Why? 3
{kind=link}
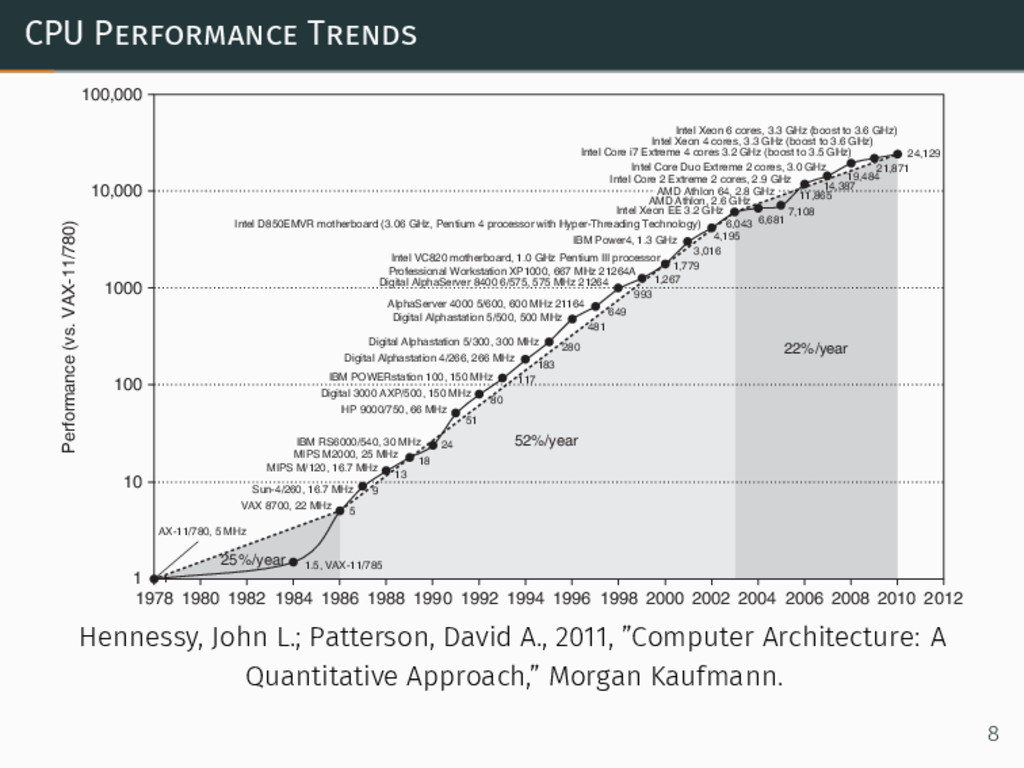
CPU Performance Trends 1 5 9 13 18 24 51
{kind=link}
80 117 183 280 481 649 993 1,267 1,779 3,016 4,195 6,043 6,681 7,108 11,865 14,387 19,484 21,871 24,129 1 10 100 1000 10,000 100,000 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 Performance (vs. VAX-11/780) 25%/year 52%/year 22%/year IBM POWERstation 100, 150 MHz Digital Alphastation 4/266, 266 MHz Digital Alphastation 5/300, 300 MHz Digital Alphastation 5/500, 500 MHz AlphaServer 4000 5/600, 600 MHz 21164 Digital AlphaServer 8400 6/575, 575 MHz 21264 Professional Workstation XP1000, 667 MHz 21264A Intel VC820 motherboard, 1.0 GHz Pentium III processor IBM Power4, 1.3 GHz Intel Xeon EE 3.2 GHz AMD Athlon, 2.6 GHz Intel Core 2 Extreme 2 cores, 2.9 GHz Intel Core Duo Extreme 2 cores, 3.0 GHz Intel Core i7 Extreme 4 cores 3.2 GHz (boost to 3.5 GHz) Intel Xeon 4 cores, 3.3 GHz (boost to 3.6 GHz) Intel Xeon 6 cores, 3.3 GHz (boost to 3.6 GHz) Intel D850EMVR motherboard (3.06 GHz, Pentium 4 processor with Hyper-Threading Technology) 1.5, VAX-11/785 AMD Athlon 64, 2.8 GHz Digital 3000 AXP/500, 150 MHz HP 9000/750, 66 MHz IBM RS6000/540, 30 MHz MIPS M2000, 25 MHz MIPS M/120, 16.7 MHz Sun-4/260, 16.7 MHz VAX 8700, 22 MHz AX-11/780, 5 MHz Hennessy, John L.; Patterson, David A., 2011, ”Computer Architecture: A Quantitative Approach,” Morgan Kaufmann. 8
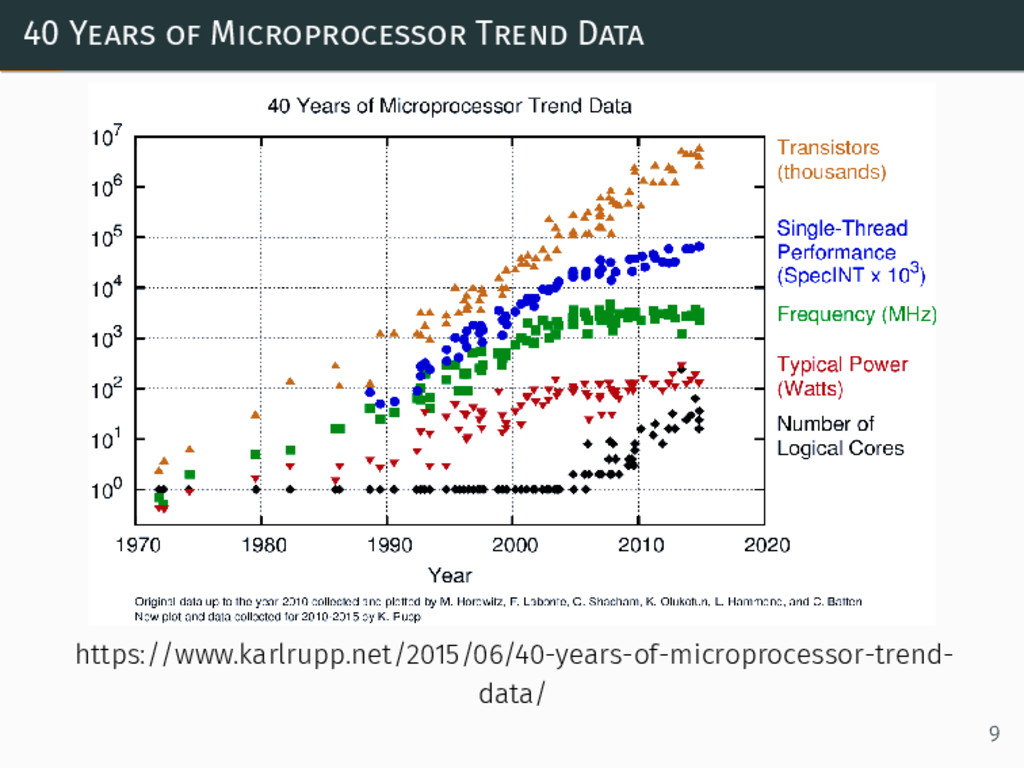
40 Years of Microprocessor Trend Data https://www.karlrupp.net/2015/06/40-years-of-microprocessor-trend- data/ 9
{kind=link}
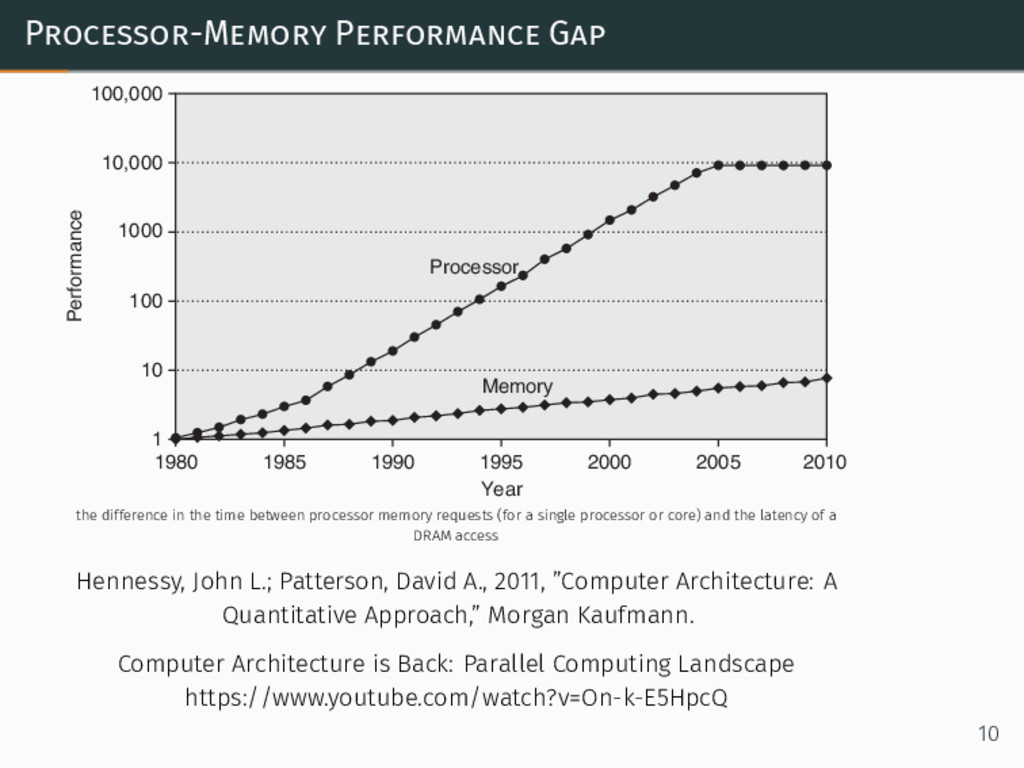
Processor-Memory Performance Gap 1 100 10 1000 Performance 10,000 100,000
{kind=link}
1980 2010 2005 2000 1995 Year Processor Memory 1990 1985 the difference in the time between processor memory requests (for a single processor or core) and the latency of a DRAM access Hennessy, John L.; Patterson, David A., 2011, ”Computer Architecture: A Quantitative Approach,” Morgan Kaufmann. Computer Architecture is Back: Parallel Computing Landscape https://www.youtube.com/watch?v=On-k-E5HpcQ 10
What? 14
{kind=link}
Rcpp Example - Pass & Sum Experiment - C++ Code
{kind=link}
I // [[Rcpp::plugins(cpp11)]] #include <algorithm> // std::accumulate #include <cstddef> // std::size_t #include <iterator> // std::begin, std::end #include <vector> // std::vector //#include <Rcpp.h> // note: not w/ <RcppArmadillo.h> // [[Rcpp::depends(RcppArmadillo)]] #include <RcppArmadillo.h> // [[Rcpp::depends(RcppEigen)]] #include <RcppEigen.h> // [[Rcpp::export]] double sum_Rcpp_NumericVector_for(const Rcpp::NumericVector input) { double sum = 0.0; for (R_xlen_t i = 0; i != input.size(); ++i) sum += input[i]; return sum; } 23
Rcpp Example - Pass & Sum Experiment - C++ Code
{kind=link}
II // [[Rcpp::export]] double sum_Rcpp_NumericVector_sugar(const Rcpp::NumericVector input) { return sum(input); } // [[Rcpp::export]] double sum_std_vector_for(const std::vector<double> & input) { double sum = 0.0; for (std::size_t i = 0; i != input.size(); ++i) sum += input[i]; return sum; } // [[Rcpp::export]] double sum_std_vector_accumulate(const std::vector<double> & input) { return std::accumulate(begin(input), end(input), 0.0); } 24
Rcpp Example - Pass & Sum Experiment - C++ Code
{kind=link}
III // [[Rcpp::export]] double sum_Eigen_Vector(const Eigen::VectorXd & input) { return input.sum(); } // [[Rcpp::export]] double sum_Eigen_Map(const Eigen::Map<Eigen::VectorXd> input) { return input.sum(); } // [[Rcpp::export]] double sum_Eigen_Map_for(const Eigen::Map<Eigen::VectorXd> input) { double sum = 0.0; for (Eigen::DenseIndex i = 0; i != input.size(); ++i) sum += input(i); return sum; } 25
Rcpp Example - Pass & Sum Experiment - C++ Code
{kind=link}
IV // [[Rcpp::export]] double sum_Arma_ColVec(const arma::colvec & input) { return sum(input); } // [[Rcpp::export]] double sum_Arma_RowVec(const arma::rowvec & input) { return sum(input); } Note: types with reference semantics - pass-by-value (const) types with value semantics - pass-by-reference (-to-const) 26
Rcpp Example - Pass & Sum Experiment - R Benchmark
{kind=link}
size = 10000000L v = rep_len(1.0, size) library("rbenchmark") benchmark(sum_Rcpp_NumericVector_for(v), sum_Rcpp_NumericVector_sugar(v), sum_std_vector_for(v), sum_std_vector_accumulate(v), sum_Eigen_Vector(v), sum_Eigen_Map(v), sum_Eigen_Map_for(v), sum_Arma_ColVec(v), sum_Arma_RowVec(v), order = "relative", columns = c("test", "replications", "elapsed", "relative", "user.self", "sys.self")) 27
Rcpp Example - Pass & Sum Experiment - Results test
{kind=link}
replications elapsed relative user.self 6 sum_Eigen_Map(v) 100 0.64 1.000 0.64 2 sum_Rcpp_NumericVector_sugar(v) 100 0.67 1.047 0.67 9 sum_Arma_RowVec(v) 100 0.67 1.047 0.67 8 sum_Arma_ColVec(v) 100 0.68 1.062 0.67 7 sum_Eigen_Map_for(v) 100 1.41 2.203 1.41 4 sum_std_vector_accumulate(v) 100 4.80 7.500 2.55 3 sum_std_vector_for(v) 100 4.82 7.531 2.49 5 sum_Eigen_Vector(v) 100 4.88 7.625 2.92 1 sum_Rcpp_NumericVector_for(v) 100 6.68 10.438 6.67 • sum_Rcpp_NumericVector_sugar faster than sum_Rcpp_NumericVector_for • sum_std_vector_for, sum_std_vector_accumulate, and sum_Eigen_Vector slow • sum_Eigen_Map_for slower than sum_Eigen_Map 28
Rcpp Example - Pass & Sum Experiment - NumericVector sum_Rcpp_NumericVector_sugar
{kind=link}
faster than sum_Rcpp_NumericVector_for Why? // [[Rcpp::export]] double sum_Rcpp_NumericVector_for(const Rcpp::NumericVector input) { double sum = 0.0; for (R_xlen_t i = 0; i != input.size(); ++i) sum += input[i]; return sum; } // https://github.com/RcppCore/Rcpp/ // /blob/master/inst/include/Rcpp/sugar/functions/sum.h R_xlen_t n = object.size(); for (R_xlen_t i = 0; i < n; i++) Alternative sum_Rcpp_NumericVector_for: for (R_xlen_t i = 0, n = input.size(); i != n; ++i) 29
Rcpp Example - Pass & Sum Experiment - New Results
{kind=link}
test replications elapsed relative user.self 6 sum_Eigen_Map(v) 100 0.67 1.000 0.68 1 sum_Rcpp_NumericVector_for(v) 100 0.69 1.030 0.69 9 sum_Arma_RowVec(v) 100 0.69 1.030 0.69 2 sum_Rcpp_NumericVector_sugar(v) 100 0.70 1.045 0.70 8 sum_Arma_ColVec(v) 100 0.70 1.045 0.67 7 sum_Eigen_Map_for(v) 100 1.48 2.209 1.48 3 sum_std_vector_for(v) 100 4.90 7.313 2.89 4 sum_std_vector_accumulate(v) 100 5.01 7.478 2.67 5 sum_Eigen_Vector(v) 100 5.17 7.716 2.84 sum_Rcpp_NumericVector_sugar now on par w/ sum_Rcpp_NumericVector_for Next: Why is std::vector slow - and sum_Eigen_Vector even slower than sum_Eigen_Map_for? Hypothesis: (Implicit) conversions — passing means copying — linear complexity. 30
Rcpp Example - Doubling Ratio Experiment - std::vector Hypothesis: (Implicit)
{kind=link}
conversions — passing means copying — linear complexity. How to check? Recall doubling ratio experiments! C++: #include <vector> // [[Rcpp::export]] double pass_std_vector(const std::vector<double> & v) { return v.back(); } R: pass_vector = pass_std_vector v = seq(from = 0.0, to = 1.0, length.out = 10000000) system.time(pass_vector(v)) v = seq(from = 0.0, to = 1.0, length.out = 20000000) system.time(pass_vector(v)) v = seq(from = 0.0, to = 1.0, length.out = 40000000) system.time(pass_vector(v)) Timing results: 0.04, 0.08, 0.17 31
Rcpp Example - Doubling Ratio Experiment - Rcpp::NumericVector C++: #include
{kind=link}
<Rcpp.h> // [[Rcpp::export]] double pass_Rcpp_vector(const Rcpp::NumericVector v) { return v[v.size() - 1]; } R: pass_vector = pass_Rcpp_vector v = seq(from = 0.0, to = 1.0, length.out = 10000000) system.time(pass_vector(v)) v = seq(from = 0.0, to = 1.0, length.out = 20000000) system.time(pass_vector(v)) v = seq(from = 0.0, to = 1.0, length.out = 40000000) system.time(pass_vector(v)) Timing results: 0, 0, 0 32
Rcpp Example - Timing Experiments - std::vector pass_vector = pass_std_vector
{kind=link}
time_argpass = function(length) { show(length) v = seq(from = 0.0, to = 1.0, length.out = length) r = system.time(pass_vector(v))["elapsed"] show(r) r } lengths = seq(from = 10000000, to = 40000000, length.out = 10) times = sapply(lengths, time_argpass) plot(log(lengths), log(times), type="l") lm(log(times) ~ log(lengths)) Coefficients: (Intercept) log(lengths) -19.347 1.005 33
C++ - Copies vs. Views • implicit conversions - costly
{kind=link}
copies - worth avoiding • analogous case: std::string vs. boost::string_ref • C++17: std::string_view http://www.boost.org/doc/libs/master/libs/utility/doc/html/string_ref.html http://en.cppreference.com/w/cpp/experimental/basic_string_view http://en.cppreference.com/w/cpp/string/basic_string_view 34
Computer Architecture: A Science of Tradeoffs ”My tongue in cheek
{kind=link}
phrase to emphasize the importance of tradeoffs to the discipline of computer architecture. Clearly, computer architecture is more art than science. Science, we like to think, involves a coherent body of knowledge, even though we have yet to figure out all the connections. Art, on the other hand, is the result of individual expressions of the various artists. Since each computer architecture is the result of the individual(s) who specified it, there is no such completely coherent structure. So, I opined if computer architecture is a science at all, it is a science of tradeoffs. In class, we keep coming up with design choices that involve tradeoffs. In my view, ”tradeoffs” is at the heart of computer architecture.” — Yale N. Patt 35
Trade-offs - Multiple levels - Numerical Optimization Gradient computation -
{kind=link}
accuracy vs. function evaluations f : Rd → RN • Finite differencing: • forward-difference: O( √ ϵM) error, d O(Cost(f)) evaluations • central-difference: O(ϵ2/3 M ) error, 2d O(Cost(f)) evaluations w/ the machine epsilon ϵM := inf{ϵ > 0 : 1.0 + ϵ ̸= 1.0} • Algorithmic differentiation (AD): precision - as in hand-coded analytical gradient • rough forward-mode cost d O(Cost(f)) • rough reverse-mode cost N O(Cost(f)) 38
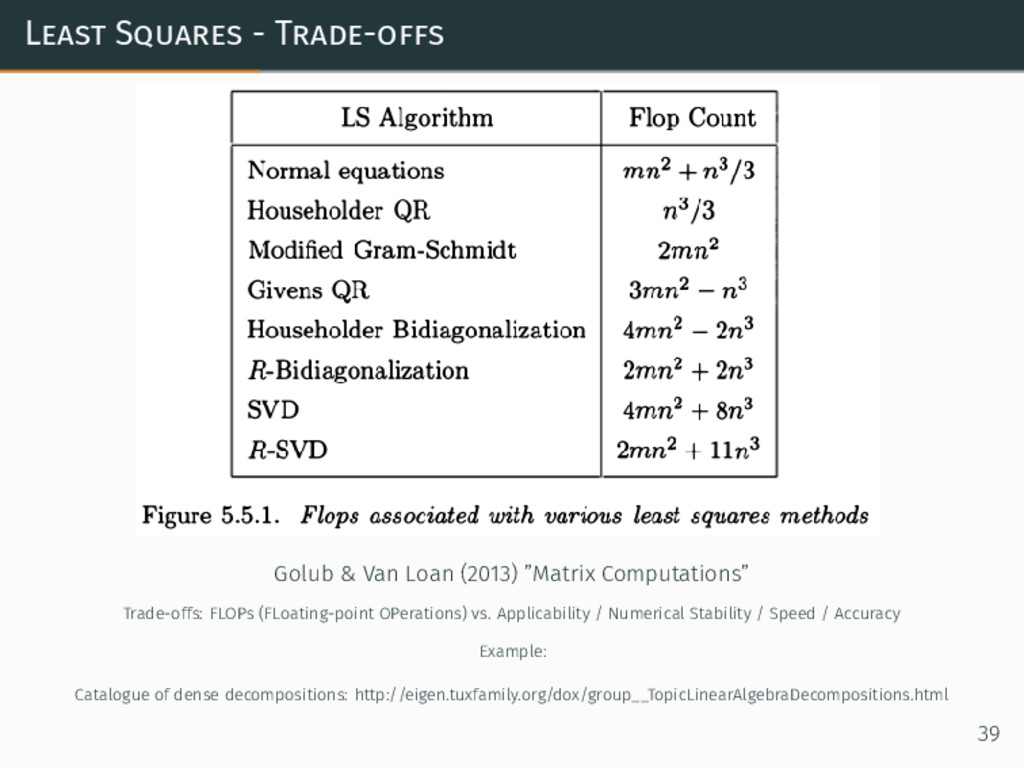
Least Squares - Trade-offs Golub & Van Loan (2013) ”Matrix
{kind=link}
Computations” Trade-offs: FLOPs (FLoating-point OPerations) vs. Applicability / Numerical Stability / Speed / Accuracy Example: Catalogue of dense decompositions: http://eigen.tuxfamily.org/dox/group__TopicLinearAlgebraDecompositions.html 39
How? 42
{kind=link}
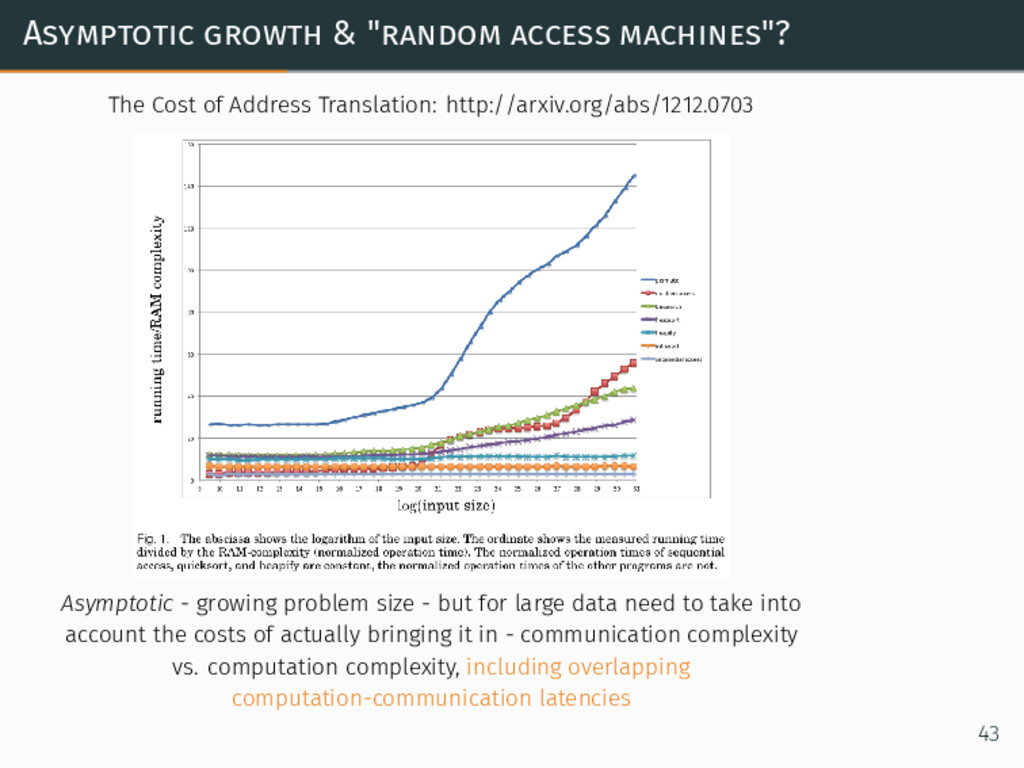
Asymptotic growth & "random access machines"? The Cost of Address
{kind=link}
Translation: http://arxiv.org/abs/1212.0703 Asymptotic - growing problem size - but for large data need to take into account the costs of actually bringing it in - communication complexity vs. computation complexity, including overlapping computation-communication latencies 43
Complexity - constants, microarchitecture? ”Array Layouts for Comparison-Based Searching” Paul-Virak
{kind=link}
Khuong, Pat Morin http://cglab.ca/~morin/misc/arraylayout-v2/ • ”With this understanding, we are able to choose layouts and design search algorithms that perform searches in 1/2 to 2/3 (depending on the array length) the time of the C++ std::lower_bound() implementation of binary search • (which itself performs searches in 1/3 the time of searching in the std::set implemementation of red-black trees). 44
Complexity - constants, microarchitecture? ”Array Layouts for Comparison-Based Searching” Paul-Virak
{kind=link}
Khuong, Pat Morin http://cglab.ca/~morin/misc/arraylayout-v2/ • ”With this understanding, we are able to choose layouts and design search algorithms that perform searches in 1/2 to 2/3 (depending on the array length) the time of the C++ std::lower_bound() implementation of binary search • (which itself performs searches in 1/3 the time of searching in the std::set implemementation of red-black trees). • It was only through careful and controlled experimentation with different implementations of each of the search algorithms that we are able to understand how the interactions between processor features such as pipelining, prefetching, speculative execution, and conditional moves affect the running times of the search algorithms.” 44
Reasoning about Performance: The Scientific Method Requires - enabled by
{kind=link}
- the knowledge of microachitectural details. Mark D. Hill, Norman P. Jouppi, and Gurindar S. Sohi, Chapter 2 ”Methods” from ”Readings in Computer Architecture,” Morgan Kaufmann, 2000. Prefetching benefits evaluation: Disable/enable prefetchers using likwid-features: https://github.com/RRZE-HPC/likwid/wiki/likwid-features Example: https://gist.github.com/MattPD/06e293fb935eaf67ee9c301e70db6975 45
Instruction Level Parallelism & Loop Unrolling - Code II typedef
{kind=link}
double T; T sum_1(const std::vector<T> & input) { T sum = 0.0; for (std::size_t i = 0, n = input.size(); i != n; ++i) sum += input[i]; return sum; } T sum_2(const std::vector<T> & input) { T sum1 = 0.0, sum2 = 0.0; for (std::size_t i = 0, n = input.size(); i != n; i += 2) { sum1 += input[i]; sum2 += input[i + 1]; } return sum1 + sum2; } 49
Instruction Level Parallelism & Loop Unrolling - Code III int
{kind=link}
main(int argc, char * argv[]) { std::size_t n = (argc >= 2) ? std::atoll(argv[1]) : 10000000; std::size_t f = (argc >= 3) ? std::atoll(argv[2]) : 1; std::cout << "n = " << n << '\n'; // iterations count std::cout << "f = " << f << '\n'; // unroll factor std::vector<T> a(n, T(1)); boost::timer::auto_cpu_timer timer; T sum = (f == 1) ? sum_1(a) : (f == 2) ? sum_2(a) : 0; std::cout << sum << '\n'; } 50
Instruction Level Parallelism & Loop Unrolling - Results make vector_sums
{kind=link}
CXXFLAGS="-std=c++14 -O2 -march=native" LDLIBS=-lboost_timer $ ./vector_sums 1000000000 2 n = 1000000000 f = 2 1e+09 0.466293s wall, 0.460000s user + 0.000000s system = 0.460000s CPU (98.7%) $ ./vector_sums 1000000000 1 n = 1000000000 f = 1 1e+09 0.841269s wall, 0.840000s user + 0.010000s system = 0.850000s CPU (101.0%) 51
perf • https://perf.wiki.kernel.org/ • http://www.brendangregg.com/perf.html 52
{kind=link}
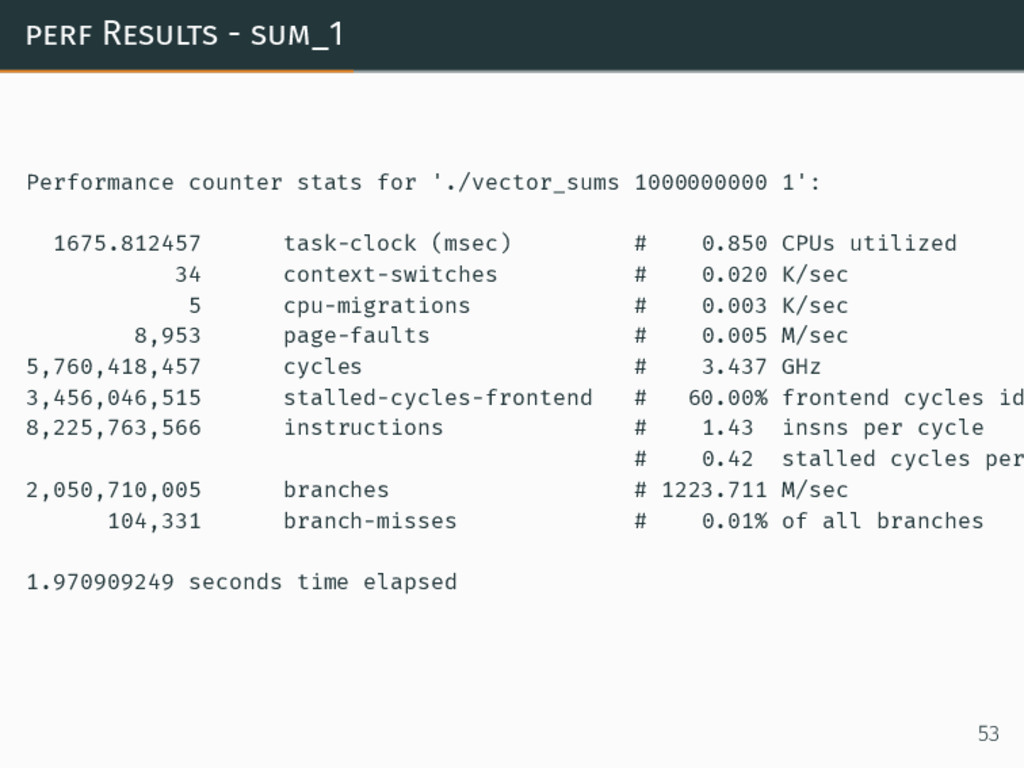
perf Results - sum_1 Performance counter stats for './vector_sums 1000000000
{kind=link}
1': 1675.812457 task-clock (msec) # 0.850 CPUs utilized 34 context-switches # 0.020 K/sec 5 cpu-migrations # 0.003 K/sec 8,953 page-faults # 0.005 M/sec 5,760,418,457 cycles # 3.437 GHz 3,456,046,515 stalled-cycles-frontend # 60.00% frontend cycles id 8,225,763,566 instructions # 1.43 insns per cycle # 0.42 stalled cycles per 2,050,710,005 branches # 1223.711 M/sec 104,331 branch-misses # 0.01% of all branches 1.970909249 seconds time elapsed 53
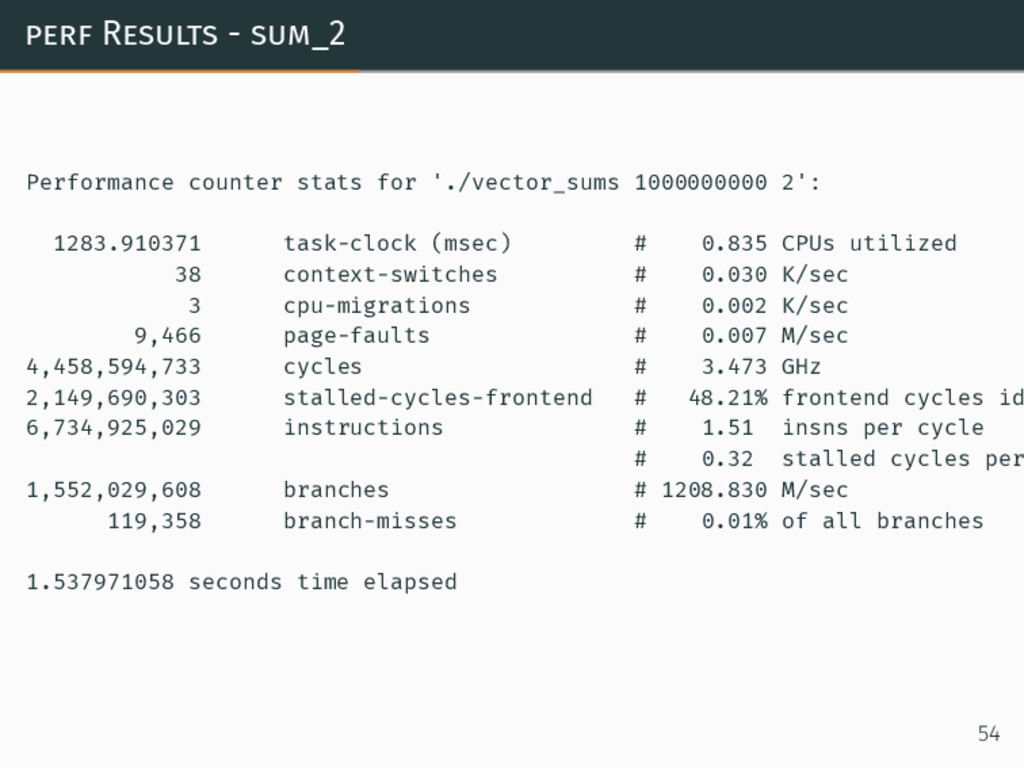
perf Results - sum_2 Performance counter stats for './vector_sums 1000000000
{kind=link}
2': 1283.910371 task-clock (msec) # 0.835 CPUs utilized 38 context-switches # 0.030 K/sec 3 cpu-migrations # 0.002 K/sec 9,466 page-faults # 0.007 M/sec 4,458,594,733 cycles # 3.473 GHz 2,149,690,303 stalled-cycles-frontend # 48.21% frontend cycles id 6,734,925,029 instructions # 1.51 insns per cycle # 0.32 stalled cycles per 1,552,029,608 branches # 1208.830 M/sec 119,358 branch-misses # 0.01% of all branches 1.537971058 seconds time elapsed 54
GCC Explorer: sum_1 http://gcc.godbolt.org/ 55
{kind=link}
GCC Explorer: sum_2 http://gcc.godbolt.org/ 56
{kind=link}
Intel Architecture Code Analyzer (IACA) #include <iacaMarks.h> T sum_2(const std::vector<T>
{kind=link}
& input) { T sum1 = 0.0, sum2 = 0.0; for (std::size_t i = 0, n = input.size(); i != n; i += 2) { IACA_START sum1 += input[i]; sum2 += input[i + 1]; } IACA_END return sum1 + sum2; } $ g++ -std=c++14 -O2 -march=native vector_sums_2i.cpp -o vector_sums_2i $ iaca -64 -arch IVB -graph ./vector_sums_2i • https://software.intel.com/en-us/articles/intel-architecture-code-analyzer • https://stackoverflow.com/questions/26021337/what-is-iaca-and-how-do-i- use-it • http://kylehegeman.com/blog/2013/12/28/introduction-to-iaca/ 57
IACA Results - sum_1 $ iaca -64 -arch IVB -graph
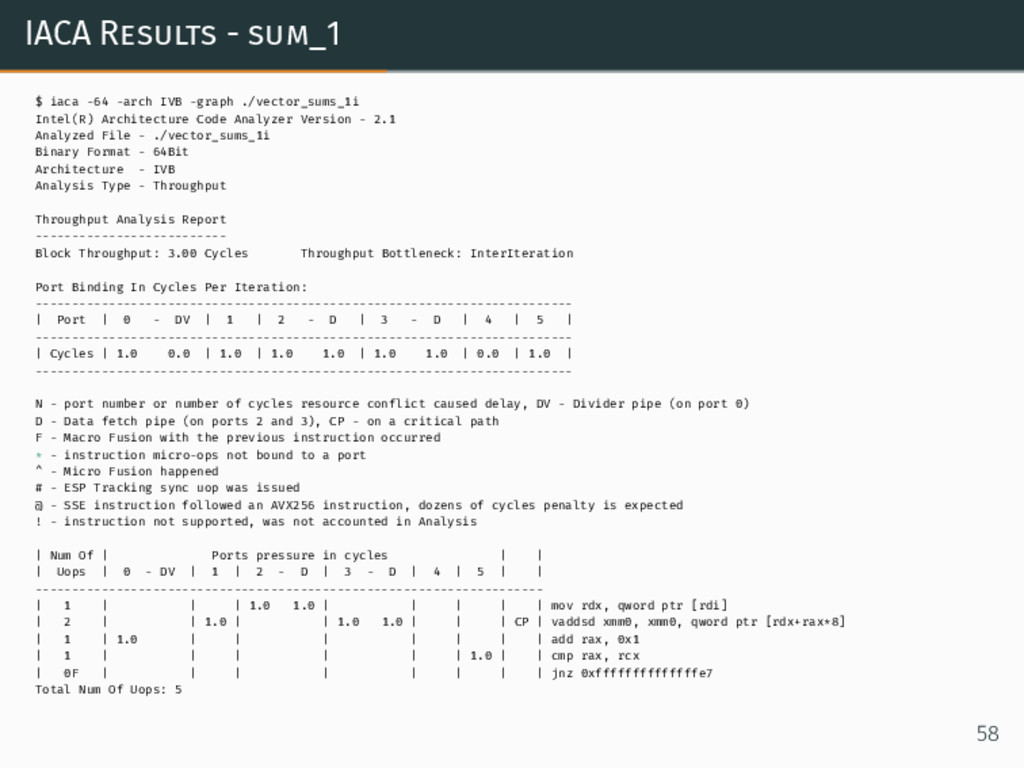{kind=link}
./vector_sums_1i Intel(R) Architecture Code Analyzer Version - 2.1 Analyzed File - ./vector_sums_1i Binary Format - 64Bit Architecture - IVB Analysis Type - Throughput Throughput Analysis Report -------------------------- Block Throughput: 3.00 Cycles Throughput Bottleneck: InterIteration Port Binding In Cycles Per Iteration: ------------------------------------------------------------------------- | Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | ------------------------------------------------------------------------- | Cycles | 1.0 0.0 | 1.0 | 1.0 1.0 | 1.0 1.0 | 0.0 | 1.0 | ------------------------------------------------------------------------- N - port number or number of cycles resource conflict caused delay, DV - Divider pipe (on port 0) D - Data fetch pipe (on ports 2 and 3), CP - on a critical path F - Macro Fusion with the previous instruction occurred * - instruction micro-ops not bound to a port ^ - Micro Fusion happened # - ESP Tracking sync uop was issued @ - SSE instruction followed an AVX256 instruction, dozens of cycles penalty is expected ! - instruction not supported, was not accounted in Analysis | Num Of | Ports pressure in cycles | | | Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | | --------------------------------------------------------------------- | 1 | | | 1.0 1.0 | | | | | mov rdx, qword ptr [rdi] | 2 | | 1.0 | | 1.0 1.0 | | | CP | vaddsd xmm0, xmm0, qword ptr [rdx+rax*8] | 1 | 1.0 | | | | | | | add rax, 0x1 | 1 | | | | | | 1.0 | | cmp rax, rcx | 0F | | | | | | | | jnz 0xffffffffffffffe7 Total Num Of Uops: 5 58
IACA Results - sum_2 $ iaca -64 -arch IVB -graph
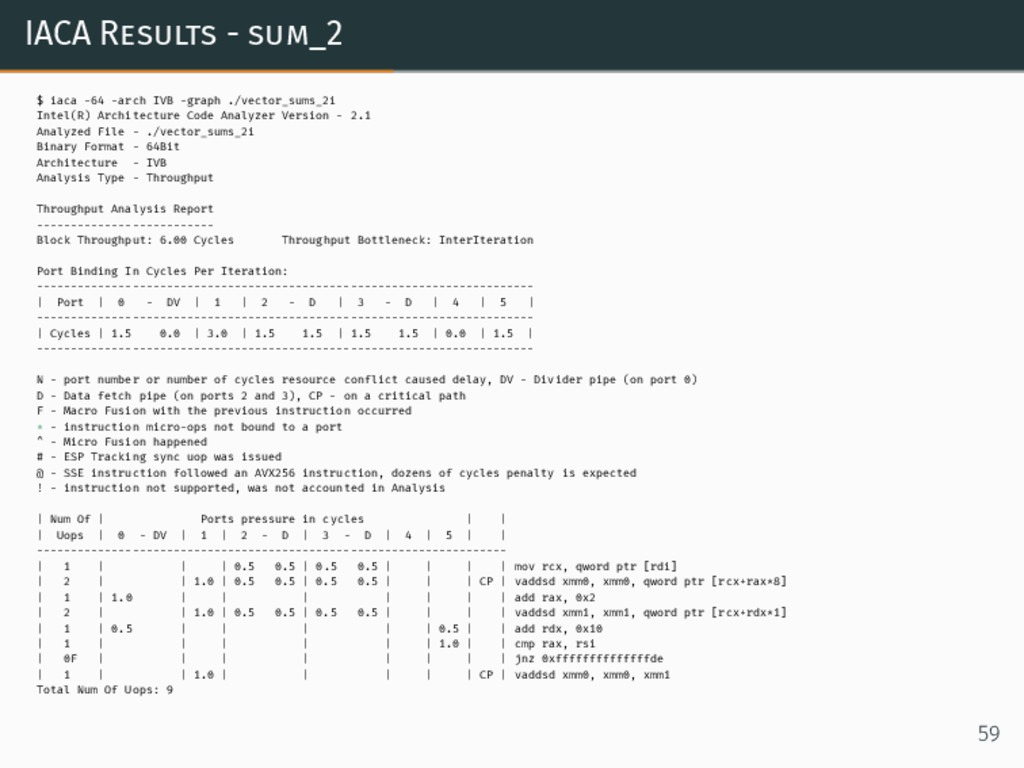{kind=link}
./vector_sums_2i Intel(R) Architecture Code Analyzer Version - 2.1 Analyzed File - ./vector_sums_2i Binary Format - 64Bit Architecture - IVB Analysis Type - Throughput Throughput Analysis Report -------------------------- Block Throughput: 6.00 Cycles Throughput Bottleneck: InterIteration Port Binding In Cycles Per Iteration: ------------------------------------------------------------------------- | Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | ------------------------------------------------------------------------- | Cycles | 1.5 0.0 | 3.0 | 1.5 1.5 | 1.5 1.5 | 0.0 | 1.5 | ------------------------------------------------------------------------- N - port number or number of cycles resource conflict caused delay, DV - Divider pipe (on port 0) D - Data fetch pipe (on ports 2 and 3), CP - on a critical path F - Macro Fusion with the previous instruction occurred * - instruction micro-ops not bound to a port ^ - Micro Fusion happened # - ESP Tracking sync uop was issued @ - SSE instruction followed an AVX256 instruction, dozens of cycles penalty is expected ! - instruction not supported, was not accounted in Analysis | Num Of | Ports pressure in cycles | | | Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | | --------------------------------------------------------------------- | 1 | | | 0.5 0.5 | 0.5 0.5 | | | | mov rcx, qword ptr [rdi] | 2 | | 1.0 | 0.5 0.5 | 0.5 0.5 | | | CP | vaddsd xmm0, xmm0, qword ptr [rcx+rax*8] | 1 | 1.0 | | | | | | | add rax, 0x2 | 2 | | 1.0 | 0.5 0.5 | 0.5 0.5 | | | | vaddsd xmm1, xmm1, qword ptr [rcx+rdx*1] | 1 | 0.5 | | | | | 0.5 | | add rdx, 0x10 | 1 | | | | | | 1.0 | | cmp rax, rsi | 0F | | | | | | | | jnz 0xffffffffffffffde | 1 | | 1.0 | | | | | CP | vaddsd xmm0, xmm0, xmm1 Total Num Of Uops: 9 59
IACA Data Dependency Graph - sum_1 60
{kind=link}
IACA Data Dependency Graph - sum_2 61
{kind=link}
Wasted Slots: Causes D. M. Tullsen, S. J. Eggers and
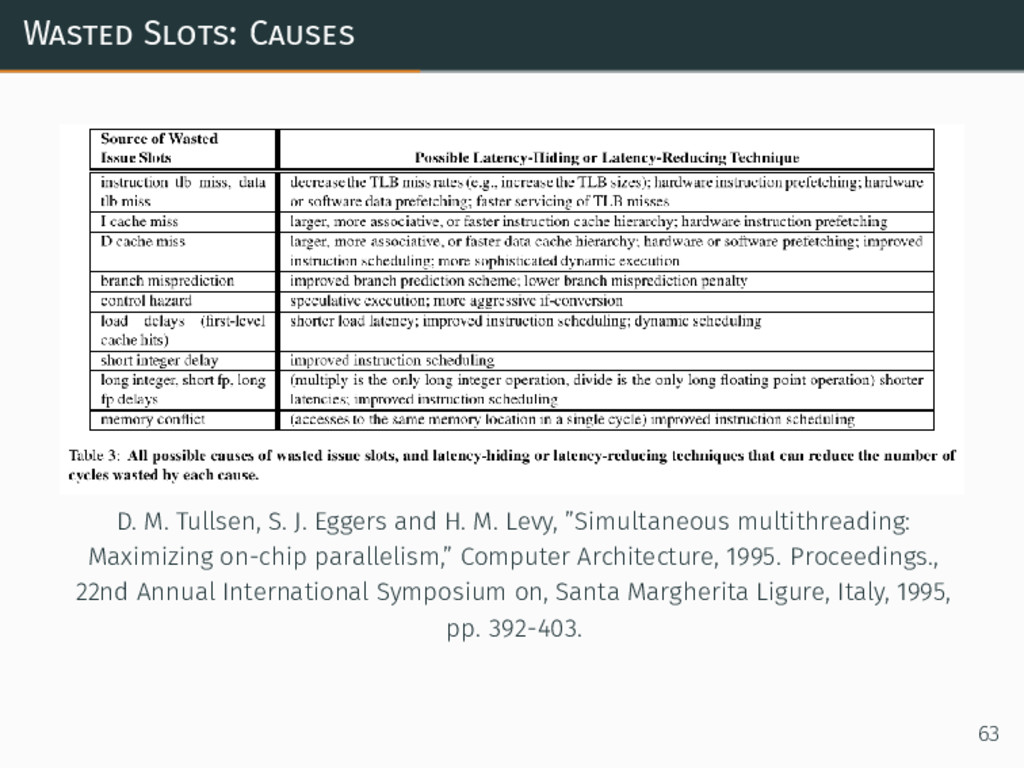{kind=link}
H. M. Levy, ”Simultaneous multithreading: Maximizing on-chip parallelism,” Computer Architecture, 1995. Proceedings., 22nd Annual International Symposium on, Santa Margherita Ligure, Italy, 1995, pp. 392-403. 63
likwid • https://github.com/RRZE-HPC/likwid • https://github.com/RRZE-HPC/likwid/wiki • https://github.com/RRZE-HPC/likwid/wiki/likwid-perfctr 64
{kind=link}
likwid Results - sum_1: 489 Scalar MUOPS/s $ likwid-perfctr -C
{kind=link}
S0:0 -g FLOPS_DP -f ./vector_sums 1000000000 1 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 1000000000 f = 1 1e+09 1.090122s wall, 0.880000s user + 0.000000s system = 0.880000s CPU (80.7%) -------------------------------------------------------------------------------- Group 1: FLOPS_DP +--------------------------------------+---------+------------+ | Event | Counter | Core 0 | +--------------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 8002493499 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 4285189526 | | CPU_CLK_UNHALTED_REF | FIXC2 | 3258346806 | | FP_COMP_OPS_EXE_SSE_FP_PACKED_DOUBLE | PMC0 | 0 | | FP_COMP_OPS_EXE_SSE_FP_SCALAR_DOUBLE | PMC1 | 1000155741 | | SIMD_FP_256_PACKED_DOUBLE | PMC2 | 0 | +--------------------------------------+---------+------------+ +----------------------+-----------+ | Metric | Core 0 | +----------------------+-----------+ | Runtime (RDTSC) [s] | 2.0456 | | Runtime unhalted [s] | 1.6536 | | Clock [MHz] | 3408.2011 | | CPI | 0.5355 | | MFLOP/s | 488.9303 | | AVX MFLOP/s | 0 | | Packed MUOPS/s | 0 | | Scalar MUOPS/s | 488.9303 | +----------------------+-----------+ 65
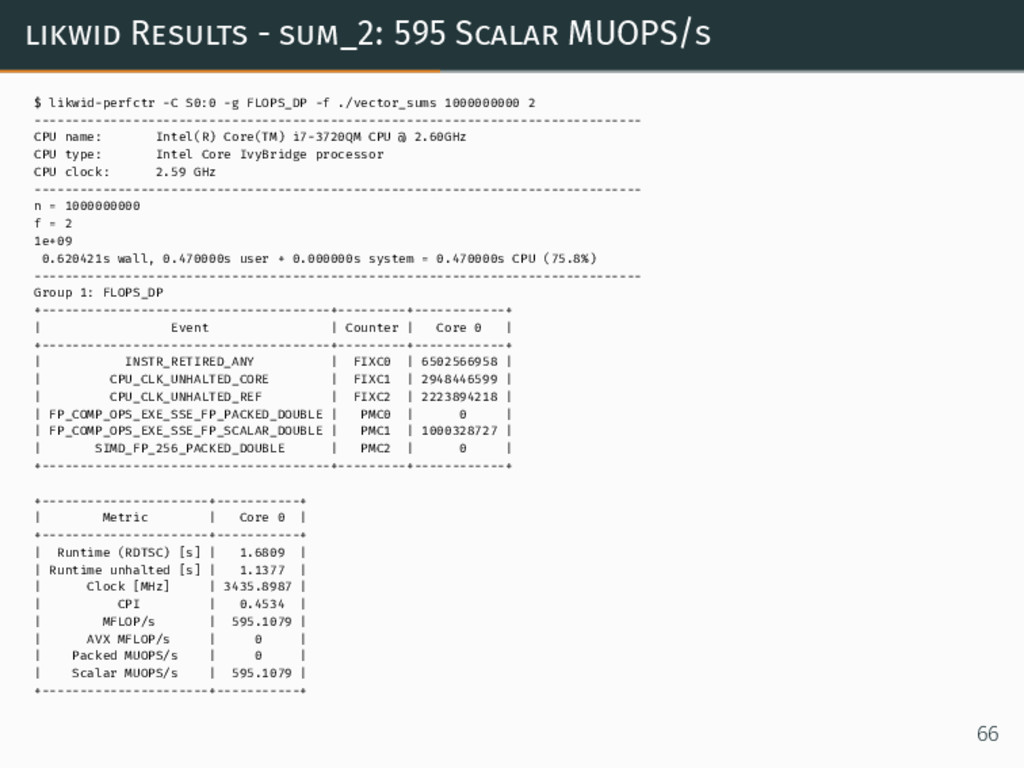
likwid Results - sum_2: 595 Scalar MUOPS/s $ likwid-perfctr -C
{kind=link}
S0:0 -g FLOPS_DP -f ./vector_sums 1000000000 2 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 1000000000 f = 2 1e+09 0.620421s wall, 0.470000s user + 0.000000s system = 0.470000s CPU (75.8%) -------------------------------------------------------------------------------- Group 1: FLOPS_DP +--------------------------------------+---------+------------+ | Event | Counter | Core 0 | +--------------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 6502566958 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 2948446599 | | CPU_CLK_UNHALTED_REF | FIXC2 | 2223894218 | | FP_COMP_OPS_EXE_SSE_FP_PACKED_DOUBLE | PMC0 | 0 | | FP_COMP_OPS_EXE_SSE_FP_SCALAR_DOUBLE | PMC1 | 1000328727 | | SIMD_FP_256_PACKED_DOUBLE | PMC2 | 0 | +--------------------------------------+---------+------------+ +----------------------+-----------+ | Metric | Core 0 | +----------------------+-----------+ | Runtime (RDTSC) [s] | 1.6809 | | Runtime unhalted [s] | 1.1377 | | Clock [MHz] | 3435.8987 | | CPI | 0.4534 | | MFLOP/s | 595.1079 | | AVX MFLOP/s | 0 | | Packed MUOPS/s | 0 | | Scalar MUOPS/s | 595.1079 | +----------------------+-----------+ 66
likwid Results: sum_vectorized: 676 AVX MFLOP/s g++ -std=c++14 -O2 -ftree-vectorize
{kind=link}
-ffast-math -march=native -lboost_timer vector_sums.cpp -o vector_sums_vf $ likwid-perfctr -C S0:0 -g FLOPS_DP -f ./vector_sums_vf 1000000000 1 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 1000000000 f = 1 1e+09 0.561288s wall, 0.390000s user + 0.000000s system = 0.390000s CPU (69.5%) -------------------------------------------------------------------------------- Group 1: FLOPS_DP +--------------------------------------+---------+------------+ | Event | Counter | Core 0 | +--------------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 3002491149 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 2709364345 | | CPU_CLK_UNHALTED_REF | FIXC2 | 2043804906 | | FP_COMP_OPS_EXE_SSE_FP_PACKED_DOUBLE | PMC0 | 0 | | FP_COMP_OPS_EXE_SSE_FP_SCALAR_DOUBLE | PMC1 | 91 | | SIMD_FP_256_PACKED_DOUBLE | PMC2 | 260258099 | +--------------------------------------+---------+------------+ +----------------------+-----------+ | Metric | Core 0 | +----------------------+-----------+ | Runtime (RDTSC) [s] | 1.5390 | | Runtime unhalted [s] | 1.0454 | | Clock [MHz] | 3435.5297 | | CPI | 0.9024 | | MFLOP/s | 676.4420 | | AVX MFLOP/s | 676.4420 | | Packed MUOPS/s | 169.1105 | | Scalar MUOPS/s | 0.0001 | +----------------------+-----------+ 67
Performance: separable components of a CPI CPI = (Infinite-cache CPI)
{kind=link}
+ finite-cache effect (FCE) Infinite-cache CPI = execute busy (EBusy) + execute idle (EIdle) FCE = (cycles per miss) × (misses per instruction) = (miss penalty) × (miss rate) P. G. Emma. Understanding some simple processor-performance limits. IBM Journal of Research and Development, 41(3):215–232, May 1997. 69
Branch (Mis)Prediction Example II double sum2(const std::vector<double> & x, const
{kind=link}
std::vector<bool> & which) { double sum = 0.0; for (std::size_t i = 0, n = which.size(); i < n; ++i) { sum += (which[i]) ? std::sin(x[i]) : std::cos(x[i]); } return sum; } std::vector<bool> inclusion_random(std::size_t n) { std::vector<bool> which; which.reserve(n); std::random_device rd; static std::mt19937 g(rd()); std::uniform_int_distribution<int> u(1, 4); for (std::size_t i = 0; i < n; ++i) 73
Branch (Mis)Prediction Example III which.push_back(u(g) >= 3); return which; }
{kind=link}
int main(int argc, char * argv[]) { const std::size_t n = (argc > 1) ? std::atoll(argv[1]) : 1000; std::cout << "n = " << n << '\n'; // branch takenness / predictability type // 0: never; 1: always; 2: random std::size_t type = (argc > 2) ? std::atoll(argv[2]) : 0; std::cout << "type = " << type << '\n'; std::vector<bool> which; if (type == 0) which.resize(n, false); else if (type == 1) which.resize(n, true); else if (type == 2) which = inclusion_random(n); 74
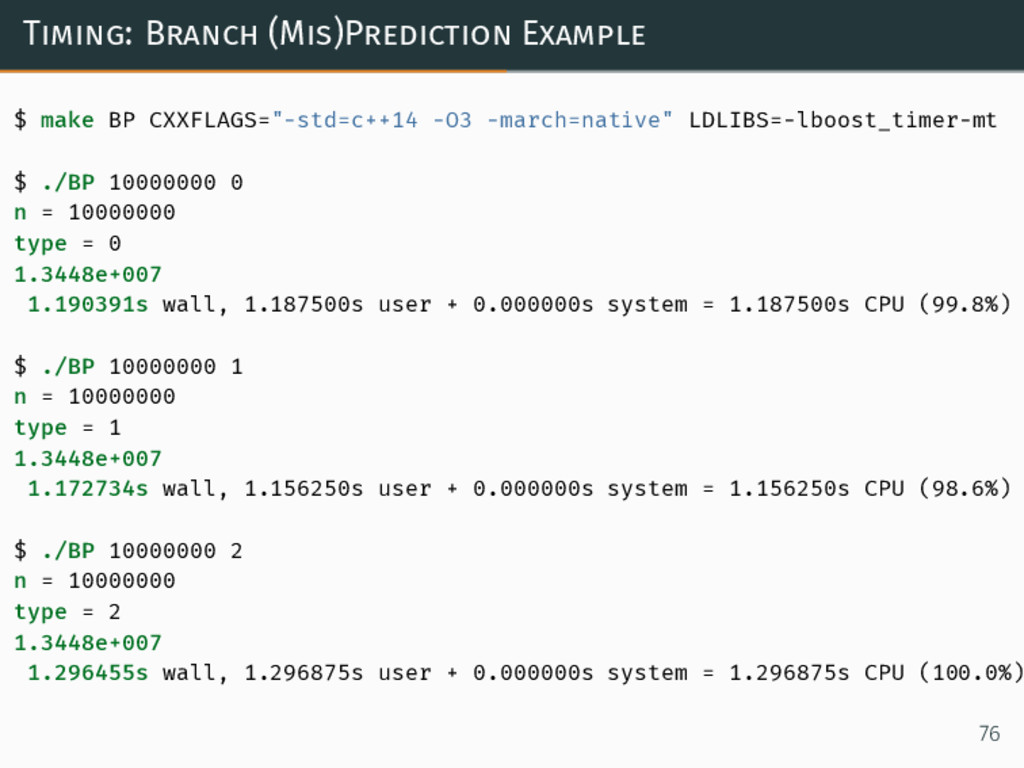
Timing: Branch (Mis)Prediction Example $ make BP CXXFLAGS="-std=c++14 -O3 -march=native"
{kind=link}
LDLIBS=-lboost_timer-mt $ ./BP 10000000 0 n = 10000000 type = 0 1.3448e+007 1.190391s wall, 1.187500s user + 0.000000s system = 1.187500s CPU (99.8%) $ ./BP 10000000 1 n = 10000000 type = 1 1.3448e+007 1.172734s wall, 1.156250s user + 0.000000s system = 1.156250s CPU (98.6%) $ ./BP 10000000 2 n = 10000000 type = 2 1.3448e+007 1.296455s wall, 1.296875s user + 0.000000s system = 1.296875s CPU (100.0%) 76
Likwid: Branch (Mis)Prediction Example $ likwid-perfctr -C S0:1 -g BRANCH
{kind=link}
-f ./BP 10000000 0 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 10000000 type = 0 1.3448e+07 0.445464s wall, 0.440000s user + 0.000000s system = 0.440000s CPU (98.8%) -------------------------------------------------------------------------------- Group 1: BRANCH +------------------------------+---------+------------+ | Event | Counter | Core 1 | +------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 2495177597 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 1167613066 | | CPU_CLK_UNHALTED_REF | FIXC2 | 1167632206 | | BR_INST_RETIRED_ALL_BRANCHES | PMC0 | 372952380 | | BR_MISP_RETIRED_ALL_BRANCHES | PMC1 | 14796 | +------------------------------+---------+------------+ +----------------------------+--------------+ | Metric | Core 1 | +----------------------------+--------------+ | Runtime (RDTSC) [s] | 0.4586 | | Runtime unhalted [s] | 0.4505 | | Clock [MHz] | 2591.5373 | | CPI | 0.4679 | | Branch rate | 0.1495 | | Branch misprediction rate | 5.929838e-06 | | Branch misprediction ratio | 3.967263e-05 | | Instructions per branch | 6.6903 | +----------------------------+--------------+ 77
Likwid: Branch (Mis)Prediction Example $ likwid-perfctr -C S0:1 -g BRANCH
{kind=link}
-f ./BP 10000000 1 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 10000000 type = 1 1.3448e+07 0.445354s wall, 0.440000s user + 0.000000s system = 0.440000s CPU (98.8%) -------------------------------------------------------------------------------- Group 1: BRANCH +------------------------------+---------+------------+ | Event | Counter | Core 1 | +------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 2495177490 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 1167125701 | | CPU_CLK_UNHALTED_REF | FIXC2 | 1167146162 | | BR_INST_RETIRED_ALL_BRANCHES | PMC0 | 372952366 | | BR_MISP_RETIRED_ALL_BRANCHES | PMC1 | 14720 | +------------------------------+---------+------------+ +----------------------------+--------------+ | Metric | Core 1 | +----------------------------+--------------+ | Runtime (RDTSC) [s] | 0.4584 | | Runtime unhalted [s] | 0.4504 | | Clock [MHz] | 2591.5345 | | CPI | 0.4678 | | Branch rate | 0.1495 | | Branch misprediction rate | 5.899380e-06 | | Branch misprediction ratio | 3.946885e-05 | | Instructions per branch | 6.6903 | +----------------------------+--------------+ 78
Likwid: Branch (Mis)Prediction Example $ likwid-perfctr -C S0:1 -g BRANCH
{kind=link}
-f ./BP 10000000 2 -------------------------------------------------------------------------------- CPU name: Intel(R) Core(TM) i7-3720QM CPU @ 2.60GHz CPU type: Intel Core IvyBridge processor CPU clock: 2.59 GHz -------------------------------------------------------------------------------- n = 10000000 type = 2 1.3448e+07 0.509917s wall, 0.510000s user + 0.000000s system = 0.510000s CPU (100.0%) -------------------------------------------------------------------------------- Group 1: BRANCH +------------------------------+---------+------------+ | Event | Counter | Core 1 | +------------------------------+---------+------------+ | INSTR_RETIRED_ANY | FIXC0 | 3191479747 | | CPU_CLK_UNHALTED_CORE | FIXC1 | 2264945099 | | CPU_CLK_UNHALTED_REF | FIXC2 | 2264967068 | | BR_INST_RETIRED_ALL_BRANCHES | PMC0 | 468135649 | | BR_MISP_RETIRED_ALL_BRANCHES | PMC1 | 15326586 | +------------------------------+---------+------------+ +----------------------------+-----------+ | Metric | Core 1 | +----------------------------+-----------+ | Runtime (RDTSC) [s] | 0.8822 | | Runtime unhalted [s] | 0.8740 | | Clock [MHz] | 2591.5589 | | CPI | 0.7097 | | Branch rate | 0.1467 | | Branch misprediction rate | 0.0048 | | Branch misprediction ratio | 0.0327 | | Instructions per branch | 6.8174 | +----------------------------+-----------+ 79
Perf: Branch (Mis)Prediction Example $ perf stat -e branches,branch-misses -r
{kind=link}
10 ./BP 10000000 0 Performance counter stats for './BP 10000000 0' (10 runs): 374,121,213 branches ( +- 0.02% ) 23,260 branch-misses # 0.01% of all branches ( +- 0.35% ) 0.460392835 seconds time elapsed ( +- 0.50% ) $ perf stat -e branches,branch-misses -r 10 ./BP 10000000 1 Performance counter stats for './BP 10000000 1' (10 runs): 374,040,282 branches ( +- 0.01% ) 23,124 branch-misses # 0.01% of all branches ( +- 0.45% ) 0.457583418 seconds time elapsed ( +- 0.04% ) $ perf stat -e branches,branch-misses -r 10 ./BP 10000000 2 Performance counter stats for './BP 10000000 2' (10 runs): 469,331,762 branches ( +- 0.01% ) 15,326,501 branch-misses # 3.27% of all branches ( +- 0.01% ) 0.884858777 seconds time elapsed ( +- 0.30% ) 80
Sniper The Sniper Multi-Core Simulator http://snipersim.org/ 81
{kind=link}
Sniper: Branch (Mis)Prediction Example CPI stack: never taken 82
{kind=link}
Sniper: Branch (Mis)Prediction Example CPI stack: always taken 83
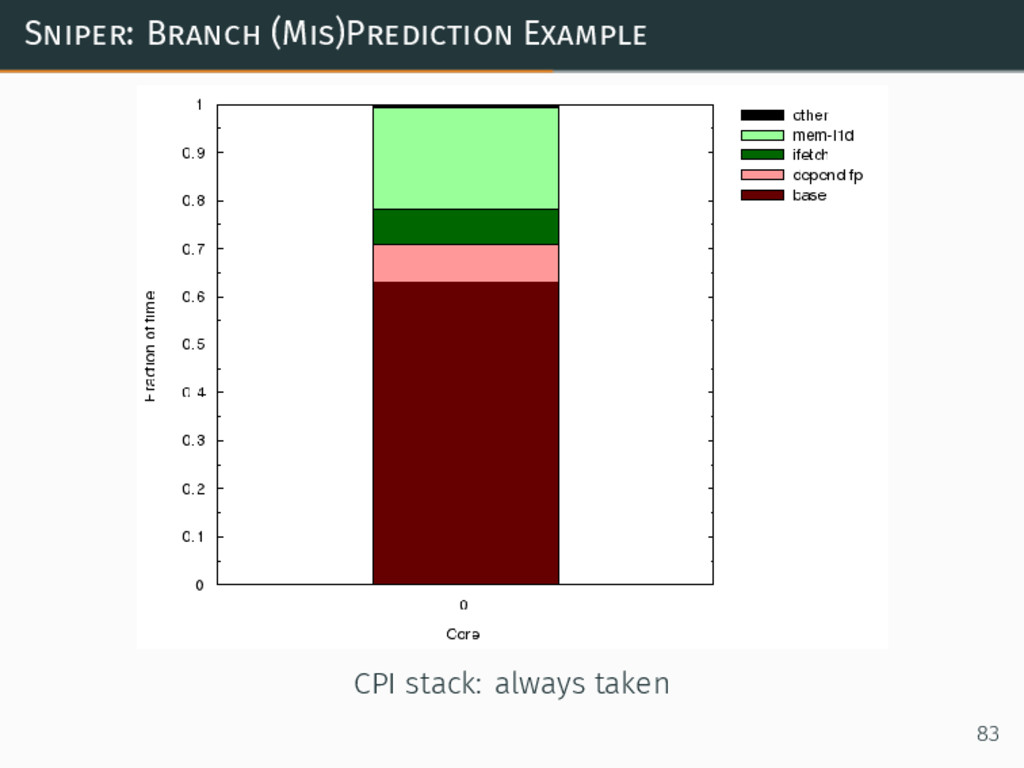{kind=link}
Sniper: Branch (Mis)Prediction Example CPI stack: randomly taken 84
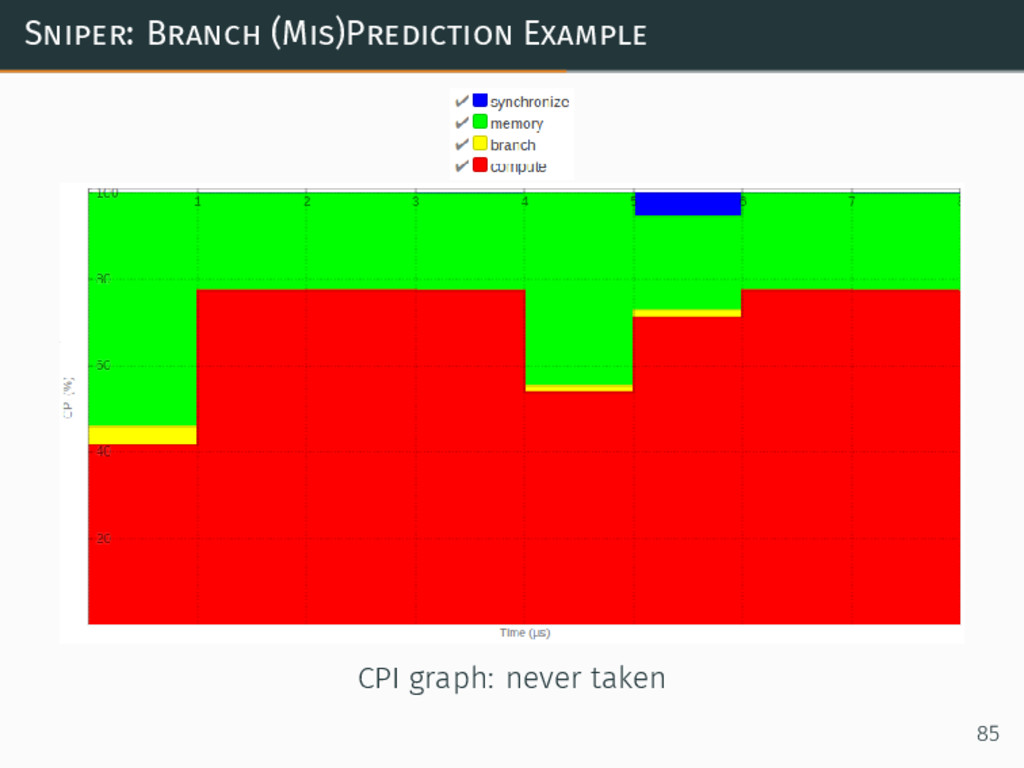
{kind=link}
Sniper: Branch (Mis)Prediction Example CPI graph: never taken 85
{kind=link}
Sniper: Branch (Mis)Prediction Example CPI graph: always taken 86
{kind=link}
Sniper: Branch (Mis)Prediction Example CPI graph: randomly taken 87
{kind=link}
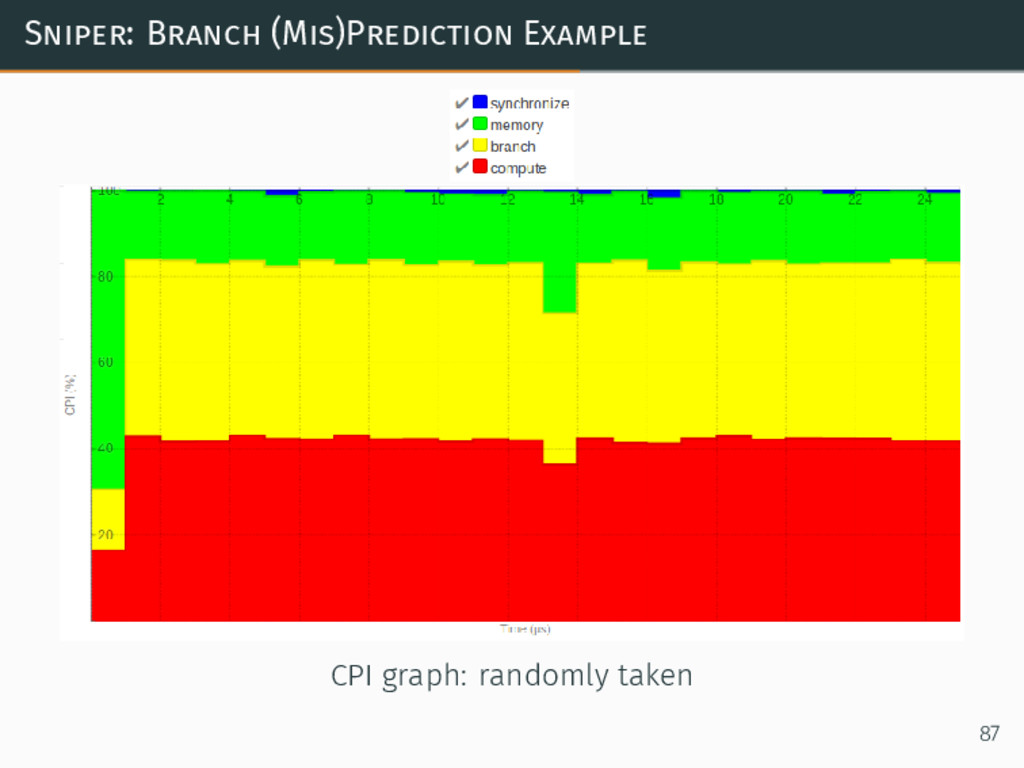
Sniper: Branch (Mis)Prediction Example CPI graph (detailed): always taken 88
{kind=link}
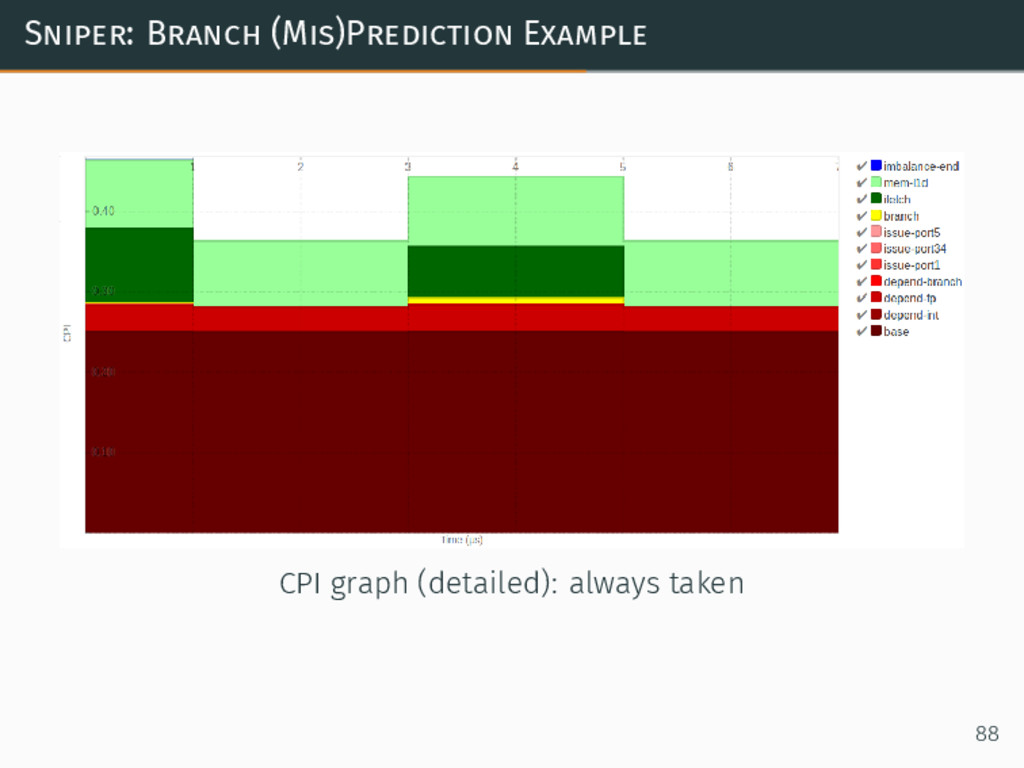
Sniper: Branch (Mis)Prediction Example CPI graph (detailed): randomly taken 89
{kind=link}
Gem5 http://www.gem5.org/ 90
{kind=link}
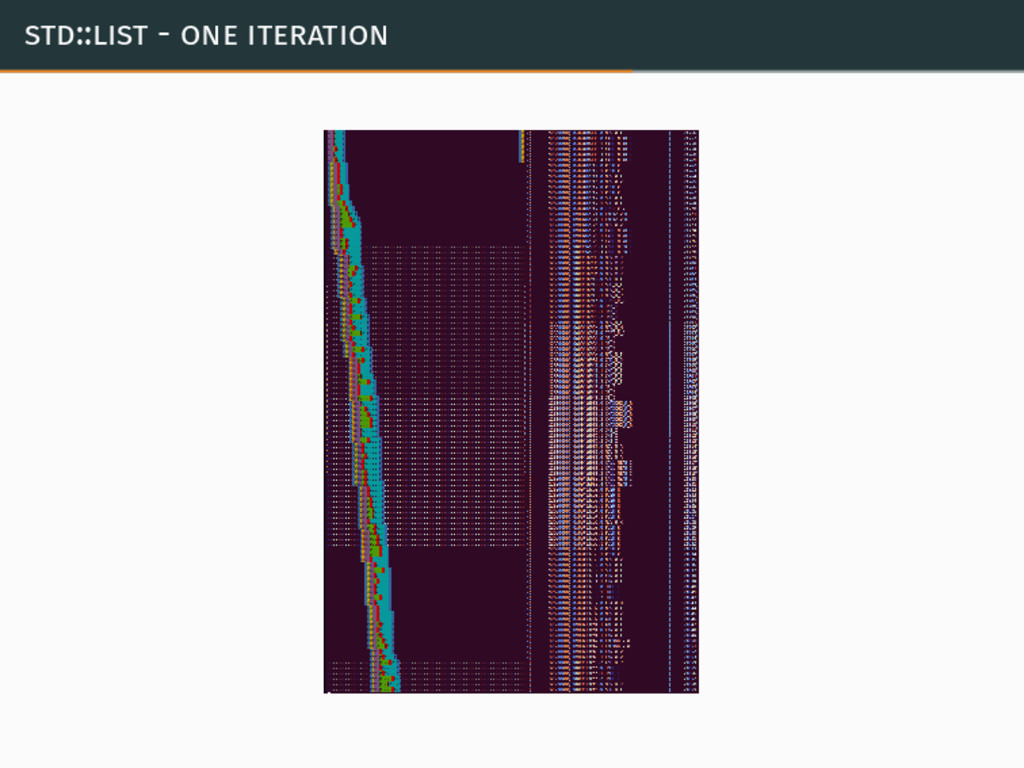
std::list - one iteration
{kind=link}
std::list - one iteration (continued...)
{kind=link}
std::list - one iteration (...continued still)
{kind=link}
std::list - one iteration (...done!)
{kind=link}
Loop Fusion 0.429504s (unfused) down to 0.287501s (fused) g++ -Ofast
{kind=link}
-march=native (5.2.0) void unfused(double * a, double * b, double * c, double * d, size_t N) { for (size_t i = 0; i != N; ++i) a[i] = b[i] * c[i]; for (size_t i = 0; i != N; ++i) d[i] = a[i] * c[i]; } void fused(double * a, double * b, double * c, double * d, size_t N) { for (size_t i = 0; i != N; ++i) { a[i] = b[i] * c[i]; d[i] = a[i] * c[i]; } } 100
Cache Miss Penalty: Different STC due to different MLP MLP
{kind=link}
(memory-level parallelism) & STC (stall-time criticality) R. Das, O. Mutlu, T. Moscibroda and C. R. Das, ”Application-aware prioritization mechanisms for on-chip networks,” 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), New York, NY, 2009, pp. 280-291. 101
Non-Overlapped Timings id,symbol,count,time 1,AAPL,565449,1.59043 2,AXP,731366,3.43745 3,BA,867366,5.40218 4,CAT,830327,7.08103 5,CSCO,400440,8.49192 6,CVX,687198,9.98761 7,DD,910932,12.2254
{kind=link}
8,DIS,910430,14.058 9,GE,871676,15.8333 10,GS,280604,17.059 11,HD,556611,18.2738 12,IBM,860071,20.3876 13,INTC,559127,21.9856 14,JNJ,724724,25.5534 15,JPM,500473,26.576 16,KO,864903,28.5405 17,MCD,717021,30.087 18,MMM,698996,31.749 19,MRK,733948,33.2642 20,MSFT,475451,34.3134 21,NKE,556344,36.4545 103
Overlapped Timings id,symbol,count,time 1,AAPL,565449,2.00713 2,AXP,731366,2.09158 3,BA,867366,2.13468 4,CAT,830327,2.19194 5,CSCO,400440,2.19197 6,CVX,687198,2.19198 7,DD,910932,2.51895
{kind=link}
8,DIS,910430,2.51898 9,GE,871676,2.51899 10,GS,280604,2.519 11,HD,556611,2.51901 12,IBM,860071,2.51902 13,INTC,559127,2.51902 14,JNJ,724724,2.51903 15,JPM,500473,2.51904 16,KO,864903,2.51905 17,MCD,717021,2.51906 18,MMM,698996,2.51907 19,MRK,733948,2.51908 20,MSFT,475451,2.51908 21,NKE,556344,2.51909 104
Visualizing & Monitoring Performance https://github.com/Celtoys/Remotery 105
{kind=link}
Timeline: Without Overlapping 106
{kind=link}
Timeline: With Overlapping 107
{kind=link}
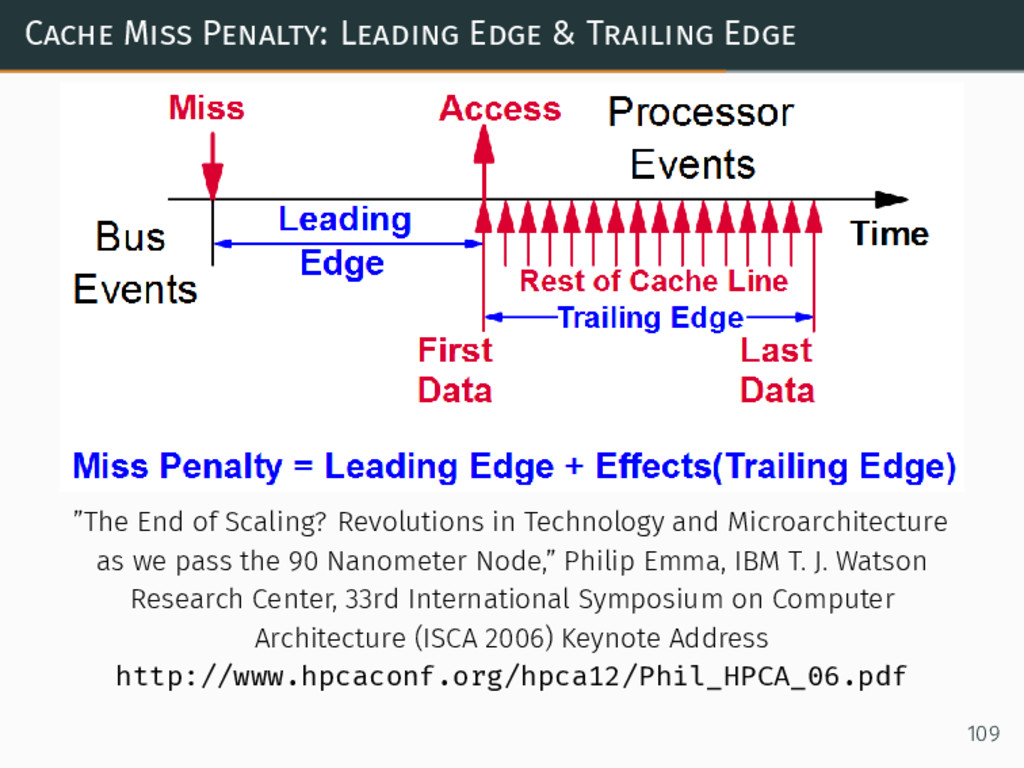
Cache Miss Penalty: Leading Edge & Trailing Edge ”The End
{kind=link}
of Scaling? Revolutions in Technology and Microarchitecture as we pass the 90 Nanometer Node,” Philip Emma, IBM T. J. Watson Research Center, 33rd International Symposium on Computer Architecture (ISCA 2006) Keynote Address http://www.hpcaconf.org/hpca12/Phil_HPCA_06.pdf 109
Multicore & DRAM: AoS II double sum_if(const container & a,
{kind=link}
const container & b, const std::vector<std::size_t> & index) { double sum = 0.0; for (std::size_t i = 0, n = index.size(); i < n; ++i) { std::size_t j = index[i]; if (a[j].K == b[j].K) sum += a[j].K; } return sum; } template <typename F> double average(F f, std::size_t m) { double average = 0.0; for (std::size_t i = 0; i < m; ++i) average += f() / m; return average; } 119
Multicore & DRAM: AoS IV int main(int argc, char *
{kind=link}
argv[]) { const std::size_t n = (argc >= 2) ? std::atoll(argv[1]) : 1000; const std::size_t m = (argc >= 3) ? std::atoll(argv[2]) : 10; std::cout << "n = " << n << '\n'; std::cout << "m = " << m << '\n'; const std::size_t threads_count = 4; // thread access locality type // 0: none (default); 1: stream; 2: random std::vector<std::size_t> thread_type(threads_count); for (std::size_t thread = 0; thread != threads_count; ++thread) { thread_type[thread] = (argc >= 4 + thread) ? std::atoll(argv[3 + thread]) : 0; std::cout << "thread_type[" << thread << "] = " << thread_type[thread] << '\n'; } 121
Multicore & DRAM: AoS V endl(std::cout); std::vector<std::vector<std::size_t>> index(threads_count); for (std::size_t
{kind=link}
thread = 0; thread != threads_count; ++thread) { index[thread].resize(n); if (thread_type[thread] == 1) index[thread] = index_stream(n); else if (thread_type[thread] == 2) index[thread] = index_random(n); } const container v1(n, {1.0, 0.5, 3.0}); const container v2(n, {1.0, 2.0, 1.0}); const auto thread_work = [m, &v1, &v2](const auto & thread_index) { const auto f = [&v1, &v2, &thread_index] { return sum_if(v1, v2, thread_index); }; return average(f, m); }; 122
Multicore & DRAM: AoS Timings 4 threads: 3 sequential access
{kind=link}
+ 1 random access $ ./DRAM_CMP 10000000 10 1 1 1 2 n = 10000000 m = 10 thread_type[0] = 1 thread_type[1] = 1 thread_type[2] = 1 thread_type[3] = 2 1e+007 1e+007 1e+007 1e+007 5.666049s wall, 7.265625s user + 0.000000s system = 7.265625s CPU (128.2%) 127
Multicore & DRAM: AoS Timings Memory Access Patterns & Multicore:
{kind=link}
Interactions Matter Inter-thread Interference Sharing - Contention - Interference - Slowdown Threads using a shared resource (like on-chip/off-chip interconnects and memory) contend for it, interfering with each other’s progress, resulting in slowdown (and thus negative returns to increased threads count). cf. Thomas Moscibroda and Onur Mutlu, ”Memory Performance Attacks: Denial of Memory Service in Multi-Core Systems,” Microsoft Research Technical Report, MSR-TR-2007-15, February 2007. 128
Multicore & DRAM: SoA II double sum_if(const data & a,
{kind=link}
const data & b, const std::vector<std::size_t { double sum = 0.0; for (std::size_t i = 0, n = index.size(); i < n; ++i) { std::size_t j = index[i]; if (a.K[j] == b.K[j]) sum += a.K[j]; } return sum; } template <typename F> double average(F f, std::size_t m) { double average = 0.0; for (std::size_t i = 0; i < m; ++i) { average += f() / m; } 130
Multicore & DRAM: SoA IV for (std::size_t i = 0;
{kind=link}
i < n; ++i) index.push_back(u(g)); return index; } int main(int argc, char * argv[]) { const std::size_t n = (argc >= 2) ? std::atoll(argv[1]) : 1000; const std::size_t m = (argc >= 3) ? std::atoll(argv[2]) : 10; std::cout << "n = " << n << '\n'; std::cout << "m = " << m << '\n'; const std::size_t threads_count = 4; // thread access locality type // 0: none (default); 1: stream; 2: random std::vector<std::size_t> thread_type(threads_count); for (std::size_t thread = 0; thread != threads_count; ++thread) { 132
Multicore & DRAM: SoA V thread_type[thread] = (argc >= 4
![Multicore & DRAM: SoA V thread_type[thread] = (argc >= 4](https://files.speakerdeck.com/presentations/955409d184d54c4d970c4644db656f81/slide_134.jpg){kind=link}
+ thread) ? std::atoll(argv[3 + th std::cout << "thread_type[" << thread << "] = " << thread_type[thre } endl(std::cout); std::vector<std::vector<std::size_t>> index(threads_count); for (std::size_t thread = 0; thread != threads_count; ++thread) { index[thread].resize(n); if (thread_type[thread] == 1) index[thread] = index_stream(n); else if (thread_type[thread] == 2) index[thread] = index_random(n); //for (auto e : index[thread]) std::cout << e; endl(std::cout); } data v1; v1.K.resize(n, 1.0); v1.T.resize(n, 0.5); v1.P.resize(n, 3.0); 133
Multicore & DRAM: SoA VI data v2; v2.K.resize(n, 1.0); v2.T.resize(n,
{kind=link}
2.0); v2.P.resize(n, 1.0); const auto thread_work = [m, &v1, &v2](const auto & thread_index) { const auto f = [&v1, &v2, &thread_index] { return sum_if(v1, v2, th return average(f, m); }; boost::timer::auto_cpu_timer timer; std::vector<std::future<double>> results; results.reserve(threads_count); for (std::size_t thread = 0; thread != threads_count; ++thread) { results.emplace_back(std::async(std::launch::async, [thread, &thread_work, &index] { return thread_work(index[thread]); 134
Multicore & DRAM: SoA Timings 4 threads: 3 sequential access
{kind=link}
+ 1 random access $ ./DRAM_CMP.SoA 10000000 10 1 1 1 2 n = 10000000 m = 10 thread_type[0] = 1 thread_type[1] = 1 thread_type[2] = 1 thread_type[3] = 2 1e+007 1e+007 1e+007 1e+007 4.581033s wall, 5.265625s user + 0.000000s system = 5.265625s CPU (114.9%) 139
Roofline Model(s) http://www.eecs.berkeley.edu/~waterman/papers/roofline.pdf Roofline: an insightful visual performance model for
{kind=link}
multicore architectures Samuel Williams, Andrew Waterman and David Patterson Communications ACM 55(6): 121-130 (2012) http://www.inesc-id.pt/ficheiros/publicacoes/9068.pdf Cache-aware Roofline model: Upgrading the loft Aleksandar Ilic, Frederico Pratas, Leonel Sousa, IEEE Computer Architecture Letters, vol. 13, no. 1, pp. 1-1, Jan.-June, 2014 http://spiral.ece.cmu.edu:8080/pub-spiral/abstract.jsp?id=181 Extending the Roofline Model: Bottleneck Analysis with Microarchitectural Constraints Victoria Caparros and Markus Püschel Proc. IEEE International Symposium on Workload Characterization (IISWC), pp. 222-231, 2014 147
Takeaways Principles Data structures & data layout - fundamental part
{kind=link}
of design CPUs & pervasive forms parallelism • can support each other: PLP, ILP (MLP!), TLP, DLP Balanced design vs. bottlenecks Overlapping latencies Sharing-contention-interference-slowdown Yale Patt’s Phase 2: Break the layers: • break through the hardware/software interface • harness all levels of the transformation hierarchy 148
Pigeonholing has to go Yale N. Patt at Yale Patt
{kind=link}
75 Visions of the Future Computer Architecture Workshop: ”Are you a software person or a hardware person?” I’m a person this pigeonholing has to go We must break the layers Abstractions are great - AFTER you understand what’s being abstracted Yale N. Patt, 2013 IEEE CS Harry H. Goode Award Recipient Interview — https://youtu.be/S7wXivUy-tk Yale N. Patt at Yale Patt 75 Visions of the Future Computer Architecture Workshop — https://youtu.be/x4LH1cJCvxs 151
Resources http://www.agner.org/optimize/ https://users.ece.cmu.edu/~omutlu/lecture-videos.html https://github.com/MattPD/cpplinks/ 152
{kind=link}
Slides https://speakerdeck.com/mattpd 153
{kind=link}
{kind=link}