GEPA, a genetic prompt optimizer released in July 2025, outperforms Group Relative Policy Optimization (GRPO) by 10% on average across four benchmarks: HotpotQA, IFBench, HOVER, and PUPA. On HotpotQA, the gap reaches 20%. GEPA achieves these results while using up to 35 times fewer rollouts than the RL approach.
What's a rollout? In RL fine-tuning, a rollout means generating a complete response and computing its reward.
This challenges a common intuition. When you want to improve an LLM's performance on a task, you update the weights. You collect preference data, run RLHF or DPO or GRPO, and bake the improvements into the model itself. Prompt engineering feels like what you do before you have the resources to properly train.
But what if the prompt is not a workaround? What if it's an optimization surface in its own right, one that can be searched systematically, and one that sometimes yields better results than touching the weights at all?
GEPA builds on a lineage of "LLMs as optimizers" research that started gaining momentum in 2023.
OPRO (September 2023) was Google DeepMind's first serious attempt at using an LLM as a mutation operator in prompt search. The idea: instead of manually iterating on prompts, let the model propose new versions based on previous prompts and their scores. On GSM8K (grade school math), OPRO-optimized prompts outperformed human-designed ones by up to 8%. On Big-Bench Hard tasks, the improvement reached 50%.
OPRO had a limitation. It worked well with large models (70B+ parameters) but struggled with smaller ones. The optimization signal from numeric scores alone wasn't rich enough for models with less reasoning capacity.
MIPRO (June 2024) addressed this by optimizing both instructions and few-shot examples jointly. Developed as part of the DSPy framework at Stanford, MIPRO used Bayesian optimization to search the space of instruction + demonstration combinations. (Specifically, Tree-structured Parzen Estimators, which build probabilistic models of which parameter combinations work, focusing search on promising regions) With Llama-3-8B, MIPRO delivered up to 13% improvements over baseline optimizers.
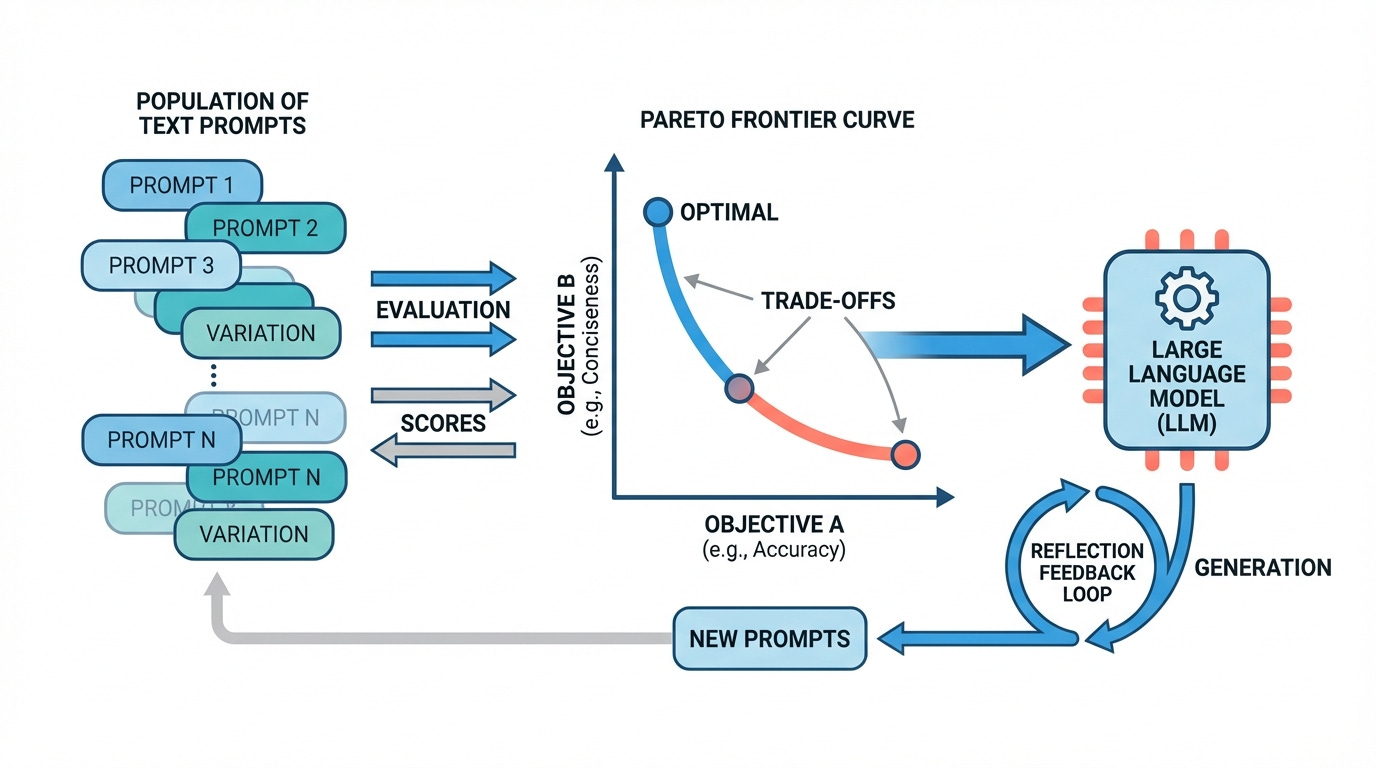
GEPA (July 2025) takes a different approach. Instead of Bayesian search over discrete combinations, it uses genetic algorithms with two key innovations: reflective prompt evolution and Pareto-optimal selection.
The results across four DSPy benchmarks: GEPA beats MIPROv2 by 14% aggregate improvement, more than doubling the gains MIPROv2 achieved over simpler optimizers.
Standard genetic algorithms for prompts work like this: maintain a population, score each candidate, select the best, mutate, repeat. OPRO added a twist by using an LLM as the mutation operator.
GEPA adds something more fundamental. When it mutates a prompt, it doesn't just pass the current instruction and its score to the LLM. It provides a structured trace:
The current instruction
A batch of input examples
The outputs the model produced
Textual feedback on what went wrong
The textual feedback is generated by prompting the LLM to critique its own outputs against ground truth, producing natural language descriptions of errors. The mutation prompt then looks something like: "The following are examples of different task inputs provided to the assistant along with the assistant's response for each of them and some feedback on how the assistant's response could be better".
This is reflective prompt evolution. The LLM isn't pattern-matching against score distributions. It's reasoning about specific failures and proposing targeted fixes. If the model kept missing edge cases in date parsing, the feedback says so. The mutation can then propose adding explicit handling for that class of inputs.
Why this matters for optimization geometry. Gradient descent on weights makes small, local updates. Each step is a tiny movement in a high-dimensional space. Prompt changes operate differently. A single word can shift the model's behavior dramatically. The optimization landscape is discrete, high-variance, and full of surprising discontinuities.
The paper authors describe it as "coarse grain jumps along the optimization space compared to gradient descent being fine grain movements". Reflective evolution enables those coarse jumps to be directed rather than random.
Pareto-optimal selection prevents collapse. A naive approach would keep only the best-scoring prompt each generation. GEPA instead maintains a Pareto frontier: the set of prompts that score highest on at least one evaluation sample.
Prompt A might excel on formal queries.
Prompt B might handle ambiguous inputs better.
Instead of forcing a choice, GEPA keeps both and samples from the frontier with probability proportional to coverage. This preserves diversity and enables the algorithm to escape local optima.
For multi-module DSPy programs (a generator feeding a critic feeding a ranker), GEPA uses "system-aware merge". When combining two candidate systems, it respects which modules were mutated when, ensuring useful mutations don't get overwritten by cross-pollination from an earlier generation.
In February 2024, VMware researchers Rick Battle and Teja Gollapudi published a paper titled "The Unreasonable Effectiveness of Eccentric Automatic Prompts".
They tested 60 combinations of system messages on Llama2-70B for GSM8K. The highest-performing prompt was not a careful, formal instruction. It was this:
"Command, we need you to plot a course through this turbulence and locate the source of the anomaly. Use all available data and your expertise to guide us through this challenging situation."
The model was asked to frame its answers as entries in a captain's log. Star Trek. Math problems. And it worked.
Battle speculated on why: "There's a ton of information about Star Trek on the internet, and it often pops up along with other correct information." The captain's log format might activate reasoning patterns associated with careful, analytical thinking.
The point for our purposes: prompt space is vast, discontinuous, and counterintuitive. Systematic search finds solutions that hand-crafting never would. Whether GEPA's Pareto selection actually discovers similarly eccentric prompts in practice remains an open research question, but the mechanism could preserve unconventional candidates that score poorly on average but excel on specific inputs.
What GRPO actually does. Group Relative Policy Optimization, introduced by DeepSeek, is an RL algorithm for LLM alignment. Unlike PPO (which requires a separate critic model as large as the policy), GRPO compares responses within a batch directly. This eliminates the critic, reducing memory and compute overhead by roughly 50%.
GRPO updates the model's weights. After training, the improved behavior is baked into the model itself. This is fundamentally different from prompt optimization, where the model stays frozen and the behavior change comes from the input.
A recent finding complicates the picture. Research published in October 2025 showed that "Your GRPO Is Secretly DPO". The paper introduced 2-GRPO, a minimal two-sample version that matches the performance of standard 16-sample GRPO while cutting training time by 70%. The RL landscape is still shifting.
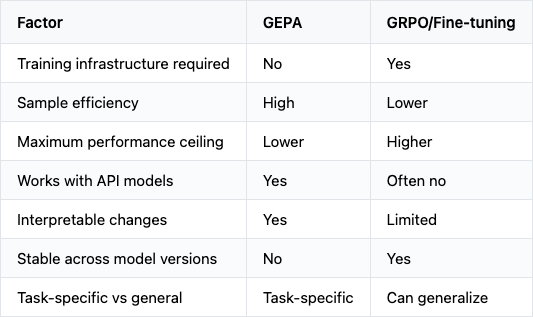
Where GEPA wins. Sample efficiency is the clearest advantage. GEPA achieves comparable or better results with 35x fewer rollouts. For teams without dedicated training infrastructure, this matters.
Interpretability is another factor. A GEPA-evolved prompt can be inspected. You can read the mutations, understand why the algorithm made changes, even manually edit the result. Weight updates are harder to interpret.
And prompt optimization doesn't touch the model. You can run GEPA on API-accessed models where fine-tuning isn't an option.
Where GRPO/fine-tuning still wins. If you need maximum performance and have the resources, weight updates have a higher ceiling. Fine-tuning can inject domain knowledge that prompts can't express. And trained behaviors are stable across prompts, whereas GEPA's optimized prompts might not transfer to different phrasings of the same task.
A decision framework:
GEPA optimization for a typical task:
10 generations x 8 population x 50 evaluation samples = 4,000 LLM calls
At $0.03/1K tokens, ~500 tokens average: $60-200 per optimization run
Optimized prompts are often 2-3x longer, increasing inference cost
GRPO fine-tuning (estimated):
One-time cost: $500-2000 in compute for a 7B model
Inference: same cost as base model
Break-even vs GEPA: depends on inference volume
For API users without fine-tuning access, GEPA is often the only option. For self-hosted models with training infrastructure, fine-tuning can win on economics at scale.
Optimized prompts are brittle. This is the elephant in the room.
What can break:
Model version updates (GPT-5.1 to GPT-5.2): Performance can degrade significantly
Temperature changes: Even small adjustments affect behavior
Context additions: Adding unrelated context can destabilize optimized prompts
Mitigation strategies:
Re-run GEPA periodically to adapt to model updates
Maintain a test suite to detect prompt degradation before production impact
Use ensemble of multiple optimized prompts and vote/aggregate
Consider hybrid approach: GEPA for exploration, then distill insights into fine-tuned model
Fine-tuned behaviors don't have this problem. The improvements are baked into weights that don't change unless you retrain.
When to consider GEPA:
You're building multi-step LLM systems (RAG pipelines, agent workflows)
You don't have training infrastructure or fine-tuning isn't an option
You want interpretable, inspectable improvements
Your task has enough evaluation signal to guide optimization
You can tolerate the maintenance cost of prompt fragility
When fine-tuning is still the right call:
Maximum performance is critical and you have the resources
You need to inject domain knowledge the base model lacks
Behavior stability across model versions matters
You're operating at scale where inference-time optimization is too expensive
Try simpler approaches first: Before running GEPA, try hand-crafted prompts with few-shot examples. Often gets 70% of GEPA's gains with minimal effort. DSPy's BootstrapFewShot optimizer is faster and simpler. Escalate to GEPA only when simple prompting plateaus below requirements.
Designing your evaluation metric: GEPA needs a scoring function that runs on your validation set. For deterministic tasks, exact match works. For open-ended generation, you'll need LLM-as-judge or human annotation. Weak metrics lead to Goodhart's law: optimized prompts that game your metric without improving real performance. Invest in metric design before running optimization.
Getting started:
import dspy
optimizer = dspy.GEPA(
metric=your_evaluation_function,
num_generations=10,
population_size=8
)
optimized_program = optimizer.compile(your_dspy_module)The DSPy documentation has full examples. The Hugging Face cookbook walks through a complete math reasoning optimization.
Prompt space is a legitimate optimization surface with different tradeoffs: cheaper to search, more fragile to deploy, limited by what instructions can express.
The question isn't "prompting vs training". It's "which optimization surface for this problem, given these constraints?" Sometimes the answer is weights. Sometimes it's prompts. Sometimes you start with GEPA to explore what's possible, then distill the insights into a fine-tuned model.
The next frontier: can we optimize prompts and weights simultaneously? Could GEPA-style reflection guide where gradient updates should focus? The optimization surfaces might not be alternatives. They might be complementary.