I'm Samuel Williams. I built Falcon. And BFCM 2025 was
{kind=link}
the moment we found out what it was actually worth. I'm joined by Marc and Josh — and together, we're going to tell you about the biggest bet we've ever made on Ruby. How We Survived BFCM with Falcon at Shopify RubyKaigi 2026 Falcon でBFCM を乗り越えた方法 Slide 1 of 170 0010-title.md Elapsed: 00:00 Slide: 00:14 🎤 Samuel
Five parts. The bet we made, the things that broke,
{kind=link}
the darkest week of the project, BFCM itself, and the lessons we took away. Marc will take us through the bet. The Bet Things Start Breaking The Darkest Week BFCM Lessons 本日の流れ:賭け、問題発生、最も暗い一週間、BFCM 、教訓 Slide 2 of 170 0015-agenda.md Elapsed: 00:14 Slide: 00:11 🎤 Samuel
Storefront Renderer. A Rack app. It powers every online store
{kind=link}
on the platform. If you've ever visited a Shopify store, this is the code that rendered the page. The App: Shopify's Storefront Renderer. Powers every online store. Shopify のストアフロントレンダラーは、すべてのオンラインストアを動かしている。 Slide 7 of 170 0070-storefront.md Elapsed: 00:47 Slide: 00:10 🎤 Marc-Andre
And once a year, for BFCM, all of our traffic
{kind=link}
doubles. This is the biggest shopping weekend on the internet. Once a year, all of that traffic doubles. 年に一度、そのトラフィックが倍になる。 Slide 9 of 170 0090-bfcm-doubles.md Elapsed: 01:09 Slide: 00:10 🎤 Marc-Andre
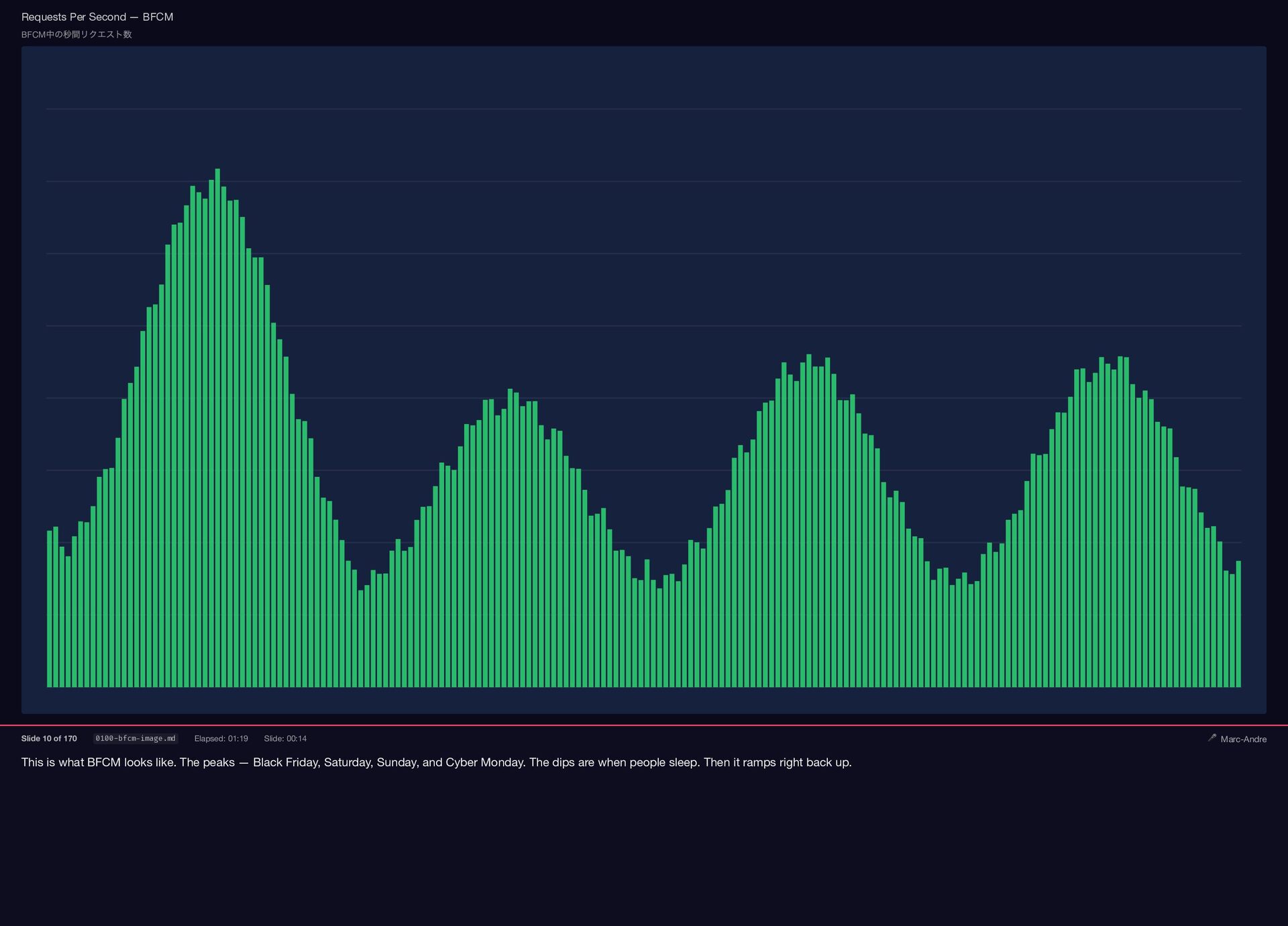
This is what BFCM looks like. The peaks — Black
{kind=link}
Friday, Saturday, Sunday, and Cyber Monday. The dips are when people sleep. Then it ramps right back up. Requests Per Second — BFCM BFCM 中の秒間リクエスト数 Slide 10 of 170 0100-bfcm-image.md Elapsed: 01:19 Slide: 00:14 🎤 Marc-Andre
And for a long time we ran all this on
{kind=link}
Unicorn. It uses one process per request. It's simple, reliable. Problem is it blocks on I/O. Unicorn: One process. One request. Simple. Reliable. 1 プロセス。1 リクエスト。シンプル。信頼性。 Slide 12 of 170 0130-unicorn-model.md Elapsed: 01:44 Slide: 00:13 🎤 Marc-Andre
When a request waits on I/O — calling to an
{kind=link}
external service, for example — the whole worker just sits there. Doing nothing. The entire worker just sits there. Doing nothing. ワーカー全体が何もせずに遊んでいる。 Slide 13 of 170 0140-unicorn-problem.md Elapsed: 01:57 Slide: 00:08 🎤 Marc-Andre
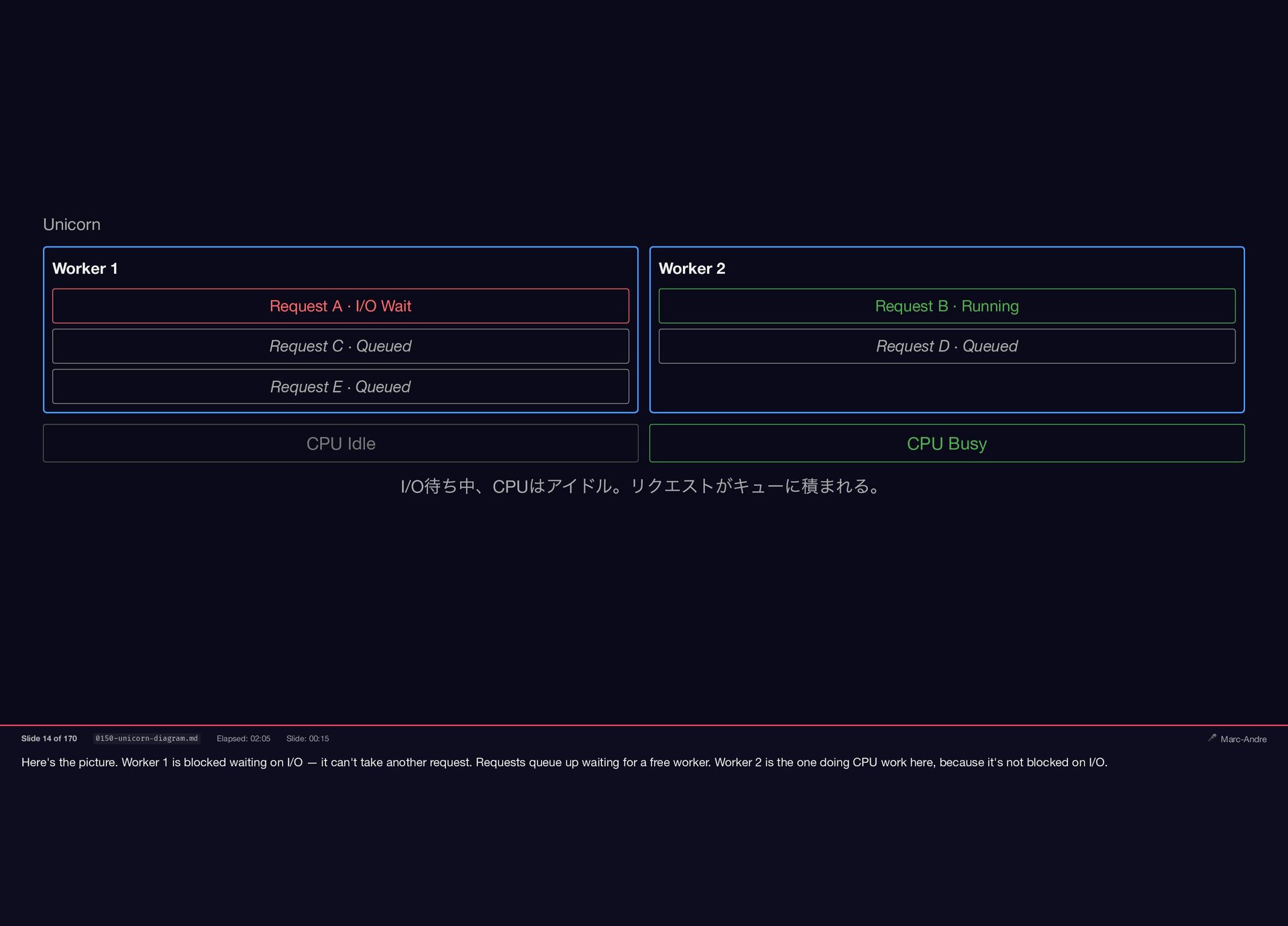
Here's the picture. Worker 1 is blocked waiting on I/O
{kind=link}
— it can't take another request. Requests queue up waiting for a free worker. Worker 2 is the one doing CPU work here, because it's not blocked on I/O. Unicorn Worker 1 Request A · I/O Wait Request C · Queued Request E · Queued Worker 2 Request B · Running Request D · Queued CPU Idle CPU Busy I/O 待ち中、CPU はアイドル。リクエストがキューに積まれる。 Slide 14 of 170 0150-unicorn-diagram.md Elapsed: 02:05 Slide: 00:15 🎤 Marc-Andre
In Falcon each worker handles multiple requests concurrently, in the
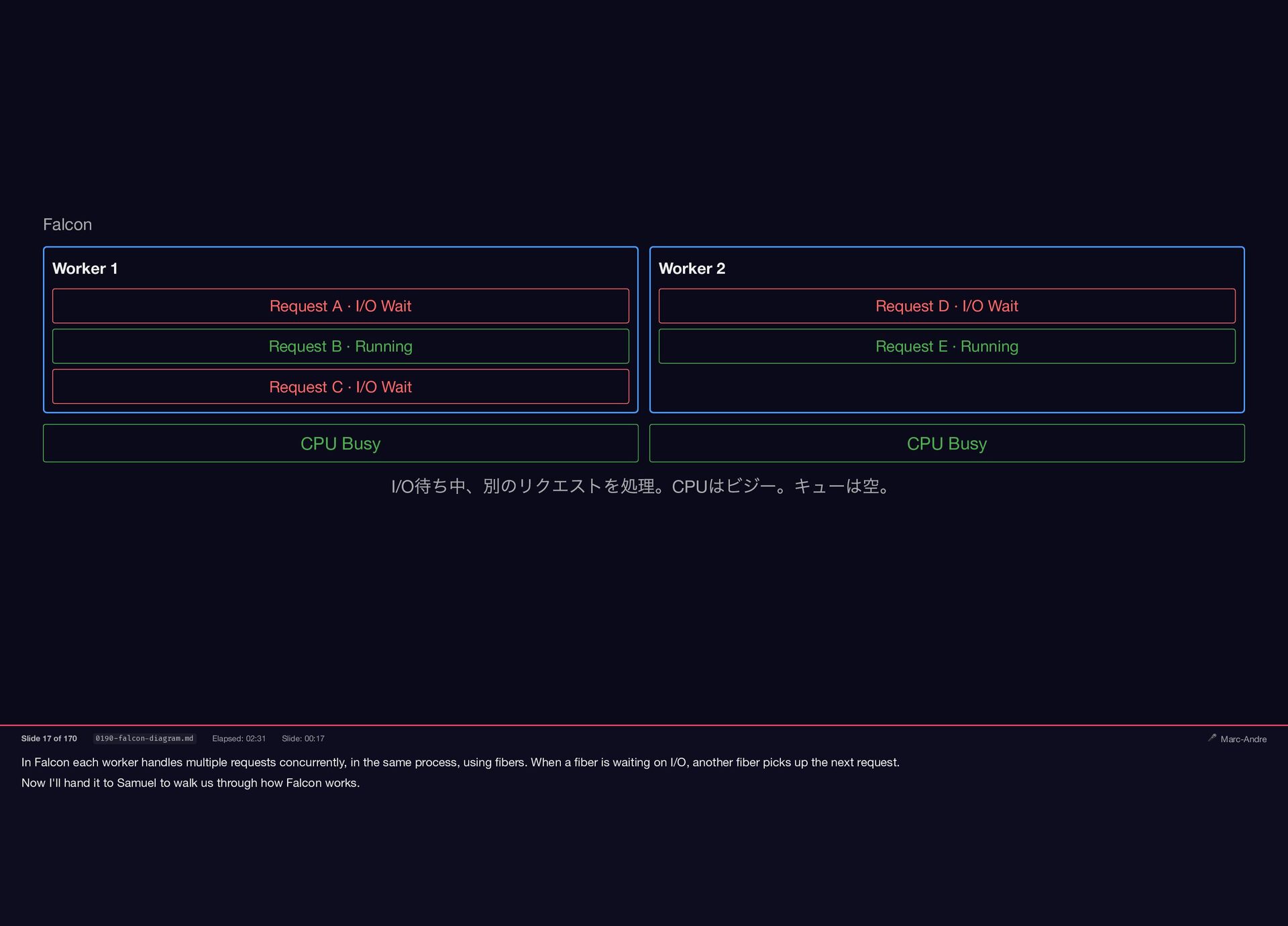{kind=link}
same process, using fibers. When a fiber is waiting on I/O, another fiber picks up the next request. Now I'll hand it to Samuel to walk us through how Falcon works. Falcon Worker 1 Request A · I/O Wait Request B · Running Request C · I/O Wait Worker 2 Request D · I/O Wait Request E · Running CPU Busy CPU Busy I/O 待ち中、別のリクエストを処理。CPU はビジー。キューは空。 Slide 17 of 170 0190-falcon-diagram.md Elapsed: 02:31 Slide: 00:17 🎤 Marc-Andre
Each fiber handles one request. When a fiber is waiting
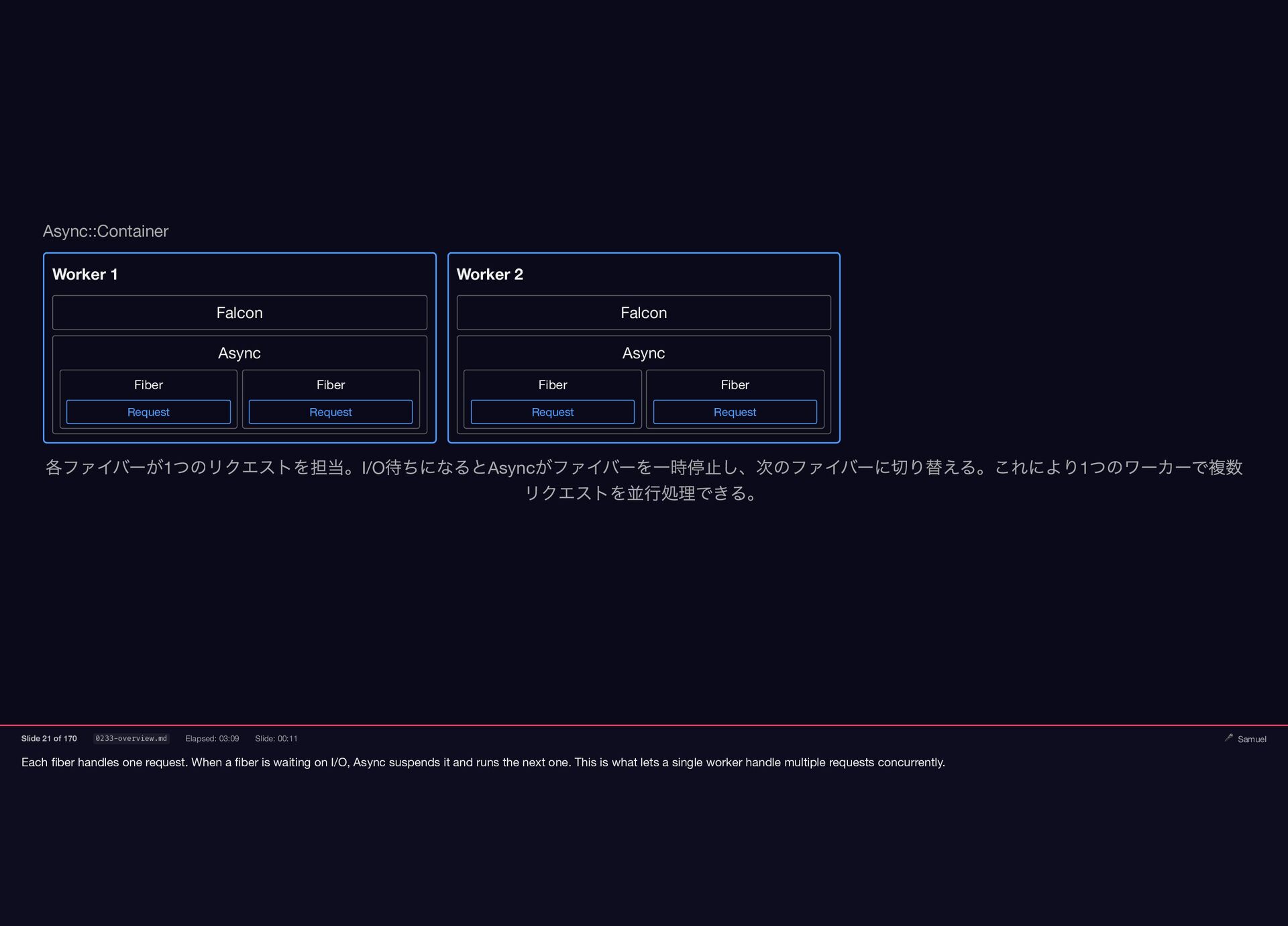{kind=link}
on I/O, Async suspends it and runs the next one. This is what lets a single worker handle multiple requests concurrently. Async::Container Worker 1 Falcon Async Worker 2 Falcon Async Fiber Request Fiber Request Fiber Request Fiber Request 各ファイバーが1 つのリクエストを担当。I/O 待ちになるとAsync がファイバーを一時停止し、次のファイバーに切り替える。これにより1 つのワーカーで複数 リクエストを並行処理できる。 Slide 21 of 170 0233-overview.md Elapsed: 03:09 Slide: 00:11 🎤 Samuel
In addition to that, Falcon can have a supervisor, which
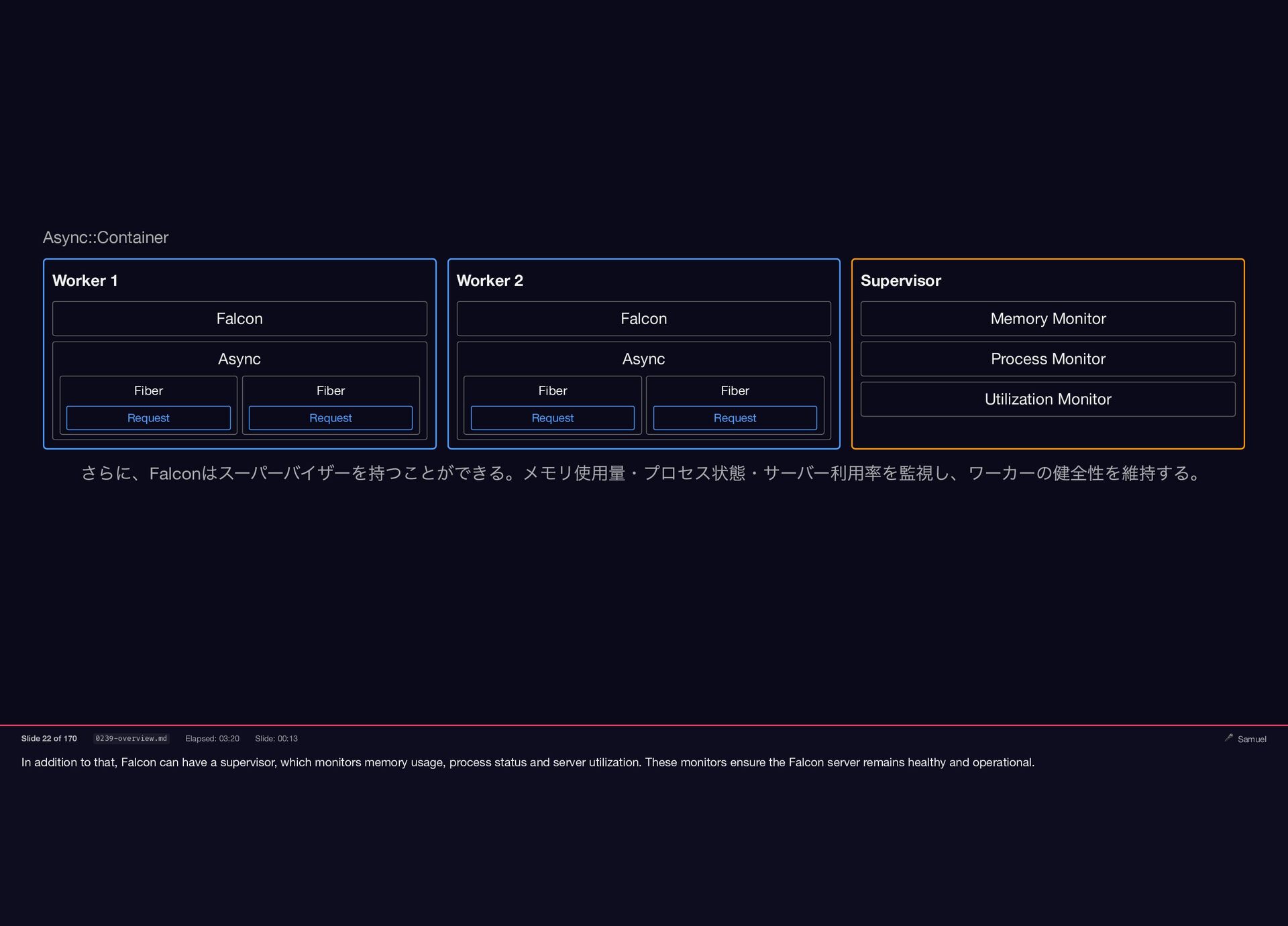{kind=link}
monitors memory usage, process status and server utilization. These monitors ensure the Falcon server remains healthy and operational. Async::Container Worker 1 Falcon Async Fiber Request Fiber Request Worker 2 Falcon Async Fiber Request Fiber Request Supervisor Memory Monitor Process Monitor Utilization Monitor さらに、Falcon はスーパーバイザーを持つことができる。メモリ使用量・プロセス状態・サーバー利用率を監視し、ワーカーの健全性を維持する。 Slide 22 of 170 0239-overview.md Elapsed: 03:20 Slide: 00:13 🎤 Samuel
Now let's look at how request scheduling actually works —
{kind=link}
how Async decides which fiber runs next, and what happens when a request is waiting on I/O. Async Fiber Request Fiber Request では、Async がどのようにファイバーをスケジュールするかを見てみましょう。 Slide 23 of 170 0240-async-fiber.md Elapsed: 03:33 Slide: 00:10 🎤 Samuel
Here is a trivialized example showing two requests. Async —
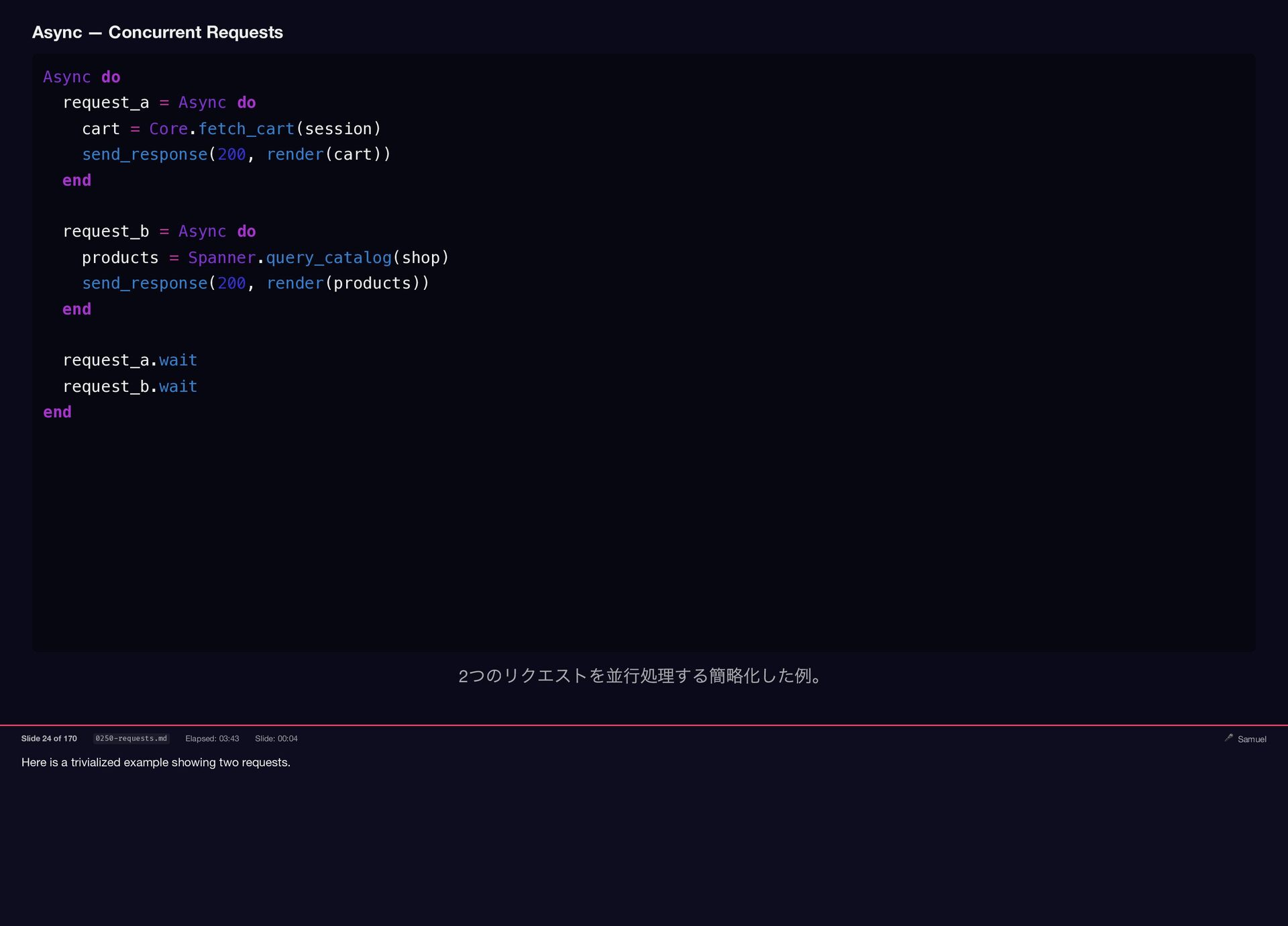{kind=link}
Concurrent Requests Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end 2 つのリクエストを並行処理する簡略化した例。 Slide 24 of 170 0250-requests.md Elapsed: 03:43 Slide: 00:04 🎤 Samuel
Request A — a cart fetch from Core. Async —
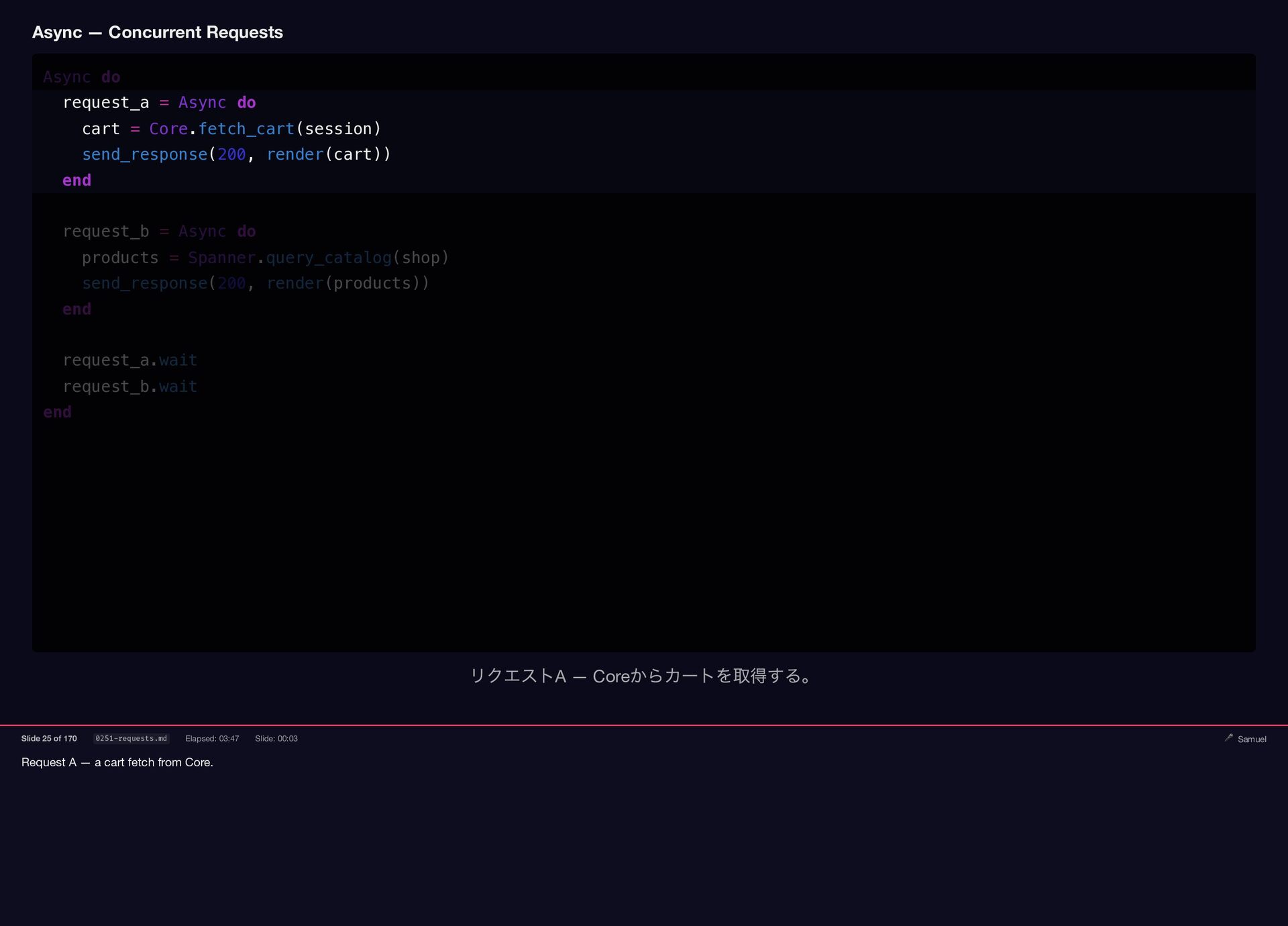{kind=link}
Concurrent Requests Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end リクエストA — Core からカートを取得する。 Slide 25 of 170 0251-requests.md Elapsed: 03:47 Slide: 00:03 🎤 Samuel
When this fiber hits the network wait, it doesn't block.
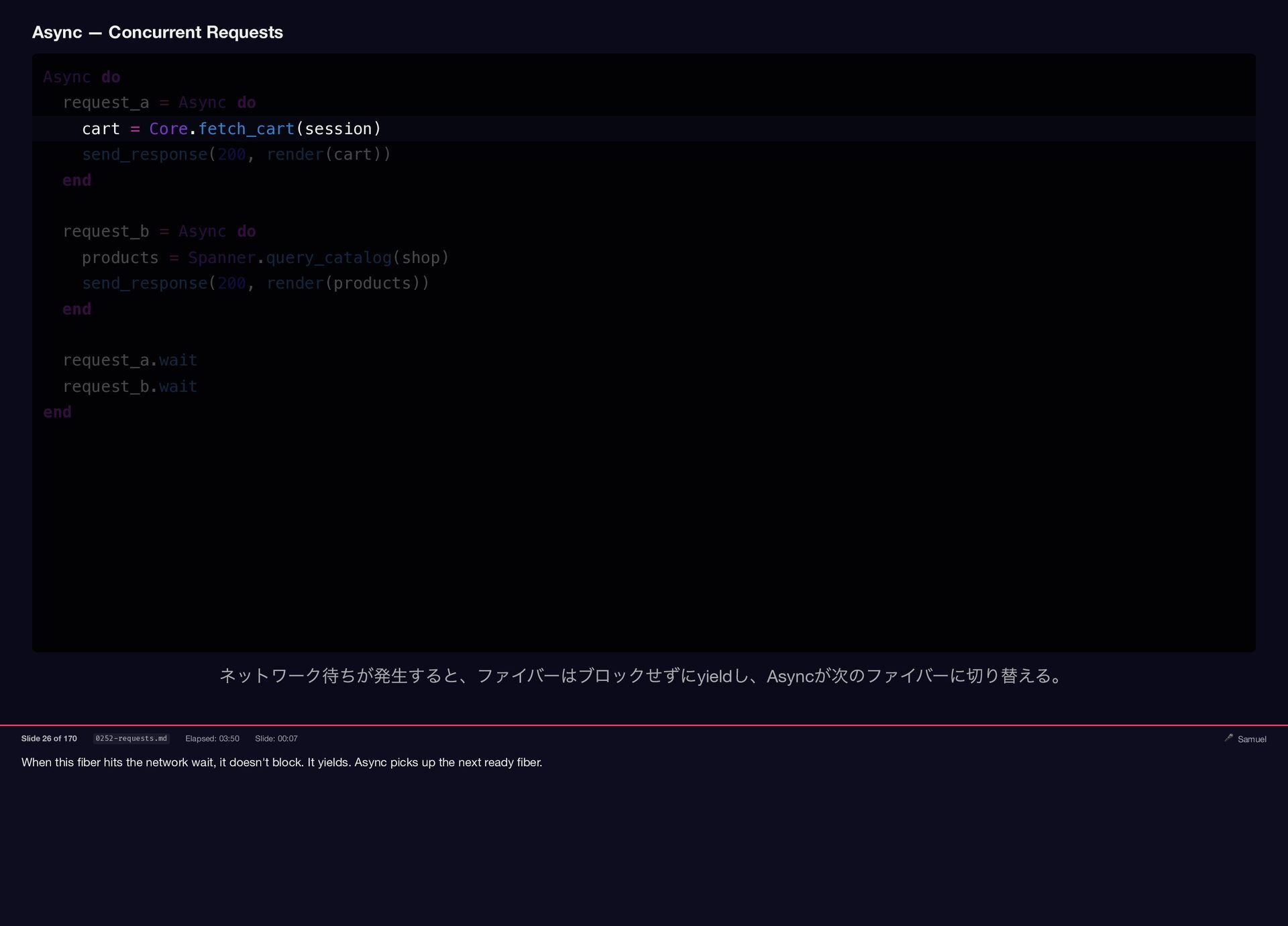{kind=link}
It yields. Async picks up the next ready fiber. Async — Concurrent Requests Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end ネットワーク待ちが発生すると、ファイバーはブロックせずにyield し、Async が次のファイバーに切り替える。 Slide 26 of 170 0252-requests.md Elapsed: 03:50 Slide: 00:07 🎤 Samuel
That is request B — a catalog query from Spanner.
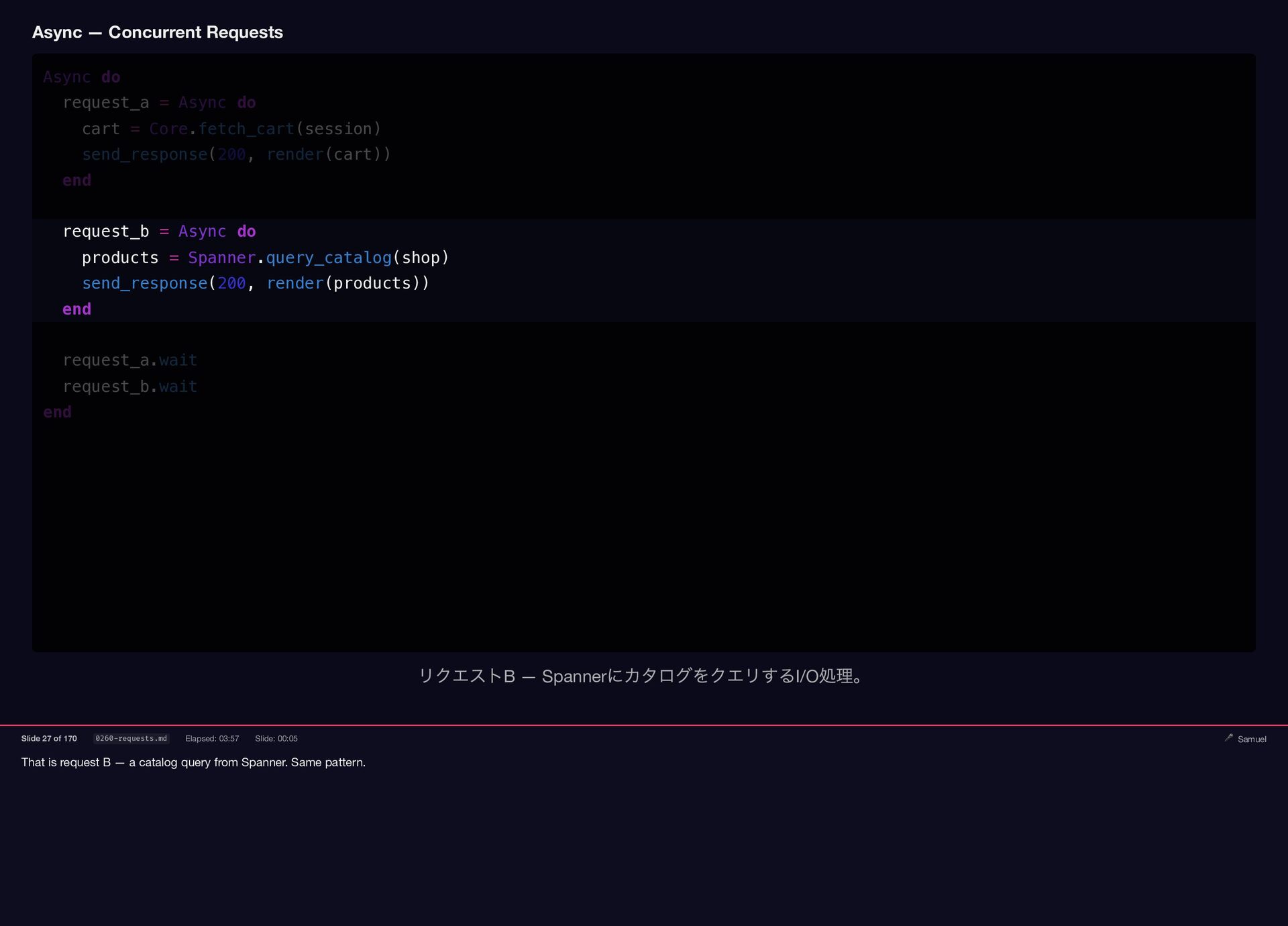{kind=link}
Same pattern. Async — Concurrent Requests Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end リクエストB — Spanner にカタログをクエリするI/O 処理。 Slide 27 of 170 0260-requests.md Elapsed: 03:57 Slide: 00:05 🎤 Samuel
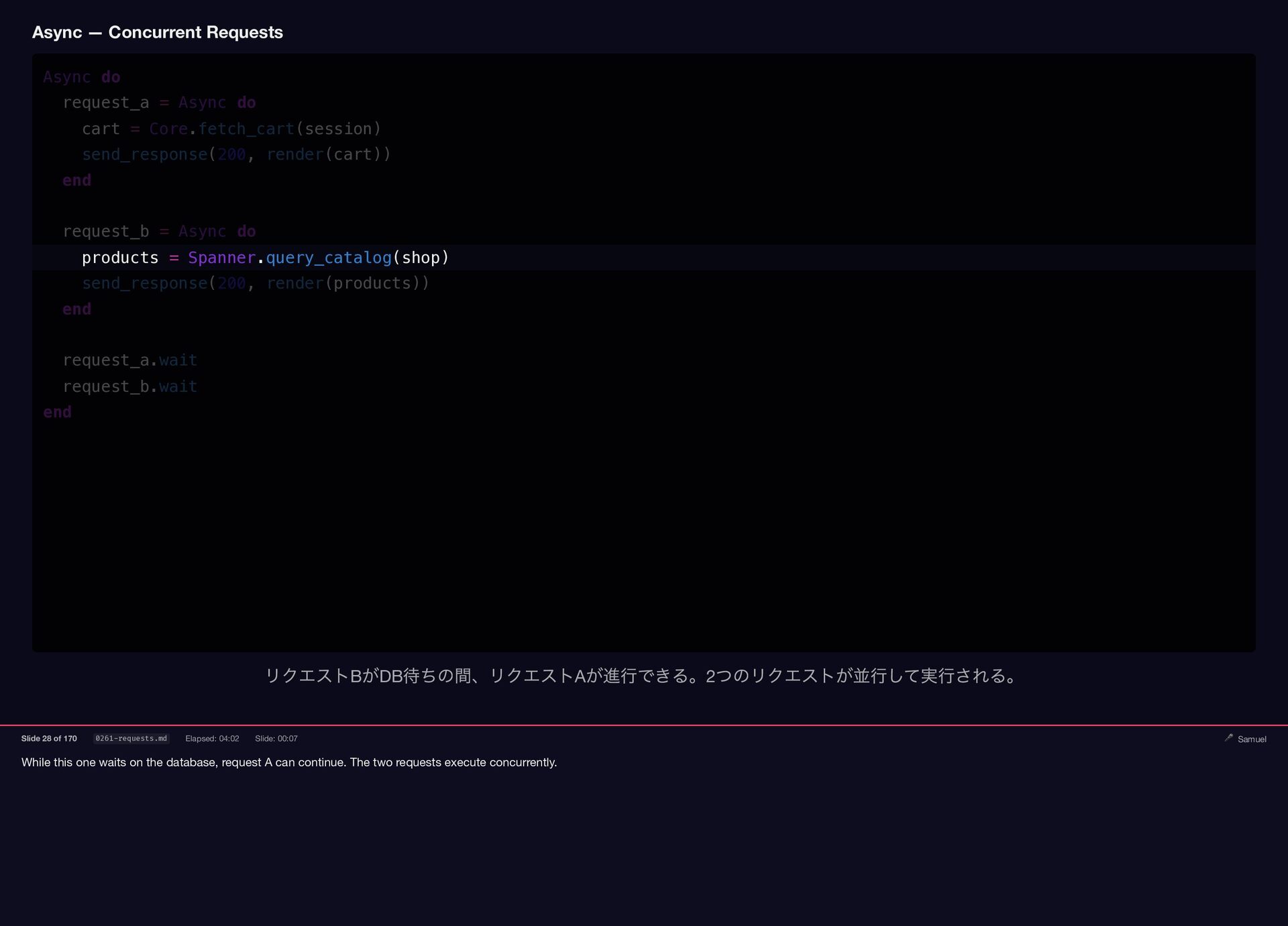
While this one waits on the database, request A can
{kind=link}
continue. The two requests execute concurrently. Async — Concurrent Requests Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end リクエストB がDB 待ちの間、リクエストA が進行できる。2 つのリクエストが並行して実行される。 Slide 28 of 170 0261-requests.md Elapsed: 04:02 Slide: 00:07 🎤 Samuel
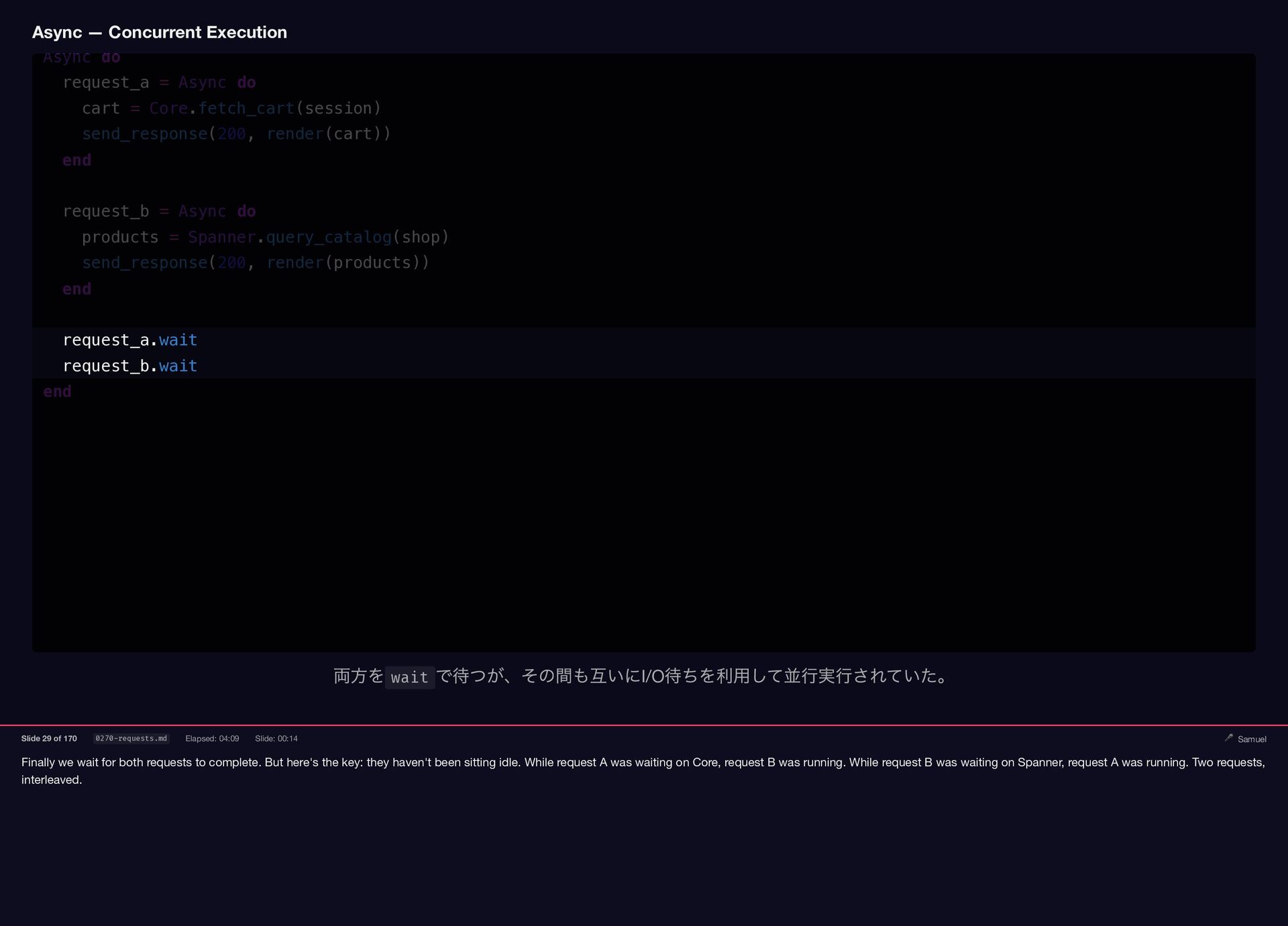
Finally we wait for both requests to complete. But here's
{kind=link}
the key: they haven't been sitting idle. While request A was waiting on Core, request B was running. While request B was waiting on Spanner, request A was running. Two requests, interleaved. Async — Concurrent Execution Async do request_a = Async do cart = Core.fetch_cart(session) send_response(200, render(cart)) end request_b = Async do products = Spanner.query_catalog(shop) send_response(200, render(products)) end request_a.wait request_b.wait end 両方を wait で待つが、その間も互いにI/O 待ちを利用して並行実行されていた。 Slide 29 of 170 0270-requests.md Elapsed: 04:09 Slide: 00:14 🎤 Samuel
At it's heart, async uses the io-event gem, which provides
{kind=link}
platform-specific backends for multiplexing blocking operations: io_uring and epoll on Linux and kqueue on macOS. io-event — the engine underneath: epoll , kqueue , io_uring . プラットフォーム固有のI/O バックエンド。 Slide 30 of 170 0290-io-event.md Elapsed: 04:23 Slide: 00:14 🎤 Samuel
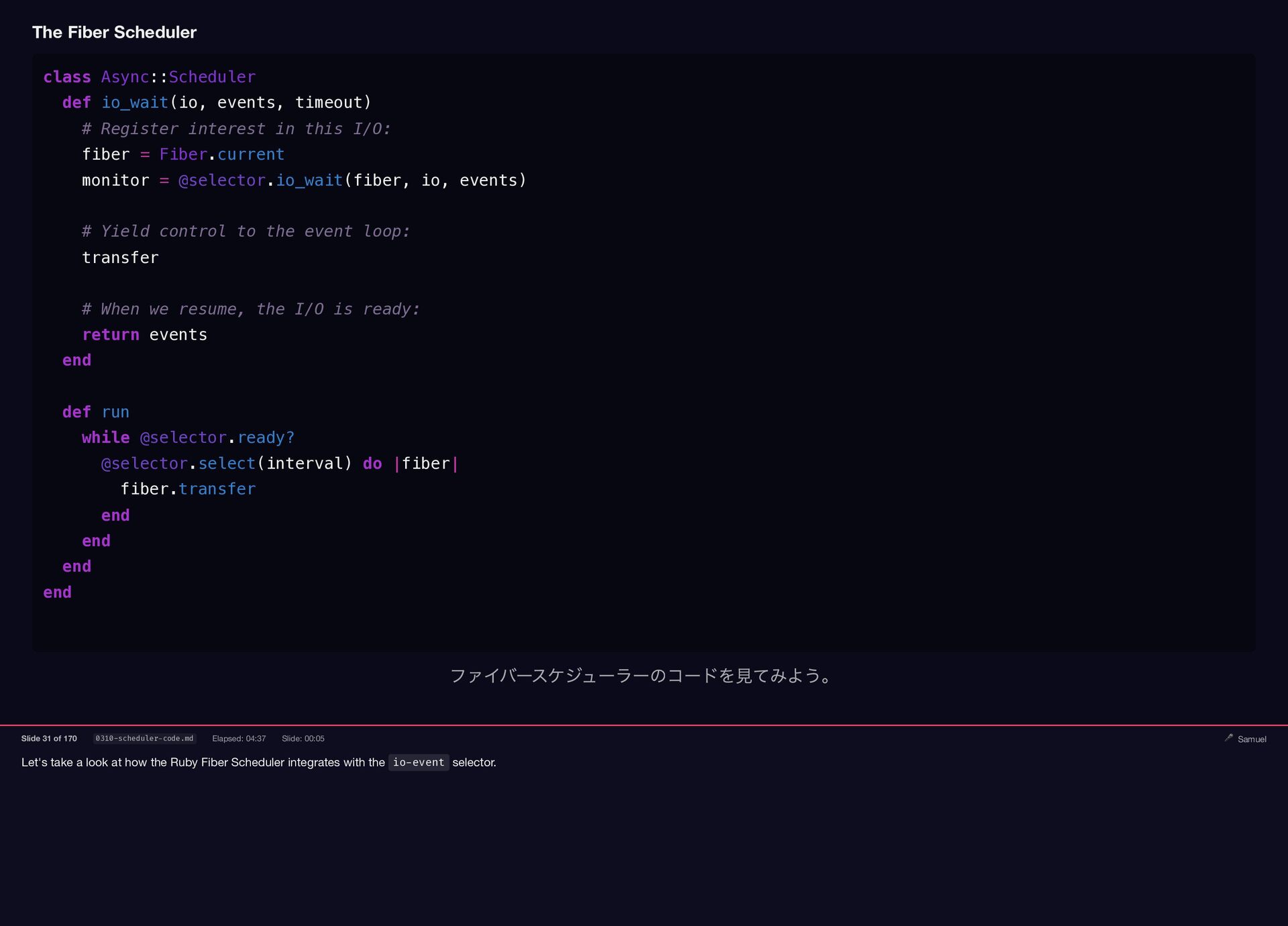
Let's take a look at how the Ruby Fiber Scheduler
{kind=link}
integrates with the io-event selector. The Fiber Scheduler class Async::Scheduler def io_wait(io, events, timeout) # Register interest in this I/O: fiber = Fiber.current monitor = @selector.io_wait(fiber, io, events) # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end ファイバースケジューラーのコードを見てみよう。 Slide 31 of 170 0310-scheduler-code.md Elapsed: 04:37 Slide: 00:05 🎤 Samuel
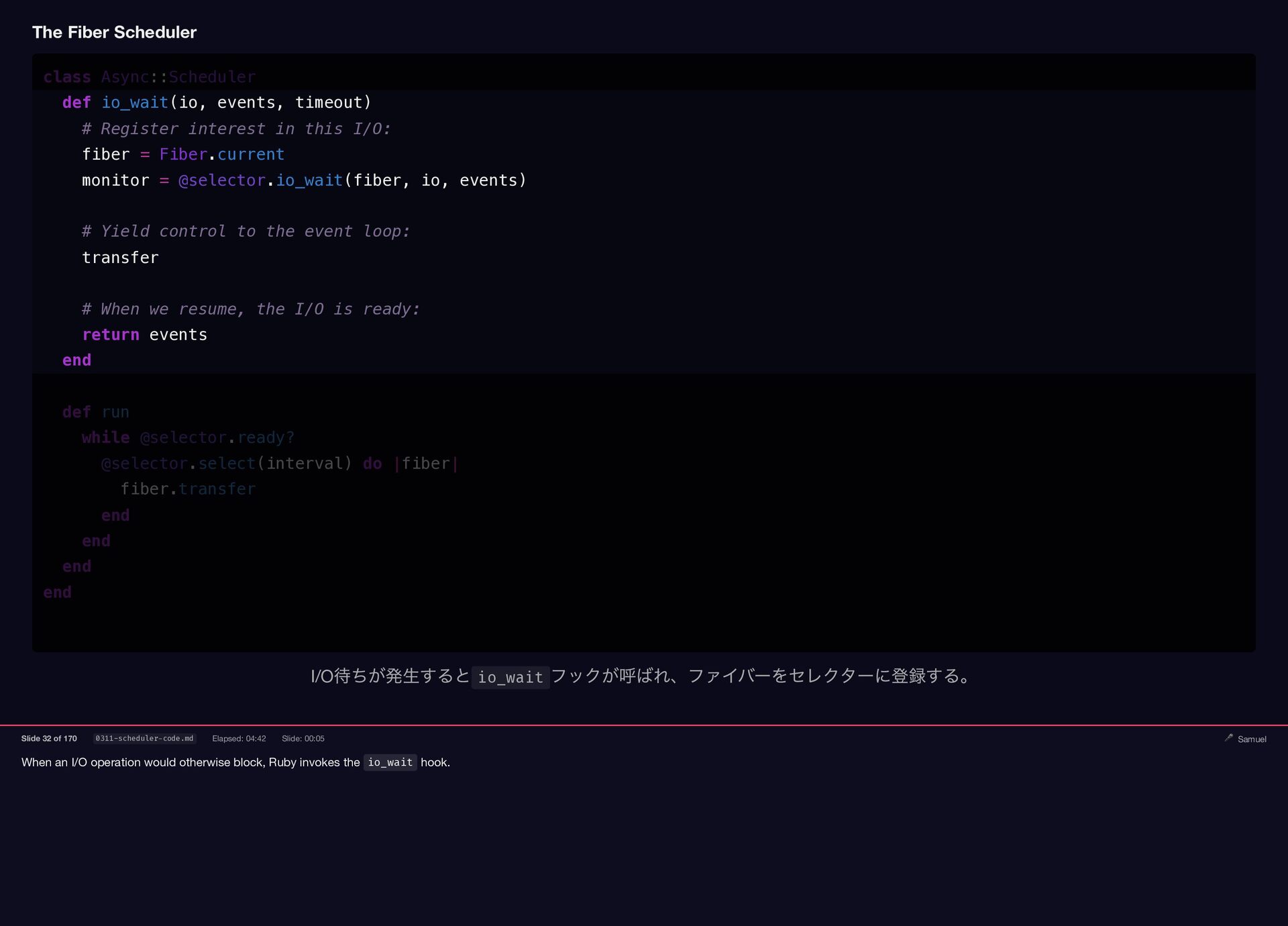
When an I/O operation would otherwise block, Ruby invokes the
{kind=link}
io_wait hook. The Fiber Scheduler class Async::Scheduler def io_wait(io, events, timeout) # Register interest in this I/O: fiber = Fiber.current monitor = @selector.io_wait(fiber, io, events) # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end I/O 待ちが発生すると io_wait フックが呼ばれ、ファイバーをセレクターに登録する。 Slide 32 of 170 0311-scheduler-code.md Elapsed: 04:42 Slide: 00:05 🎤 Samuel
The implementation registers the fiber with the io-event selector... The
{kind=link}
Fiber Scheduler class Async::Scheduler def io_wait(io, events, timeout) # Register interest in this I/O: fiber = Fiber.current monitor = @selector.io_wait(fiber, io, events) # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end io-event セレクターにファイバーを登録し、I/O の準備ができるまで監視する。 Slide 33 of 170 0312-scheduler-code.md Elapsed: 04:47 Slide: 00:04 🎤 Samuel
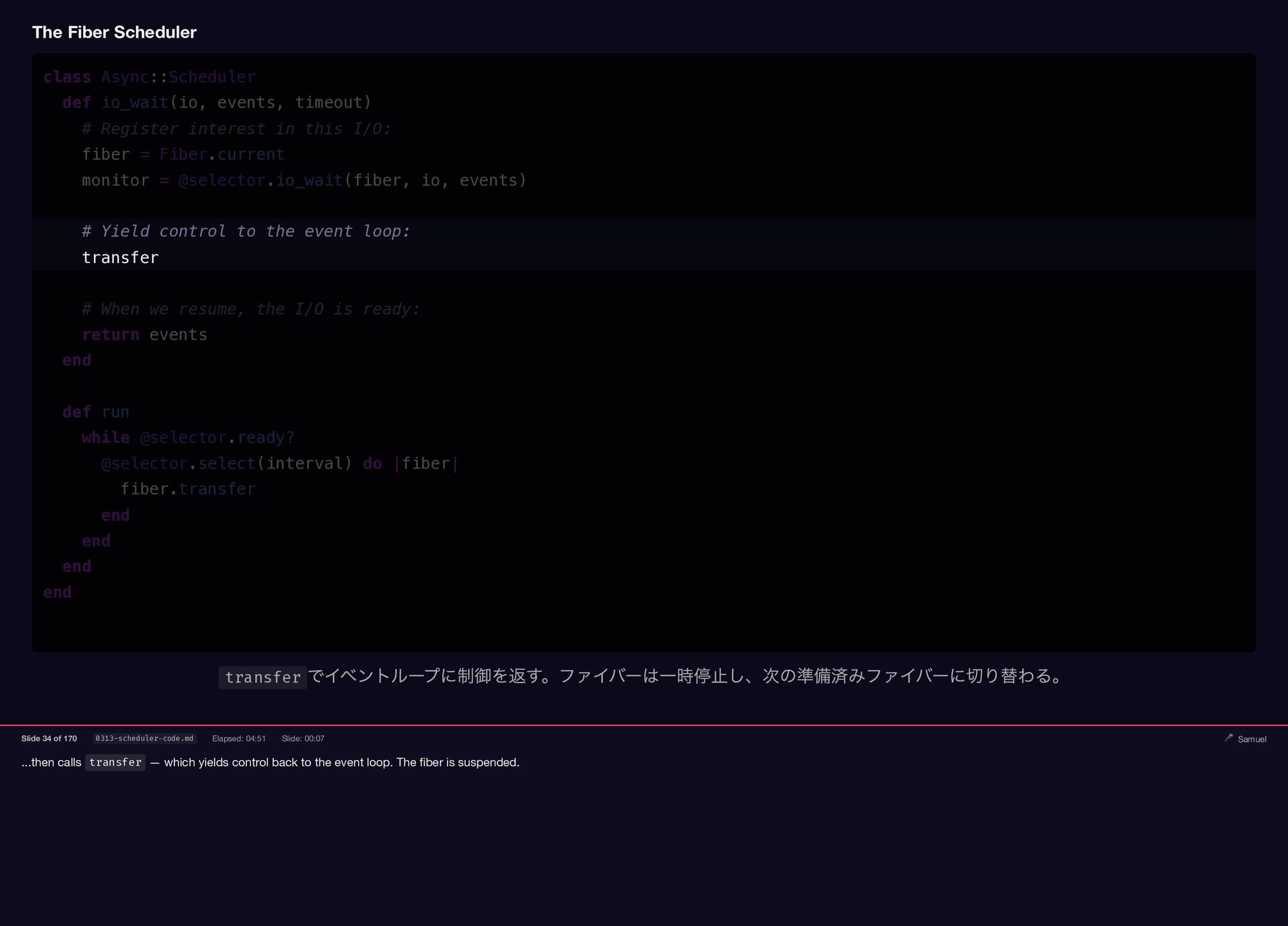
...then calls transfer — which yields control back to the
{kind=link}
event loop. The fiber is suspended. The Fiber Scheduler class Async::Scheduler def io_wait(io, events, timeout) # Register interest in this I/O: fiber = Fiber.current monitor = @selector.io_wait(fiber, io, events) # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end transfer でイベントループに制御を返す。ファイバーは一時停止し、次の準備済みファイバーに切り替わる。 Slide 34 of 170 0313-scheduler-code.md Elapsed: 04:51 Slide: 00:07 🎤 Samuel
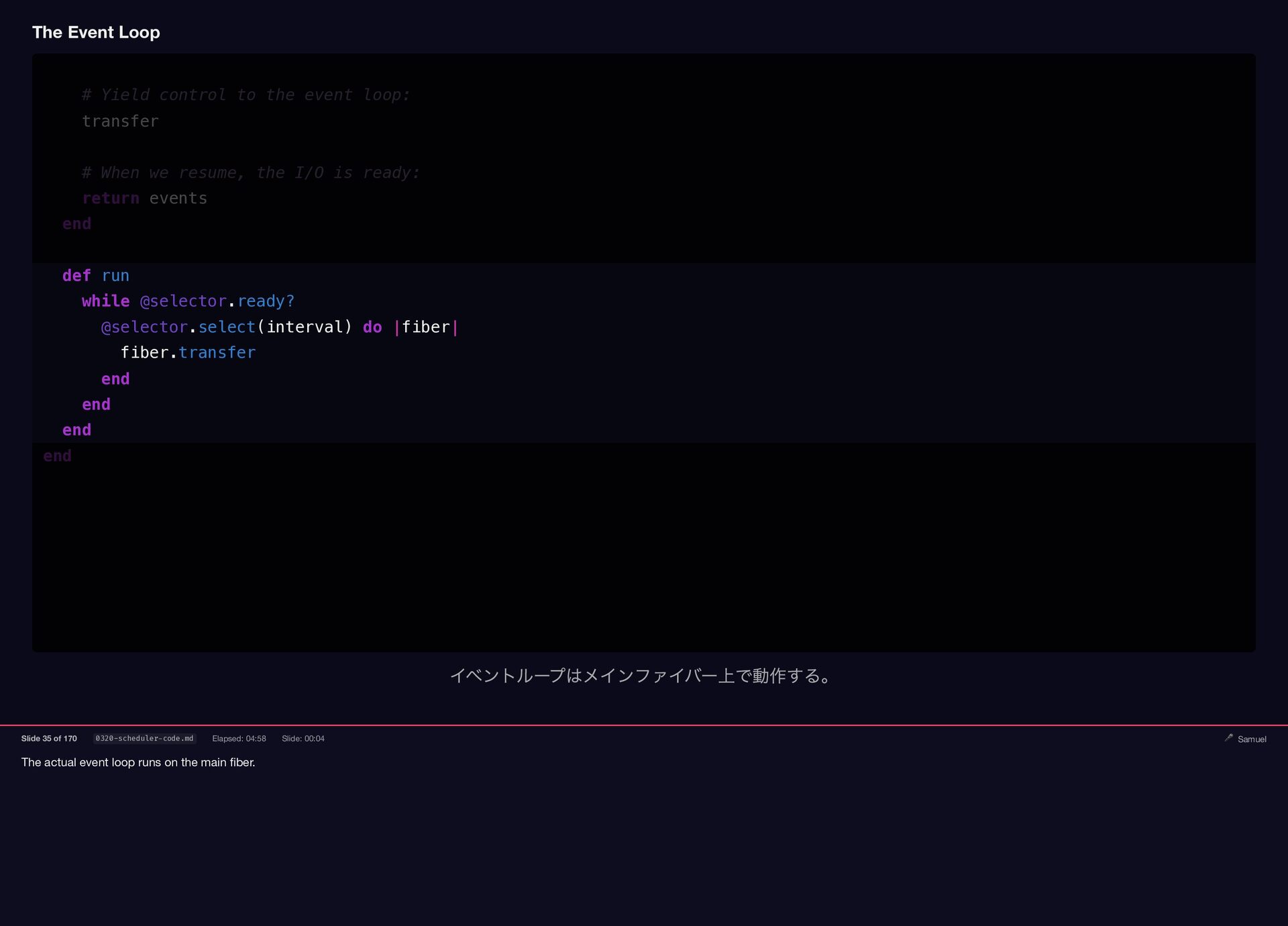
The actual event loop runs on the main fiber. The
{kind=link}
Event Loop # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end イベントループはメインファイバー上で動作する。 Slide 35 of 170 0320-scheduler-code.md Elapsed: 04:58 Slide: 00:04 🎤 Samuel
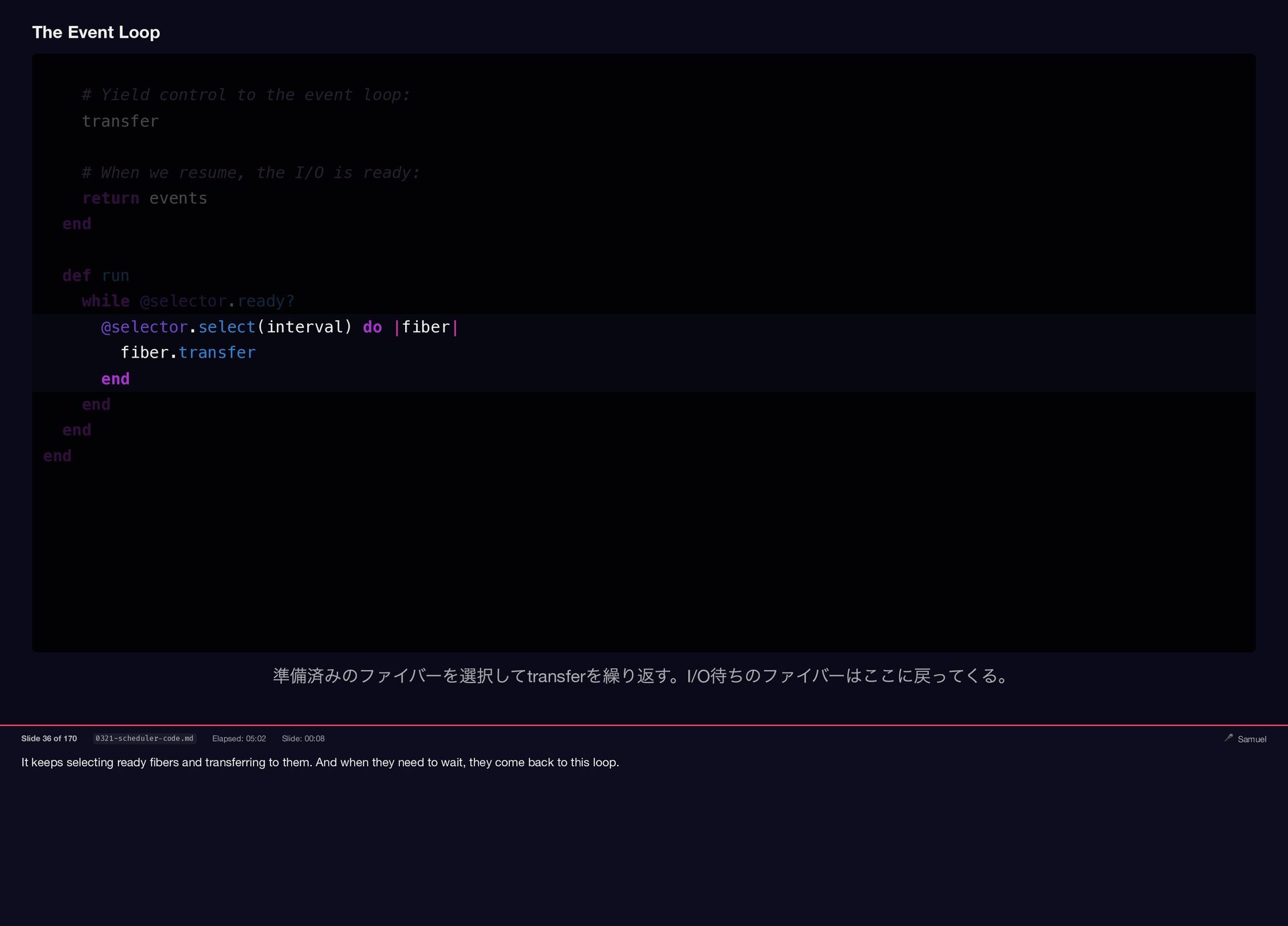
It keeps selecting ready fibers and transferring to them. And
{kind=link}
when they need to wait, they come back to this loop. The Event Loop # Yield control to the event loop: transfer # When we resume, the I/O is ready: return events end def run while @selector.ready? @selector.select(interval) do |fiber| fiber.transfer end end end end 準備済みのファイバーを選択してtransfer を繰り返す。I/O 待ちのファイバーはここに戻ってくる。 Slide 36 of 170 0321-scheduler-code.md Elapsed: 05:02 Slide: 00:08 🎤 Samuel
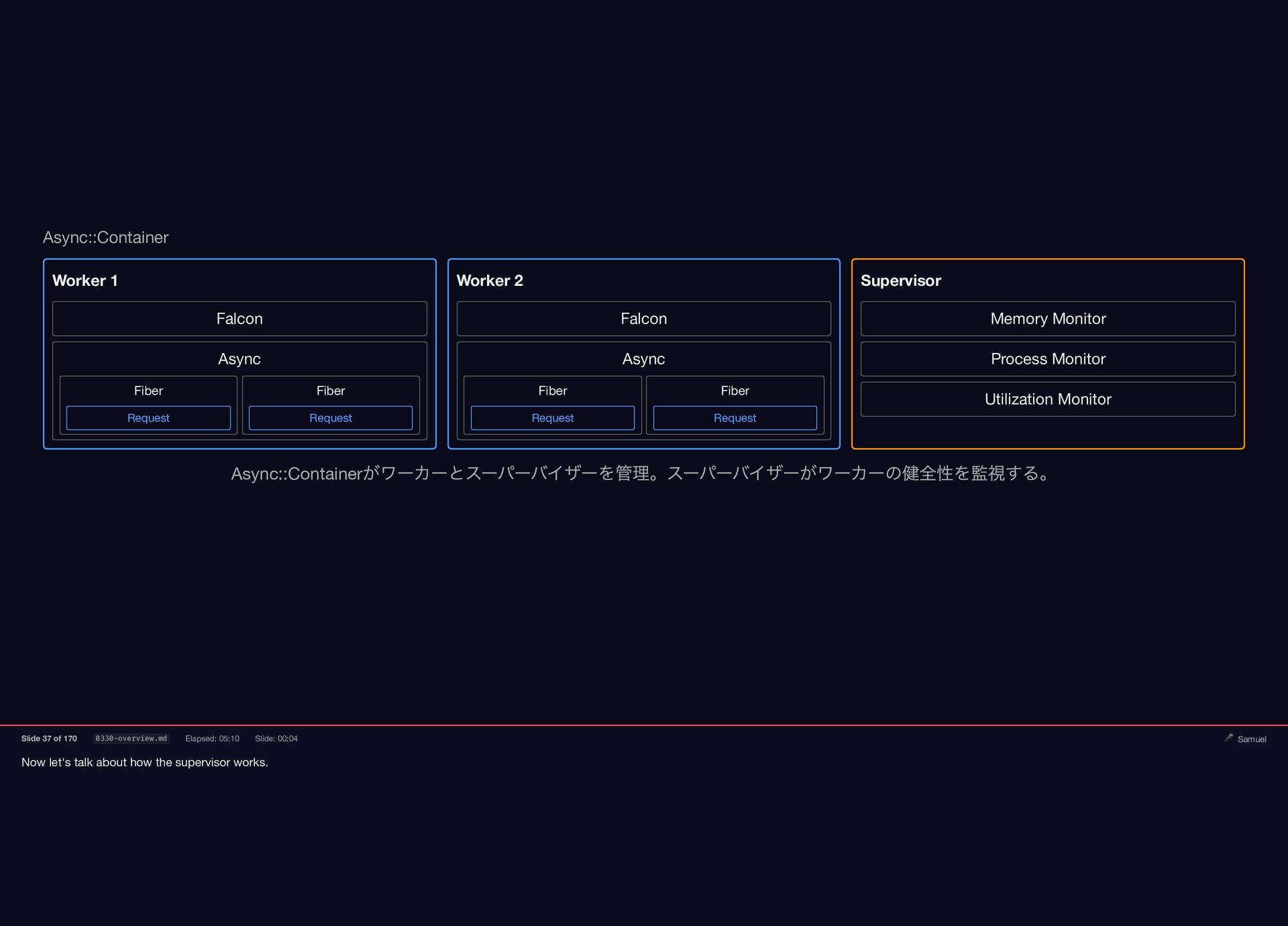
Now let's talk about how the supervisor works. Async::Container Worker
{kind=link}
1 Falcon Worker 2 Falcon Async Fiber Request Fiber Request Async Fiber Request Fiber Request Supervisor Memory Monitor Process Monitor Utilization Monitor Async::Container がワーカーとスーパーバイザーを管理。スーパーバイザーがワーカーの健全性を監視する。 Slide 37 of 170 0330-overview.md Elapsed: 05:10 Slide: 00:04 🎤 Samuel
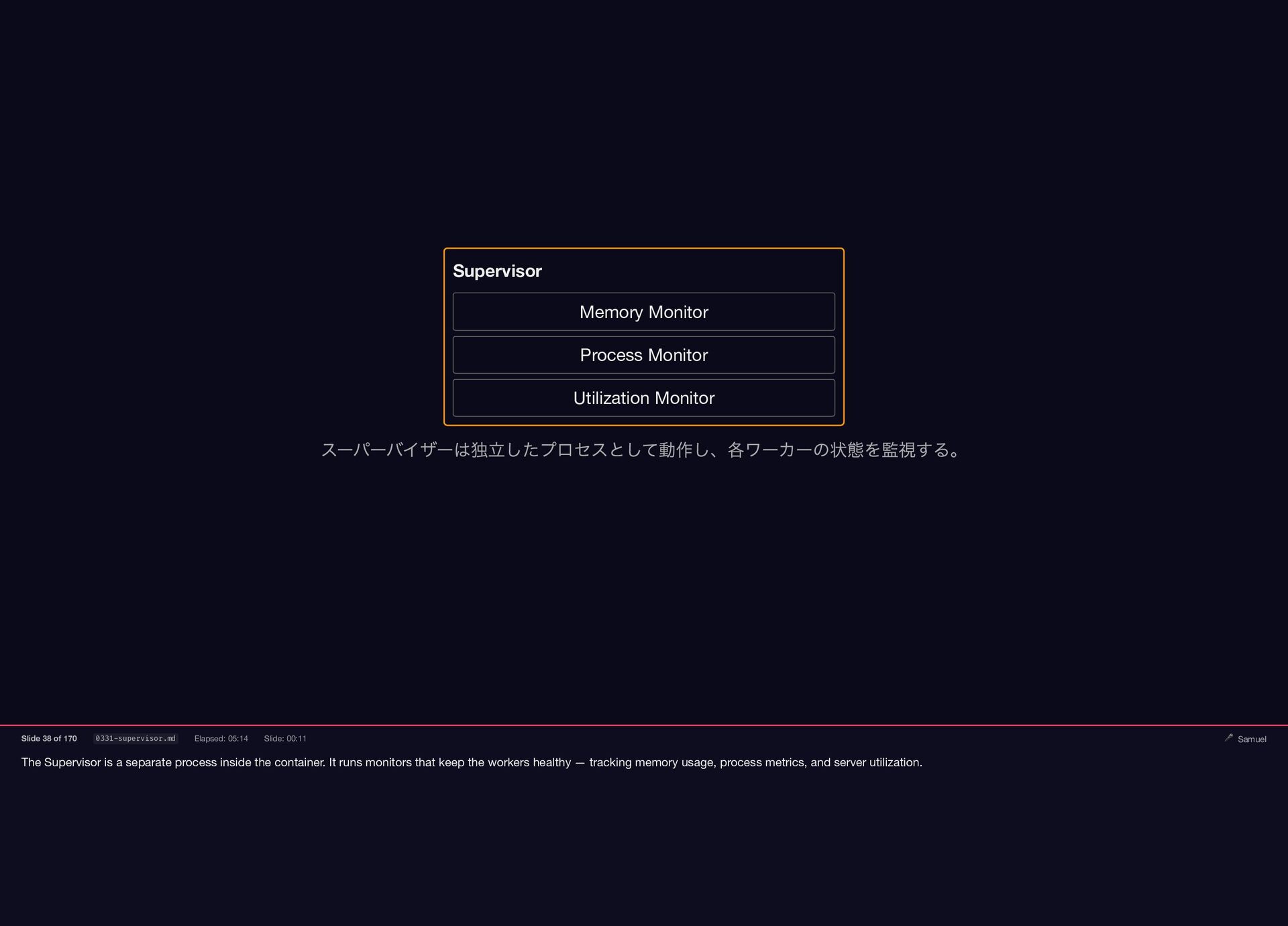
The Supervisor is a separate process inside the container. It
{kind=link}
runs monitors that keep the workers healthy — tracking memory usage, process metrics, and server utilization. Supervisor Memory Monitor Process Monitor Utilization Monitor スーパーバイザーは独立したプロセスとして動作し、各ワーカーの状態を監視する。 Slide 38 of 170 0331-supervisor.md Elapsed: 05:14 Slide: 00:11 🎤 Samuel
Every worker has a bi-directional connection to the supervisor via
{kind=link}
the async-bus gem — a transparent Ruby RPC mechanism that lets monitors execute operations directly in the context of a worker process. Workers communicate using async-bus . ワーカーは双方向チャンネルでスーパーバイザーと通信する。 Slide 39 of 170 0332-supervisor.md Elapsed: 05:25 Slide: 00:13 🎤 Samuel
The Memory Monitor is policy-driven — when a worker's memory
{kind=link}
usage crosses a threshold, it terminates the process. It supports both a maximum size limit and a minimum free size limit. The Memory Monitor terminates workers that exceed memory limits. メモリモニターはポリシーに基づき、閾値を超えたワーカープロセスを終了する。 Slide 40 of 170 0352-memory-monitor.md Elapsed: 05:38 Slide: 00:12 🎤 Samuel
The Process Monitor emits system metrics for each worker, including
{kind=link}
CPU usage, private and shared memory usage, memory map count, and so on, useful for diagnostics and debugging purposes. The Process Monitor emits system metrics for each worker (and all child processes). プロセスモニターはCPU ・メモリ使用量など、各ワーカーのシステムメトリクスを収集する。 Slide 41 of 170 0353-process-monitor.md Elapsed: 05:50 Slide: 00:12 🎤 Samuel
The Utilization Monitor reads worker utilization information from a shared
{kind=link}
memory buffer, including things like number of active connections and number of active requests. This information can be used for controlling scaling and load balancing. The Utilization Monitor reads worker utilization information. 利用率モニターはアクティブな接続数・リクエスト数など、ワーカーの利用率情報を読み取る。 Slide 42 of 170 0354-utilization-monitor.md Elapsed: 06:02 Slide: 00:15 🎤 Samuel
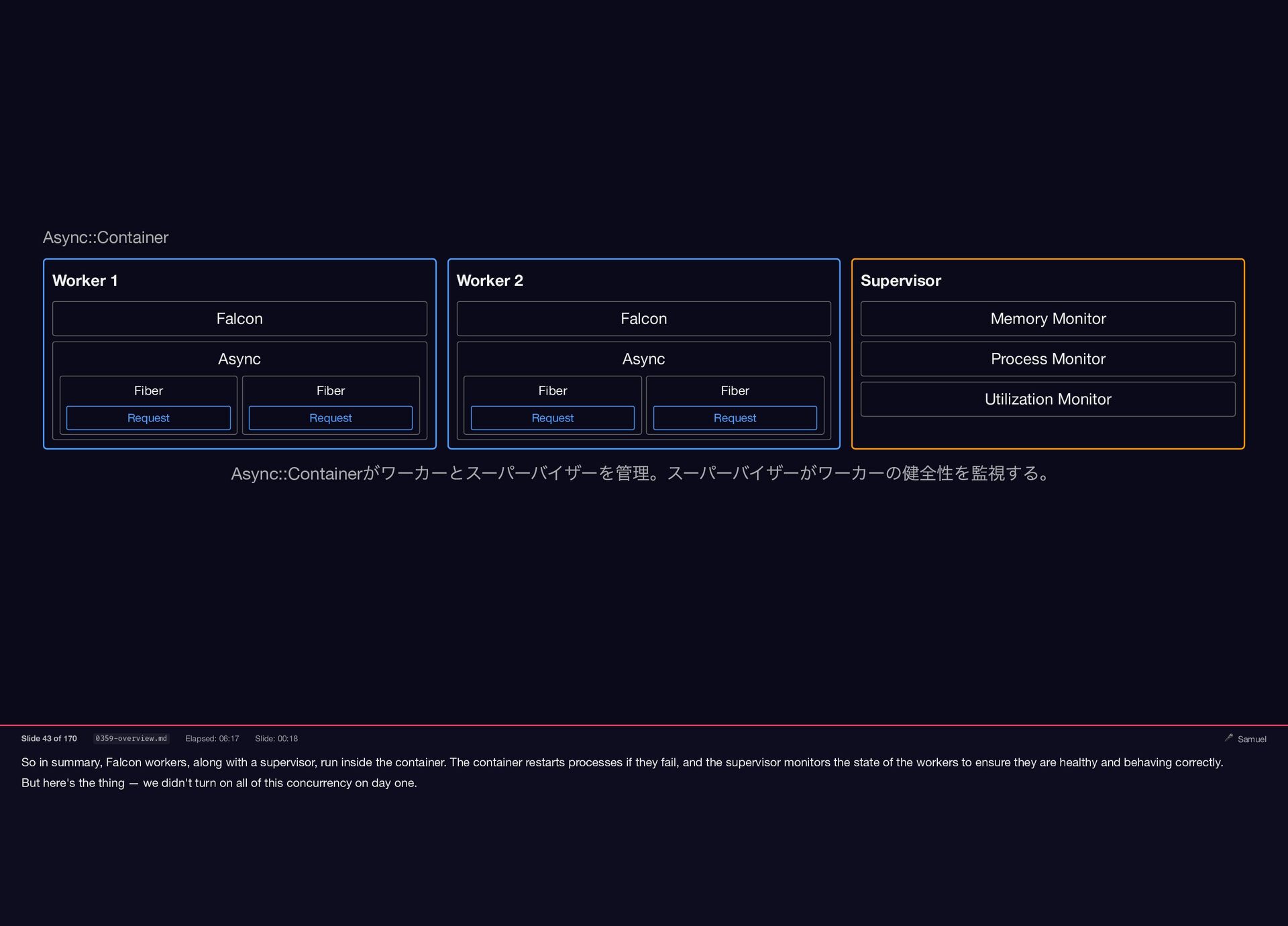
So in summary, Falcon workers, along with a supervisor, run
{kind=link}
inside the container. The container restarts processes if they fail, and the supervisor monitors the state of the workers to ensure they are healthy and behaving correctly. But here's the thing — we didn't turn on all of this concurrency on day one. Async::Container Worker 1 Falcon Worker 2 Falcon Async Fiber Request Fiber Request Supervisor Memory Monitor Process Monitor Utilization Monitor Async Fiber Request Fiber Request Async::Container がワーカーとスーパーバイザーを管理。スーパーバイザーがワーカーの健全性を監視する。 Slide 43 of 170 0359-overview.md Elapsed: 06:17 Slide: 00:18 🎤 Samuel
Handling multiple concurrent CPU bound requests can make overall latency
{kind=link}
worse, so we wanted a way to control this carefully, while still enabling I/O concurrency. CPU-bound requests don't benefit from concurrency — they fight over the CPU. CPU バウンドリクエストは並行処理の恩恵を受けない — CPU を奪い合うだけ。 Slide 45 of 170 0362-why-unicorn-mode.md Elapsed: 06:41 Slide: 00:10 🎤 Samuel
We introduced a semaphore — a permit a worker must
{kind=link}
acquire to accept a request. Before a request runs, it acquires the permit. When it finishes, it releases it. Falcon is now a drop-in replacement for Unicorn, with all the same behavioural characteristics. Same performance baseline, same operational profile. A safe starting point. We deployed Falcon in Unicorn mode first — one request per worker. 最初はUnicorn モードで展開した — ワーカーごとに1 リクエスト。 Slide 46 of 170 0364-unicorn-mode-first.md Elapsed: 06:51 Slide: 00:23 🎤 Samuel
Long Tasks is opt-in concurrency. Wrapping an I/O-bound block in
{kind=link}
a Long Task releases the semaphore too — admitting the next request — then reacquires it when the I/O is done. CPU-bound requests never release the semaphore. They run without competition. Critical CPU-bound requests stay fast. 重要なリクエストは速いまま。 Slide 47 of 170 0365-long-tasks-why.md Elapsed: 07:14 Slide: 00:18 🎤 Samuel
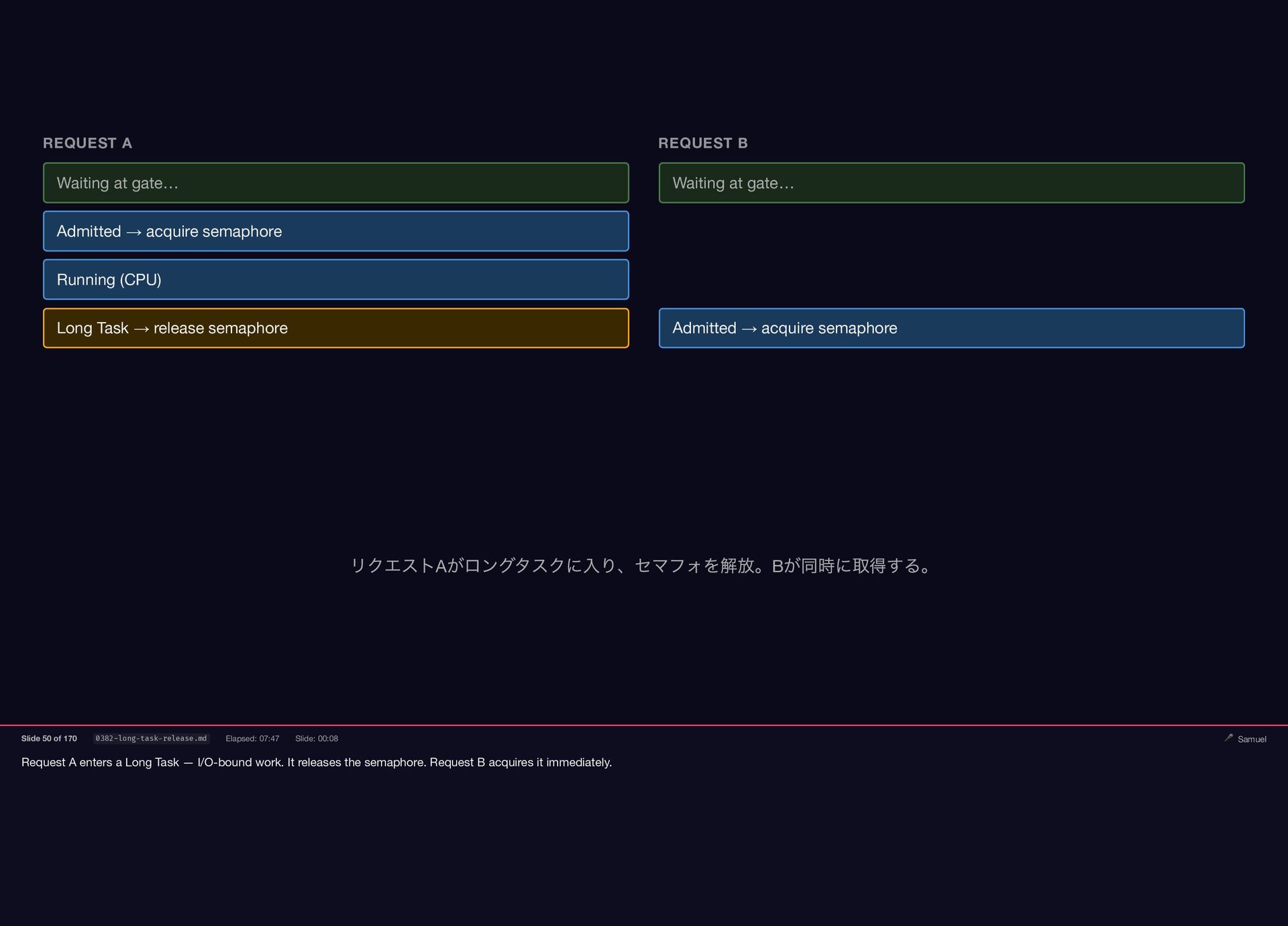
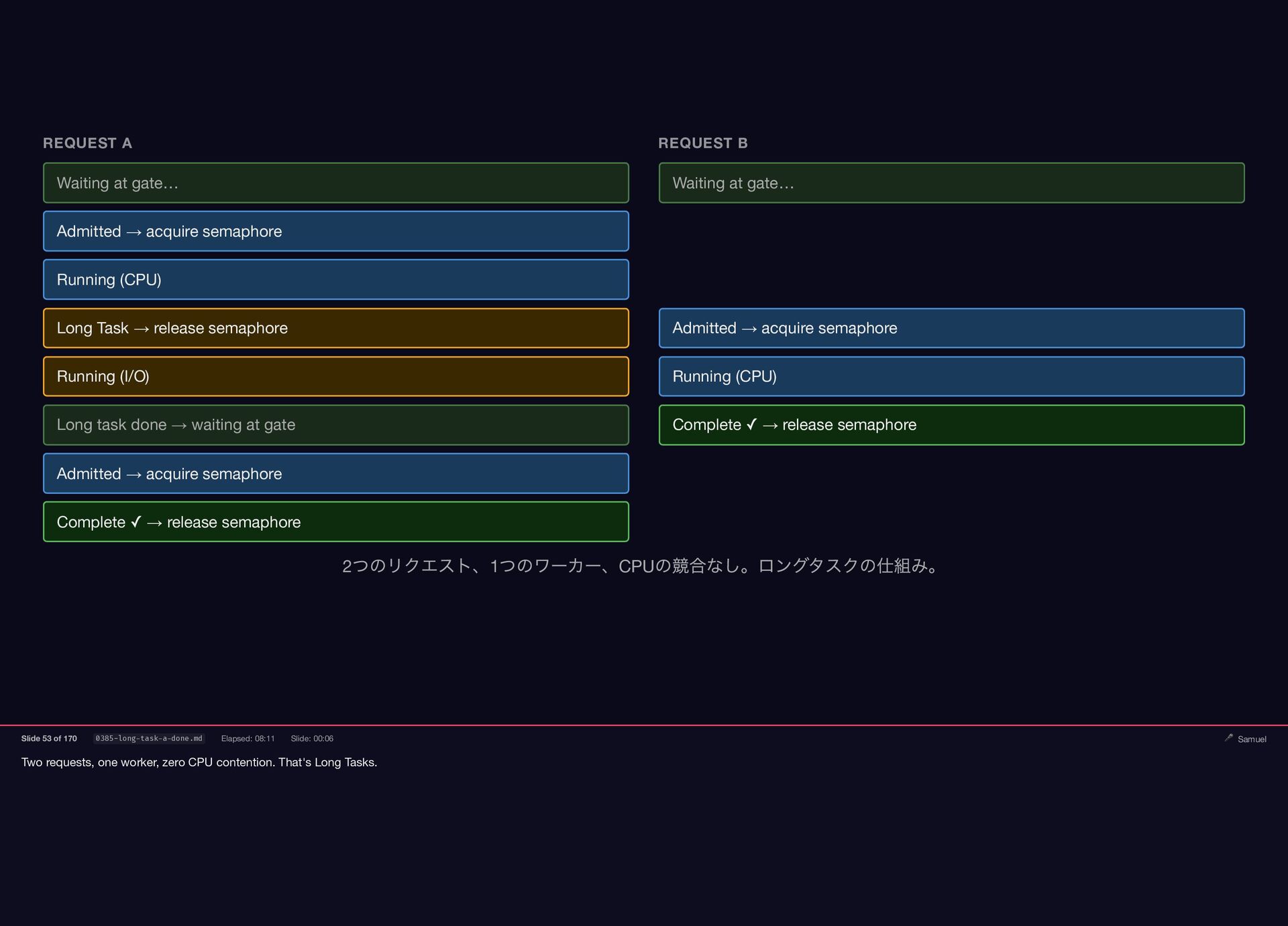
Request A enters a Long Task — I/O-bound work. It
{kind=link}
releases the semaphore. Request B acquires it immediately. REQUEST A REQUEST B Waiting at gate… Waiting at gate… Admitted → acquire semaphore Running (CPU) Long Task → release semaphore Admitted → acquire semaphore リクエストA がロングタスクに入り、セマフォを解放。B が同時に取得する。 Slide 50 of 170 0382-long-task-release.md Elapsed: 07:47 Slide: 00:08 🎤 Samuel
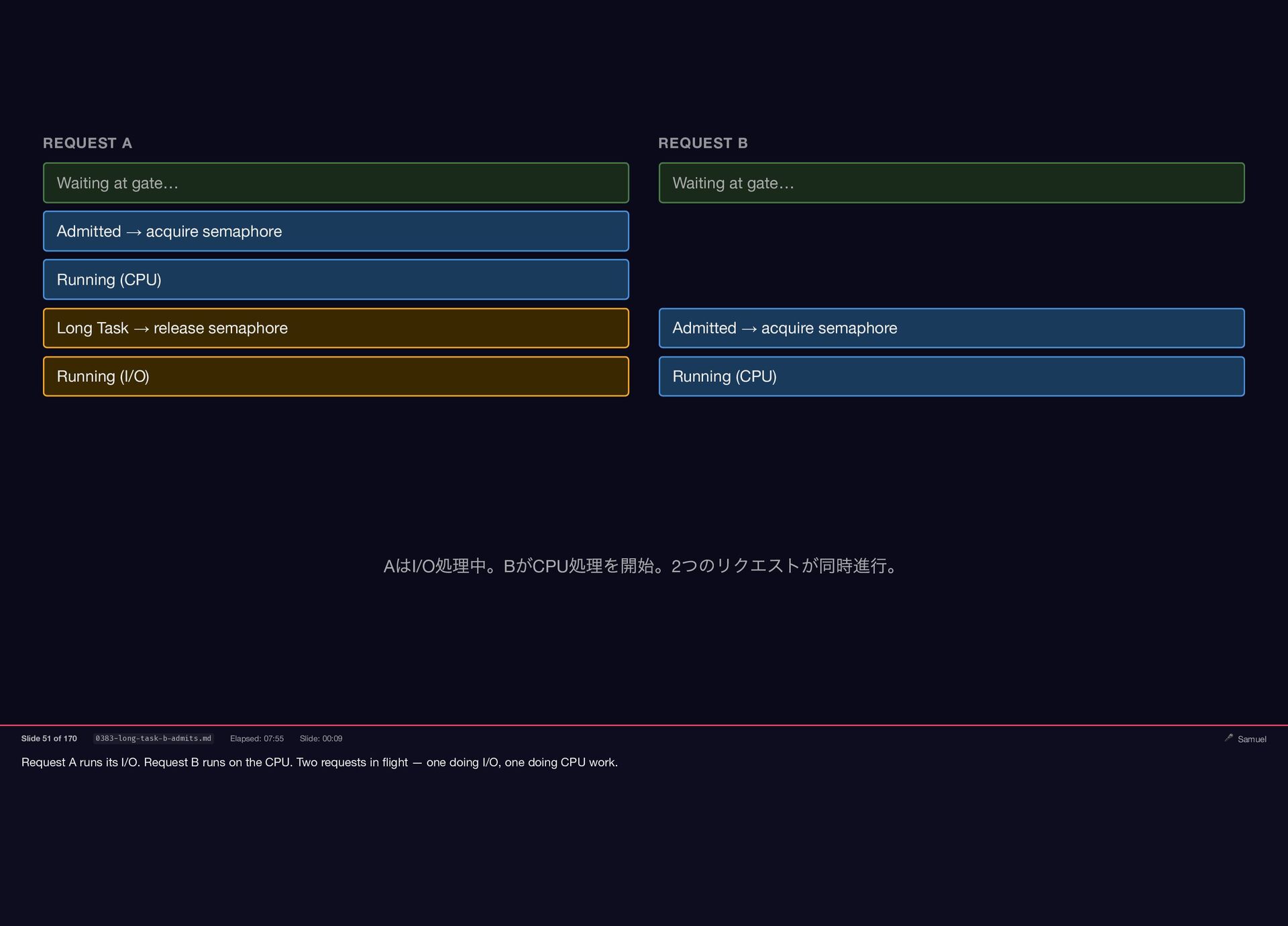
Request A runs its I/O. Request B runs on the
{kind=link}
CPU. Two requests in flight — one doing I/O, one doing CPU work. REQUEST A REQUEST B Waiting at gate… Waiting at gate… Admitted → acquire semaphore Running (CPU) Long Task → release semaphore Admitted → acquire semaphore Running (I/O) Running (CPU) A はI/O 処理中。B がCPU 処理を開始。2 つのリクエストが同時進行。 Slide 51 of 170 0383-long-task-b-admits.md Elapsed: 07:55 Slide: 00:09 🎤 Samuel
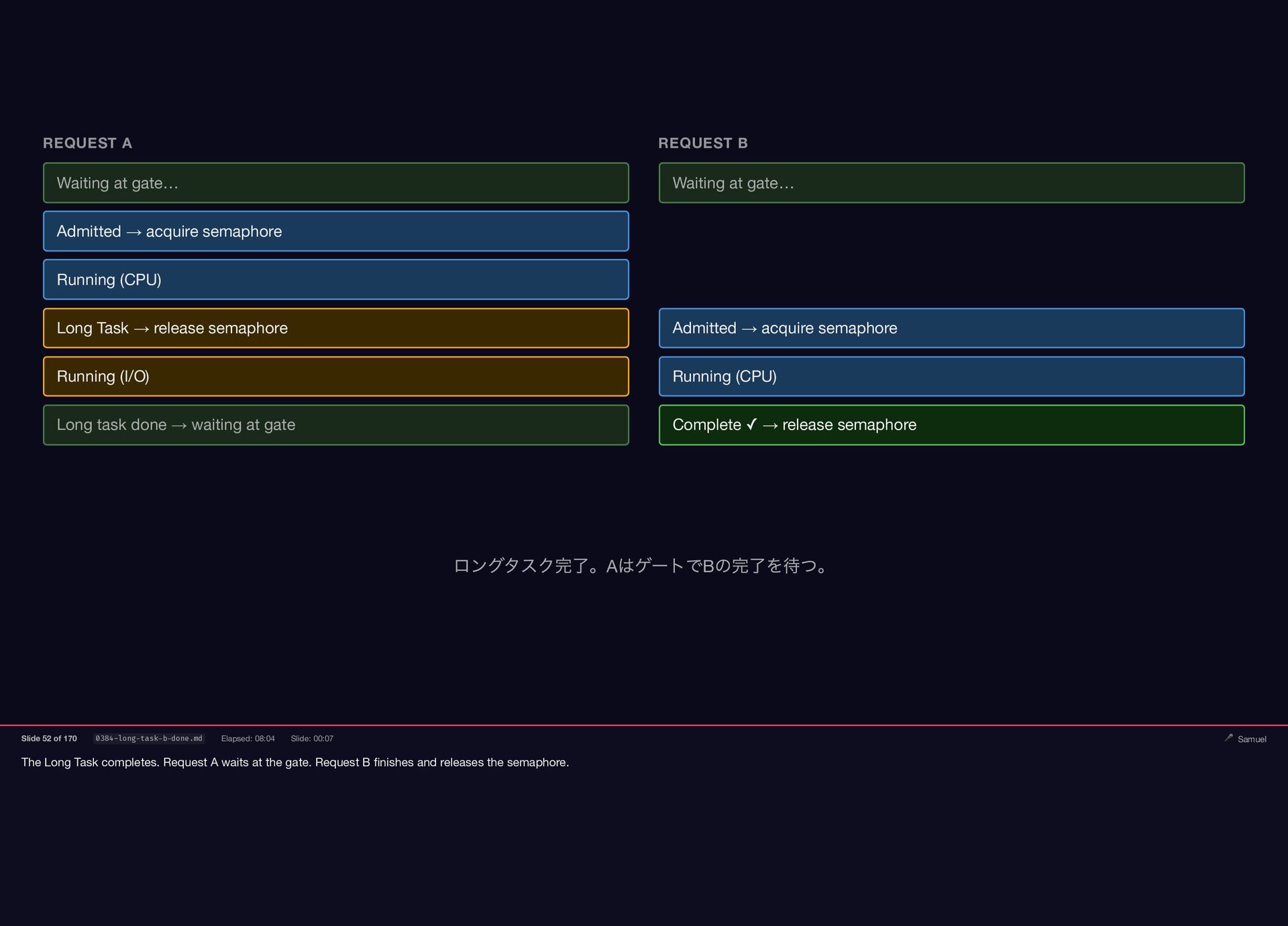
The Long Task completes. Request A waits at the gate.
{kind=link}
Request B finishes and releases the semaphore. REQUEST A REQUEST B Waiting at gate… Waiting at gate… Admitted → acquire semaphore Running (CPU) Long Task → release semaphore Admitted → acquire semaphore Running (I/O) Running (CPU) Long task done → waiting at gate Complete ✓ → release semaphore ロングタスク完了。A はゲートでB の完了を待つ。 Slide 52 of 170 0384-long-task-b-done.md Elapsed: 08:04 Slide: 00:07 🎤 Samuel
Two requests, one worker, zero CPU contention. That's Long Tasks.
{kind=link}
REQUEST A REQUEST B Waiting at gate… Waiting at gate… Admitted → acquire semaphore Running (CPU) Long Task → release semaphore Admitted → acquire semaphore Running (I/O) Running (CPU) Long task done → waiting at gate Complete ✓ → release semaphore Admitted → acquire semaphore Complete ✓ → release semaphore 2 つのリクエスト、1 つのワーカー、CPU の競合なし。ロングタスクの仕組み。 Slide 53 of 170 0385-long-task-a-done.md Elapsed: 08:11 Slide: 00:06 🎤 Samuel
But, this only works if your code is fiber-safe. We
{kind=link}
had a massive Ruby codebase with native C extensions that was never built for this kind of concurrency. But... only works if your code is fiber-safe. ファイバーセーフなコードでなければ動かない。 Slide 54 of 170 0410-fiber-safe.md Elapsed: 08:17 Slide: 00:10 🎤 Samuel
This is a key danger. A C extension that makes
{kind=link}
a blocking system call without yielding doesn't just stall one request — it stalls every concurrent request on that worker. Every fiber. The entire point of Falcon disappears. A C extension that blocks the thread blocks every fiber on that worker. スレッドをブロックするC 拡張は、そのワーカー上のすべてのファイバーをブロックする。 Slide 55 of 170 0411-not-fiber-safe.md Elapsed: 08:27 Slide: 00:15 🎤 Samuel
These aren't obscure libraries. rdkafka wraps librdkafka in C. gRPC
{kind=link}
has its own threading model. They were written for a world where the thread and the execution context are the same thing. rdkafka . gRPC . Native gems we'd depended on for years. rdkafka 。gRPC 。長年依存してきたネイティブgem 。 Slide 56 of 170 0413-native-deps.md Elapsed: 08:42 Slide: 00:15 🎤 Samuel
Some would break, we just didn't know which ones yet...
{kind=link}
let me pass over to Josh who will tell us what happened next! Some would break. We just didn't know which ones yet. いくつかは壊れる。どれかはまだわからなかった。 Slide 57 of 170 0416-about-to-find-out.md Elapsed: 08:57 Slide: 00:08 🎤 Samuel
We didn't flip a switch. You don't go from zero
{kind=link}
to one hundred on a new web server overnight just before Black Friday. We built a plan — a careful, methodical rollout designed to catch problems before they could reach merchants. The Rollout 段階的デプロイ Slide 59 of 170 0430-rollout-title.md Elapsed: 09:10 Slide: 00:12 🎤 Josh
The rollout was sequential and manually targeted. We have Canary
{kind=link}
and phases 1 through N with the final phase being production. Canary Phase 1 Phase 2 Phase 3 Phase 4 Phase 5 Phase 6 1% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 10% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 25% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 50% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 75% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 100% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 順次・手動でロールアウト。カナリアからフェーズ6 まで、各段階で1% → 10% → 25% → 50% → 75% → 100% 。 Slide 61 of 170 0450-multi-layered-rollout.md Elapsed: 09:35 Slide: 00:08 🎤 Josh
Only once canary was fully on Falcon did we start
{kind=link}
targeting parts of phase one. Then parts of phase two. And so on. At any moment only one cohort was moving and only for a fraction of its fractional traffic. Canary Phase 1 Phase 2 Phase 3 Phase 4 Phase 5 Phase 6 1% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 10% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 25% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 50% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 75% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 100% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 一度に一つのコホートだけを進める。現状が安定するまで次に進まない。 Slide 62 of 170 0451-multi-layered-rollout-1.md Elapsed: 09:43 Slide: 00:15 🎤 Josh
We didn't advance until we were sure that the current
{kind=link}
step was stable. Canary Phase 1 Phase 2 Phase 3 Phase 4 Phase 5 Phase 6 1% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 10% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 25% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 50% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 75% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 100% Falcon Falcon Falcon Falcon Falcon Falcon Falcon 一度に一つのコホートだけを進める。現状が安定するまで次に進まない。 Slide 63 of 170 0452-multi-layered-rollout-2.md Elapsed: 09:58 Slide: 00:04 🎤 Josh
And when something goes wrong: We turn the box turns
{kind=link}
red and determine if we need to rollback. It it does we can go straight back to Unicorn. Minimal impact. Canary Phase 1 Phase 2 Phase 3 Phase 4 Phase 5 Phase 6 1% 10% 25% 50% 75% 100% Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn Unicorn 問題発生時:セルが赤くなり停止。Falcon に移行した分は全てUnicorn に即戻る。一つのコマンドで。 Slide 64 of 170 0455-rollback.md Elapsed: 10:02 Slide: 00:10 🎤 Josh
These were two separate deployments, each with its own rollout.
{kind=link}
We worked through any issues with our GraphQL deployment first. The surface area is smaller and it stood to benefit the most from moving to Falcon. Two separate deployments and rollouts. GraphQL API IO wait → Template rendering CPU bound GraphQL API とテンプレートレンダリングは別々のデプロイ・ロールアウト。GraphQL を先に進める。 Slide 65 of 170 0460-sfapi-first.md Elapsed: 10:12 Slide: 00:13 🎤 Josh
Once GraphQL deployment was at 100% ands stable, we started
{kind=link}
the process over from scratch for Liquid template rendering which is the bulk of the traffic and much higher stakes. Two separate deployments and rollouts. GraphQL API IO wait → Template rendering CPU bound GraphQL が100% で安定したら、テンプレートレンダリングを最初からやり直す。 Slide 66 of 170 0461-sfapi-first.md Elapsed: 10:25 Slide: 00:11 🎤 Josh
The first scale test. Low traffic — Falcon wasn't carrying
{kind=link}
much yet. We had cautious optimism. Everything worked as expected and Marc-Andre posted to our team channel afterward: "Low numbers so far. But it's working.". The first signal that Falcon could run in production under heavy load at scale without falling apart. The first scale test. Falcon holds steady. Nothing breaks. 最初のスケールテスト。Falcon は安定。何も壊れない。 Slide 69 of 170 0480-scale1.md Elapsed: 10:47 Slide: 00:18 🎤 Josh
The first scale test. Traffic ramps, plateaus, ramps down. Unicorn
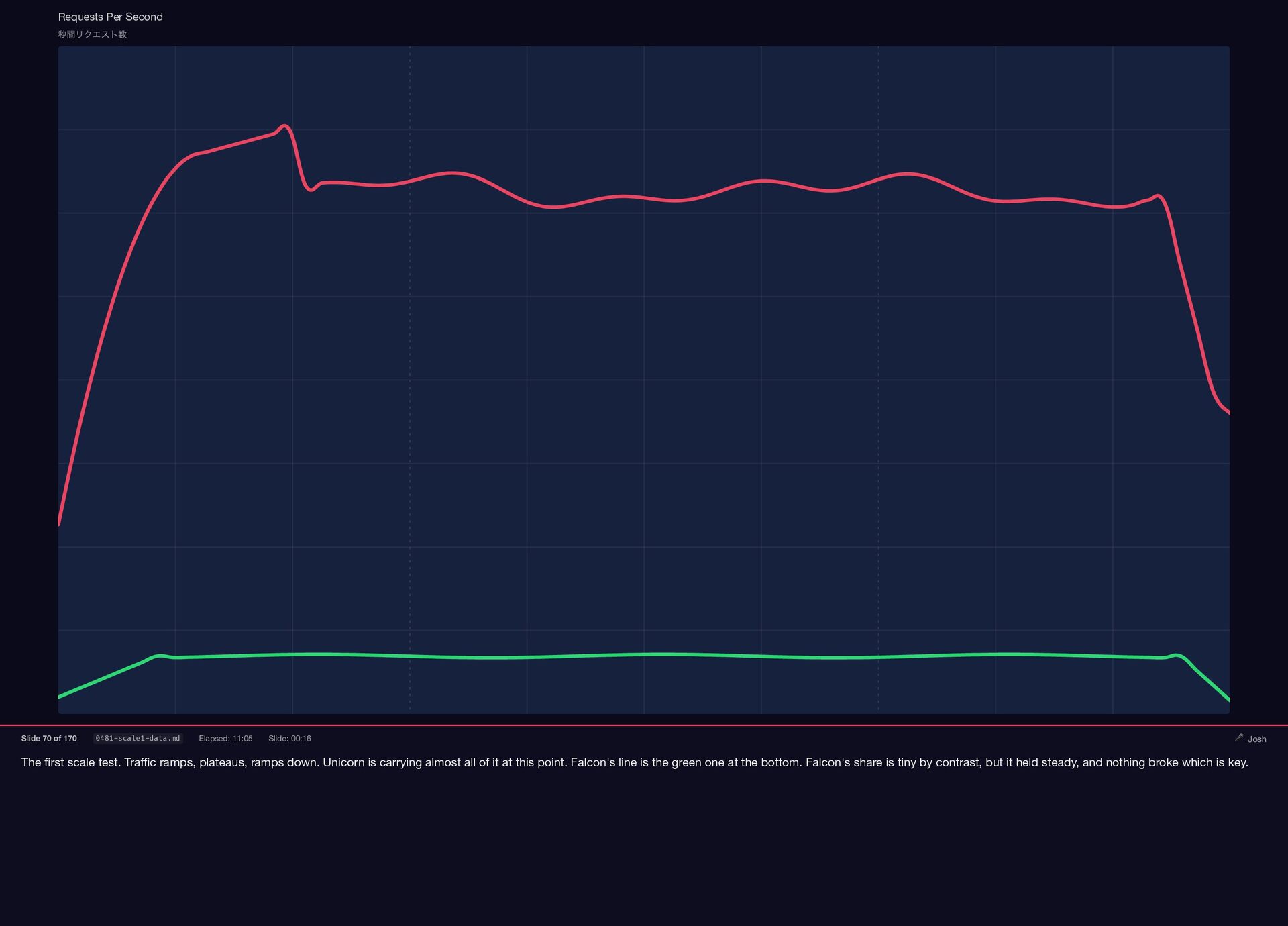{kind=link}
is carrying almost all of it at this point. Falcon's line is the green one at the bottom. Falcon's share is tiny by contrast, but it held steady, and nothing broke which is key. Requests Per Second 秒間リクエスト数 Slide 70 of 170 0481-scale1-data.md Elapsed: 11:05 Slide: 00:16 🎤 Josh
The second scale test hit with way more long tasks
{kind=link}
than April. I posted to the channel afterward: "Nothing exciting really happened." OPTIONAL: Just a week before the test, a real flash sale triggered millions of long tasks in production. External IO slowed down, Falcon absorbed it without scaling up. We didn't plan that test. We didn't need to. Falcon just did what it was built to do. The second test, more long tasks. "Nothing exciting really happened." 2 回目のテスト、ロングタスク急増。 「特に何も起こらなかった。 」 Slide 71 of 170 0490-scale2.md Elapsed: 11:21 Slide: 00:08 🎤 Josh
Second scale test. Long tasks per minute jump from the
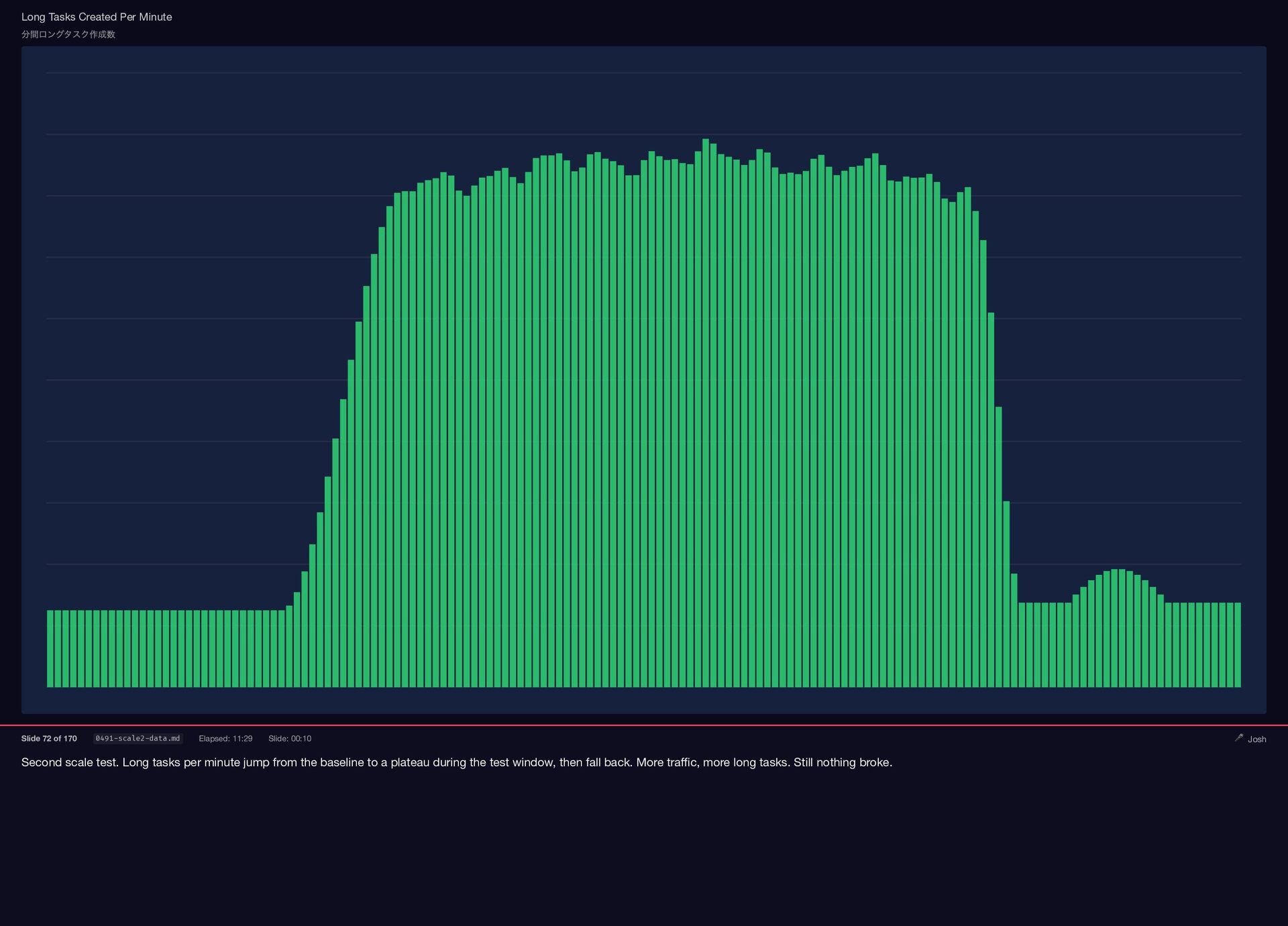{kind=link}
baseline to a plateau during the test window, then fall back. More traffic, more long tasks. Still nothing broke. Long Tasks Created Per Minute 分間ロングタスク作成数 Slide 72 of 170 0491-scale2-data.md Elapsed: 11:29 Slide: 00:10 🎤 Josh
Scale test 3. Falcon's utilization stays flat around 10% the
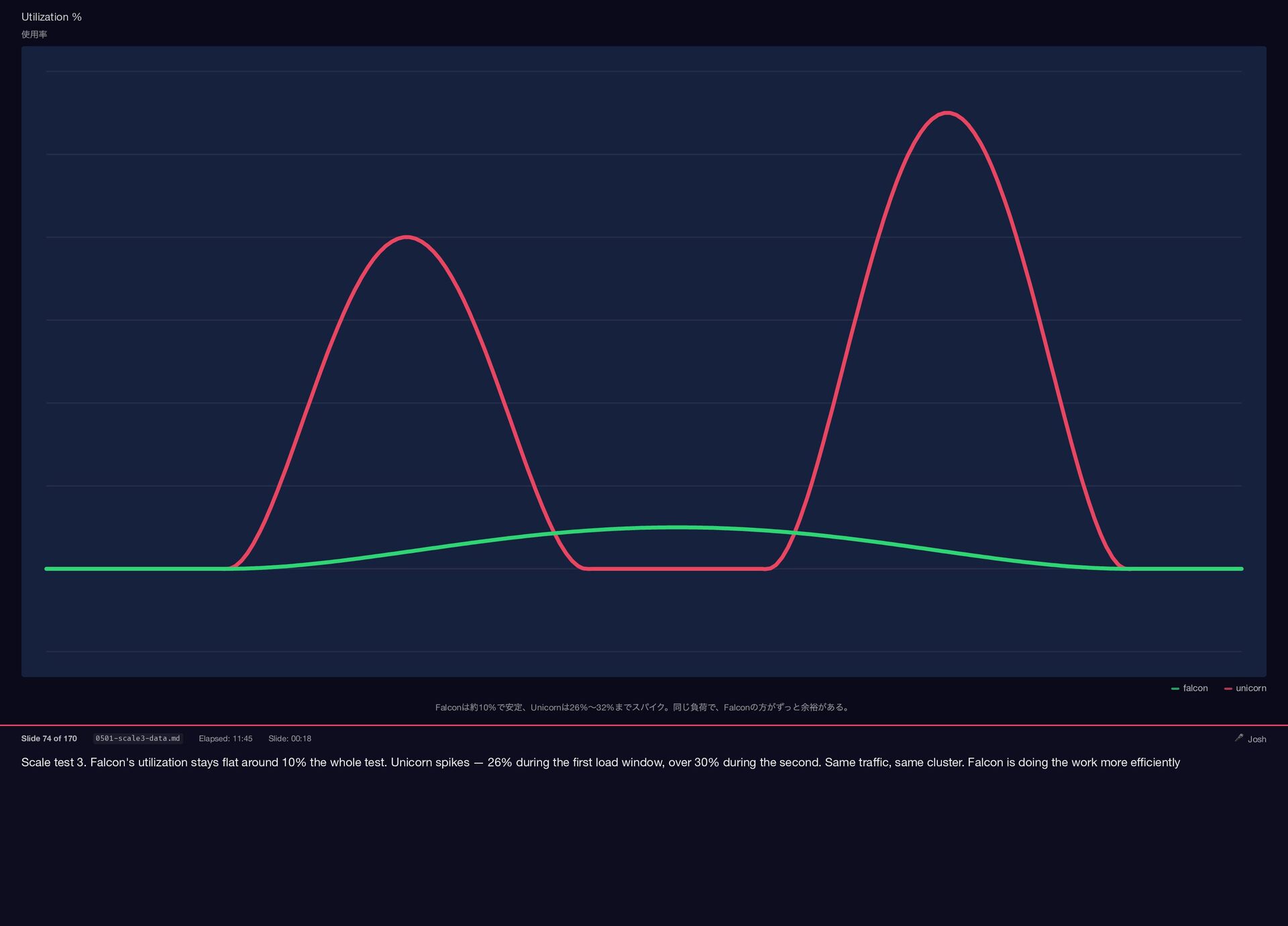{kind=link}
whole test. Unicorn spikes — 26% during the first load window, over 30% during the second. Same traffic, same cluster. Falcon is doing the work more efficiently Utilization % 使用率 falcon unicorn Falcon は約10% で安定、Unicorn は26% 〜32% までスパイク。同じ負荷で、Falcon の方がずっと余裕がある。 Slide 74 of 170 0501-scale3-data.md Elapsed: 11:45 Slide: 00:18 🎤 Josh
Tone shift. Scale test four is set to run. Three
{kind=link}
tests in, nothing catastrophic. We have no reason to expect this one to be any different. September: The Wake-Up Call 9 月:警鐘 Slide 75 of 170 0510-september-section.md Elapsed: 12:03 Slide: 00:08 🎤 Josh
The Falcon pods don't degrade. They don't slow down gracefully.
{kind=link}
They lock up. Utilization spikes to the ceiling. Load shedding kicks in. We are dropping requests on production. Falcon pods in two large regions lock up. Utilization spikes. Load shedding kicks in. 2 つの大きなリージョンでFalcon ポッドがロック。利用率がスパイク。ロードシェディング発動。 Slide 77 of 170 0540-lockup.md Elapsed: 12:18 Slide: 00:09 🎤 Josh
We dig in and we find not one problem, but
{kind=link}
three. Each one would have been bad enough on its own. We found not one problem, but three. Each one would have been bad enough on its own. 一つではなく、三つの問題を発見。どれか一つだけでも十分に深刻だった。 Slide 79 of 170 0560-three-problems.md Elapsed: 12:31 Slide: 00:06 🎤 Josh
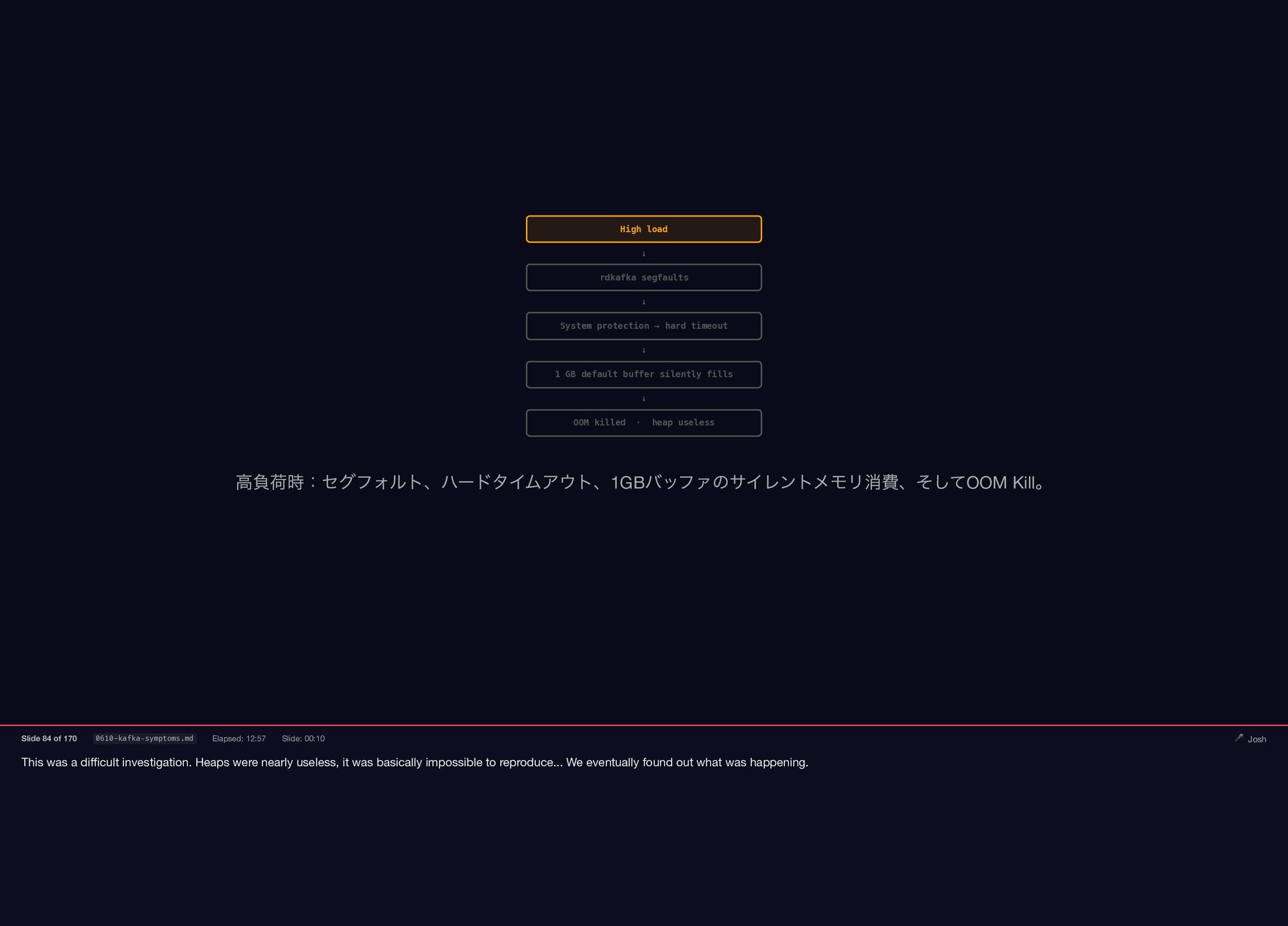
This was a difficult investigation. Heaps were nearly useless, it
{kind=link}
was basically impossible to reproduce... We eventually found out what was happening. High load ↓ rdkafka segfaults ↓ System protection → hard timeout ↓ 1 GB default buffer silently fills ↓ OOM killed · heap useless 高負荷時:セグフォルト、ハードタイムアウト、1GB バッファのサイレントメモリ消費、そしてOOM Kill 。 Slide 84 of 170 0610-kafka-symptoms.md Elapsed: 12:57 Slide: 00:10 🎤 Josh
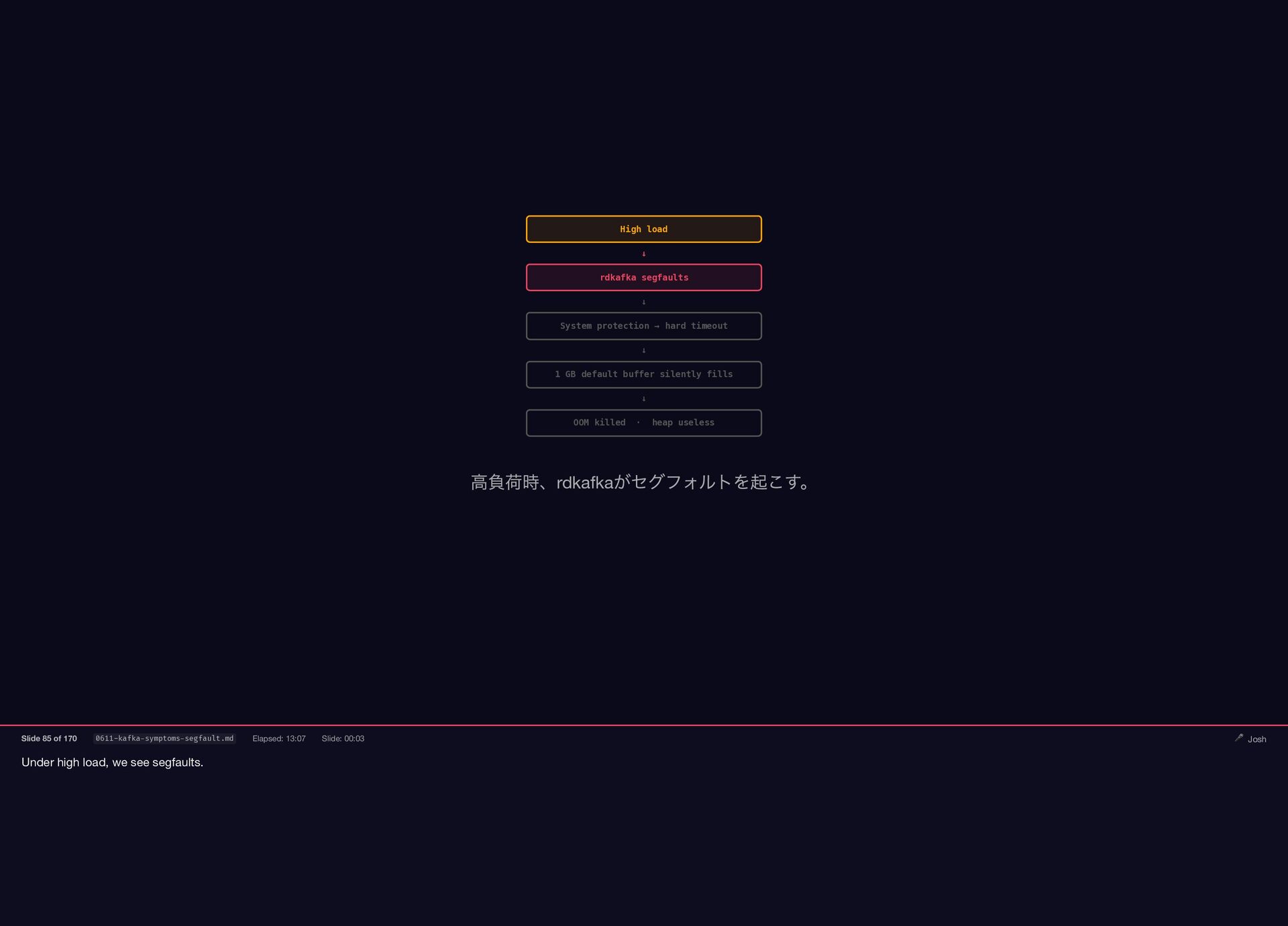
Under high load, we see segfaults. High load ↓ rdkafka
{kind=link}
segfaults ↓ System protection → hard timeout ↓ 1 GB default buffer silently fills ↓ OOM killed · heap useless 高負荷時、rdkafka がセグフォルトを起こす。 Slide 85 of 170 0611-kafka-symptoms-segfault.md Elapsed: 13:07 Slide: 00:03 🎤 Josh
Our system protection kicks in with hard timeouts where we
{kind=link}
try to exit the process. High load ↓ rdkafka segfaults ↓ System protection → hard timeout ↓ 1 GB default buffer silently fills ↓ OOM killed · heap useless システム保護機構が発動し、ハードタイムアウトでプロセス終了を試みる。 Slide 86 of 170 0612-kafka-symptoms-timeout.md Elapsed: 13:10 Slide: 00:05 🎤 Josh
A one gigabyte default buffer that silently eats memory until
{kind=link}
things start to corrupt. High load ↓ rdkafka segfaults ↓ System protection → hard timeout ↓ 1 GB default buffer silently fills ↓ OOM killed · heap useless デフォルト1GB のバッファが、気付かれないままメモリを食い潰していく。 Slide 87 of 170 0613-kafka-symptoms-buffer.md Elapsed: 13:15 Slide: 00:06 🎤 Josh
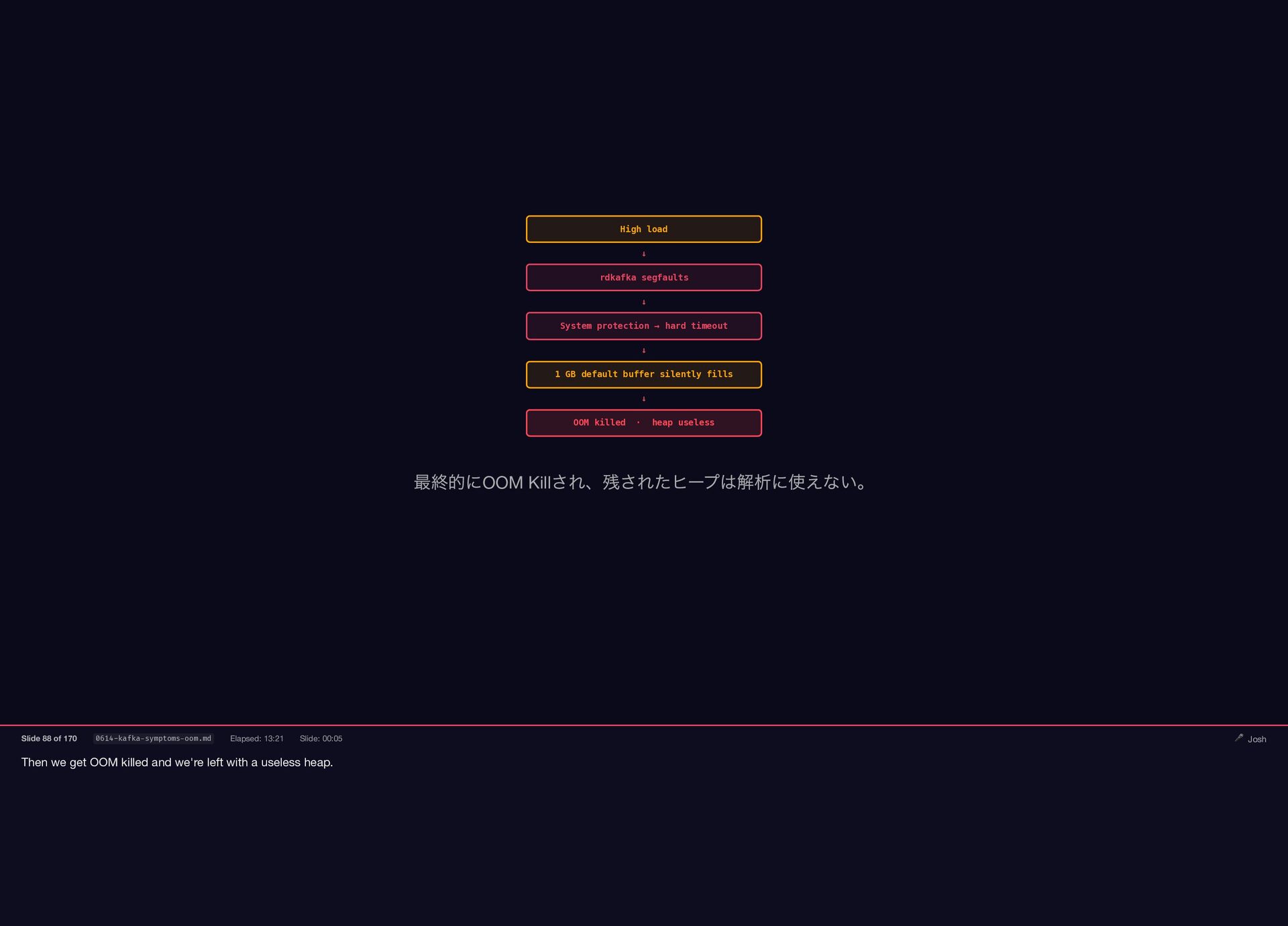
Then we get OOM killed and we're left with a
{kind=link}
useless heap. High load ↓ rdkafka segfaults ↓ System protection → hard timeout ↓ 1 GB default buffer silently fills ↓ OOM killed · heap useless 最終的にOOM Kill され、残されたヒープは解析に使えない。 Slide 88 of 170 0614-kafka-symptoms-oom.md Elapsed: 13:21 Slide: 00:05 🎤 Josh
Spanner is Google's distributed database — we use it for
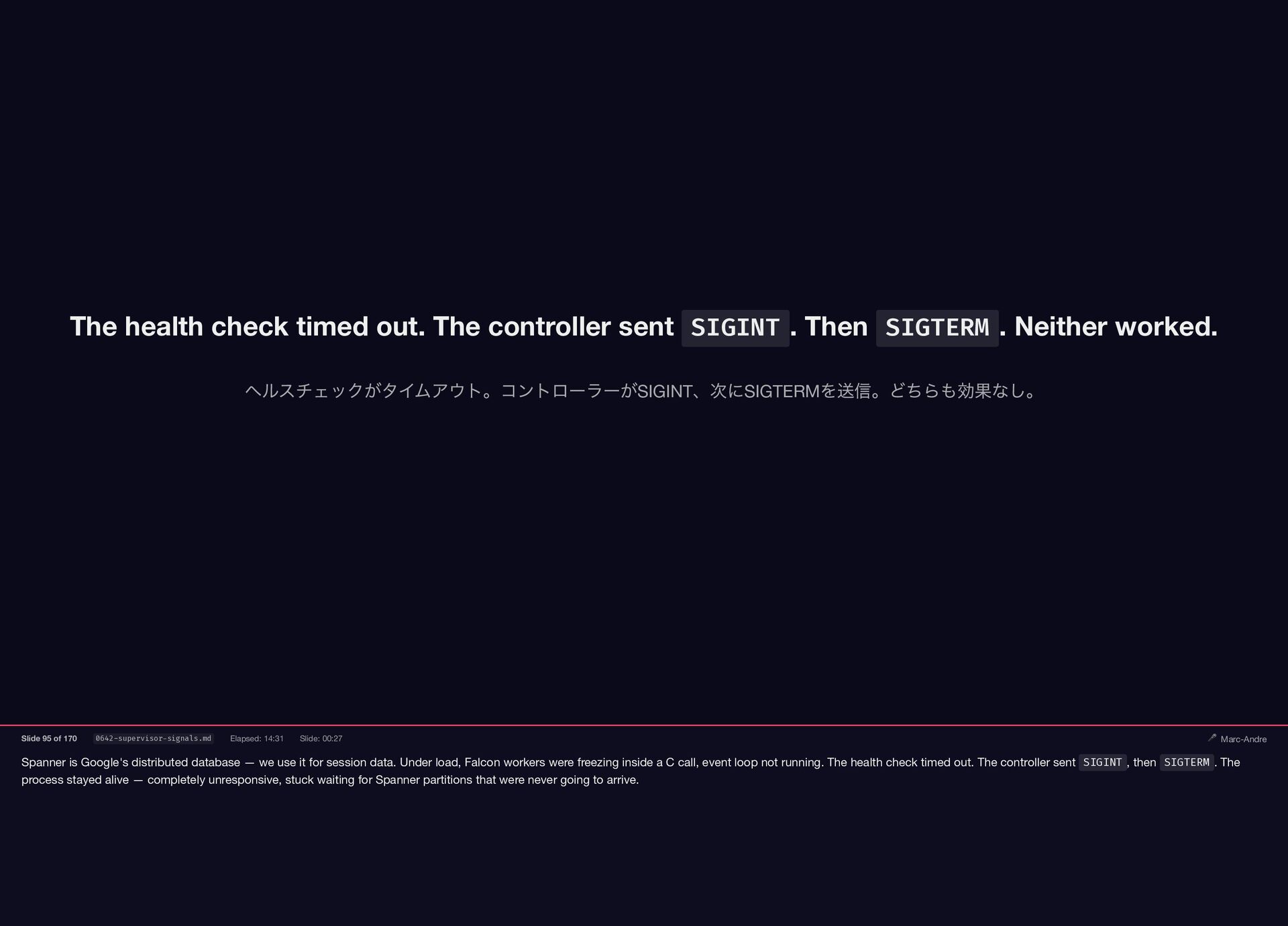{kind=link}
session data. Under load, Falcon workers were freezing inside a C call, event loop not running. The health check timed out. The controller sent SIGINT , then SIGTERM . The process stayed alive — completely unresponsive, stuck waiting for Spanner partitions that were never going to arrive. The health check timed out. The controller sent SIGINT . Then SIGTERM . Neither worked. ヘルスチェックがタイムアウト。コントローラーがSIGINT 、次にSIGTERM を送信。どちらも効果なし。 Slide 95 of 170 0642-supervisor-signals.md Elapsed: 14:31 Slide: 00:27 🎤 Marc-Andre
Here is Async's event loop run_loop ... Async Scheduler —
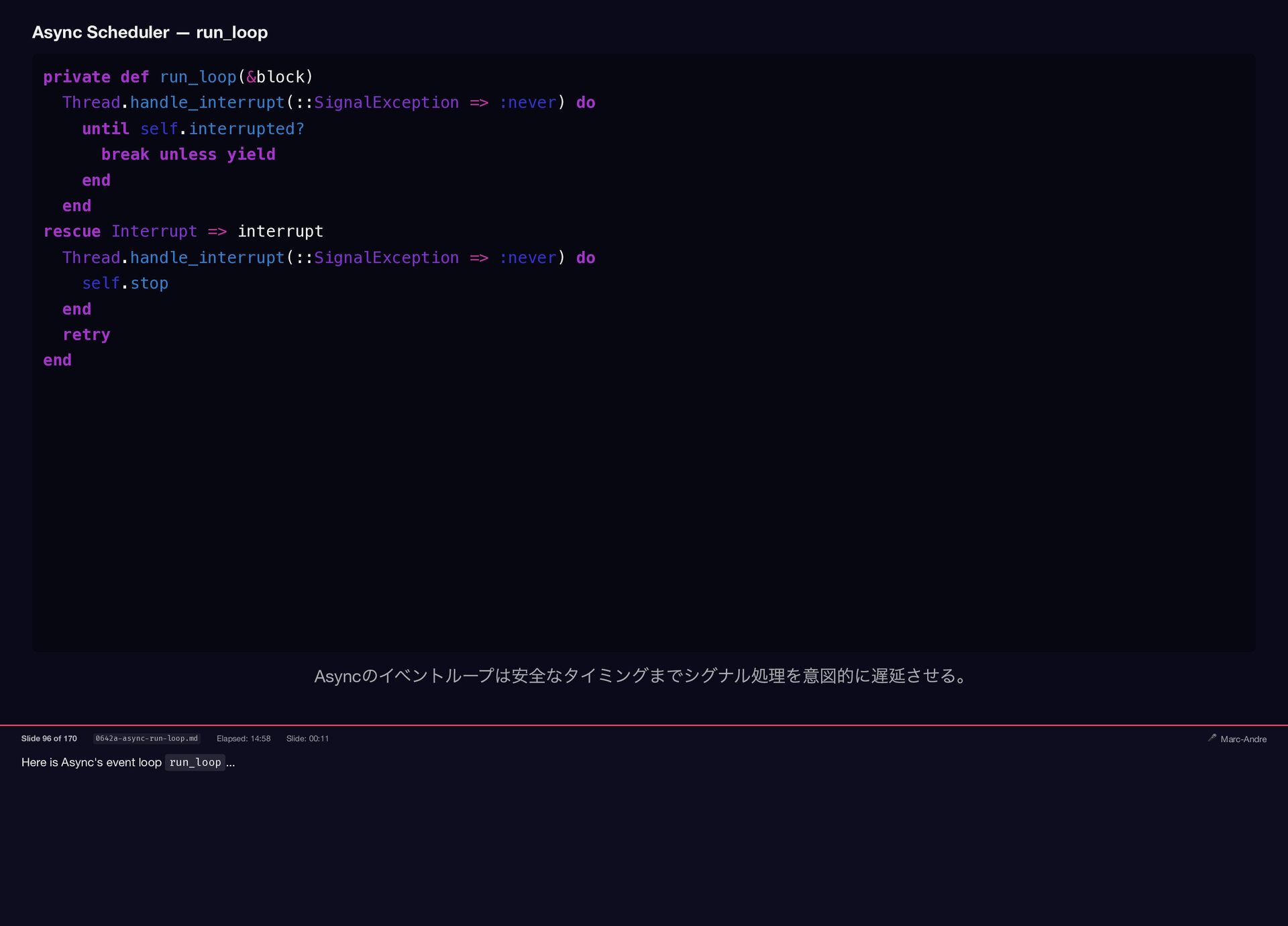{kind=link}
run_loop private def run_loop(&block) Thread.handle_interrupt(::SignalException => :never) do until self.interrupted? break unless yield end end rescue Interrupt => interrupt Thread.handle_interrupt(::SignalException => :never) do self.stop end retry end Async のイベントループは安全なタイミングまでシグナル処理を意図的に遅延させる。 Slide 96 of 170 0642a-async-run-loop.md Elapsed: 14:58 Slide: 00:11 🎤 Marc-Andre
...it deliberately defers signal handling until it's safe to do
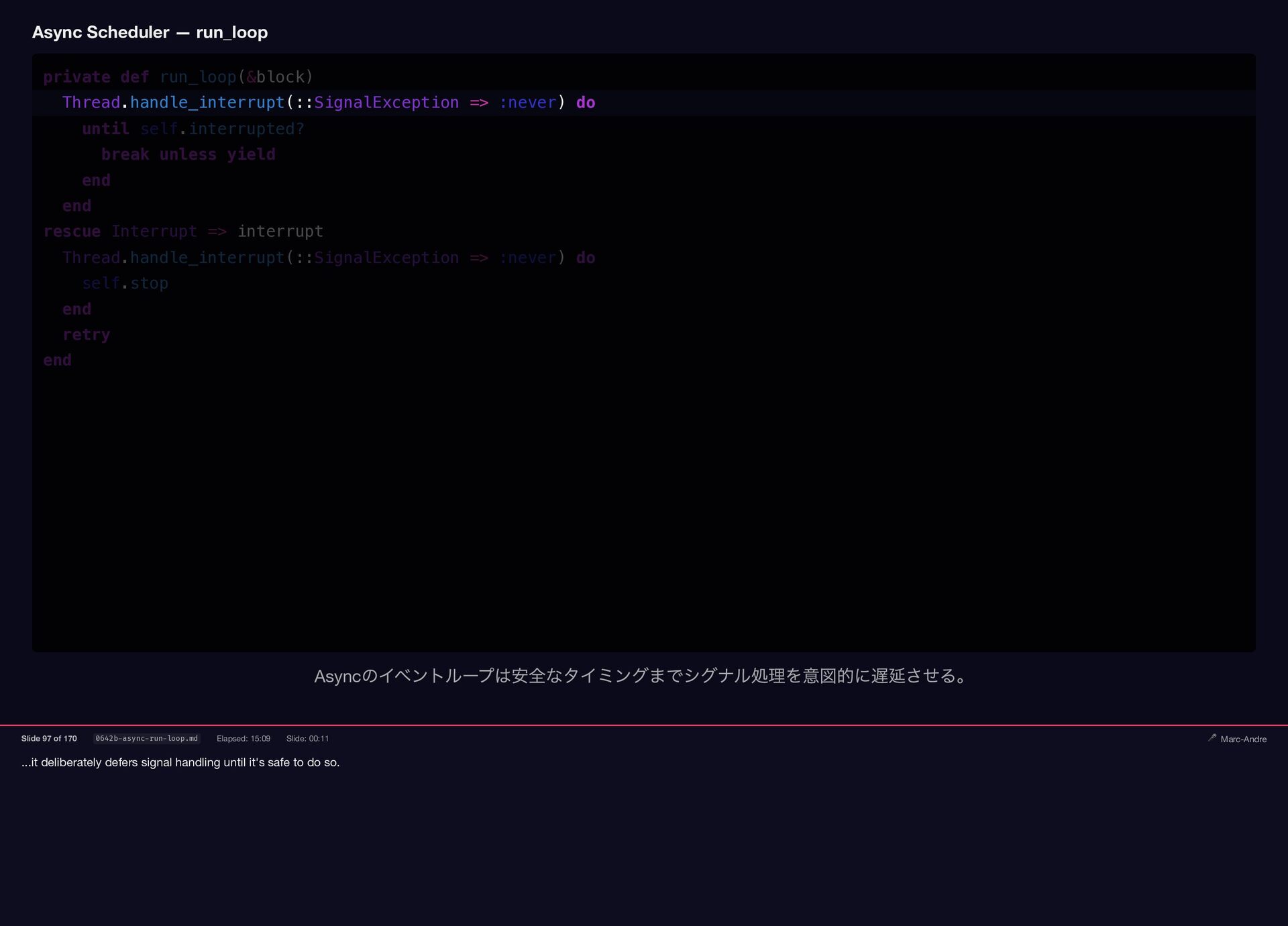{kind=link}
so. Async Scheduler — run_loop private def run_loop(&block) Thread.handle_interrupt(::SignalException => :never) do until self.interrupted? break unless yield end end rescue Interrupt => interrupt Thread.handle_interrupt(::SignalException => :never) do self.stop end retry end Async のイベントループは安全なタイミングまでシグナル処理を意図的に遅延させる。 Slide 97 of 170 0642b-async-run-loop.md Elapsed: 15:09 Slide: 00:11 🎤 Marc-Andre
Here is gRPC's blocking operation loop, used by Spanner. The
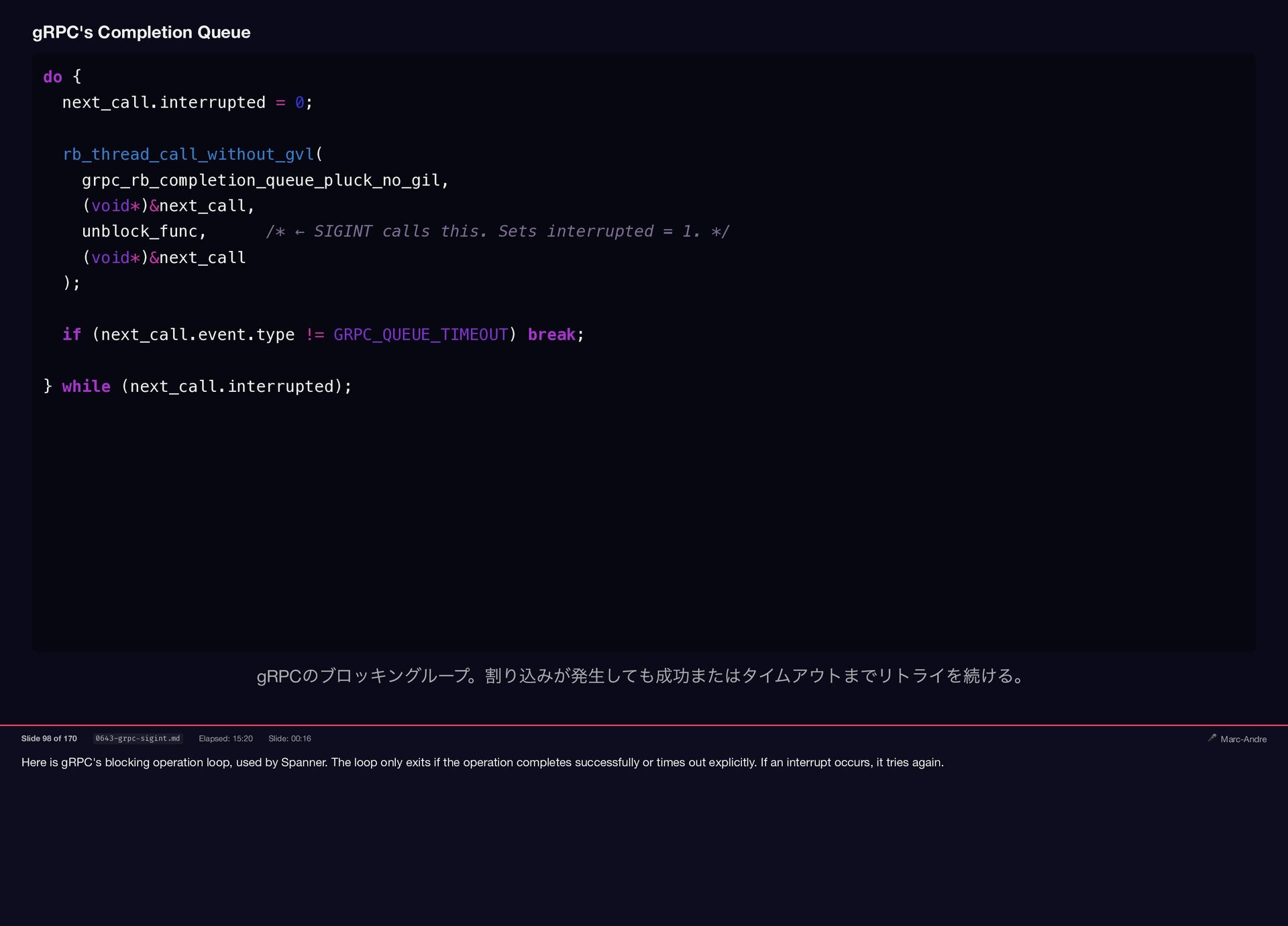{kind=link}
loop only exits if the operation completes successfully or times out explicitly. If an interrupt occurs, it tries again. gRPC's Completion Queue do { next_call.interrupted = 0; rb_thread_call_without_gvl( grpc_rb_completion_queue_pluck_no_gil, (void*)&next_call, unblock_func, /* ← SIGINT calls this. Sets interrupted = 1. */ (void*)&next_call ); if (next_call.event.type != GRPC_QUEUE_TIMEOUT) break; } while (next_call.interrupted); gRPC のブロッキングループ。割り込みが発生しても成功またはタイムアウトまでリトライを続ける。 Slide 98 of 170 0643-grpc-sigint.md Elapsed: 15:20 Slide: 00:16 🎤 Marc-Andre
Now normally, rb_thread_call_without_gvl checks Ruby's internal pending interrupts and can
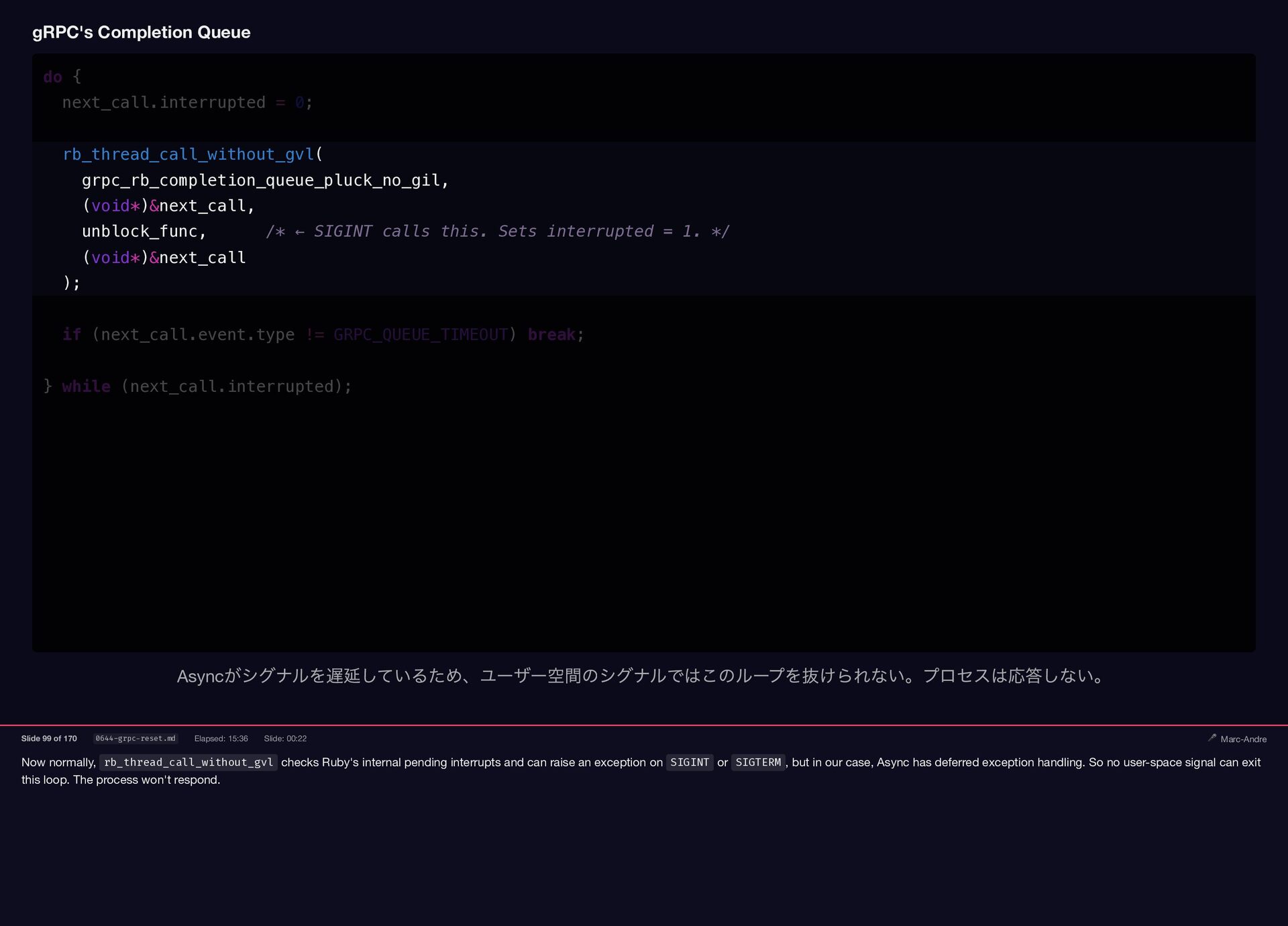{kind=link}
raise an exception on SIGINT or SIGTERM , but in our case, Async has deferred exception handling. So no user-space signal can exit this loop. The process won't respond. gRPC's Completion Queue do { next_call.interrupted = 0; rb_thread_call_without_gvl( grpc_rb_completion_queue_pluck_no_gil, (void*)&next_call, unblock_func, /* ← SIGINT calls this. Sets interrupted = 1. */ (void*)&next_call ); if (next_call.event.type != GRPC_QUEUE_TIMEOUT) break; } while (next_call.interrupted); Async がシグナルを遅延しているため、ユーザー空間のシグナルではこのループを抜けられない。プロセスは応答しない。 Slide 99 of 170 0644-grpc-reset.md Elapsed: 15:36 Slide: 00:22 🎤 Marc-Andre
We updated async-container to use SIGKILL as a final resort.
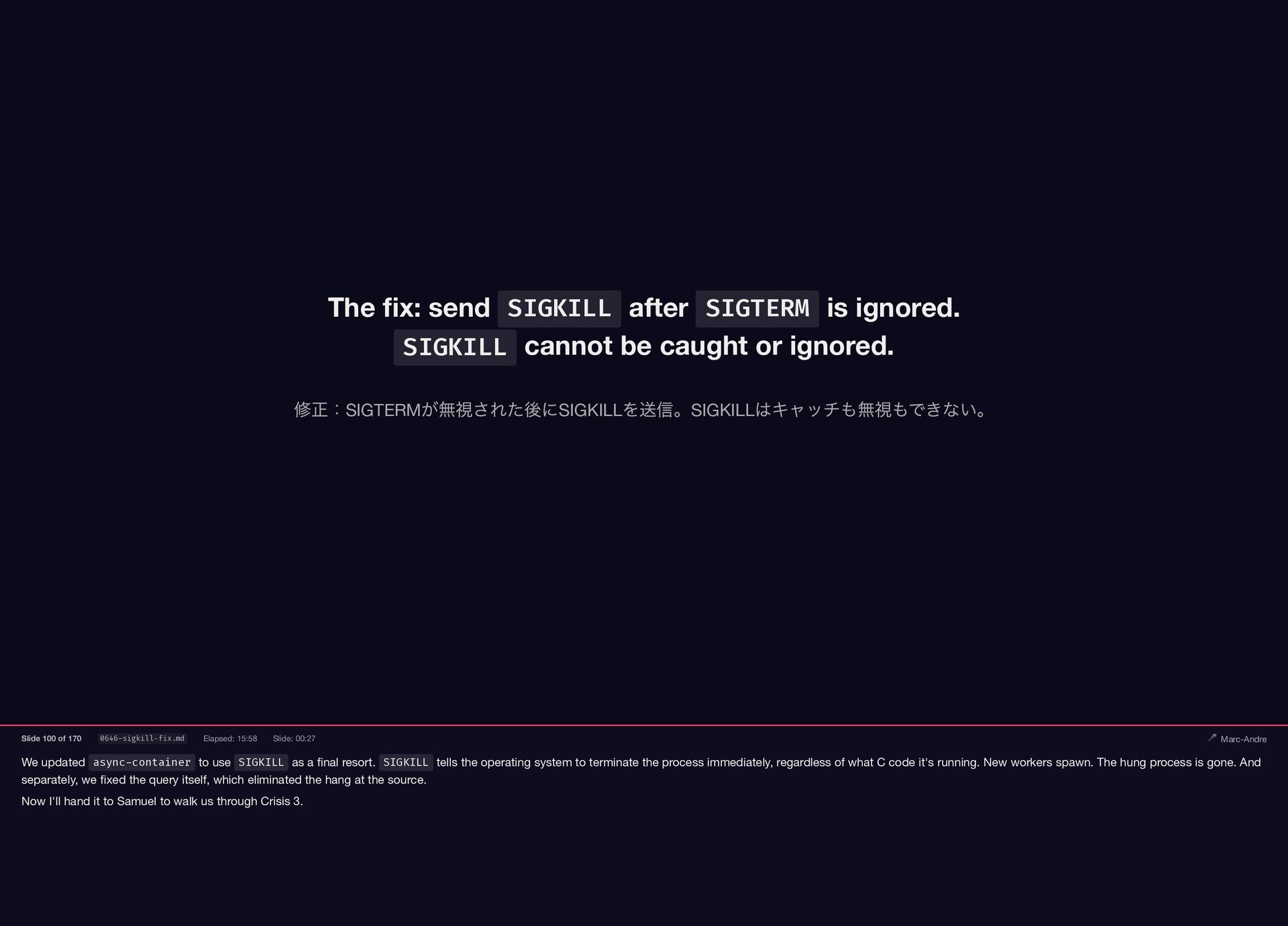{kind=link}
SIGKILL tells the operating system to terminate the process immediately, regardless of what C code it's running. New workers spawn. The hung process is gone. And separately, we fixed the query itself, which eliminated the hang at the source. Now I'll hand it to Samuel to walk us through Crisis 3. The fix: send SIGKILL after SIGTERM is ignored. SIGKILL cannot be caught or ignored. 修正:SIGTERM が無視された後にSIGKILL を送信。SIGKILL はキャッチも無視もできない。 Slide 100 of 170 0646-sigkill-fix.md Elapsed: 15:58 Slide: 00:27 🎤 Marc-Andre
And no alerts fire. There's no alarm. Just a slow,
{kind=link}
silent degradation until the pod can't handle any more traffic and starts failing every request. No alerts. Just a slow, silent degradation. アラートなし。静かな劣化だけ。 Slide 106 of 170 0730-no-alerts.md Elapsed: 17:00 Slide: 00:09 🎤 Samuel
We found the root cause: A write wasn't atomic —
{kind=link}
SIGINT could land between the data and the newline. The newline never arrives. The controller hangs forever. Let me show you the code. Root cause: a torn pipe write in async-container . 根本原因: async-container のパイプ書き込みの分断。 Slide 107 of 170 0740-root-cause.md Elapsed: 17:09 Slide: 00:15 🎤 Samuel
Workers communicate with the controller through a notification pipe —
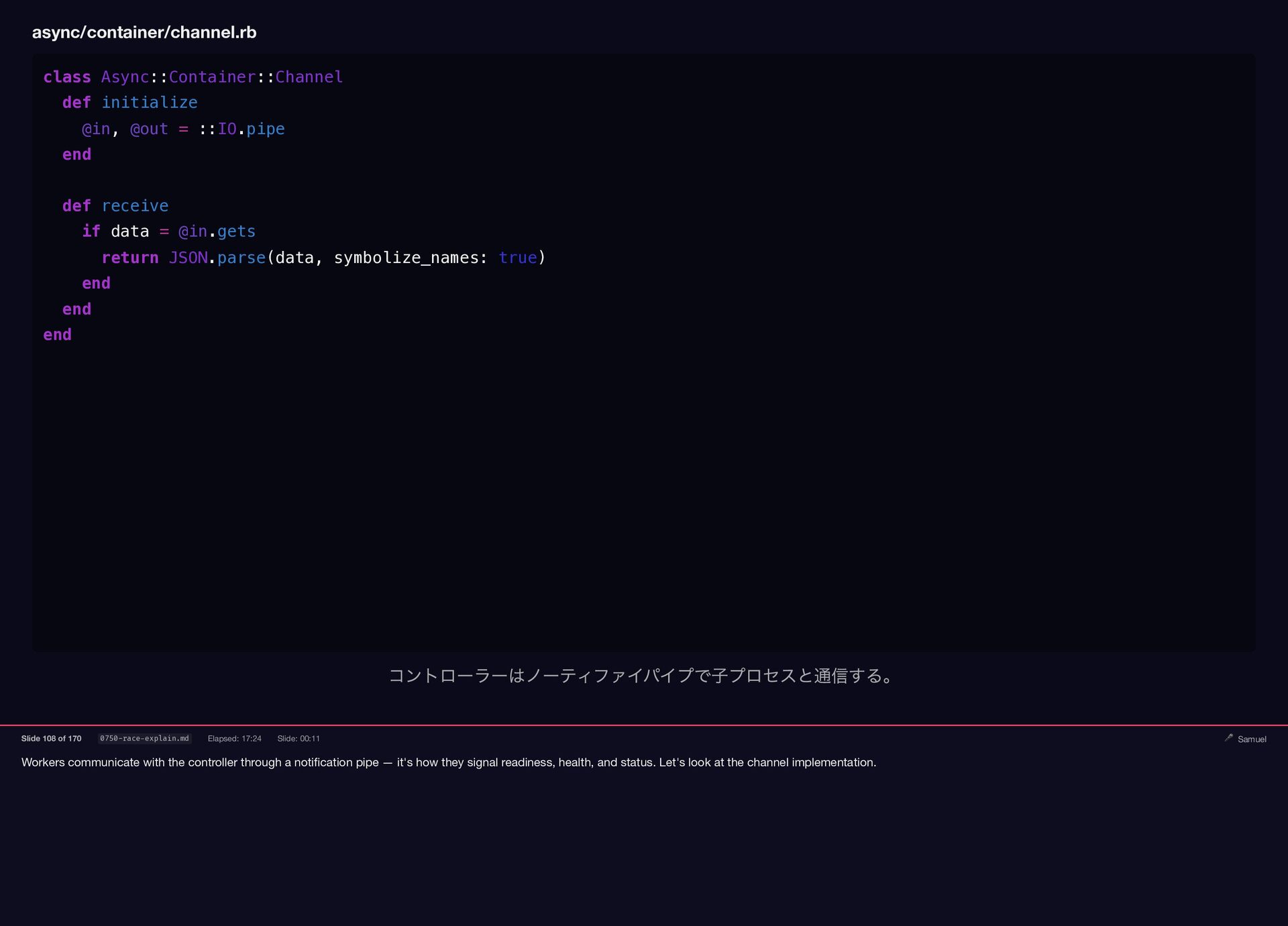{kind=link}
it's how they signal readiness, health, and status. Let's look at the channel implementation. async/container/channel.rb class Async::Container::Channel def initialize @in, @out = ::IO.pipe end def receive if data = @in.gets return JSON.parse(data, symbolize_names: true) end end end コントローラーはノーティファイパイプで子プロセスと通信する。 Slide 108 of 170 0750-race-explain.md Elapsed: 17:24 Slide: 00:11 🎤 Samuel
We create a pipe for the communication, the child process
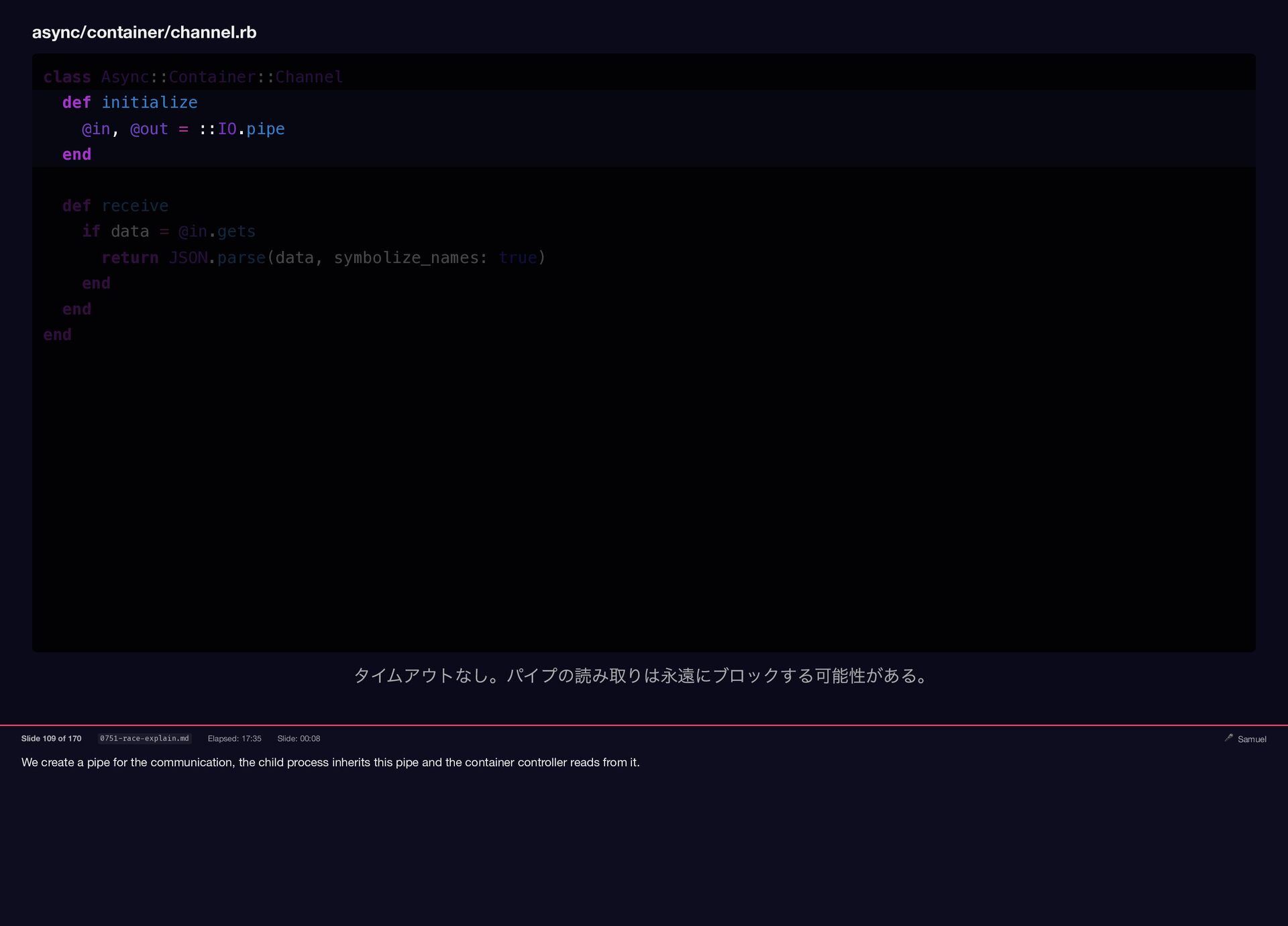{kind=link}
inherits this pipe and the container controller reads from it. async/container/channel.rb class Async::Container::Channel def initialize @in, @out = ::IO.pipe end def receive if data = @in.gets return JSON.parse(data, symbolize_names: true) end end end タイムアウトなし。パイプの読み取りは永遠にブロックする可能性がある。 Slide 109 of 170 0751-race-explain.md Elapsed: 17:35 Slide: 00:08 🎤 Samuel
The receive method calls gets , which reads until it
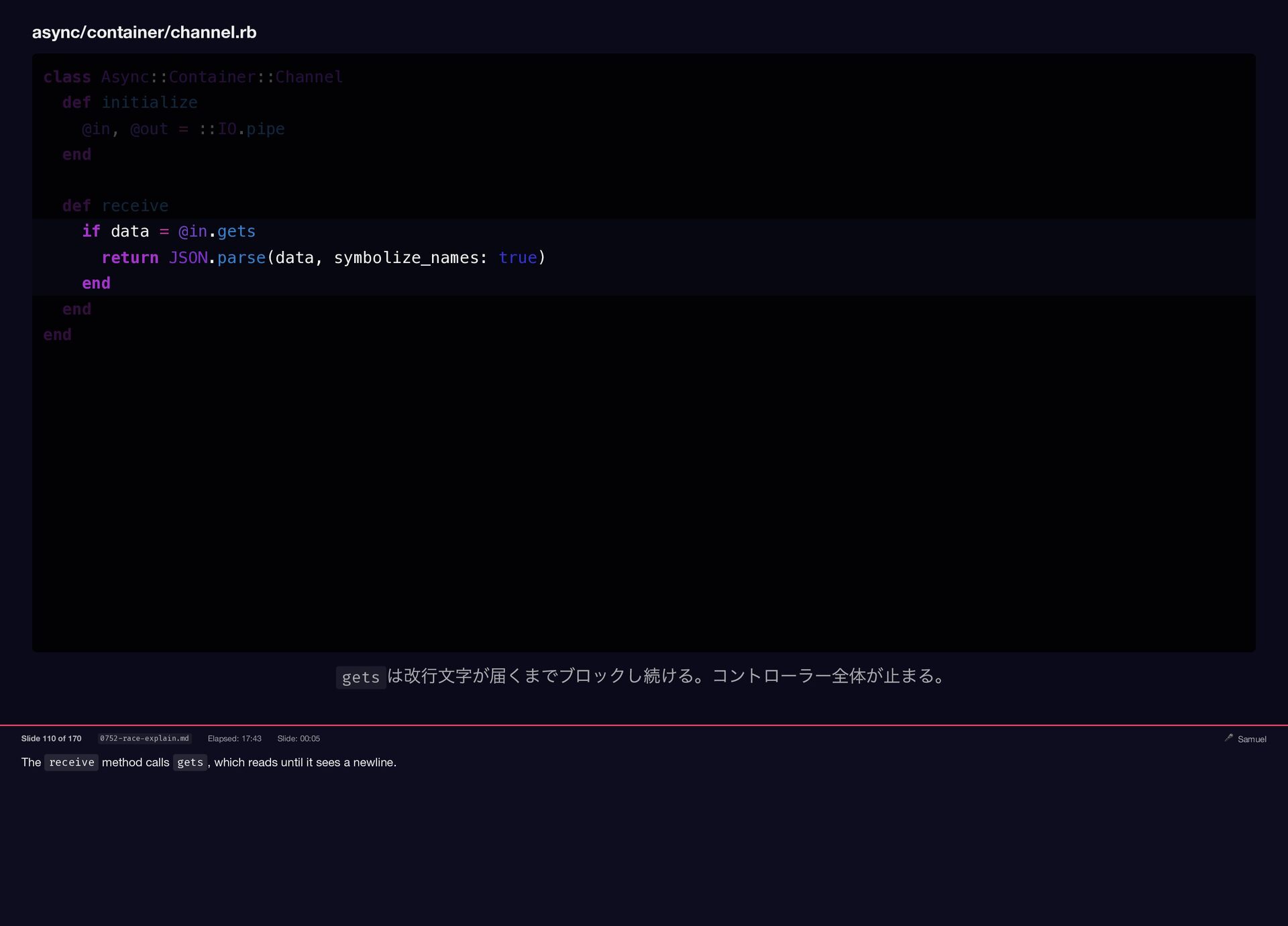{kind=link}
sees a newline. async/container/channel.rb class Async::Container::Channel def initialize @in, @out = ::IO.pipe end def receive if data = @in.gets return JSON.parse(data, symbolize_names: true) end end end gets は改行文字が届くまでブロックし続ける。コントローラー全体が止まる。 Slide 110 of 170 0752-race-explain.md Elapsed: 17:43 Slide: 00:05 🎤 Samuel
On the other side — the worker. It writes status
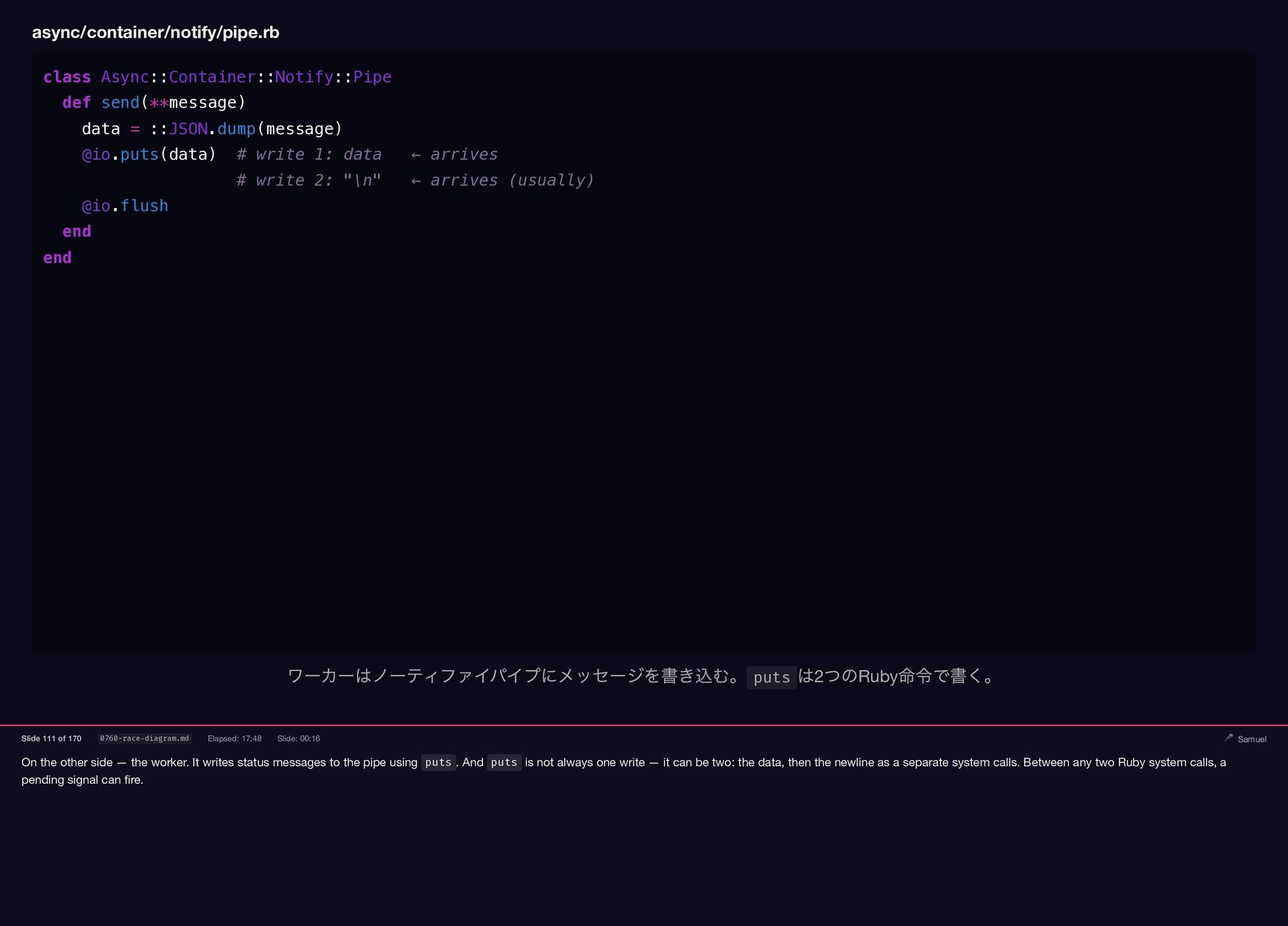{kind=link}
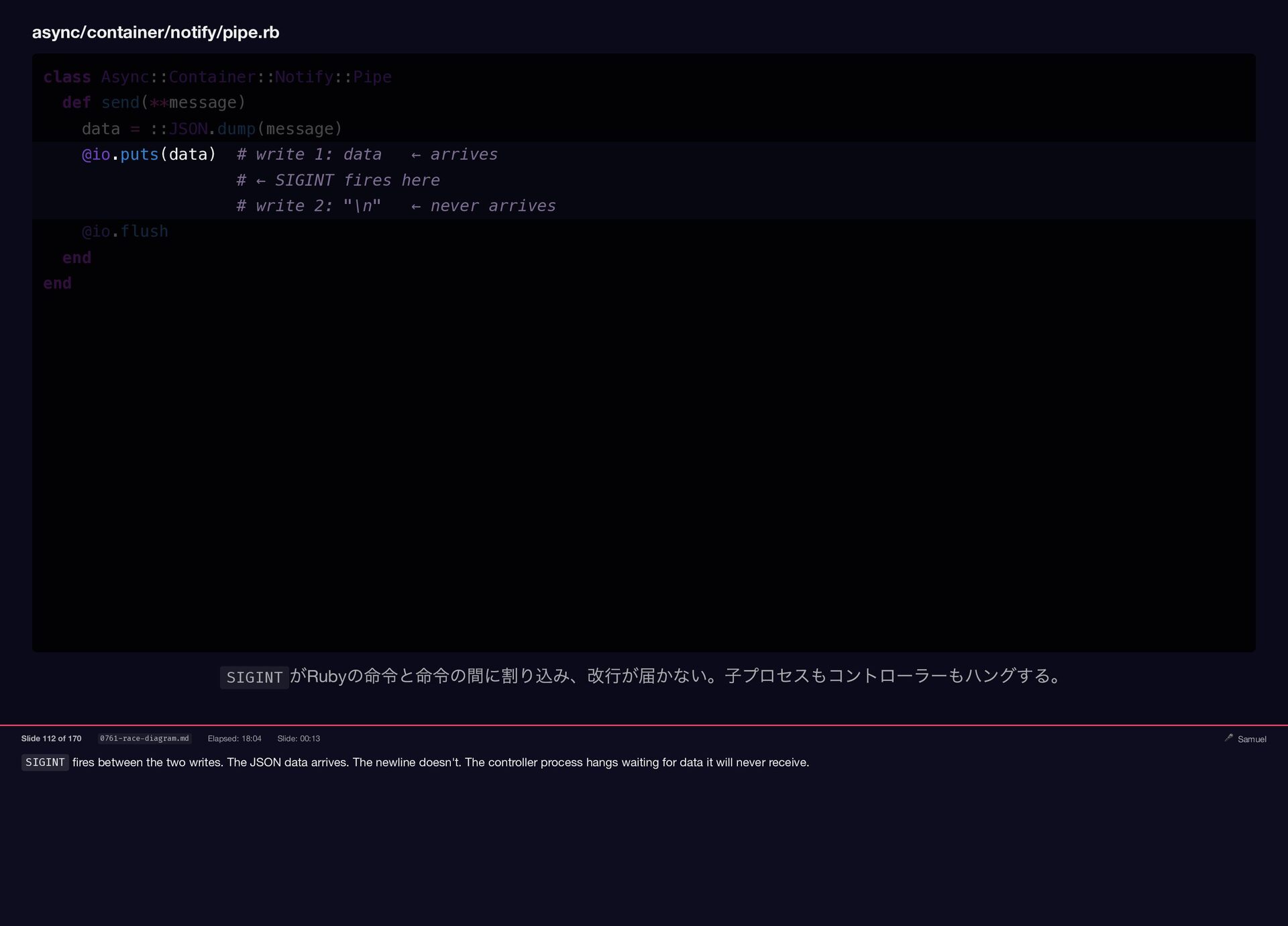
messages to the pipe using puts . And puts is not always one write — it can be two: the data, then the newline as a separate system calls. Between any two Ruby system calls, a pending signal can fire. async/container/notify/pipe.rb class Async::Container::Notify::Pipe def send(**message) data = ::JSON.dump(message) @io.puts(data) # write 1: data ← arrives # write 2: "\n" ← arrives (usually) @io.flush end end ワーカーはノーティファイパイプにメッセージを書き込む。 puts は2 つのRuby 命令で書く。 Slide 111 of 170 0760-race-diagram.md Elapsed: 17:48 Slide: 00:16 🎤 Samuel
SIGINT fires between the two writes. The JSON data arrives.
{kind=link}
The newline doesn't. The controller process hangs waiting for data it will never receive. async/container/notify/pipe.rb class Async::Container::Notify::Pipe def send(**message) data = ::JSON.dump(message) @io.puts(data) # write 1: data ← arrives # ← SIGINT fires here # write 2: "\n" ← never arrives @io.flush end end SIGINT がRuby の命令と命令の間に割り込み、改行が届かない。子プロセスもコントローラーもハングする。 Slide 112 of 170 0761-race-diagram.md Elapsed: 18:04 Slide: 00:13 🎤 Samuel
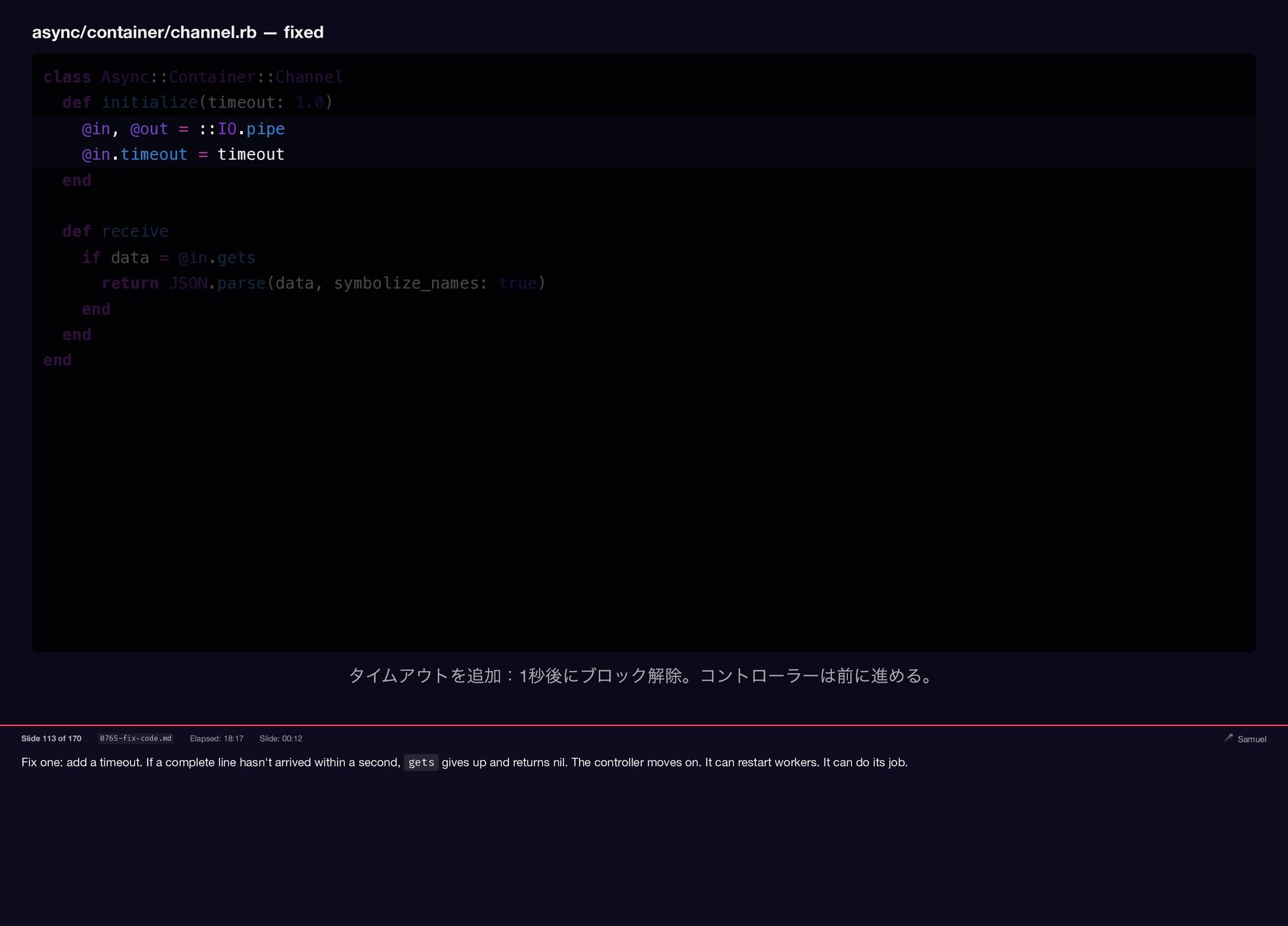
Fix one: add a timeout. If a complete line hasn't
{kind=link}
arrived within a second, gets gives up and returns nil. The controller moves on. It can restart workers. It can do its job. async/container/channel.rb — fixed class Async::Container::Channel def initialize(timeout: 1.0) @in, @out = ::IO.pipe @in.timeout = timeout end def receive if data = @in.gets return JSON.parse(data, symbolize_names: true) end end end タイムアウトを追加:1 秒後にブロック解除。コントローラーは前に進める。 Slide 113 of 170 0765-fix-code.md Elapsed: 18:17 Slide: 00:12 🎤 Samuel
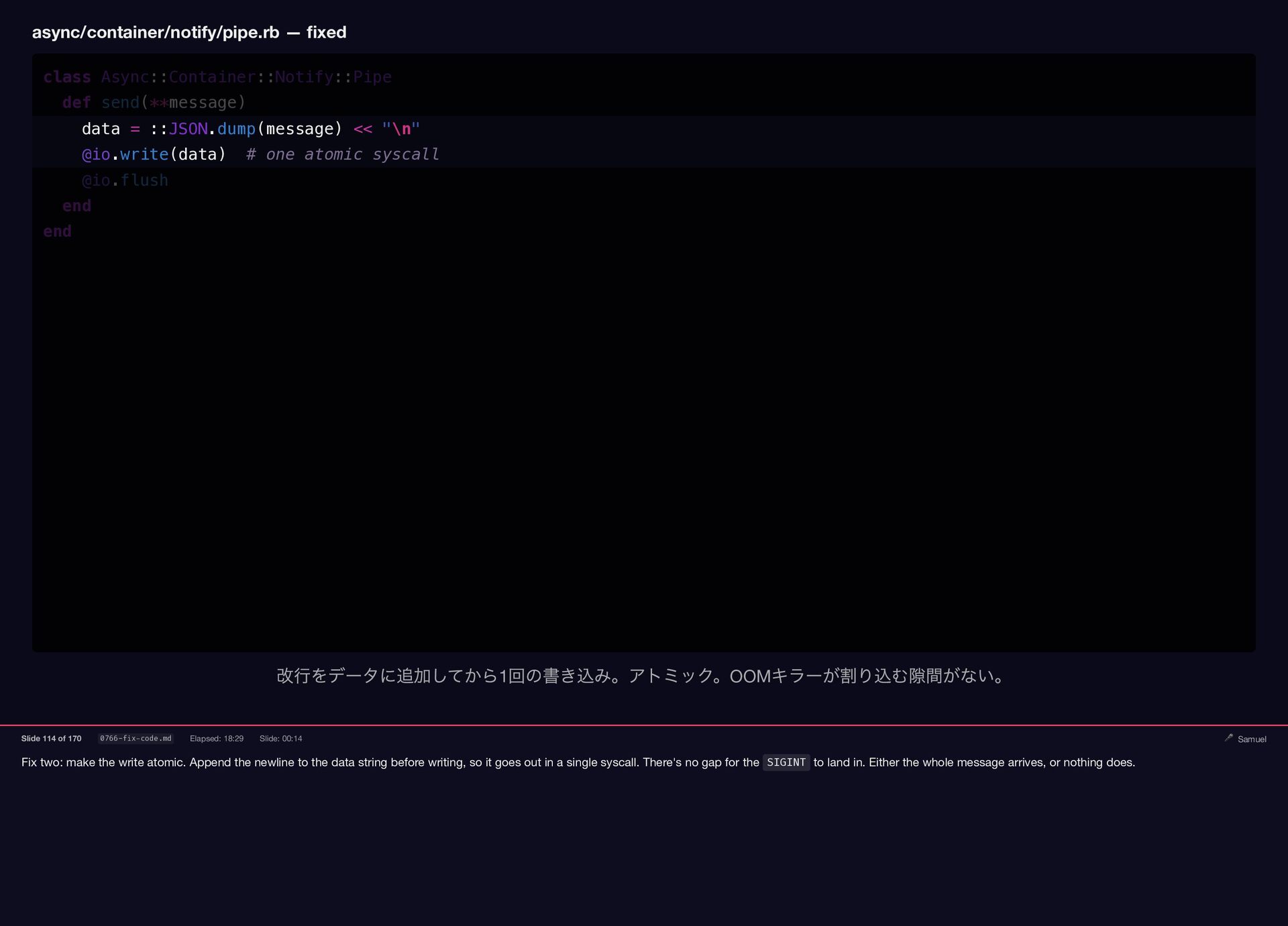
Fix two: make the write atomic. Append the newline to
{kind=link}
the data string before writing, so it goes out in a single syscall. There's no gap for the SIGINT to land in. Either the whole message arrives, or nothing does. async/container/notify/pipe.rb — fixed class Async::Container::Notify::Pipe def send(**message) data = ::JSON.dump(message) << "\n" @io.write(data) # one atomic syscall @io.flush end end 改行をデータに追加してから1 回の書き込み。アトミック。OOM キラーが割り込む隙間がない。 Slide 114 of 170 0766-fix-code.md Elapsed: 18:29 Slide: 00:14 🎤 Samuel
October 14th. I meet with our infra leads. We made
{kind=link}
the call to roll back all major regions to Unicorn, as we fix Falcon. BFCM is six weeks away. We set a deadline — fix Falcon by next Monday, or we stay on Unicorn. October 14th — Roll Back to Unicorn 10 月14 日 ー Unicorn にロールバック Slide 117 of 170 0790-october-14.md Elapsed: 18:55 Slide: 00:21 🎤 Marc-Andre
Blocker number 1: workers not restarting due to silent death,
{kind=link}
like Samuel has shown. The fix is ready — but it hasn't been tested at scale. We don't know if it holds under real BFCM traffic. 1. Workers not restarting due to silent death (fix ready but unproven) 1. OOM 後にワーカーが再起動しない(修正は準備済みだが未検証) Slide 119 of 170 0840-blocker1.md Elapsed: 19:24 Slide: 00:18 🎤 Marc-Andre
Not the segfaults — those we'd fixed. This was a
{kind=link}
different problem that was more structural. And if we couldn't solve it, Falcon couldn't ship. The Kafka problem is existential. Kafka の問題は死活問題だ。 Slide 122 of 170 0860-kafka-problem.md Elapsed: 19:58 Slide: 00:07 🎤 Josh
Under Unicorn, each process has one Kafka connection that only
{kind=link}
connects on the first message. One process, one connection. You have twenty workers per pod, you have twenty connections. Under Unicorn: each process has one Kafka connection that lazily connects. Simple. Unicorn では、各プロセスがKafka 接続を1 つだけ持ち、遅延的に接続する。シンプル。 Slide 123 of 170 0870-unicorn-kafka.md Elapsed: 20:05 Slide: 00:11 🎤 Josh
In our experience with Unicorn. Low PIDs tend to handle
{kind=link}
more requests meaning with twenty workers only the first few will handle the majority of traffic staying very warm We had depended on the Unicorn behaviour for years and plan for that. Unicorn workers W1 W2 W3 W4 W5 │ │ ╎ ╎ ╎ Kafka 5 つのUnicorn ワーカー。W1 とW2 が接続を確立し、Kafka にメッセージ送信。W3 〜W5 はまだ接続していない。 Slide 124 of 170 0871-unicorn-kafka-diagram.md Elapsed: 20:16 Slide: 00:15 🎤 Josh
We're running thousands of pods. Each pod has around a
{kind=link}
hundred workers. Each worker has its own Kafka connections. The connection count explodes — and it grows linearly with every pod we add. Across thousands of pods: the connection count explodes. ~100 connections per pod. 数千のポッドで接続数が爆発。ポッドあたり約100 接続。 Slide 127 of 170 0890-connection-explode.md Elapsed: 20:44 Slide: 00:14 🎤 Josh
We ran the numbers with the Kafka infrastructure team. At
{kind=link}
BFCM scale — with the traffic we were expecting — we would overwhelm the brokers. They were direct about it: this will not work. You cannot ship Falcon like this. At BFCM scale, we'd overwhelm the Kafka brokers. BFCM の規模では、Kafka ブローカーを圧倒してしまう。 Slide 128 of 170 0900-overwhelm.md Elapsed: 20:58 Slide: 00:11 🎤 Josh
Ilya suggests something simple: What if only one process per
{kind=link}
pod talks to Kafka? All the workers send their messages to that one process. The one process talks to Kafka. The broker only ever sees one connection per pod. Ilya Grigorik suggests an idea: "What if only one process per pod talks to Kafka?" 「ポッドごとに一つのプロセスだけがKafka と通信したら?」 Slide 129 of 170 0910-ilya.md Elapsed: 21:09 Slide: 00:18 🎤 Josh
Marc and I pair on a prototype and Marc gets
{kind=link}
it just ready enough to talk about. It's rough, but it works. Marc and Josh prototype. Josh takes it from prototype to production. Marc が週末でプロトタイプ。Josh がプロトタイプからプロダクションへ。 Slide 130 of 170 0920-prototype.md Elapsed: 21:27 Slide: 00:07 🎤 Josh
I take it and build it into something we can
{kind=link}
actually ship — proper error handling, retry logic, load testing etc. We call it Outbox. And we have four weeks to test, scale test and roll it out everywhere before BFCM. Marc and Josh prototype. Josh takes it from prototype to production. Marc が週末でプロトタイプ。Josh がプロトタイプからプロダクションへ。 Slide 131 of 170 0921-prototype-2.md Elapsed: 21:34 Slide: 00:12 🎤 Josh
Each Falcon worker sends its Kafka messages to a single
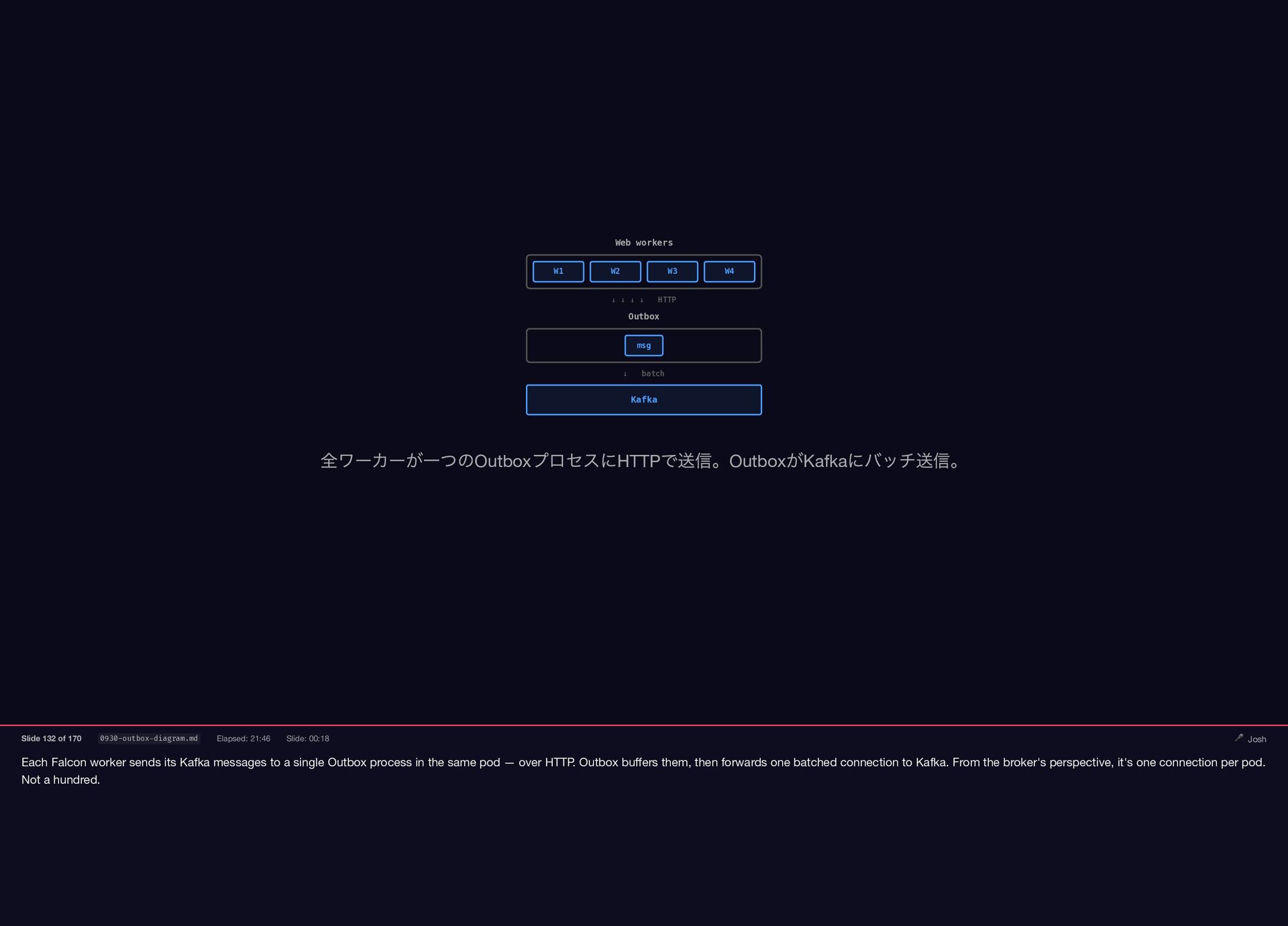{kind=link}
Outbox process in the same pod — over HTTP. Outbox buffers them, then forwards one batched connection to Kafka. From the broker's perspective, it's one connection per pod. Not a hundred. Web workers W1 W2 W3 W4 ↓ ↓ ↓ ↓ HTTP Outbox msg ↓ batch Kafka 全ワーカーが一つのOutbox プロセスにHTTP で送信。Outbox がKafka にバッチ送信。 Slide 132 of 170 0930-outbox-diagram.md Elapsed: 21:46 Slide: 00:18 🎤 Josh
This dramatically reduces the load on Kafka. Every worker's messages
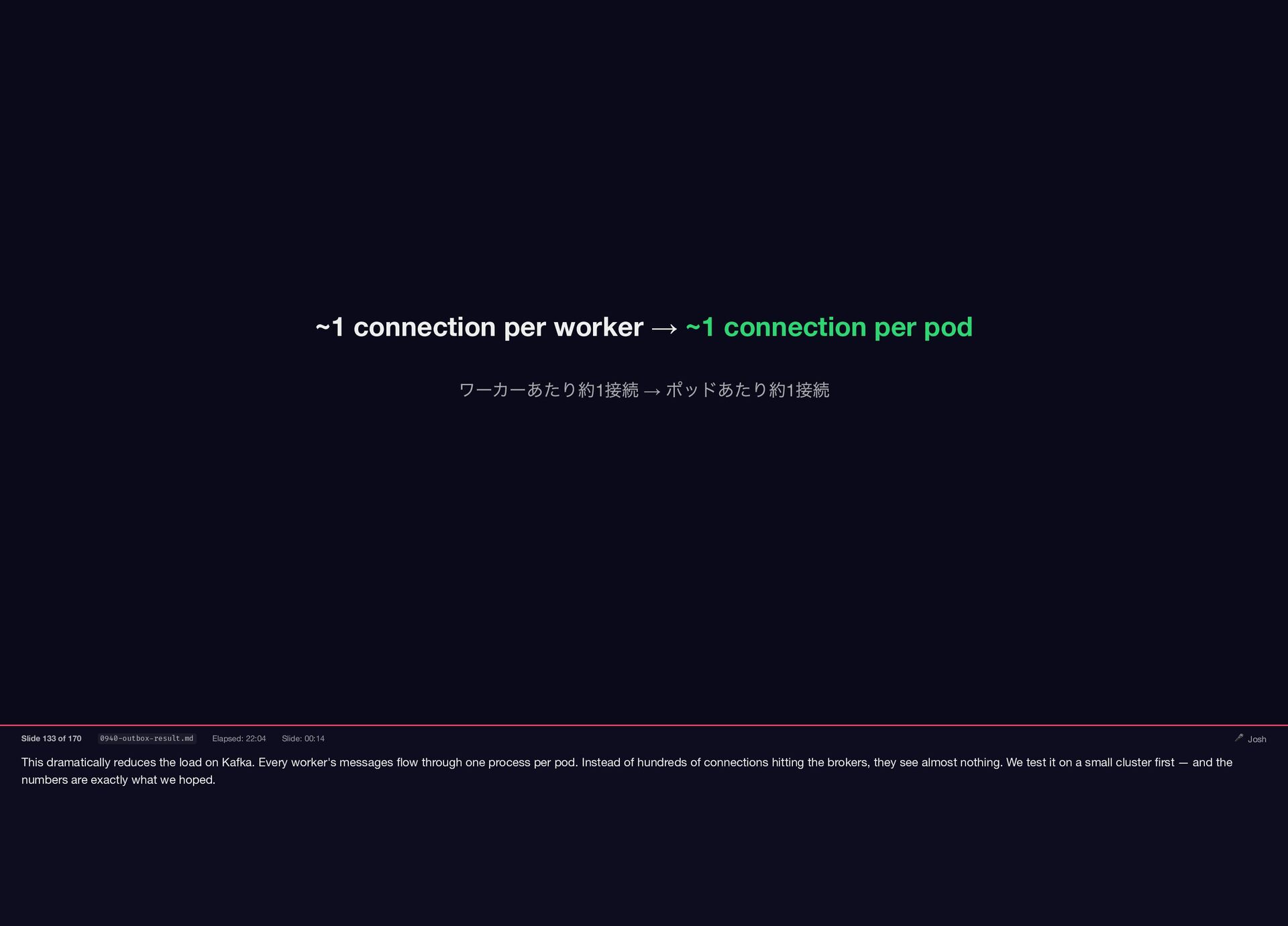{kind=link}
flow through one process per pod. Instead of hundreds of connections hitting the brokers, they see almost nothing. We test it on a small cluster first — and the numbers are exactly what we hoped. ~1 connection per worker → ~1 connection per pod ワーカーあたり約1 接続 → ポッドあたり約1 接続 Slide 133 of 170 0940-outbox-result.md Elapsed: 22:04 Slide: 00:14 🎤 Josh
Here's view of what that kind of looked like. You
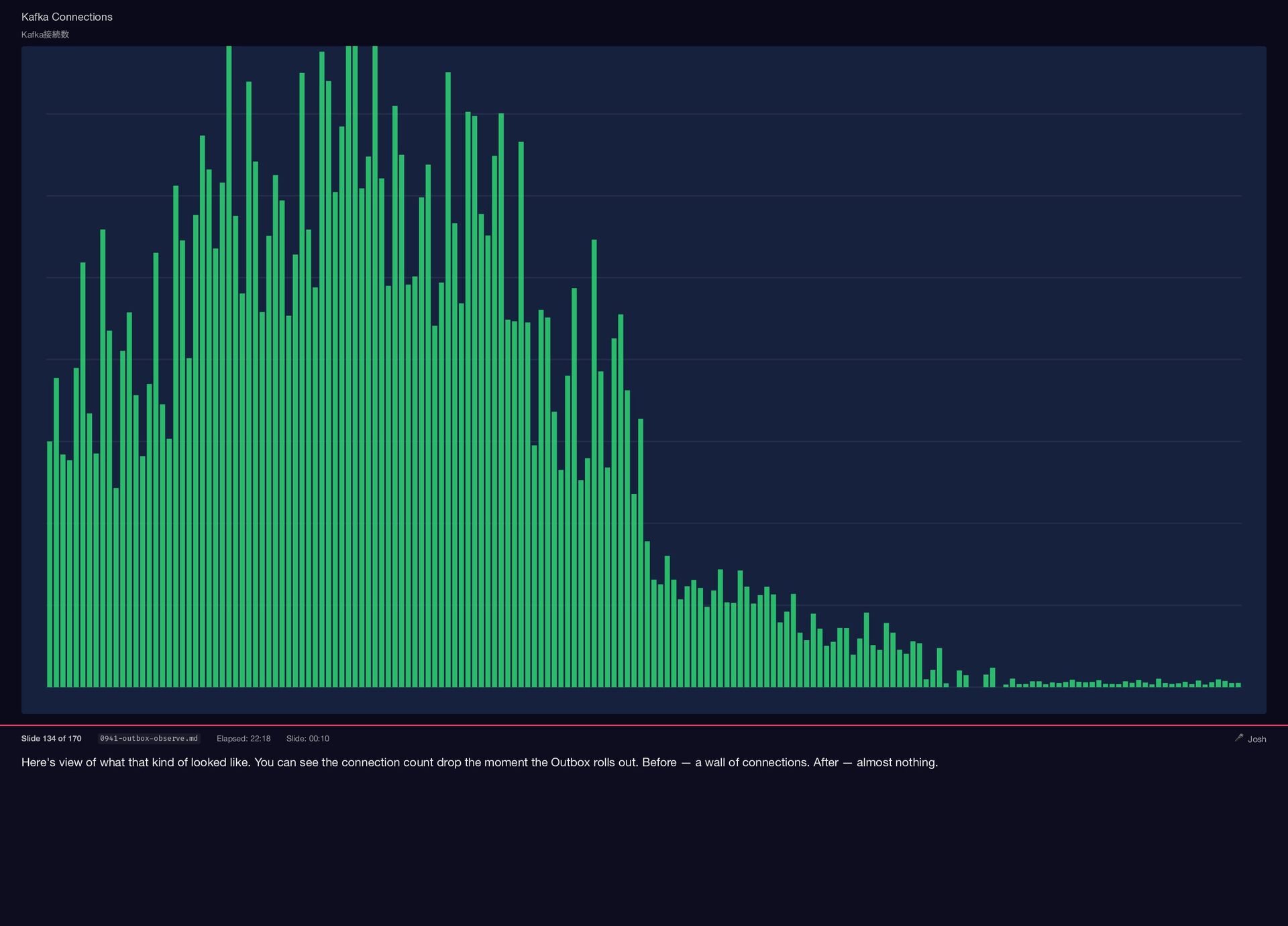{kind=link}
can see the connection count drop the moment the Outbox rolls out. Before — a wall of connections. After — almost nothing. Kafka Connections Kafka 接続数 Slide 134 of 170 0941-outbox-observe.md Elapsed: 22:18 Slide: 00:10 🎤 Josh
The go/no-go meeting arrives. We walk in with two things:
{kind=link}
Samuel's fix for the silent death deployed and holding. And Outbox, running on a small cluster with numbers we can actually show. We put them on the screen and walk through our changes. The go/no-go meeting arrives. We show the numbers. ゴー/ ノーゴー会議が来る。数字を見せる。 Slide 135 of 170 0950-go-nogo.md Elapsed: 22:28 Slide: 00:14 🎤 Josh
Four weeks. That's what we have between the green light
{kind=link}
and BFCM. We roll the Outbox out cluster by cluster — carefully, watching the connection numbers after each one. Every rollout confirms the same thing: it works. Connection count drops. Kafka team signs off on each region. The next 4 weeks are a sprint. Outbox rolls out cluster by cluster, phase by phase. 次の4 週間はスプリント。Outbox をクラスターごと、フェーズごとに展開。 Slide 137 of 170 0970-sprint.md Elapsed: 22:48 Slide: 00:19 🎤 Josh
Mid-sprint, we ran Scale Test 5 and a Kafka regional
{kind=link}
failover test at full scale. Traffic more than doubled. Outbox handled it. Message drop rate was nearly zero (0.00001%). The Kafka team confirmed: it works. That was the moment the last doubt went away. Mid-sprint: Scale Test 5. Kafka failover. Traffic doubles. Almost nothing drops. スプリント中盤:スケールテスト5 。Kafka フェイルオーバー。トラフィックが倍増。ほぼ何もドロップしない。 Slide 138 of 170 0975-scale-test-5.md Elapsed: 23:07 Slide: 00:16 🎤 Josh
The Kafka team sends us the real numbers. Real numbers:
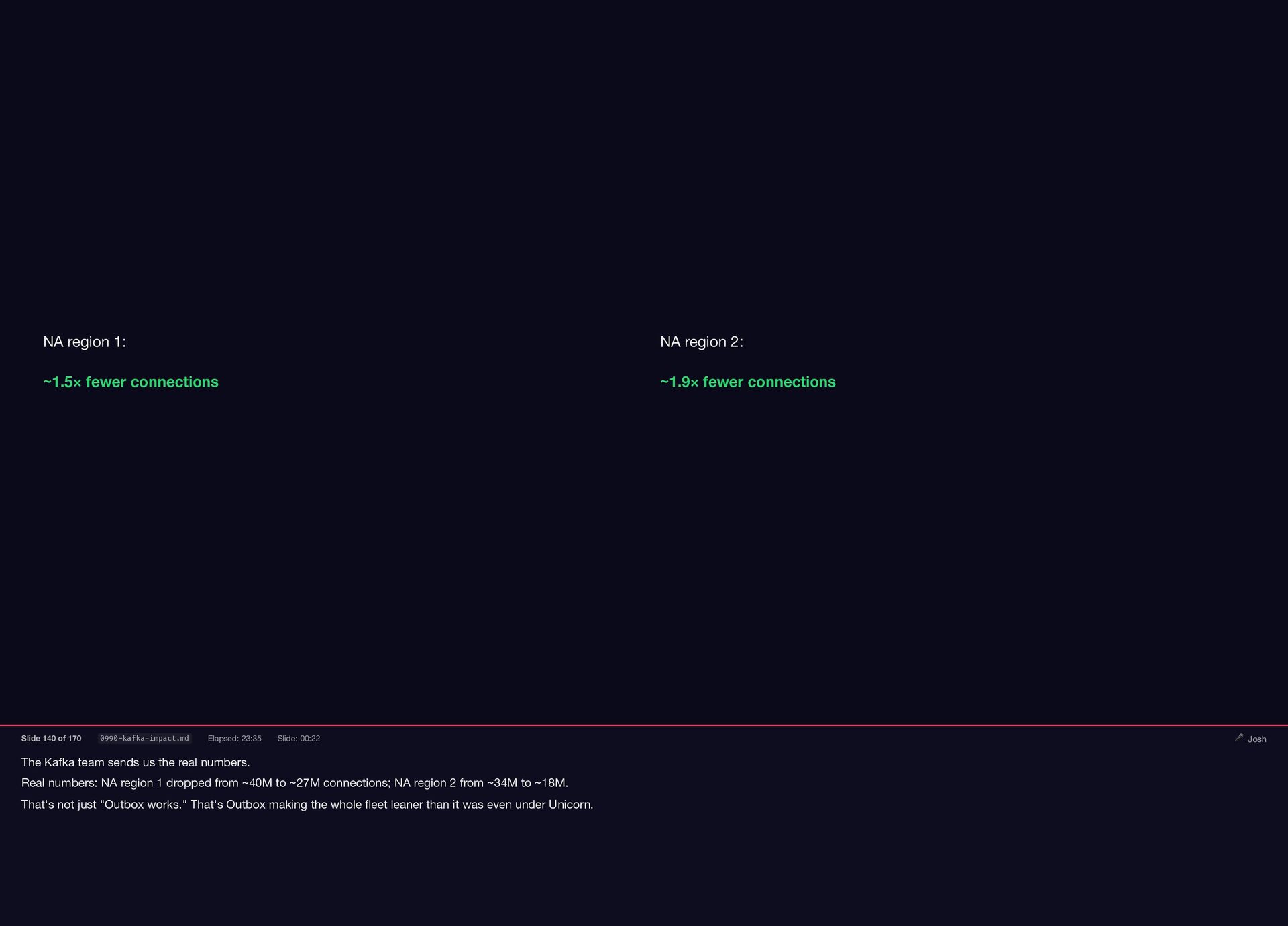{kind=link}
NA region 1 dropped from ~40M to ~27M connections; NA region 2 from ~34M to ~18M. That's not just "Outbox works." That's Outbox making the whole fleet leaner than it was even under Unicorn. NA region 1: ~1.5× fewer connections NA region 2: ~1.9× fewer connections Slide 140 of 170 0990-kafka-impact.md Elapsed: 23:35 Slide: 00:22 🎤 Josh
One hundred and ten million Kafka messages per minute —
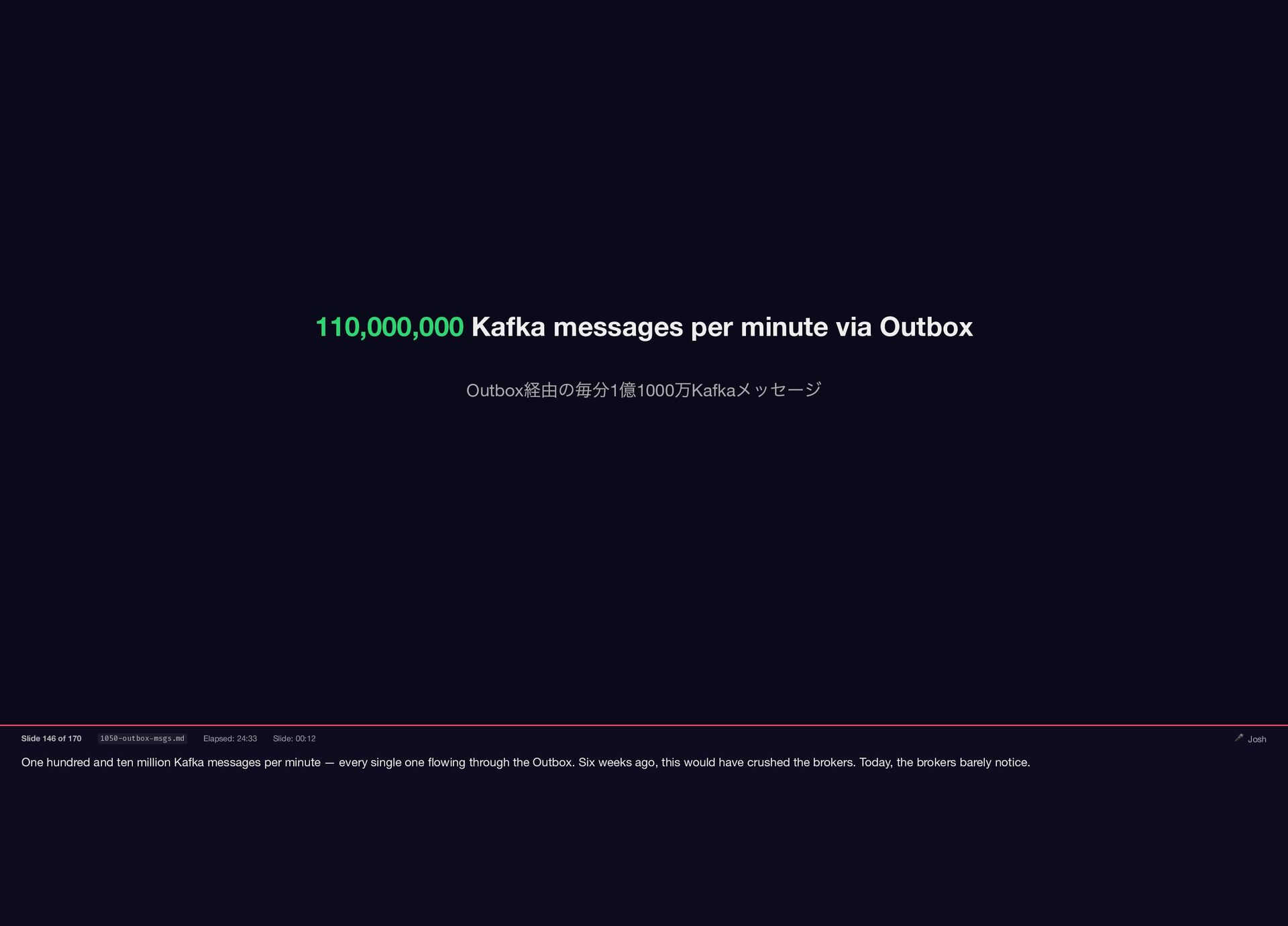{kind=link}
every single one flowing through the Outbox. Six weeks ago, this would have crushed the brokers. Today, the brokers barely notice. 110,000,000 Kafka messages per minute via Outbox Outbox 経由の毎分1 億1000 万Kafka メッセージ Slide 146 of 170 1050-outbox-msgs.md Elapsed: 24:33 Slide: 00:12 🎤 Josh
We see some P99 bumps on GraphQL when upstream services
{kind=link}
slow down, but that's expected. That's not us. That's upstream. Some P99 bumps on GraphQL when upstream services slow down. But that's expected. アップストリームサービスが遅くなるとGraphQL のP99 にバンプ。しかし、これは想定内。 Slide 149 of 170 1080-p99.md Elapsed: 24:55 Slide: 00:08 🎤 Josh
On December third, I posted to the channel: "Congrats folks
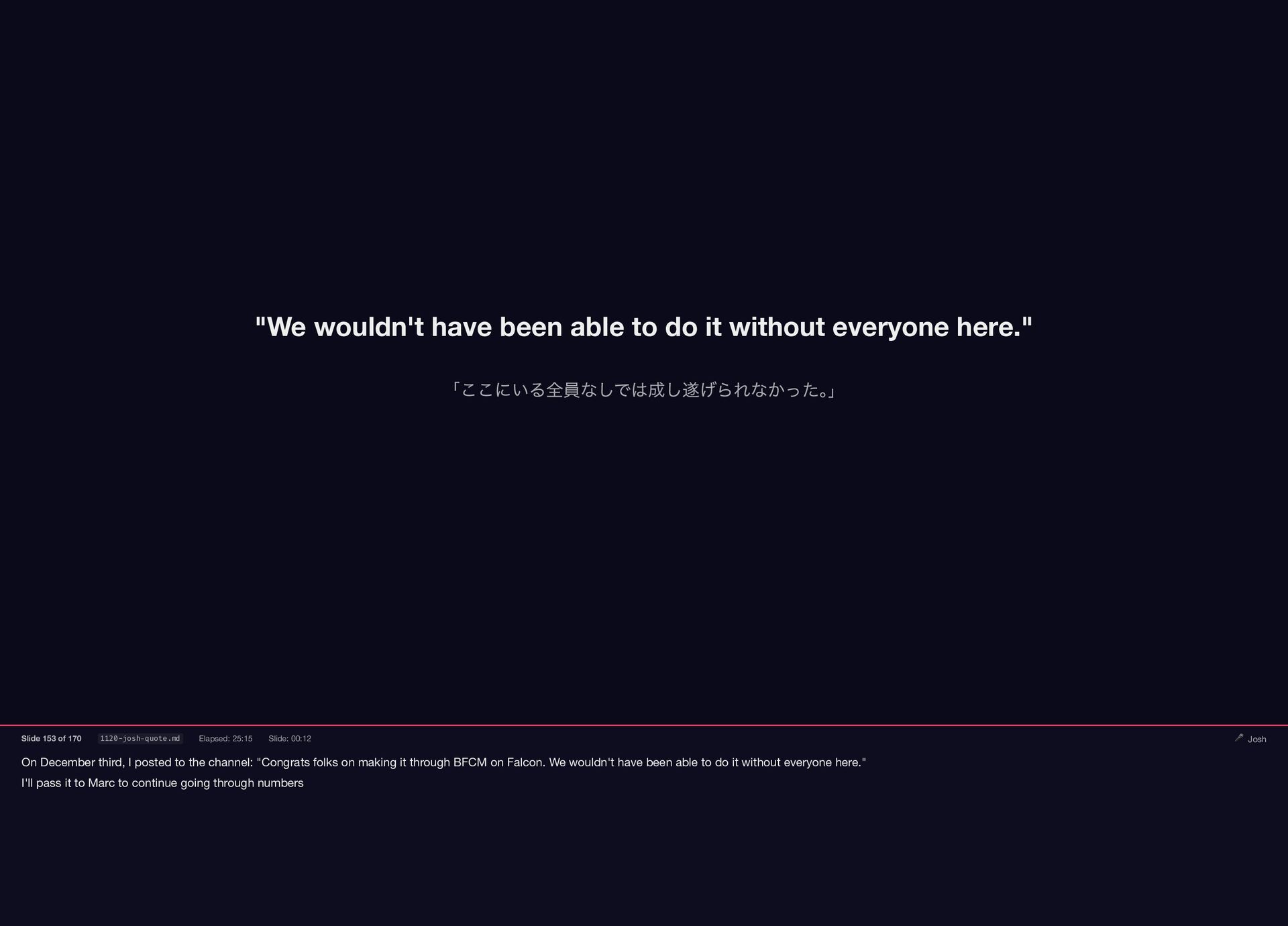{kind=link}
on making it through BFCM on Falcon. We wouldn't have been able to do it without everyone here." I'll pass it to Marc to continue going through numbers "We wouldn't have been able to do it without everyone here." 「ここにいる全員なしでは成し遂げられなかった。 」 Slide 153 of 170 1120-josh-quote.md Elapsed: 25:15 Slide: 00:12 🎤 Josh
2. Scale tests save you. We ran 5 of them.
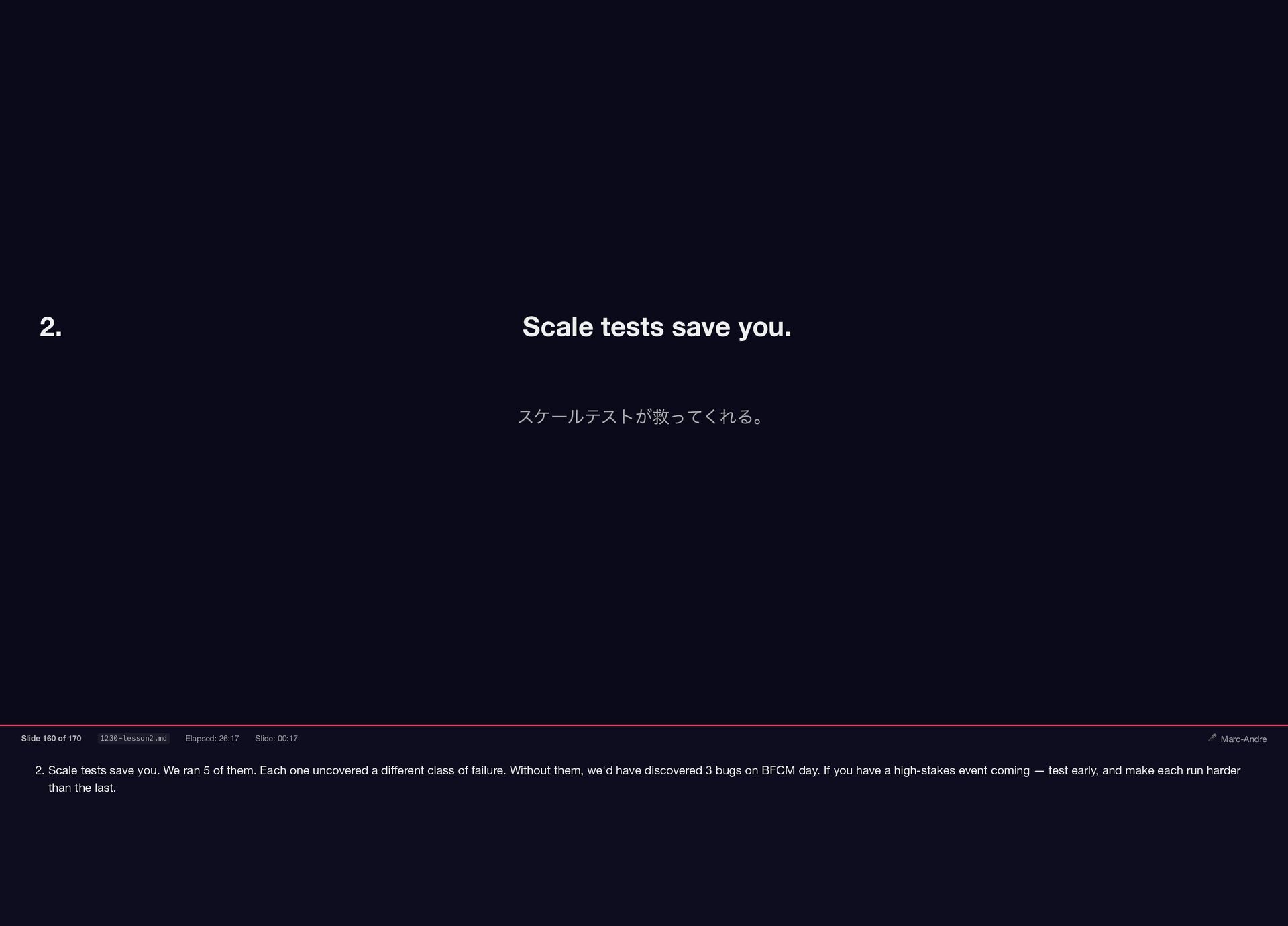{kind=link}
Each one uncovered a different class of failure. Without them, we'd have discovered 3 bugs on BFCM day. If you have a high-stakes event coming — test early, and make each run harder than the last. 2. Scale tests save you. スケールテストが救ってくれる。 Slide 160 of 170 1230-lesson2.md Elapsed: 26:17 Slide: 00:17 🎤 Marc-Andre
4. Pressure creates invention. The Outbox was born from a
{kind=link}
crisis with a deadline. From prototype to production in 4 weeks. Sometimes the best solutions come when there's no time for the perfect one. 4. Pressure creates invention. プレッシャーが発明を生む。 Slide 162 of 170 1250-lesson4.md Elapsed: 26:49 Slide: 00:12 🎤 Marc-Andre
Falcon lets us mix workloads in the same process —
{kind=link}
Liquid template rendering, GraphQL, and long I/O operations. This gives us better utilization, lower cost, and simplifies our infrastructure. Better concurrency controls open the door to combining workloads. Same container. Better utilization. Lower cost. より高度な並行制御により、ワークロードの統合が可能に。同じコンテナ。より高い利用率。コスト削減。 Slide 166 of 170 1285-combining-workloads.md Elapsed: 27:24 Slide: 00:15 🎤 Marc-Andre
We've proven Falcon can handle Shopify's scale. That opens the
{kind=link}
door — both for other teams inside Shopify, and for anyone else in the Ruby world who's been waiting to make the jump. Falcon is proven at scale. The door is open to further adoption. Falcon は大規模で実証済み。さらなる採用への道が開かれた。 Slide 167 of 170 1290-further-adoption.md Elapsed: 27:39 Slide: 00:15 🎤 Marc-Andre
If you want to go deeper — on Falcon, Async,
{kind=link}
the Outbox, fiber schedulers, or anything else we talked about today — we'd love to talk more. Come find us. Thank you! Oh and one more thing... Pass over to Samuel Questions? Samuel Williams (ioquatix) · Josh Teeter (whatisinternet) · Marc-Andre Cournoyer (macournoyer) 質問はありますか? Slide 168 of 170 1300-questions.md Elapsed: 27:54 Slide: 00:16 🎤 Marc-Andre
Samuel gestures at the screen. This whole talk — live
{kind=link}
reloading, the animations, the diagrams — all running on presently , which is built on top of async and lively . Same stack, different application. This presentation runs on the same stack as Falcon — via presently . このプレゼンテーションはFalcon と同じスタックで動いています — presently を通して。 Slide 169 of 170 1305-presently.md Elapsed: 28:10 Slide: 00:13 🎤 Samuel
If you'd like to go deeper on Falcon, Async, or
{kind=link}
building real-time web applications with Ruby, please come to the Async Cafe Workshop. Scan the QR code or visit the RubyKaigi event page for more information. Looking forward to hanging out! All bow Async Cafe Workshop — Ruby によるリアルタイムWeb アプリ開発 / https://connpass.com/event/390661/ Slide 170 of 170 1310-async-cafe.md Elapsed: 28:23 Slide: 00:17 🎤 Samuel