
Ask ChatGPT to tell you a joke. Then ask again. And again.
You'll notice a pattern. The same punchlines. The same setups. A handful of variations on the same themes.
Andrej Karpathy calls this "collapsed distribution". In a recent interview with Dwarkesh Patel, he put it bluntly: "The LLMs, when they come off, they're collapsed. They have a collapsed data distribution."
The model doesn't know the full space of human humor.
This isn't a bug to fix with more training. It's a fundamental property of how LLMs compress information. And as AI-generated content floods Internet, the problem is just accelerating.
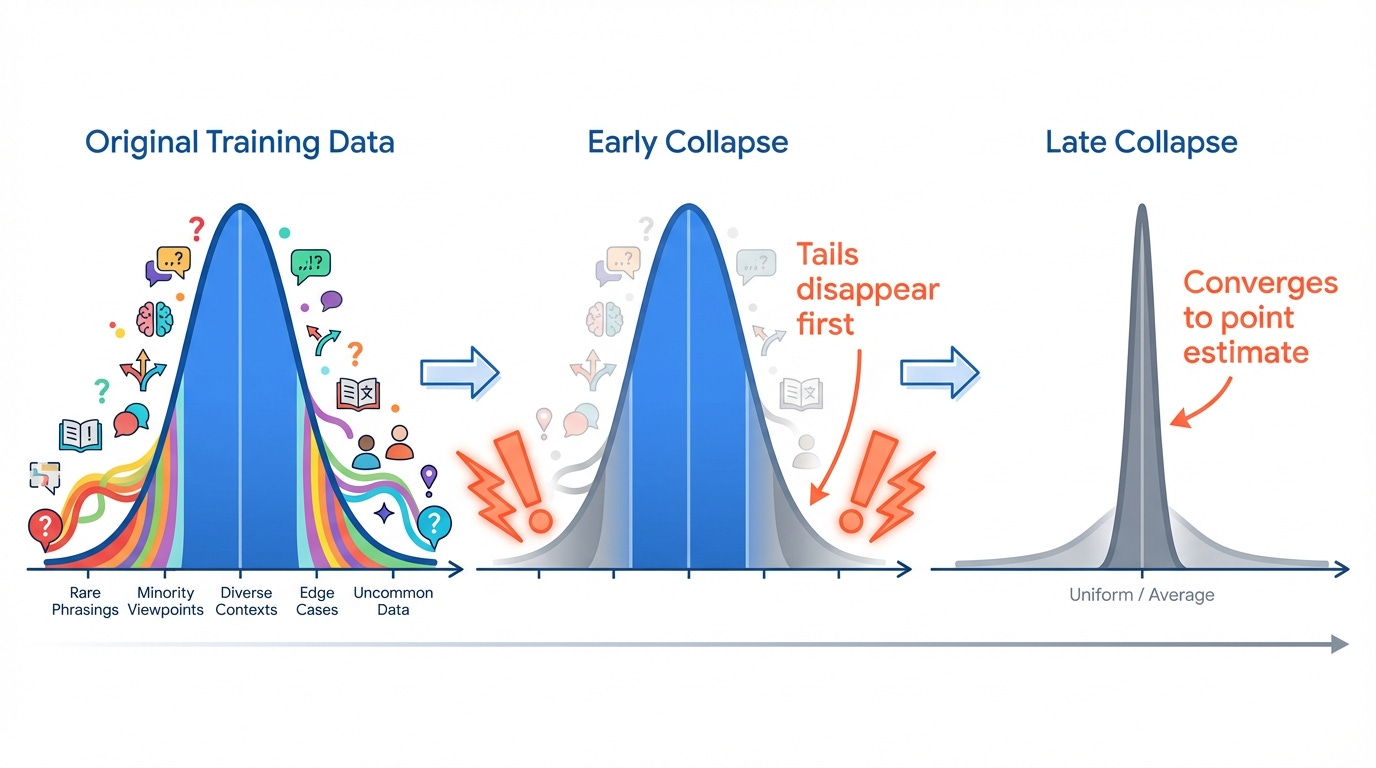
In July 2024, researchers from Oxford, Cambridge, and other institutions published findings in Nature that confirmed what practitioners had suspected: training models on their own outputs causes persistent defects that are difficult to reverse.
LLMs compress their training data into neural network weights. When you train a new model on outputs from an older model, you're compressing already-compressed information. Each generation loses more.
The team identified two stages of collapse:
Early collapse: The model first loses information from the tails of the distribution. Rare phrasings, unusual perspectives, minority viewpoints. The outputs still look fine. Benchmarks don't catch it. But the diversity is shrinking.
Late collapse: Eventually the distribution converges so tightly that outputs look "nearly nothing like the original data". The model has forgotten most of what it once knew.
Research on entropy dynamics quantifies this in controlled experiments. In synthetic-only training regimes, Shannon entropy per token drops dramatically. Vocabulary usage can narrow to half of initial levels. A model trained on mixed real/synthetic data maintains entropy around 3.3-3.5 bits per token. A model trained recursively on synthetic data drops from 4.2 to 2.5.
That's losing half your vocabulary diversity in a few training generations.
The internet is already saturated with AI-generated content.
A Graphite SEO study analyzed 65,000 English-language articles published between January 2020 and May 2025. Their finding: over 50% of new articles on the internet are now AI-generated.
In late 2022, roughly 10% of new content was AI-generated.
By 2024, that passed 40%.
By mid-2025, it crossed 50%.
Research from Jia et al. (2025) estimates that at least 30% of text on active web pages originates from AI, with the actual proportion likely approaching 40%.
The platforms are feeling it. Spotify removed 75 million spam tracks over the past year as AI tools made fake music easy to generate. Spotify's actual catalogue is 100 million tracks. A fake band called "Velvet Sundown" racked up over 1 million plays before detection.
The term "AI slop" has entered the vocabulary. Mentions increased 9x from 2024 to 2025, with negative sentiment hitting 54% in October.
Search engines are responding. A second Graphite report notes that Google Search shows 86% human-written content and only 14% AI. The search algorithms are actively deprioritizing AI content farms.
But models that scrape the web for training data don't have Google's filtering.
Model collapse doesn't produce obvious nonsense. It produces confident “wrongness”.
When searching for hard business data like market-share statistics, AI tools increasingly return numbers from sites that "bear some resemblance” to reality but are never quite right. Instead of stats from actual SEC filings, you get AI-generated summaries of AI-generated summaries of something that might once have been a real number.
The problem spans all major AI search tools.
In April 2025, a deepfake video showed Goldman Sachs' chief equity strategist David Kostin endorsing a fraudulent investment scheme. The financial sector is learning that AI trained on AI-polluted data produces convincing but wrong outputs.
Collapse doesn't make models stupid. It makes them boringly, repetitively, confidently narrow. The "confidently, perfectly incoherent" outputs come from models that have never seen the variation that existed in their original training data.
Model collapse is preventable but it requires intentional design.
The paper “STRONG MODEL COLLAPSE” explains this be avoided if synthetic data accumulates alongside real human-generated data, rather than replacing it.
Iterative retraining remains stable when synthetic data is mixed with a fixed set of real data. The practical implication: never delete your original human-generated training data, even as you add synthetic augmentation.
It suggests maintaining at least 50% real data in your training mix, though the optimal ratio depends on the quality of your synthetic data and your verification process. The principle is universal: cap your synthetic ratio, monitor it, enforce it.
One important nuance: high-quality, curated synthetic data can actually improve models when it fills gaps in your real-data distribution. The problem is indiscriminate scraping of AI outputs, not targeted synthetic augmentation.
Karpathy suggests watching perplexity (how surprised the model is by real text) on a holdout set of known human-written text as a canary for collapse.
If your model's perplexity on this holdout set starts climbing over training iterations, your distribution is shifting. If vocabulary diversity metrics start dropping, you're losing tails.
Metrics to track:
Perplexity on human-written holdout (alert if rises >10% from baseline)
Unique token usage per fixed-length sample (alert if drops below 85% of baseline)
Shannon entropy of output distribution
Distance from original training distribution
Set alerts before you notice problems in production.
The C2PA Coalition (Coalition for Content Provenance and Authenticity) includes over 300 organizations working on content provenance standards. Google's SynthID embeds watermarks in AI-generated content across text, audio, visual, and video.
These tools aren't perfect. Watermarks can be stripped by heavy editing. But combined with organizational policies, they form a defense layer.
The value of pre-2023 data is increasing. Web content created before widespread AI adoption is less likely to be contaminated. Companies are paying for access: Reddit's licensing deals with Google (~$60M/year) and OpenAI (~$70M/year) total over $130M annually. Stack Overflow has similar arrangements.
Even imperfect verification helps. Research shows that filtering low-quality synthetic data using external verifiers can not only avoid degradation but actually improve model performance.
Active curation means selecting synthetic data that fills gaps in your real-data distribution, not synthetic data that duplicates what you already have.
For high-stakes training, human-in-the-loop verification remains essential. Automated systems can catch obvious problems; humans catch subtle distribution shifts that metrics miss.
A two-tier market is emerging. Companies with resources can license high-quality human data. Smaller firms face litigation when they scrape the same information.
Reddit sued Perplexity in October 2025 and Anthropic in June 2025 for unauthorized data access. In September, Reddit joined Yahoo, Medium, and others in backing Really Simple Licensing (RSL), an effort to standardize AI content licensing modeled after music industry frameworks like ASCAP.
Scale wants more data. Quality wants better data. As web pollution grows, these forces pull harder against each other.
The practitioners who take data provenance seriously now will have significant advantages as contamination grows. Companies ignoring provenance today will spend 2027 debugging why their models can't escape median outputs.
Model collapse is preventable with intentional design. Start measuring now.