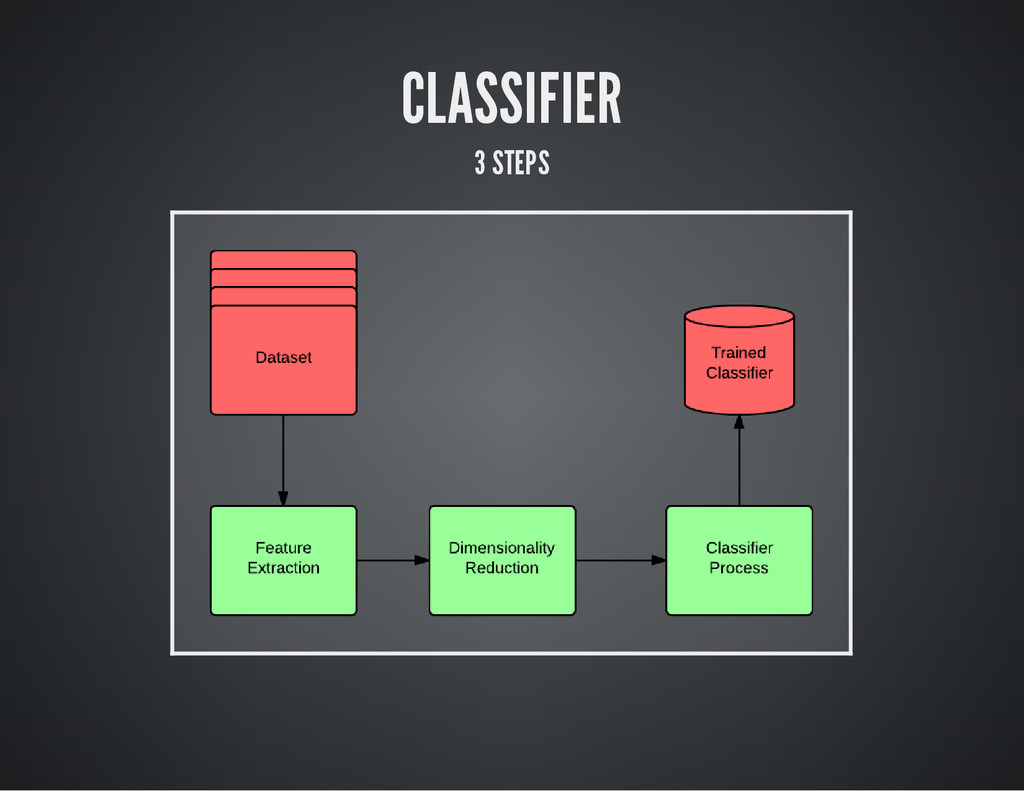
CLASSIFIER 3 STEPS
-
FEATURE EXTRACTION How are we going to find features from
a phrase? "Bag of Words" representation m y _ p h r a s e = " T o d a y w a s s u c h a r a i n y a n d h o r r i b l e d a y " I n [ 1 2 ] : f r o m n l t k i m p o r t w o r d _ t o k e n i z e I n [ 1 3 ] : w o r d _ t o k e n i z e ( m y _ p h r a s e ) O u t [ 1 3 ] : [ ' T o d a y ' , ' w a s ' , ' s u c h ' , ' a ' , ' r a i n y ' , ' a n d ' , ' h o r r i b l e ' , ' d a y ' ]
-
FEATURE EXTRACTION CREATE A PIPELINE OF FEATURE EXTRACTORS F O
R M A T T E R = f o r m a t t i n g . F o r m a t t e r P i p e l i n e ( f o r m a t t i n g . m a k e _ l o w e r c a s e , f o r m a t t i n g . s t r i p _ u r l s , f o r m a t t i n g . s t r i p _ h a s h t a g s , f o r m a t t i n g . s t r i p _ n a m e s , f o r m a t t i n g . r e m o v e _ r e p e t i t o n s , f o r m a t t i n g . r e p l a c e _ h t m l _ e n t i t i e s , f o r m a t t i n g . s t r i p _ n o n c h a r s , f u n c t o o l s . p a r t i a l ( f o r m a t t i n g . r e m o v e _ n o i s e , s t o p w o r d s = s t o p w o r d s . w o r d s ( ' e n g l i s h ' ) + [ ' r t ' ] ) , f u n c t o o l s . p a r t i a l ( f o r m a t t i n g . s t e m _ w o r d s , s t e m m e r = n l t k . s t e m . p o r t e r . P o r t e r S t e m m e r ( ) ) )
-
FEATURE EXTRACTION PASS THE REPRESENTATION DOWN THE PIPELINE I n
[ 1 1 ] : f e a t u r e _ e x t r a c t o r . e x t r a c t ( " T o d a y w a s s u c h a r a i n y a n d h o r r i b l e d a y " ) O u t [ 1 1 ] : { ' d a y ' : T r u e , ' h o r r i b l ' : T r u e , ' r a i n i ' : T r u e , ' t o d a y ' : T r u e } The result is a dictionary of variable length, containing keys as features and values as always True
-
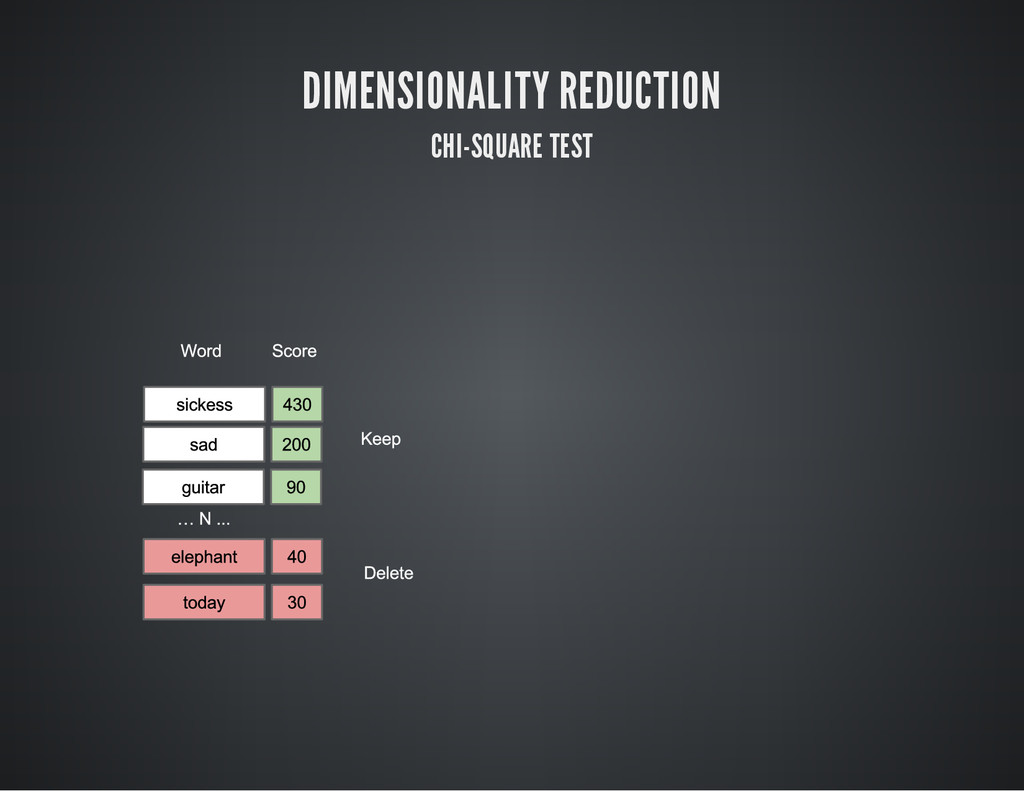
DIMENSIONALITY REDUCTION CHI-SQUARE TEST
-
DIMENSIONALITY REDUCTION CHI-SQUARE TEST
-
DIMENSIONALITY REDUCTION CHI-SQUARE TEST
-
DIMENSIONALITY REDUCTION CHI-SQUARE TEST
-
DIMENSIONALITY REDUCTION CHI-SQUARE TEST
-
NLTK gives us BigramAssocMeasures.chi_sq DIMENSIONALITY REDUCTION CHI-SQUARE TEST # C
a l c u l a t e t h e n u m b e r o f w o r d s f o r e a c h c l a s s p o s _ w o r d _ c o u n t = l a b e l _ w o r d _ f d [ ' p o s ' ] . N ( ) n e g _ w o r d _ c o u n t = l a b e l _ w o r d _ f d [ ' n e g ' ] . N ( ) t o t a l _ w o r d _ c o u n t = p o s _ w o r d _ c o u n t + n e g _ w o r d _ c o u n t # F o r e a c h w o r d a n d i t ' s t o t a l o c c u r a n c e f o r w o r d , f r e q i n w o r d _ f d . i t e r i t e m s ( ) : # C a l c u l a t e a s c o r e f o r t h e p o s i t i v e c l a s s p o s _ s c o r e = B i g r a m A s s o c M e a s u r e s . c h i _ s q ( l a b e l _ w o r d _ f d [ ' p o s ' ] [ w o r d ] , ( f r e q , p o s _ w o r d _ c o u n t ) , t o t a l _ w o r d _ c o u n t ) # C a l c u l a t e a s c o r e f o r t h e n e g a t i v e c l a s s n e g _ s c o r e = B i g r a m A s s o c M e a s u r e s . c h i _ s q ( l a b e l _ w o r d _ f d [ ' n e g ' ] [ w o r d ] , ( f r e q , n e g _ w o r d _ c o u n t ) , t o t a l _ w o r d _ c o u n t ) # T h e s u m o f t h e t w o w i l l g i v e y o u i t ' s t o t a l s c o r e w o r d _ s c o r e s [ w o r d ] = p o s _ s c o r e + n e g _ s c o r e
-
TRAINING Now that we can extract features from text, we
can train a classifier. The simplest and most flexible learning algorithm for text classification is Naive Bayes P ( l a b e l | f e a t u r e s ) = P ( l a b e l ) * P ( f e a t u r e s | l a b e l ) / P ( f e a t u r e s ) Simple to compute = fast Assumes feature indipendence = easy to update Supports multiclass = scalable
-
TRAINING NLTK provides built-in components 1. Train the classifier 2.
Serialize classifier for later use 3. Train once, use as much as you want > > > f r o m n l t k . c l a s s i f y i m p o r t N a i v e B a y e s C l a s s i f i e r > > > n b _ c l a s s i f i e r = N a i v e B a y e s C l a s s i f i e r . t r a i n ( t r a i n _ f e a t s ) . . . w a i t a l o t o f t i m e > > > n b _ c l a s s i f i e r . l a b e l s ( ) [ ' n e g ' , ' p o s ' ] > > > s e r i a l i z e r . d u m p ( n b _ c l a s s i f i e r , f i l e _ h a n d l e )
-
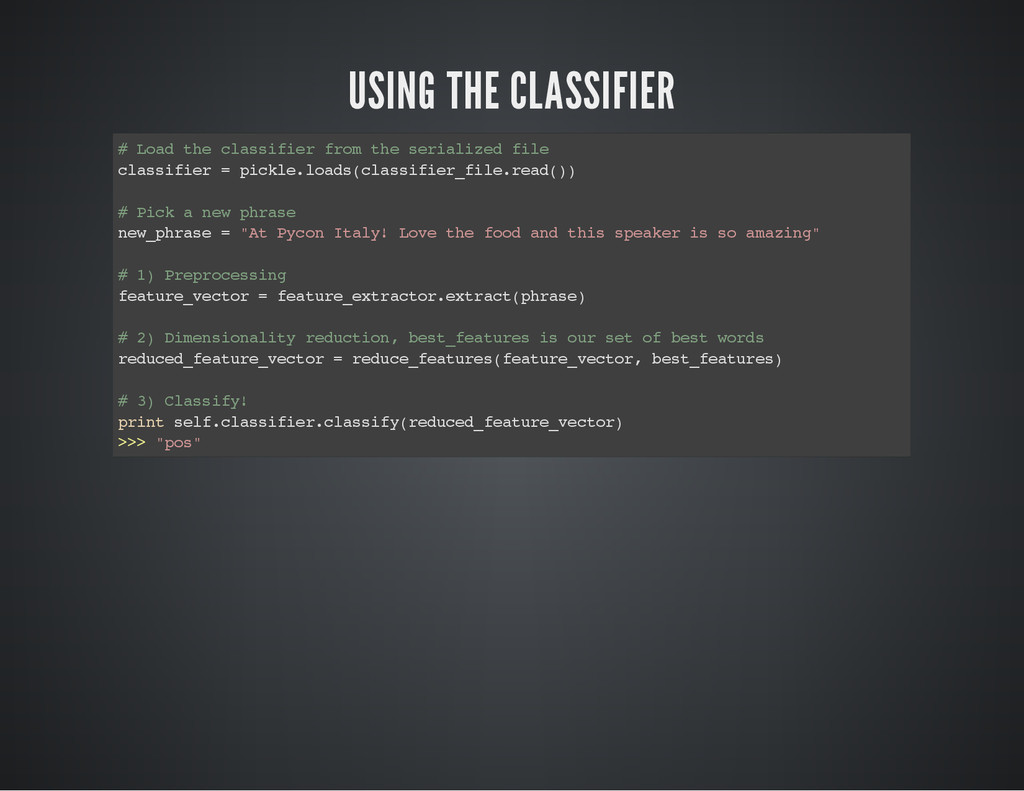
USING THE CLASSIFIER # L o a d t h
e c l a s s i f i e r f r o m t h e s e r i a l i z e d f i l e c l a s s i f i e r = p i c k l e . l o a d s ( c l a s s i f i e r _ f i l e . r e a d ( ) ) # P i c k a n e w p h r a s e n e w _ p h r a s e = " A t P y c o n I t a l y ! L o v e t h e f o o d a n d t h i s s p e a k e r i s s o a m a z i n g " # 1 ) P r e p r o c e s s i n g f e a t u r e _ v e c t o r = f e a t u r e _ e x t r a c t o r . e x t r a c t ( p h r a s e ) # 2 ) D i m e n s i o n a l i t y r e d u c t i o n , b e s t _ f e a t u r e s i s o u r s e t o f b e s t w o r d s r e d u c e d _ f e a t u r e _ v e c t o r = r e d u c e _ f e a t u r e s ( f e a t u r e _ v e c t o r , b e s t _ f e a t u r e s ) # 3 ) C l a s s i f y ! p r i n t s e l f . c l a s s i f i e r . c l a s s i f y ( r e d u c e d _ f e a t u r e _ v e c t o r ) > > > " p o s "
-
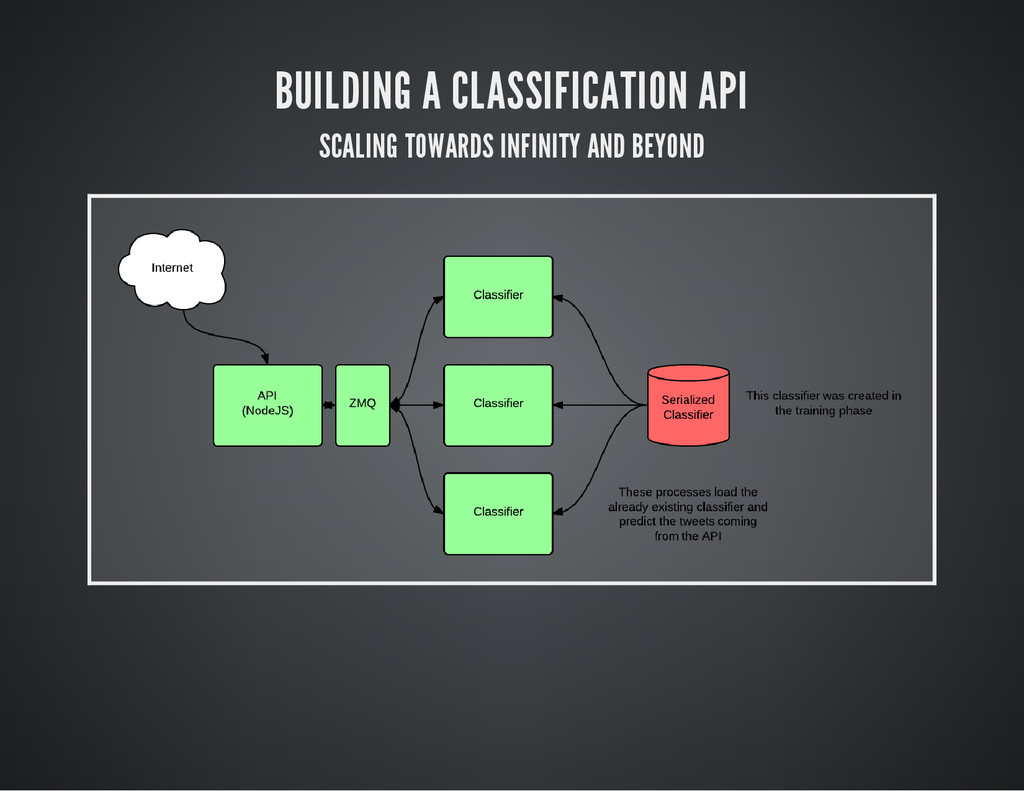
BUILDING A CLASSIFICATION API SCALING TOWARDS INFINITY AND BEYOND
-
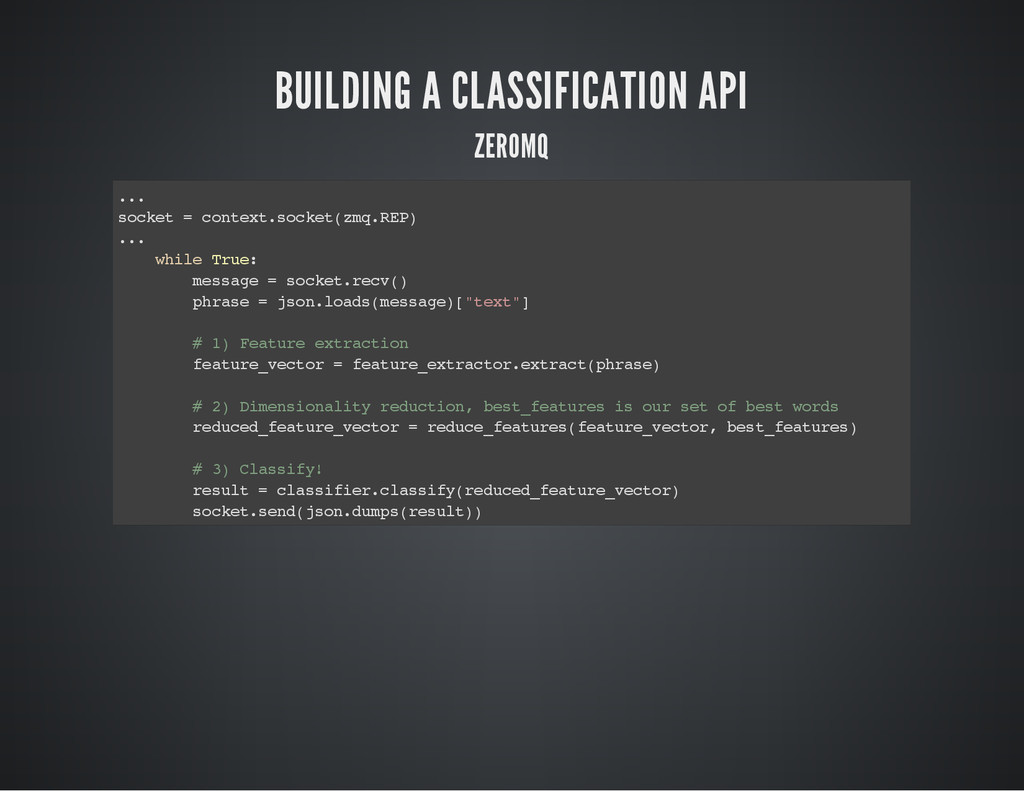
BUILDING A CLASSIFICATION API ZEROMQ . . . s o
c k e t = c o n t e x t . s o c k e t ( z m q . R E P ) . . . w h i l e T r u e : m e s s a g e = s o c k e t . r e c v ( ) p h r a s e = j s o n . l o a d s ( m e s s a g e ) [ " t e x t " ] # 1 ) F e a t u r e e x t r a c t i o n f e a t u r e _ v e c t o r = f e a t u r e _ e x t r a c t o r . e x t r a c t ( p h r a s e ) # 2 ) D i m e n s i o n a l i t y r e d u c t i o n , b e s t _ f e a t u r e s i s o u r s e t o f b e s t w o r d s r e d u c e d _ f e a t u r e _ v e c t o r = r e d u c e _ f e a t u r e s ( f e a t u r e _ v e c t o r , b e s t _ f e a t u r e s ) # 3 ) C l a s s i f y ! r e s u l t = c l a s s i f i e r . c l a s s i f y ( r e d u c e d _ f e a t u r e _ v e c t o r ) s o c k e t . s e n d ( j s o n . d u m p s ( r e s u l t ) )
-
DEMO
-
FIN QUESTIONS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}