In this early stage of the AI boom, opportunities are everywhere, but old moats won't hold. Competitive advantages are shifting, but to what? Here's an attempt to trace where new moats might form, what blocks them, and how the game itself will change.
Every LLM breakthrough opens up new markets. As users get used to the capabilities of this new technology, people will become impatient: when AI can already perform tasks that previously required dozens of clicks, why do so many apps still require me to manually click all these buttons? This gap in user expectations has sparked a gold rush. Pioneers are racing to deliver the next generation of AI-native experiences, overturning any software that can be disrupted. People 10 years from now, looking at pre-LLM software, might be like us looking at people using abacuses, unable to imagine how people in the past lived. Programmers who have used Cursor or Claude Code have already lived through this transformation firsthand.
With each LLM update, these transitional solutions might be crushed, or new entrants might flood in to claim a share, or if lucky, become 10x more powerful on the spot, until the cycle repeats. Eventually, frontier models will become infrastructure, and most user-facing products will fully leverage the potential of LLMs.
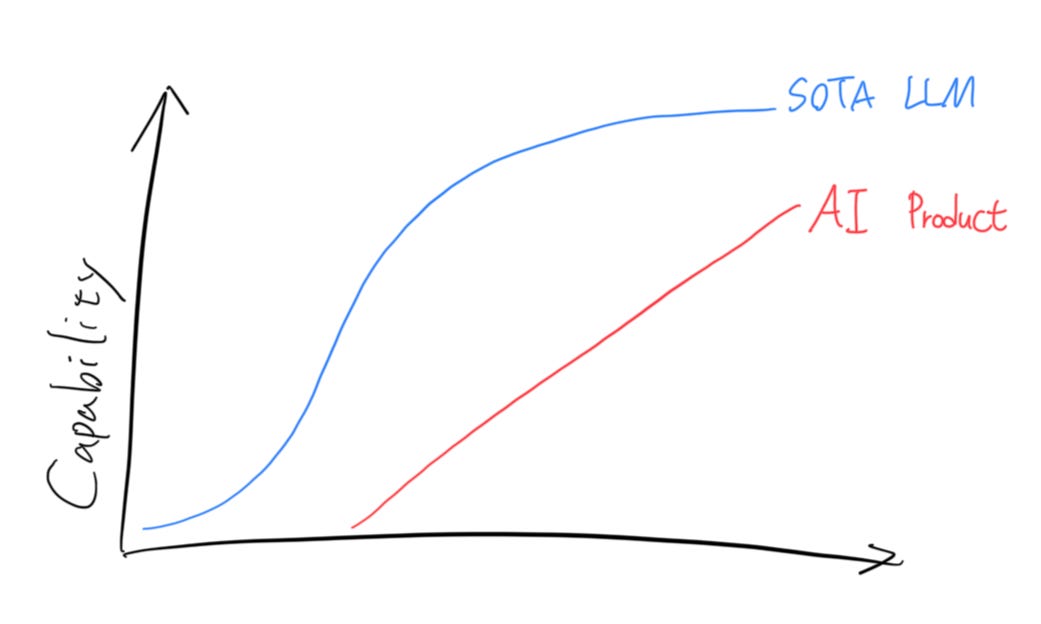
This might be a decade-long process, with some domains faster or slower than others, and it won’t be easy. This is when fast learners without legacy constraints have massive advantages, but these advantages are all temporary. No one can build a moat in this stage.
As competition intensifies, some companies that can solve the bottlenecks of this era and build positive feedback loops will win. What are these key bottlenecks? What kind of flywheels can establish competitive advantages?
We can't possibly see clearly now, but here are some rough ideas.
If the internet lowered distribution costs and connected nodes, individual nodes themselves remained inefficient, until LLMs. The improvement LLMs bring to individual nodes is enormous.
An agent is like a factory that burns tokens into productivity, but it needs valuable problems as feedstock. The more problems it can consume, the more valuable outcomes it can generate. Not giving it enough problems is like wasting an idle factory's capacity.
Taking software as an example, when I'm using ChatGPT Pro plan without worrying about bills exploding, I always feel it's a crime to let Codex sit idle. If I can run multiple agents in parallel, I never run just one; if I can run —yolo continuously for 24 hours, it should never wait for my permission; it should even find problems on its own after tasks end, like completing tests or upgrading libraries, without needing my guidance.

In this simple case, no matter how much it self-evolves, it will ultimately converge to an endpoint. But what if we could find some kind of infinite loop where the problem and answer fuel each other?
For instance, solving a scientific problem, like AlphaFold or some new anti-cancer drug, usually unlocks the next batch of new problems: this drug might bind with an unexpected protein, producing toxicity. How do we solve that? The complexity of biology, the arrangement of elements and microstructures in materials science - these endless challenges instead become goldmines waiting to be developed.
In this loop, output becomes input, and the entire problem space is self-expanding. AI has greater leverage in domains with these infinite problem characteristics. Finding such domains will separate disruptive applications from general tools.
When the continuously surging problems truly transform into infinite output, new bottlenecks appear downstream in this value production chain: how to validate the work, and who is responsible when it fails?
Even if execution capacity multiplies, it’s just one link in the entire chain; now the bottleneck has shifted to verification. Developers need to review shitty code before deployment; pharmaceutical R&D also needs to be able to turn the benefits AI brings into reality in the laboratory.
To clear this blockage, verifiable tasks will be automated; harder ones will need better engineering and design to reduce verification difficulty. What cannot be thoroughly verified will require human intervention, not merely to verify correctness, but to provide something far more crucial, something AI can never offer: accountability.
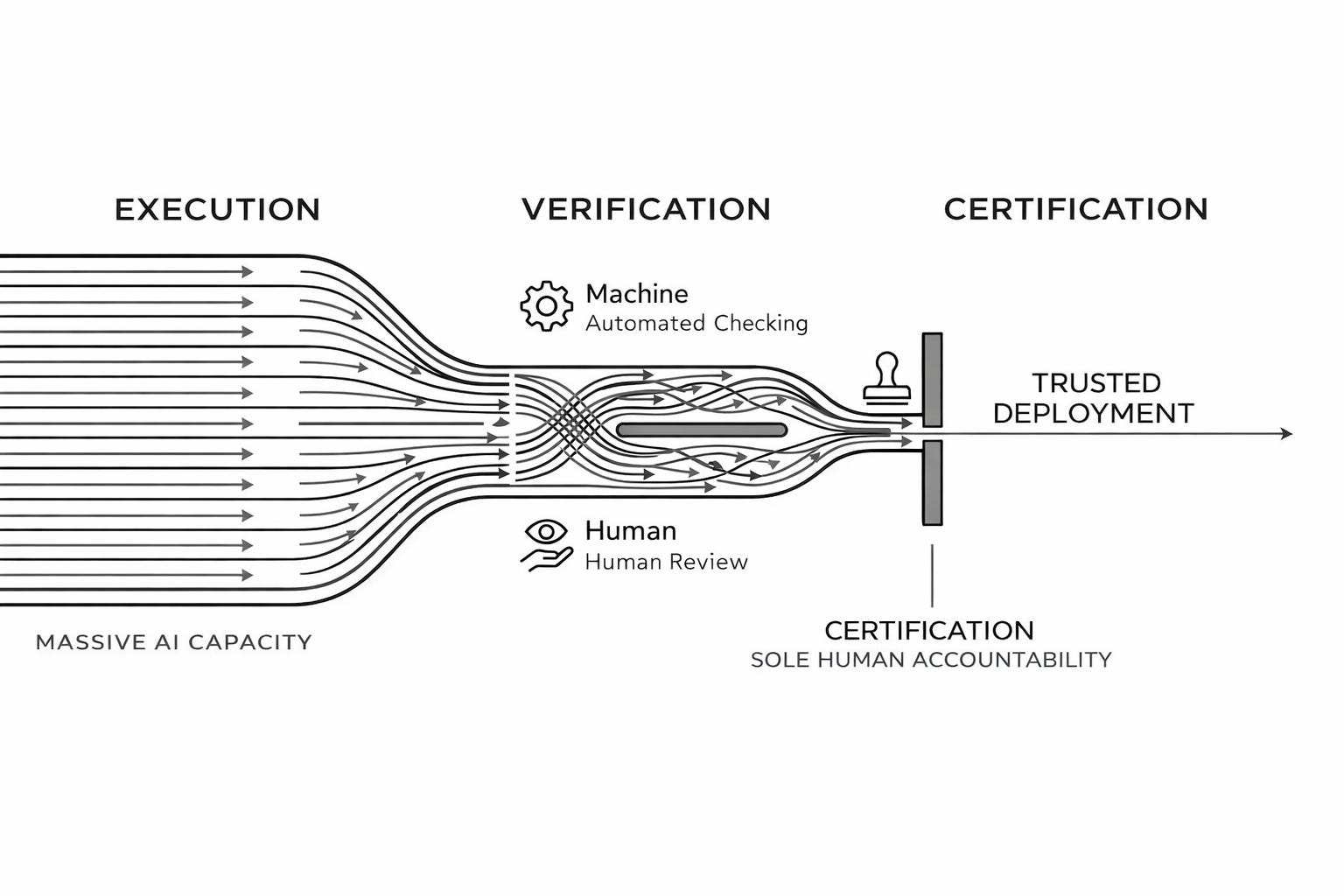
Before LLMs, “whoever does it is responsible” was just an obvious truism. But now, execution and responsibility have decoupled.
AI may do all the work, but we still need someone to sign off, staking their reputation that the output is ready. AI won't be held accountable for failures; humans will. This form of human certification reduces trust costs and enables collaboration across the value chain.
From a consumer perspective, there seems to be no difference. Don't companies always need to gain user trust and bear responsibility? The difference is that when the suppliers remove all constraints and fully leverage AI, supply will explode. What follows is even more significant: those making consumption choices on the demand side are likely no longer human.
Human bandwidth is limited, so the previous generation still needed aggregators to organize massive amounts of information into a list that humans could easily understand. But now, AI often digests information before it reaches users, and it doesn't need to mimic human behavior by sequentially scanning options. It can directly test them, since AI's execution cost approaches zero.
Suppose AI can directly test a hundred solutions, then decide entirely based on performance, or even continuously use different solutions in parallel, do we still need aggregators? With the supply side entering abundant infinite competition, and the demand side correspondingly undergoing qualitative change brought by AI, what will the entire network become? What will be the next bottleneck?