1KAIST AI 2NAVER AI Lab 3SNU AIIS
*: Equal contribution †: Co-corresponding authors ‡: Work conducted as part of the NAVER Cloud Residency Program
AI-Generated Video by SWM
TL;DR
What if a world model could render not an imagined place, but the real city outside your window? We built Seoul World Model (SWM), grounded in the actual streets of Seoul. Through RAG on millions of street-view images, SWM produces faithful videos spanning kilometers of real cityscape.
Roaming the City for Kilometers
Grounded in a real city, SWM generates videos over multi-kilometer trajectories without accumulating errors, maintaining robust performance across long-horizon generation.
20x speed AI-Generated Video by SWM
Text-Prompted Scenario Control
SWM also allows users to reshape familiar city scenes through text prompts: summon a massive wave onto the streets, drop Godzilla between skyscrapers, or imagine any scenario you like.
AI-Generated Video by SWM
World Model RAG with Street-View Database
SWM performs retrieval-augmented generation: given geographic coordinates, camera actions, and text prompts, it retrieves nearby street-view images and conditions generation on complementary geometric and appearance references. This anchors each generated chunk to the real layout and appearance of the location.
AI-Generated Video by SWM
Data Overview
SWM is trained on aligned pairs of street-view references and target video sequences from two sources: 1.2M real panoramic images captured across Seoul, and 10K synthetic videos from a Unreal Engine-based CARLA urban simulator spanning 431,500m² of city area.

Cross-Temporal Pairing & Street-View Interpolation
Cross-temporal pairing requires that reference street-view images be captured at a different time from the target, forcing the model to rely on persistent spatial structure and ignore transient objects like vehicles. As shown below (left), the trained model attends to scene geometry rather than dynamic content in the references. View interpolation (right) synthesizes smooth training videos from sparse street-view keyframes (5–20m apart) using an Intermittent Freeze-Frame strategy matched to the 3D VAE's temporal stride.
 Attention Visualization under Cross-Temporal Pairing
Attention Visualization under Cross-Temporal Pairing
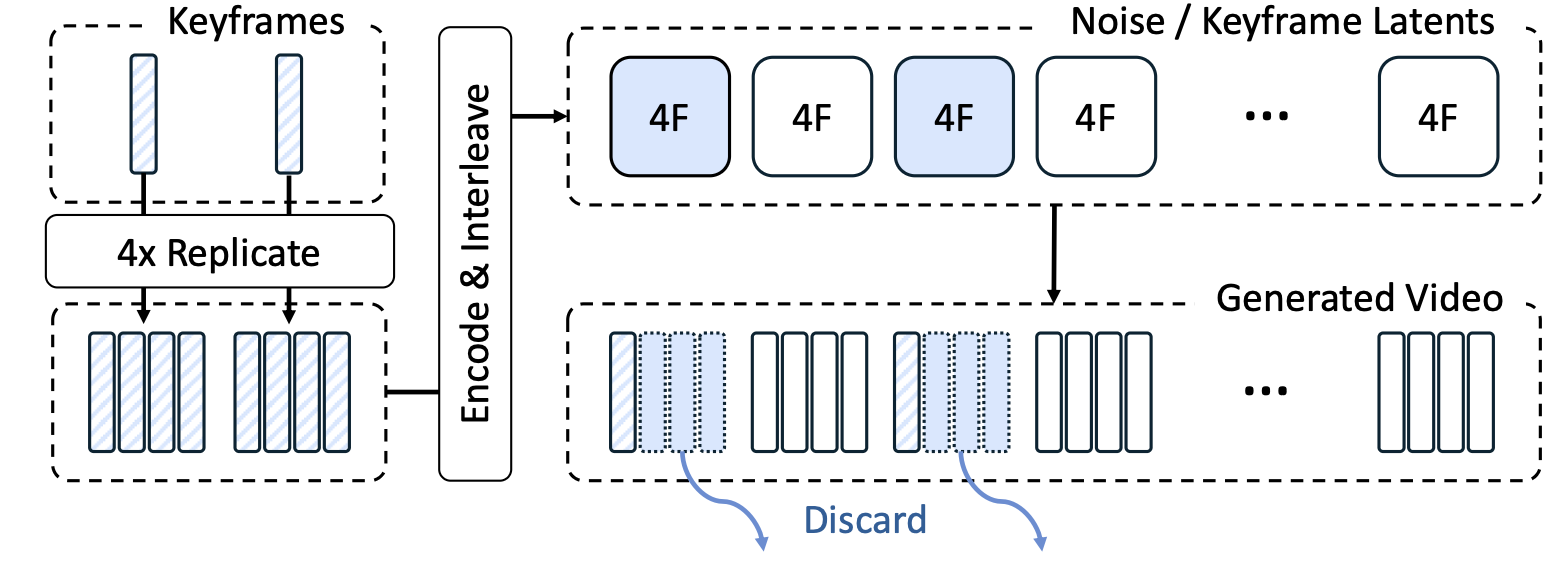 Street-View Interpolation Model
Street-View Interpolation Model
Without cross-temporal pairing, dynamic objects in the reference (e.g., vehicles) leak into the generated video. Temporal separation forces the model to focus on persistent scene structure.
Unreal Engine-based Synthetic Data
To complement driving-only real trajectories, we render synthetic data from CARLA simulator with three trajectory types: pedestrian (sidewalks, crossings), vehicle (highways, urban roads), and free-camera (arbitrary collision-free paths). This diversity enables SWM to handle arbitrary camera movements at inference.
Examples of synthetic training data
Synthetic data with diverse camera paths allows SWM to generalize beyond forward-driving trajectories, as shown in the comparison below.
Model Overview
SWM autoregressively generates video chunks conditioned on a text prompt, camera trajectory, and street-view images retrieved from a geo-indexed street-view database.
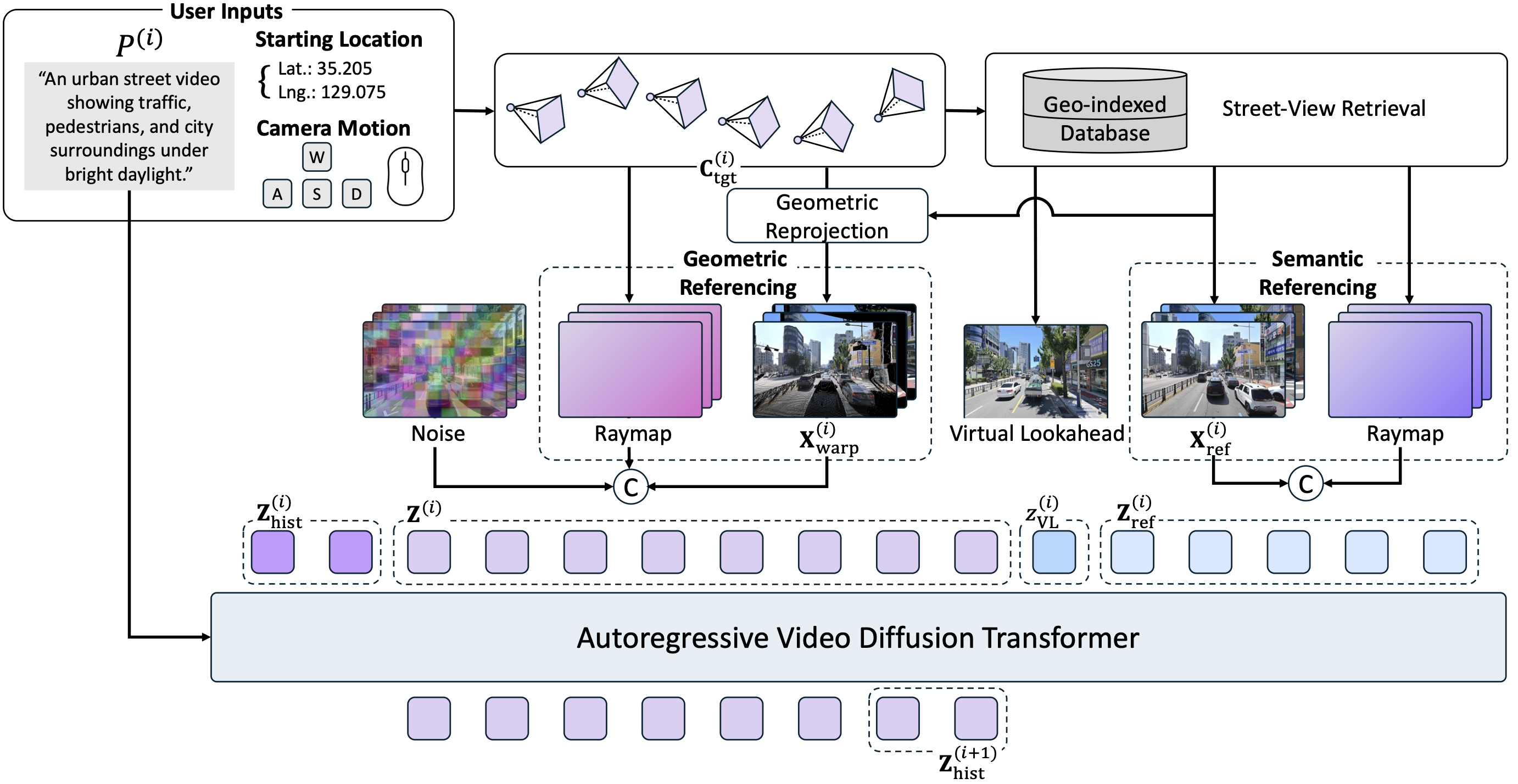
Retrieval & Referencing
For each generation chunk, nearby street-view images are retrieved via nearest-neighbor search and depth-based reprojection filtering. These references condition generation through two complementary pathways: geometric referencing warps the nearest reference into the target viewpoint via depth-based splatting to provide spatial layout cues, while semantic referencing injects original reference images into the transformer's latent sequence so the model can attend to appearance details across all references.
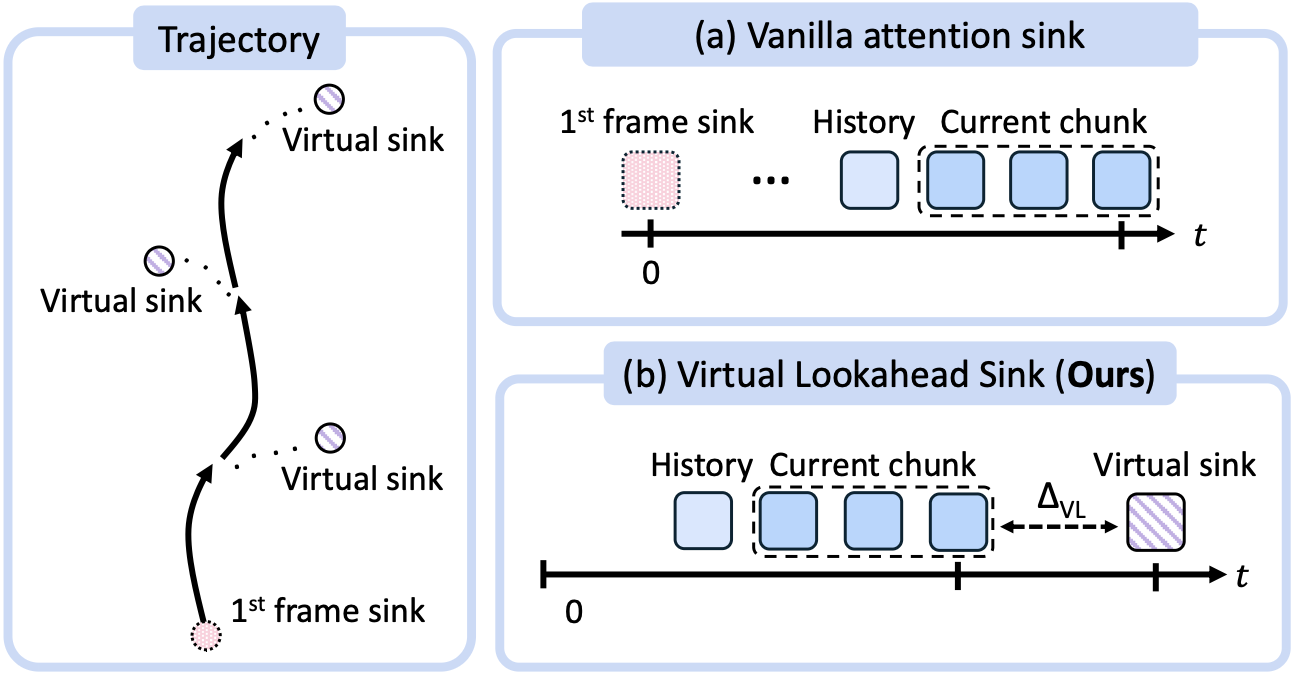
Virtual Lookahead Sink
Autoregressive generation accumulates errors over long horizons. Prior methods (a) use a static attention sink anchored to the initial frame, whose guidance weakens as the camera moves farther away. Our Virtual Lookahead (VL) Sink (b) dynamically retrieves the nearest street-view image as a virtual future destination, providing a clean, error-free anchor ahead of the current chunk. This continuously re-grounds generation, stabilizing video quality over trajectories spanning hundreds of meters. The comparison below shows that VL Sink effectively prevents quality degradation in long-horizon generation.
Abstract
What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
Citation
@article{seo2026grounding, title={Grounding World Simulation Models in a Real-World Metropolis}, author={Seo, Junyoung and Choi, Hyunwook and Kwon, Minkyung and Choi, Jinhyeok and Jin, Siyoon and Lee, Gayoung and Kim, Junho and Lee, JoungBin and Gu, Geonmo and Han, Dongyoon and others}, journal={arXiv preprint arXiv:2603.15583}, year={2026} }
@article{seo2026grounding,
title={Grounding World Simulation Models in a Real-World Metropolis},
author={Seo, Junyoung and Choi, Hyunwook and Kwon, Minkyung and Choi, Jinhyeok and Jin, Siyoon and Lee, Gayoung and Kim, Junho and Lee, JoungBin and Gu, Geonmo and Han, Dongyoon and others},
journal={arXiv preprint arXiv:2603.15583},
year={2026}
}This work is an industry-academic collaboration between NAVER and KAIST, utilizing NAVER Map data.
Acknowledgements
We would like to sincerely thank everyone at NAVER and NAVER Cloud who contributed their time, expertise, and feedback throughout this work. We are grateful to Jinbae Im, Moonbin Yim, and Bado Lee for their help with data preprocessing. We also thank Jongchae Na, Hyunjoon Cho, Hochul Hwang, MyoungSuk Chae, and Kwangkean Kim for their support with data processing and guidance on the use of map data and metadata. Finally, we thank Jonghak Kim, Jieun Shin, and Hyeeun Shin for valuable discussions and thoughtful feedback. Their support and collaboration are greatly appreciated.
