Overview
Nathan Lambert is a distinguished researcher from AI2 (Allen Institute for Science) who recently published a book on RLHF (Reinforcement Learning from Human Feedback). Book can be found here
Core Concept
RLHF enables a base model to learn from human preferences. These preferences are encoded in a separate reward model, and the training objective is to align the base model with human preferences through this reward model. A Supervised Fine-Tuning (SFT) step precedes RLHF to facilitate reaching the aligned model.
Three Key Steps:
- Train a language model to understand human instruction data
- Gather human preference data to train a reward model
- Optimize the LM using an RL optimizer by sampling generations and rating them against the reward model
Post-Training
Post-training encompasses all steps after obtaining the base model, including supervised fine-tuning and RLHF.
Key Points:
- RLVR (RL for reasoning) helps with enhanced reasoning capabilities
- RLHF elicits behaviors aligned with human values
- RLHF was initially the primary post-training technique but is now one component of a larger chain
- RLHF gained prominence with ChatGPT's success
- Challenge: controlling optimization to avoid over-optimization, since the reward signal is a proxy
- Unlike IFT (token-level prediction), RLHF operates at the response level, aiming to mimic specific styles and behaviors
- Uses contrastive loss functions to guide what to pursue and what to avoid
- Pre-2018: TAMER approach showed humans choosing between Atari trajectories was more effective than agent-environment interaction
- 2018-2022: Focus on LLMs (GPT-2, GPT-3 papers)
- Post-2023: Widespread adoption across major labs; expansion into broader preference fine-tuning including PRMs, DPO, and reasoning methods
Chapter 3: Definitions and Background
Language Modeling Overview
- Focus on autoregressive decoder-only LMs
- LM head: Final projection layer mapping from internal embedding space to tokenizer space (vocabulary)
Key RL Definitions
- Finite horizon reward
- Q function
- Value function
- Advantage function
- Additional foundational RL terminology and notation
Chapter 4: Training Overview
Optimization Objective
J_θ(π) = Expected value of rewards over infinite time horizon
Regularization
- Since training builds on a strong base model, we prevent excessive deviation by subtracting a D_KL (divergence) term
- Transition from reward function to reward model to capture human preferences: r(s_t, a_t)
- Initial states = prompts from training dataset
- Actions = completions to prompts
- Response-level rewards (not token-level)
Basic RLHF Pipeline
- IFT on ~10K examples
- Train reward model on ~100K pairwise prompts (using instruction-tuned checkpoint)
- Train IFT model with RLHF
Standard objective: maximize reward while constraining KL distance from reference policy
- InstructGPT recipe (2022): ~10K instruction examples → ~100K preference pairs for RM → ~100K prompts for RLHF
- Tülu 3 recipe (2024): ~1M instruction examples → ~1M preference pairs → ~10K prompts for RLVR
- DeepSeek R1 recipe (2025): Cold-start reasoning samples → large-scale RL → rejection sampling → mixed RL training
Modern Approaches
Today's models involve multiple iterations with RLVR (RL for reasoning) to boost reasoning behavior:
- SFT includes Chain-of-Thought (CoT) examples so the base model learns reasoning patterns
- Heavy reliance on RLVR
- Data types and iteration counts in post-training depend on desired capabilities
Chapters 5 & 6: The Nature of Preferences
Challenges in Quantifying Preferences
Humans find it easier to choose between options (rank or rate) than generate answers from scratch.
Preference Collection Methods
- Ranking: Likert scales with varying degrees
- UI Design: Critical for gathering quality preferences
- Thumbs up/down
- Midjourney-style tracking (which generation users select)
- All collected data feeds back into model fine-tuning via RLHF
- Data collection process: Expensive ($1-10+ per prompt), requires vendor contracts, delivered in weekly batches
- Multi-turn data typically continues with "chosen" response; all prior turns masked from loss
- Structured preference data can be auto-generated (e.g., correct vs. incorrect math answers)
Note: Post-training is capability-specific—the behaviors a model needs to exhibit determine the data types and training iterations required.
7. Reward Modeling
Key Takeaways:
- Trained using Bradley-Terry model: predicts probability that one completion is preferred over another
- Loss function:
-log(σ(r_θ(y_c|x) - r_θ(y_r|x))) - Architecture: language model + classification head outputting single scalar
- Train for only 1 epoch to avoid overfitting
- Variants: Preference margin loss (Llama 2), K-wise loss (Plackett-Luce), balancing multiple comparisons per prompt
- Outcome Reward Models (ORMs): Predict correctness per-token with cross-entropy loss
- Process Reward Models (PRMs): Assign scores at each reasoning step, not every token
- Generative Reward Models (LLM-as-judge) are simpler but often less effective than trained RMs
8. Regularization
Key Takeaways:
- KL distance penalty prevents over-optimization:
r = r_θ - λ*D_KL(π_RL||π_ref) - Most common: reverse KL from current policy to reference model
- Implementation uses Monte Carlo approximation:
E_x~P[log P(x) - log Q(x)] - Other options: pretraining gradients (maintaining performance on NLP datasets), margin losses
- Double regularization occurs in PPO (internal step-size control + external KL penalty)
- Many models now remove KL penalty entirely for reasoning training
9. Instruction Finetuning
Key Takeaways:
- Teaches question-answer format and basic instruction following
- Uses same autoregressive loss as pretraining but with smaller batches
- Chat templates: Structure messages with system/user/assistant roles and special tokens (e.g., ChatML format)
- Prompt masking: Only completion tokens contribute to loss, not prompt tokens
- Best practices: ~1M prompts achieves strong performance; quality > quantity; prompts should match downstream tasks
- Multi-turn masking: only final assistant turn included in loss
- Foundation for all subsequent post-training
10. Rejection Sampling
Key Takeaways:
- Simple baseline: generate N completions per prompt → filter with reward model → finetune on top completions
- Selection methods: (1) top per prompt, or (2) top K overall
- Sampling parameters: temperature 0.7-1.0, 10-30+ completions per prompt
- Used in WebGPT, Anthropic models, Llama 2, and as RL baseline
- Best-of-N sampling is inference-time equivalent (doesn't modify model)
- Less complex than full RL but requires good reward model
- Implementation trick: sort completions by length for efficient batched inference
11. Reinforcement Learning (Policy Gradient Algorithms)
Key Takeaways:
- Core objective:
∇_θ J(θ) = E[∑ ∇_θ log π_θ(a_t|s_t) Ψ_t]where Ψ_t can be return, advantage, etc. - REINFORCE: Uses Monte Carlo return with baseline; RLOO variant uses leave-one-out baseline
- PPO: Clips policy ratio to constrain updates:
min(ratio*A, clip(ratio, 1-ε, 1+ε)*A)- Includes learned value function for variance reduction
- Trust region prevents too-large updates
- GRPO: Simplified PPO without value network; uses group-wise advantage normalization
- Requires multiple samples per prompt
- KL penalty typically in loss rather than reward
- Implementation details: per-token vs. per-sequence loss aggregation significantly affects learning
- Asynchronous training increasingly important for long reasoning traces
- GAE (Generalized Advantage Estimation) balances bias-variance tradeoff
12. Direct Alignment Algorithms
Key Takeaways:
- DPO: Directly optimizes RLHF objective without reward model or RL training
- Loss:
-log(σ(β log(π_θ(y_c|x)/π_ref(y_c|x)) - β log(π_θ(y_r|x)/π_ref(y_r|x)))) - Implicit reward:
r(x,y) = β log(π_r(y|x)/π_ref(y|x)) - β parameter controls KL constraint (static, unlike dynamic in RL)
- Advantages: Simpler implementation, lower memory, easier hyperparameter tuning
- Disadvantages: Preference displacement (reduces both chosen and rejected probabilities), off-policy data limits
- Variants: IPO, cDPO, ORPO, SimPO, REBEL address various weaknesses
- Online variants (Online DPO, D2PO) bridge gap to RL methods
- RL methods generally outperform DPO slightly, but DPO remains popular for simplicity
13. Constitutional AI & AI Feedback
Key Takeaways:
- RLAIF uses AI-generated feedback instead of human labels (far cheaper: <$0.01 vs. $1-10+)
- Constitutional AI (CAI): Uses principles to critique and revise outputs
- Critique phase: Model revises outputs based on constitution principles
- Preference generation: Model judges which output better follows principles
- Specific judge models exist (Prometheus, CriticLLM) but not widely adopted
- AI feedback tradeoff: low-noise but high-bias vs. human high-noise, low-bias
- Used extensively in leading models (Claude, etc.) but exact practices not disclosed
- Deliberative Alignment (OpenAI) has models reference safety policies during reasoning
14. Reasoning Training & Inference-Time Scaling
Key Takeaways:
- RLVR (RL with Verifiable Rewards): Uses binary rewards (correct/incorrect) instead of reward models
- Training cycle: sample multiple answers → gradient towards correct ones → repeat on same data
- Why it works now: model capability threshold reached, stable RL infrastructure, accessible tooling
- Common techniques:
- Offline difficulty filtering (20-80% solve rate)
- Online/curriculum filtering during training
- Remove KL penalty for exploration
- Relaxed clipping for better exploration
- Off-policy/asynchronous updates for efficiency
- Text-only reasoning training surprisingly boosts multimodal performance
- Inference-time scaling: more compute at test time → better performance
- Models include: DeepSeek R1, OpenAI o1, Kimi 1.5, Phi-4, Qwen 3, etc.
Key Takeaways:
- Tool use extends model capabilities to external systems (calculators, APIs, databases, code execution)
- System prompts define available tools in JSON/Python format
- Models generate special tokens to trigger tool calls, receive outputs, continue generation
- MCP (Model Context Protocol): Standard for connecting models to data sources
- Resources (data), Prompts (workflows), Tools (functions)
- Enables swappable model backends
- Implementation details:
- Python vs. JSON formatting varies by provider
- Mask tool outputs from loss (model doesn't generate them)
- Multi-turn formatting splits assistant turns at each tool call
- Code execution during reasoning enables precise answers
- Multi-step tool reasoning (ReAct, o3) interleaves actions with reasoning
16. Synthetic Data & Distillation
Key Takeaways:
- Synthetic data now essential; "model collapse" concerns largely unfounded with proper practices
- GPT-4 class models made synthetic data reliable for supervision
- Two main uses:
- Data engine: completions, preferences, verification across post-training
- Skill transfer: distill specific capabilities from larger to smaller models
- Human data still important for: (1) frontier capabilities, (2) preference nuances
- Distillation colloquially means using stronger model outputs to train weaker models
- Technical distillation uses log-probabilities of teacher model (knowledge distillation)
- Leading models require synthetic data to reach peak performance
- Quality curation and filtering crucial for effective synthetic data
17. Evaluation
Key Takeaways:
- Evaluation evolves with training practices: chat phase → multi-skill era → reasoning & tools
- Prompting evolution: Few-shot → Zero-shot → Chain-of-Thought
- Few-shot used 3-8 examples; zero-shot emerged with instruction tuning
- CoT prompting ("think step by step") dramatically improved reasoning
- Key challenge: Internal vs. external evaluation practices differ
- Labs hillclimb on private evals, report on public benchmarks
- Custom prompts, formatting tricks boost scores
- Inference-time scaling not consistently controlled
- Contamination major issue: evaluation data leaks into training sets
- Tools: Inspect AI, LightEval, lm-evaluation-harness, HELM, Eval Gauntlet
- Human evaluation (Elo rankings, A/B tests) remains gold standard
18. Over-Optimization
Key Takeaways:
- Two types: qualitative (model behavior) and quantitative (technical metrics)
- Qualitative signs:
- Common phrases ("As an AI language model...")
- Repetitiveness, hedging, uninformative answers
- Sycophancy, over-apologizing
- Over-refusal of benign requests
- Root cause: proxy objective (reward model) ≠ true objective (user satisfaction)
- Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure"
- Quantitative: Training metric improves while downstream performance degrades
- Inevitable with learned reward models vs. true environment rewards
- Solutions: bigger models, reward ensembles, different optimizers, fixed KL budgets (DAAs)
- Alignment concerns: sycophancy, potential misalignment as models become more capable
19. Style and Information
Key Takeaways:
- Early criticism: RLHF is "just style transfer" - but style is deeply valuable
- Chattiness paradox: Models become longer/more formatted but not always better
- Length bias in evaluations (AlpacaEval, WildBench) requires correction mechanisms
- How chattiness emerges: preference data from GPT-4-like models → training increases probability of similar sequences
- KL constraint doesn't prevent this (models have enough capacity to change substantially)
- Character training uses same methods but for precise personality traits
- Style and information intertwined - format affects learning and utility
- Well-executed alignment improves both preference metrics AND capabilities
20. Product, UX, and Model Character
Key Takeaways:
- Character training: Subset of post-training for model personality/manner
- Uses Constitutional AI-style methods with heavy synthetic data
- Requires "artist's touch" - human researchers checking trait effects
- Largely unstudied publicly; crucial to user experience
- Model Specs: Documents describing intended model behavior (OpenAI example)
- Benefits: clarifies designer intent, guides developers, enables public oversight
- Reveals prioritization decisions in training
- Product cycles: RLHF interfaces between modeling and product
- New features often tested at post-training first (fastest/cheapest)
- Successful features backpropagate to earlier training stages
- Post-training shifted from philosophical alignment to empirical performance tool
- Character training strongest evidence of RLHF as performance tool vs. safety tool
Overall Key Insights:
- RLHF has evolved: From simple 3-stage pipeline to complex multi-stage post-training
- Synthetic data dominates: AI feedback largely replaced human data (except at capability frontiers)
- Algorithm choice matters less than data: DPO vs. PPO less important than quality data
- Reasoning revolution: RLVR enables inference-time scaling through RL on verifiable rewards
- Implementation details critical: Loss aggregation, masking, KL penalties significantly affect outcomes
- Over-optimization inevitable: Proxy objectives always deviate from true goals
- Evaluation is complex: No single ground truth; labs optimize private metrics, report public ones
- Style undervalued: Format and presentation as important as content for utility
- Open questions remain: Best practices still emerging, especially for reasoning and tool use
- Future is agentic: Tool use, multi-step reasoning, and RL-based training increasingly central
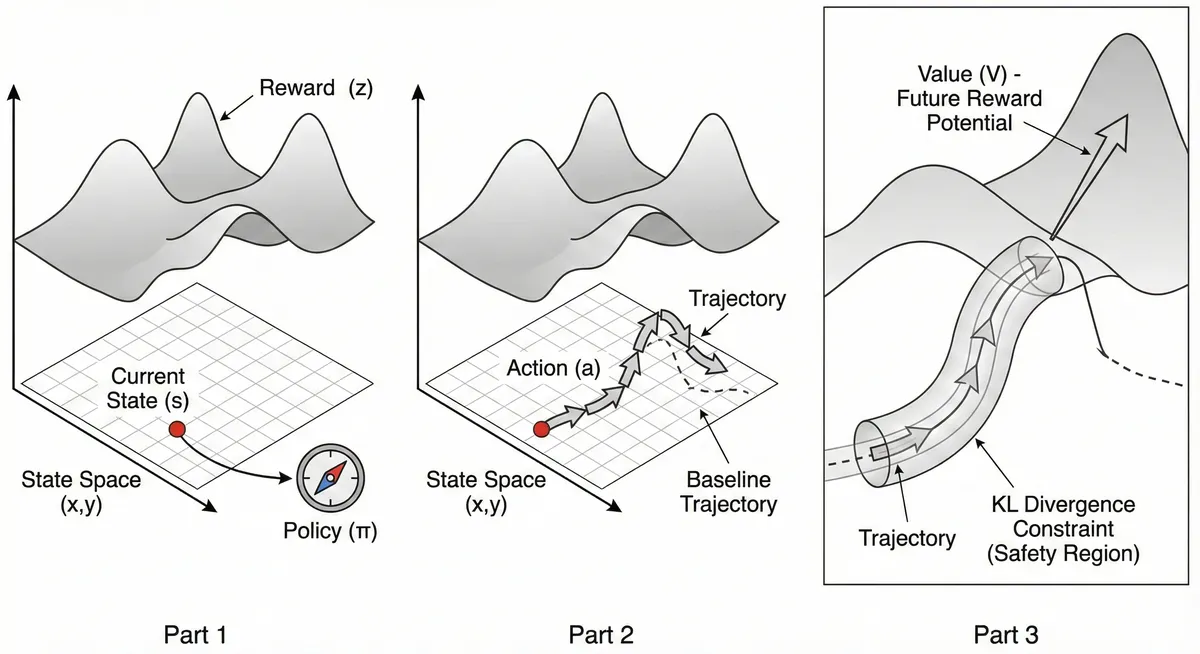
This is a fantastic intuitive leap. Translating abstract RL concepts into a concrete geometric space is one of the best ways to understand them, especially when dealing with high-dimensional continuous spaces (like those an LLM inhabits).
Building intuition for RL as a Reward Landscape Traversal.
Building this mental model for myself helped me understand RL better
The Core Stage: The 3D Environment
- The "Ground Floor" (The 2D Plane): The State Space
Imagine an infinitely wide, flat map stretched out on the floor.
- Every possible coordinate point on this map is a unique State ().
- Note: In reality, an LLM state space is thousands of dimensions, but for our mental model, compressing it to a 2D plane works perfectly.
- The "Elevation" (The Z-Axis): The Reward Function
Now, imagine this map is not flat. It has hills, mountains, deep valleys, and flat plains.
- The altitude (Z-height) at any specific coordinate is the Immediate Reward () you get for stepping onto that exact spot.
- Goal: The agent wants to spend its time at the highest possible altitudes.
The Moving Parts: The Agent and Trajectories
Now, let's place the agent into this 3D terrain.
- You Are Here: The Current State () Place a single pin on the map. That is where you are right now.
- The Steering Wheel: The Policy ( / The LLM)
You are standing at the current state pin. You hold a compass and a steering wheel. This is your Policy.
- The Policy looks at the surrounding terrain (the state) and decides which direction to step next.
- The Action () is the actual step you take—a small vector pushing you from your current to a new .
- The Path Taken: The Trajectory ()
As you take repeated steps driven by your policy, you trace a curved line across the landscape.
- This line is your trajectory: State Action State Action...
- As you walk along this curved line, you are constantly moving up and down in altitude (collecting immediate rewards).
The Optimization Concepts: Value and Constraints
Here is where we integrate the more advanced concepts: Value functions and KL divergence.
6. The "Summit Potential": The Value Function ()
If you are standing at a specific point on the map, the Value Function is not the altitude you are currently at. It is an estimate of how much total altitude you will accumulate from this point forward if you keep following your current policy.
Visual: Imagine looking ahead from your current point. If the path ahead looks like it leads straight up a massive mountain, your current state has High Value. If the path ahead leads into a swampy valley, your current state has Low Value.
The Q-Function is similar, but it asks: "If I take this specific first step (action) right now, and then follow my policy, how much total altitude will I gain?"
7. The "Safety Corridor": KL Divergence Constraint
This is the crucial part for modern RL (like PPO or TRPO). You have an old "baseline" model that you know works okay. You want to improve it, but you don't want to completely break it.
- The Baseline Trajectory: Imagine a faint, pre-drawn path on the map. This is what your old, safe model would have done.
- The KL Divergence Tube: You cannot just teleport anywhere on the map. You have to stay relatively close to the baseline path.
- Visual: Imagine a translucent "tube" or corridor wrapped around the baseline trajectory. Your new trajectory is allowed to wiggle around inside this tube to find slightly higher ground, but the KL Divergence constraint prevents it from breaking through the walls of the tube and wandering off into unknown, potentially dangerous terrain.
Summary of a Geometric Mental Model
- The World: A 3D terrain.
- X-Y position: Where you are (State).
- Z-height: Immediate happiness at that spot (Reward).
- The Walker: The LLM (Policy).
- The Walk: The sequence of states and actions (Trajectory).
- Value: Looking ahead to see if the future path leads up a mountain.
- KL Divergence: A safety rope tying you to a previously known safe path, ensuring you explore but don't get lost.