Google just released the #3 ranked AI model in the world for free. It is already running privately on SeqPU. Open Telegram, get your key, and go — whether you want to chat privately, build your own bot, replace Cursor, or run your own AI infrastructure. We meet you exactly where you are.
S
The SeqPU Team
PUBLISHED APRIL 2026 · 8 MIN READ · SEQPU.COM
On April 2, 2026, Google released Gemma 4. Four open-source models, Apache 2.0, free to download, free to run, free to build on. The 31B dense model ranked #3 among every AI model in the world — open or closed. It competes with Claude Sonnet. It beats Gemini 2.5 Pro in blind human preference tests. And it is already live on SeqPU right now, running privately, waiting for you.
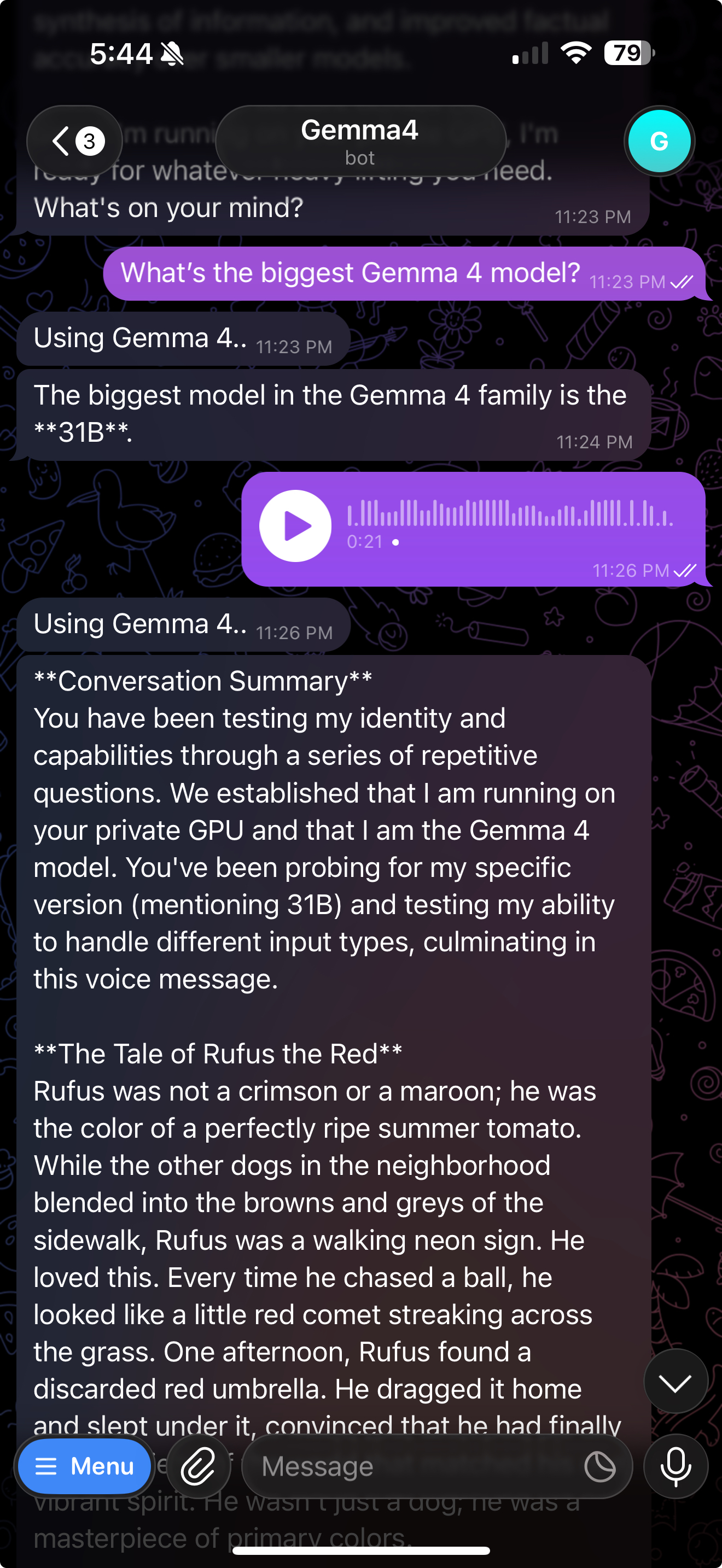
A REAL CONVERSATION WITH OPENGEMMA4BOT — TEXT IN, VOICE MEMO IN, INTELLIGENT RESPONSE OUT. NOBODY ELSE SAW THIS.
That is a real conversation with OpenGemma4Bot happening right now. The user sent a text question. The bot answered. The user sent a 21-second voice memo. The bot heard it, understood it, and responded with a full conversation summary and a story. Text in. Voice in. Nobody else saw it. Not OpenAI. Not Google. Not Anthropic. It happened between a phone and a rented GPU that shut down when it was done.
Here is how you do that in 60 seconds.
Step 1. Go to seqpu.com. Sign up with Google or email. Click API Keys. Click Create. Copy the key.
Step 2. Open Telegram. Go to t.me/OpenGemma4Bot. Send /connect abc123def456hij789klm012nop345qr.access replacing the key with your actual one. The .access at the end is required.
Step 3. Start talking. Send a text. Send a voice memo. Send a photo. You are live on private compute running the #3 AI model in the world.
Four Models. You Pick the Right One.
Every other AI product picks the model for you. ChatGPT gives you GPT-4o. Cursor gives you whatever they negotiated that week. You pay their markup, use their model, and send your data to their servers whether the task needed that much firepower or not.
OpenGemma4Bot gives you four Gemma 4 models and a slash command. You switch between them mid-conversation. The context carries across every switch — the history is stored per chat, not per model.
— Ranked #3 worldwide among all AI models open or closed
The 31B — /use_31b_version
The one that thinks. Deep reasoning, legal analysis, complex code, financial modeling, long-form writing, research synthesis. Competes with Claude Sonnet and GPT-4o in blind preference tests. Running on your rented GPU — nobody sees the conversation, nobody trains on it, the GPU shuts down when it is done.
— $0.01 per message
— Ranked #6 worldwide, fraction of the compute cost
The 26B MoE — /use_26b_version
The smart efficient one. 26 billion total parameters but only a fraction activate per response. Thinks like a large model, costs like a small one. Nearly as capable as the 31B at noticeably lower cost. For professionals who use AI constantly and do not need maximum depth on every single query.
— Fraction of the 31B cost
— Native audio and vision built in
The E4B — /use_4b_version
The one that hears and sees. Send a voice memo and it responds to what you said. Send a photo of a receipt and it reads it. Send a contract and it summarizes it. No transcription step, no second model — it just understands. Smart enough for daily life, cheap enough to forget about the cost entirely.
— $0.003 per message
— Fastest response, lowest cost
The E2B — /use_2b_version
The fast one. Answers in seconds. Costs fractions of a penny. For quick questions, label reading, short translations, simple classifications — anything where speed matters more than depth. The model you use a hundred times a day without thinking about it.
— Fractions of a penny per message
Here is what switching looks like in practice. You are chatting on /use_2b_version — quick questions, instant answers, fractions of a penny. A client sends you a contract photo. You type /use_31b_version and send it. The 31B — ranked #3 in the world — reads the full contract and walks you through exactly what it says. You switch back to /use_2b_version for the rest of the day. Same conversation. Right tool for each moment. You just used the most powerful open AI model in the world for one message and paid a penny.
#3Gemma 4 31B world ranking among all AI models open or closed
4Models in one bot — fastest 2B to most powerful 31B
$0.003Per message on the 4B model with native voice and vision
60 secFrom zero to live on the #3 AI model in the world
Here Is How We Built This on SeqPU
The bot you just tried — OpenGemma4Bot — took ten minutes to build. Here is exactly what that looked like. Every step. Every screen. So you can see precisely what SeqPU is and what it means to build on it.
We opened the notebook. SeqPU gives you a notebook — a workspace where your script lives and runs. We selected the Gemma 4 base image from the Custom Image panel. We picked the A100 80GB GPU tier from the row of hardware options across the top. The console confirmed: Loaded Gemma 4 31B. Ready to execute. System online. GPU pool available.
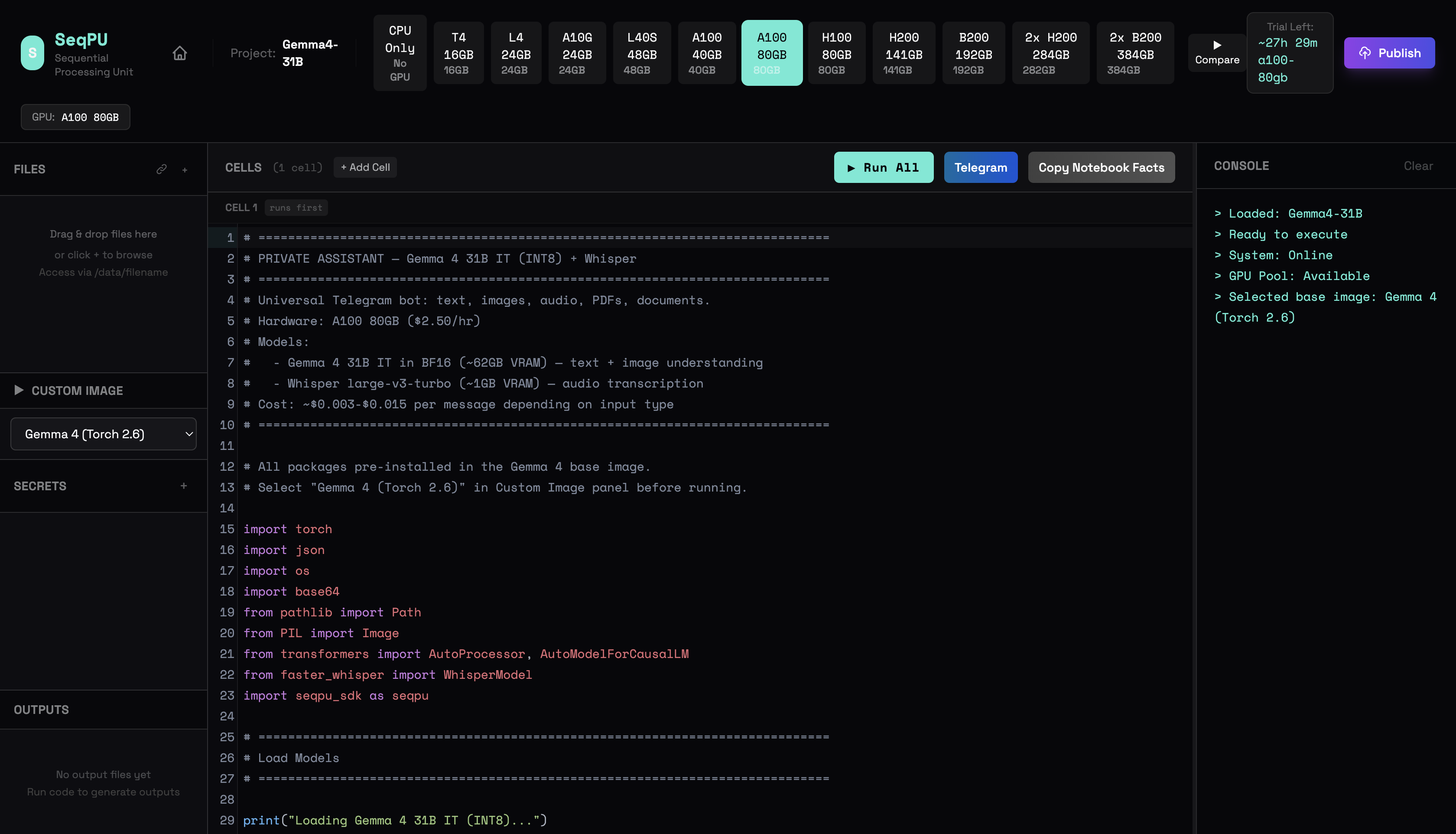
The script was already there. The Gemma 4 template comes pre-loaded — Gemma 4 31B in INT8 plus Whisper large-v3-turbo for audio transcription. Text, images, audio, PDFs, documents — all handled. We added the system prompt, the welcome message, the model switching logic. The script handles everything: receiving a Telegram message in the task variable, running it through the model, sending the response back via seqpu.notify().
We clicked Telegram. The platform ran two checks. Does the script receive the user’s message? Does it send a response back? Two green checks. Ready.
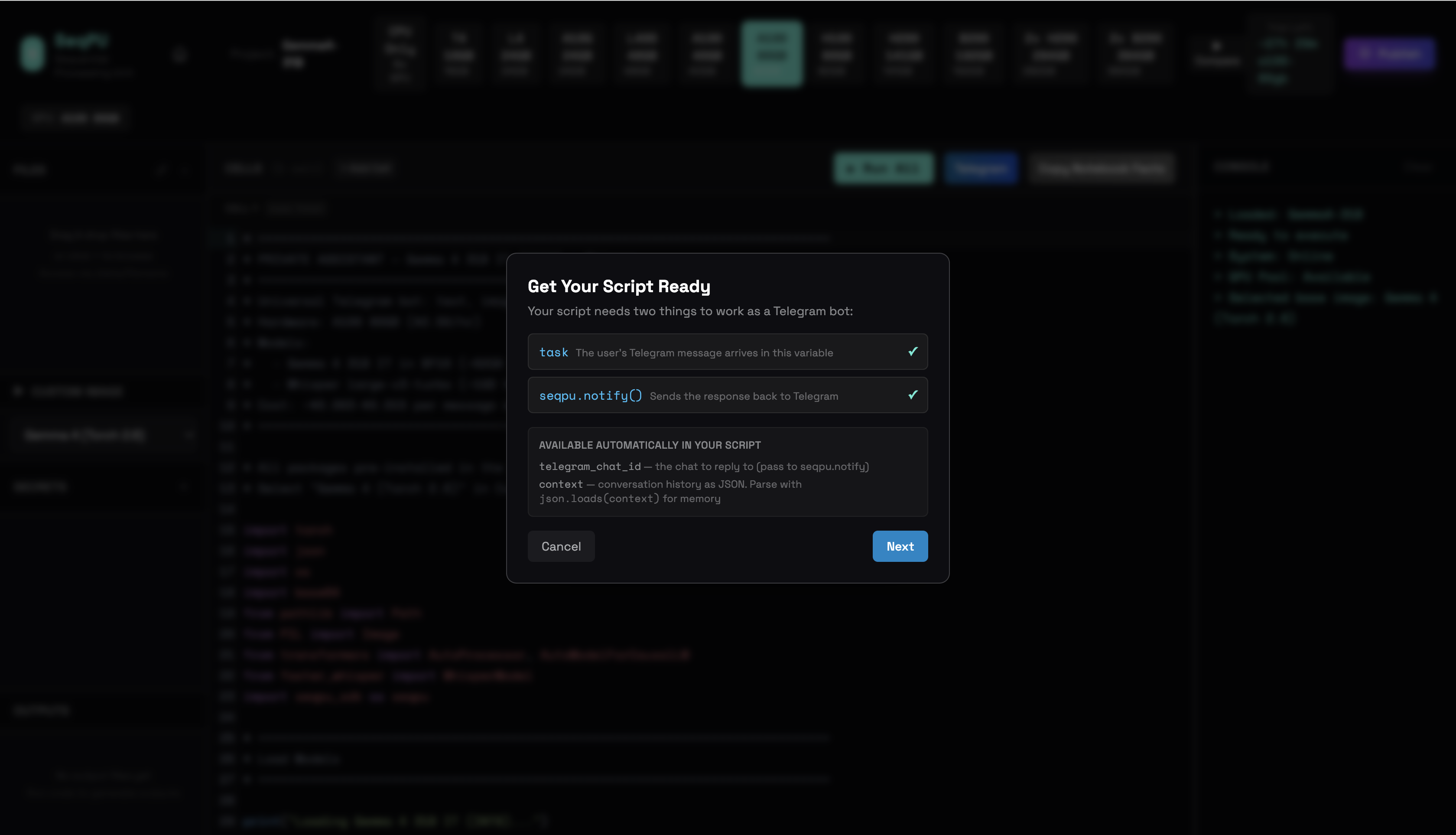
We pasted the BotFather token. Open Telegram. Search @BotFather. Send /newbot. Pick a name. Copy the token BotFather gives you. Paste it into SeqPU. Click Connect Bot.
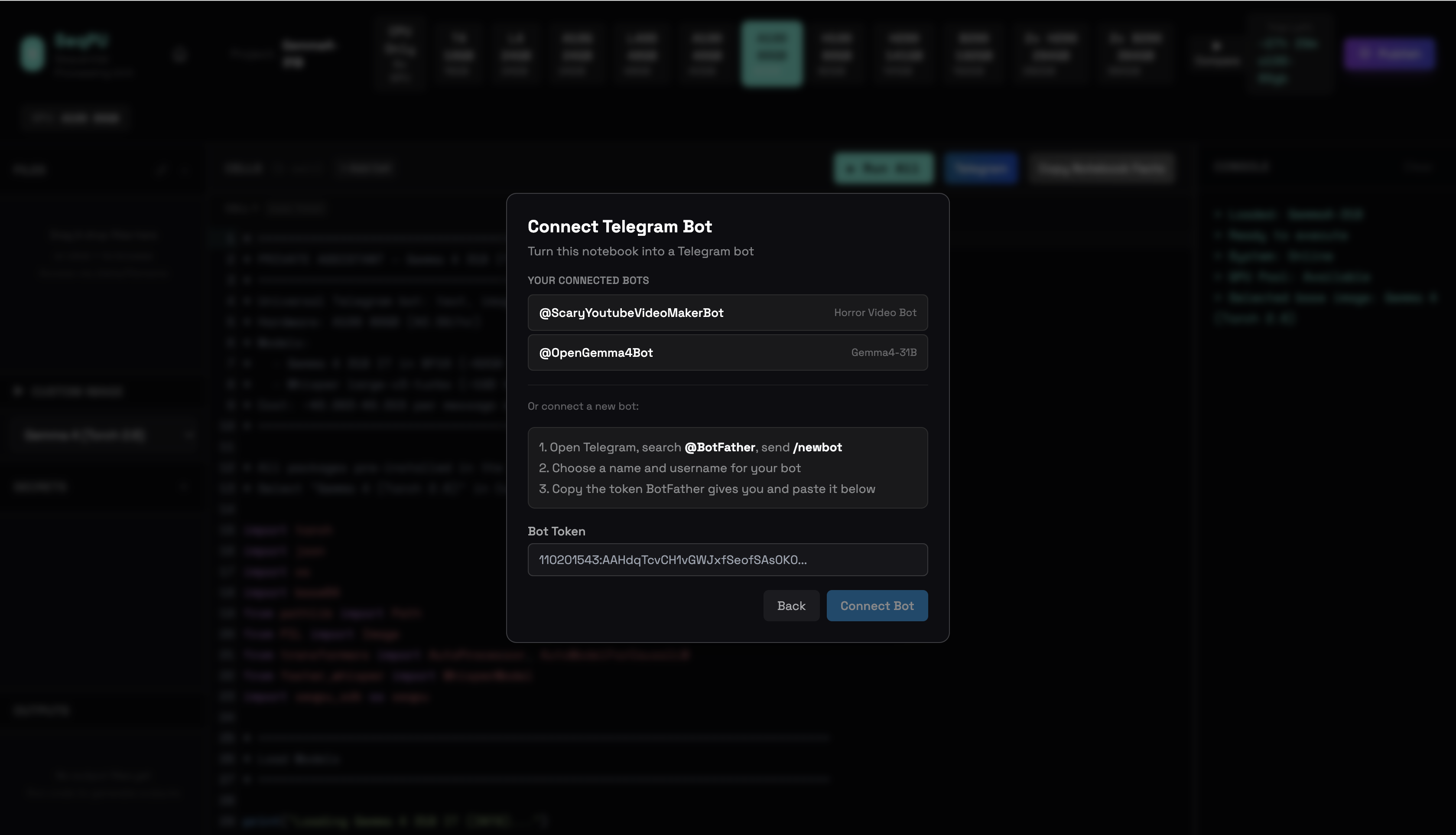
We mapped the four models to slash commands. The configuration panel lets you set a system prompt, a welcome message, and map slash commands to tools. We mapped /use_2b_version to Gemma4-2B, /use_4b_version to Gemma4-4B, /use_26b_version to Gemma4-26B, /use_31b_version to Gemma4-31B. Click Done.
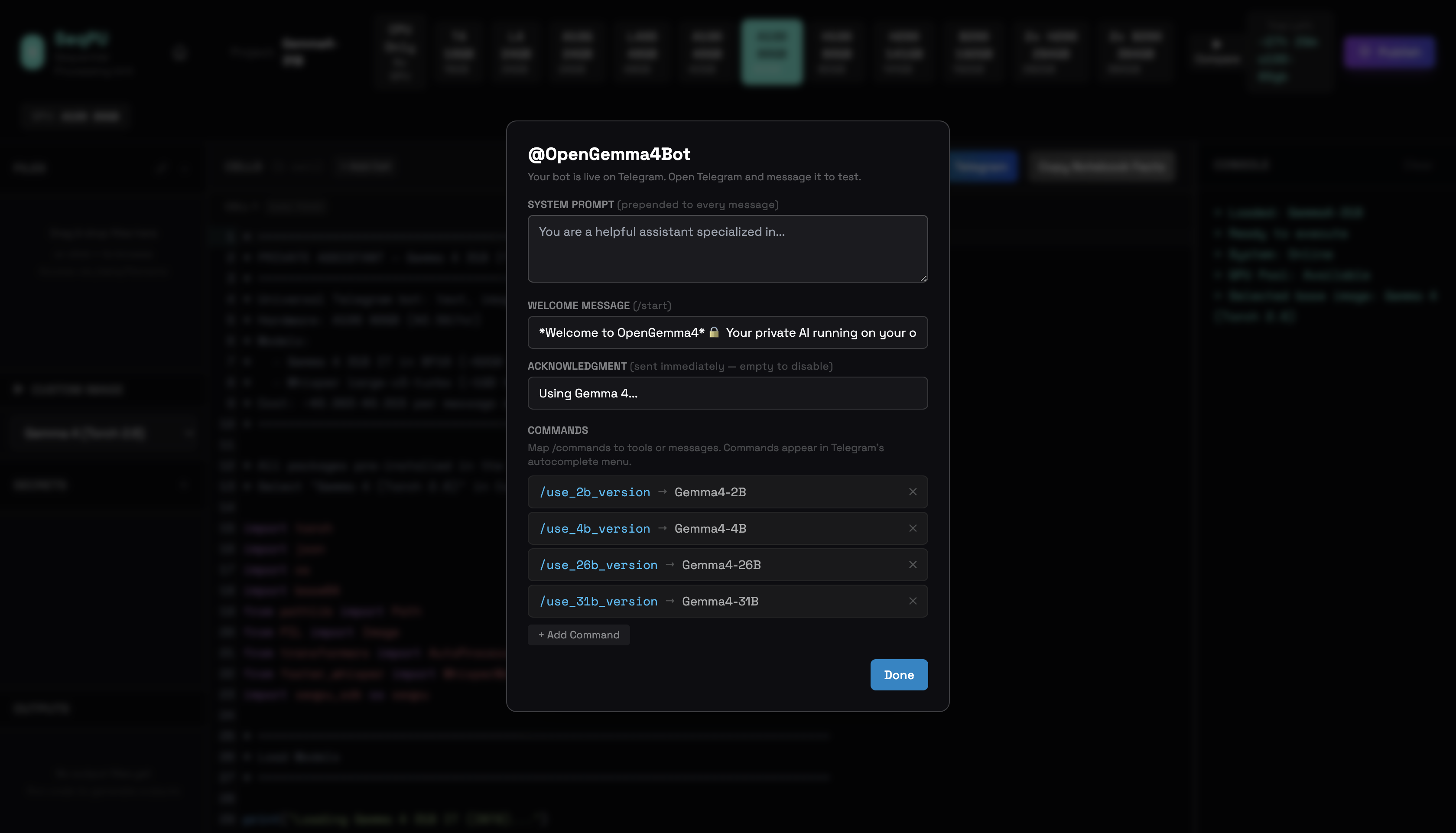
The bot was live. Ten minutes from opening the notebook to a working private multi-model Gemma 4 bot on Telegram. No server to manage. No infrastructure to maintain. No third party in between. The same process works for any bot you want to build — a dinner planner, a legal research assistant, a private coding tool, a morning briefing bot. The template changes. The steps are identical.
How visitors connect to your bot. Share your bot’s Telegram username. They sign up at seqpu.com, click API Keys, create one in 30 seconds, and send /connect with their key. Their usage bills to their own account. You pay nothing for their messages. Their usage bills to their own account. You pay nothing. You built it. It runs. They use it.
Your Data Is Not Safe on Anyone Else’s API
When you send a message to ChatGPT it goes to OpenAI’s servers. When you send code to Cursor it goes to Anthropic or OpenAI. When you use any AI API — OpenRouter, HuggingFace, Google AI Studio — your data goes through someone else’s infrastructure. Their privacy policy governs what happens to it. Their engineers can access it. Their legal team can produce it in a subpoena. And in most cases your data is being used to make their next model smarter whether you agreed to it consciously or just clicked accept.
This is not a conspiracy theory. It is the business model. Your data has value to them. That is why the tool is cheap or free. You are paying with your information even when you are also paying with your money.
It does not matter what the privacy policy says. If your request goes through someone else’s server, your data was on someone else’s server. There is exactly one architecture where that is not true: your server talking to your server.
On SeqPU your message goes from your device to a GPU you rented. The GPU runs the model. The response comes back. The GPU shuts down. Not stored on our servers. Not logged for training. Not accessible to anyone else. Not subject to anyone’s terms changing next quarter. Your server talking to your server. That is the whole architecture.
We Meet You Where You Are
The same platform. The same private compute. The same bot you just tried. For every person on this spectrum.
You just want a private AI to chat with. You already did it. You connected the bot, you are talking to the #3 AI model in the world privately for fractions of a penny a message. Send it anything you would never send ChatGPT because you know ChatGPT saves everything. This conversation does not leave your Telegram. You never need to read anything else in this article.
You want your own bot. The section above shows you exactly how we built OpenGemma4Bot — open the notebook, load the template, click Telegram, paste your BotFather token, map your commands, connect. The same ten minute process works for any bot you want to build. We publish 50 ready-made templates — voice transcriber, dinner planner, homework helper, meeting analyzer, morning briefing, receipt logger. Pick one, copy it to your notebook, connect it. Or describe what you want to Claude in plain English and paste what it writes. You never write a line of code.
You want to replace Cursor. Publish your Gemma 4 notebook as a headless API on SeqPU. Open Cursor settings, go to Models, paste your SeqPU endpoint in the Override OpenAI Base URL field. Every autocomplete, every chat, every agentic task now runs on your private Gemma 4 instance. Your code never leaves your GPU. Same IDE. Same experience. Fractions of the cost. Zero data on anyone else’s servers.
You want to run your agent stack on open models. You are using OpenClaw, LangChain, CrewAI, or your own framework and paying GPT-4 API prices. Point your agent framework at your SeqPU endpoint. Run Gemma 4 31B as your agent brain. Pay for the seconds of compute it actually uses. The framework is free. The model is free. The only thing you pay for is the compute you use.
You want to publish a headless API and charge for it. You built something specialized on top of Gemma 4. Publish it as a SeqPU endpoint. The people using it authenticate with their own SeqPU accounts and their usage bills to their own accounts. You charge for the specialized tool you built. The model is free. The infrastructure is pay-per-second. What you built is yours.
You want to be the compute layer for your clients. No server farm. No capital expenditure. SeqPU handles the infrastructure. You handle the relationship and the value you built on top of it.
And here is what most people miss regardless of which path they take: there is almost always a better cost-per-dollar option than the one you defaulted into. A Cloudflare AI Worker running a small model at the edge for $0.000001 per invocation for routing. Whisper Base on a T4 for audio at less than a penny per minute. A Nvidia NIM endpoint for specific tasks at a fraction of GPT-4 prices. SeqPU shows you the options and what they cost. You never have to figure it out yourself.
ChatGPT Plus
$20/month
OpenAI
Otter.ai
$20/month
Their cloud
GitHub Copilot
$30/month
Microsoft
Google Gemini
“Free”
Google. You are the product.
Your SeqPU bots
Under $1/month
Nobody. Only you. Ever.
A family running six private bots — voice-to-do, dinner planner, homework helper, morning briefing, receipt logger, family calendar — pays under a dollar a month. Every conversation is an encrypted chat between your phone and your rented server. Nobody in between. Nobody listening. Nobody training on what your kid asked for homework help or what medication you’re taking or how much you spent on groceries. Not using it? $0. Literally zero. No subscriptions. No idle charges. No monthly fee for the privilege of being someone else’s training data.
You used to need to own a server farm to play at this level. Now you need a SeqPU account. The ceiling is gone.
Why This Is Bigger Than One Bot
For twenty years the hyperscalers won because they owned the compute. Google, Microsoft, Amazon, OpenAI — they built their advantage on two things: access to the best models and access to the best hardware. Both of those advantages are eroding simultaneously. The models are becoming open. Gemma 4 31B is ranked #3 in the world and it is free. The hardware is available by the second through SeqPU.
The only thing left is the platform that makes it usable — that takes a free model and pay-per-second compute and turns it into something a person who has never seen a terminal can chat with privately and a developer can wire into their entire stack. That is what SeqPU is. Not a model. Not a GPU rental. The compute layer that democratizes the game.
Private AI chat
$20/month, your data on their servers
Fractions of a penny, your GPU only
Your own bot
Months of engineering, cloud bills
10 minutes, template already written
Replace Cursor
Your code on Anthropic servers
Your code on your GPU, same IDE
Agent stack on open models
GPT-4 API prices every call
Seconds of compute, open model cost
Publish a headless API
Build your own infra or use their platform
Publish from the notebook, done
Private infra for clients
Server farm, capex, engineering team
SeqPU account, ten minutes
The Window Is Short
Google's new Gemma 4 dropped April 2nd. The people building on top of it right now are a small group who moved fast. In six months every AI company will have wrapped these models in a subscription, marked up the compute, and started training on the data their users generate. The window where you can get here first — before the hyperscalers commoditize it, before everyone is paying a monthly fee to access a model that is currently free — is open right now.
The person who just wants to chat privately gets a better deal than anything they are currently paying for. The developer who replaces Cursor cuts their bill and removes their code from Anthropic’s servers. The builder who publishes a headless API captures value the hyperscalers would have captured. Every person on the spectrum benefits from moving now rather than later.
All of them start at the same place. t.me/OpenGemma4Bot. A SeqPU account. An API key. Sixty seconds.
The model is free. The compute is by the second. What you build on top of it is yours to keep. The only question is whether you move before or after the subscriptions start.
The #3 AI model in the world is free and already running privately on SeqPU. From chatting privately to running your own distributed compute infrastructure — we meet you exactly where you are. The ceiling is gone. That is SeqPU.
Talk to Gemma 4 in 60 seconds.
Open Telegram. Go to t.me/OpenGemma4Bot. Sign up at seqpu.com, get your API key, send /connect yourkey.access.
Then go as far as you want.